







摘要: 增量日志明细处理共享经验总结
关键词: 数据仓库、增量日志、数据开发、数据共享
整体说明
增量日志明细处理共享经验总结,大致如下:
一、任务背景
最近接到一个任务,要把数据仓库中的增量日志明细给三方,让他们做统计分析,
虽然不理解为什么不直接做统计分析再共享,本着打工人让干啥就干啥的原则,还是做了,
日志也不是很大的日志,还是能做的。
- 日志半年存量数量级:千万
- 日志增量数量级:万
二、增量日志特点
- 每日增量: 每日数据增量,也就是说今天的日志和历史日志没有关系,且历史日志不会变动
- 全量数据大: 全量日志相对于每日增量数据,很大
- 增量数据小: 每日增量是小数据,很好处理
- 明细数据: 数据都是明细,没有统计,没有汇聚
- 处理字段少: 日志数据最常用的字段就是相关组织关系,及相关统计维度,最终用来统计 UV 和 PV,所以字段相对较少
- 通常无业务主键: 通常日志数据的主键,都是自增主键,没有常规意义上的业务主键
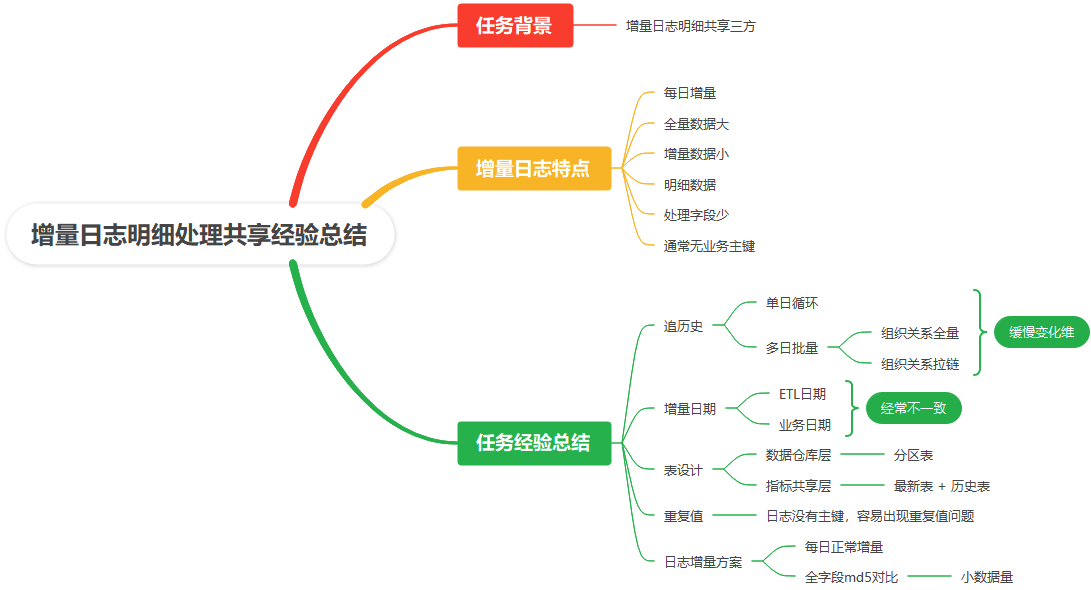
三、任务经验总结
3.1、追历史
提起日志,就涉及到分区表,就涉及到追历史,数据增加如下所示:
[时间轴]
◄─── 历史数据 ───┤►├── 增量更新 ───►
(截至T日) (T+1, T+2...)
[数据存储结构示意图]
┌───────────────────┐
│ 历史数据主库 │
│ (完整数据截至T日) │
└─────────┬─────────┘
│ 增量追加
▼
┌───────────────────┐
│ 增量缓冲区 │
│ [T+1] [T+2] [T+3]│
└───────────────────┘
[操作流程]
1. 初始状态:历史数据完整存储
2. 周期性地捕获增量数据(按小时/天/周)
3. 校验后增量数据追加到主库
4. 形成新的完整历史数据集
但是如果我们只是单纯的把日志表数据,数据增加,这个很简单,
但是我们通常都是使用日志表,和其他的组织关系关联,比如用户组织关系
这个使用就有如下两种情况
3.1.1、单日循环
这个是最常用的追历史的方式
有如下前置条件:
- 所有相关表,均保存所有历史快照数据
- SQL 的分区参数,以外部入参的方式传入
3.1.2、多日批量
-
组织关系全量
这个方式可以直接执行多日数据,执行效率高,但是缺点是,全量组织关系表只能取最新的
-
组织关系拉链
这个方式可以像单日循环拿到,所有的历史,缺点是拉链表维护比价麻烦
3.2、增量日期
-
ETL日期
这个日期,就是我们同步数据的日期,不管这一批是什么时候产生的,只要我今天拿到,并且入库,那么日期,就是昨天
-
业务日期
通常日志的业务日期,就是这个日志活跃的日期,或者说产生的日期
3.3、表设计
-
数据仓库层
这一层,增量是保留全部日志分区,并且通常都是 Hive 这样的大数据的,数据库,对分区支持良好,
同时因为经常需要为下游支持,所以数据需要保留较长时间
-
指标共享层
这一层,一般是快速查询的数据库,比如 MySQL 分区设计一般,保留所有分区,给应用查询,增加了查询难度,且效率会越来越低
最新表交给应用查询或者数据共享,这个要求前置有个检查最新表的质量任务,如果有数据则清空插入,没有则不操作数据,
历史数据放入历史表
3.4、重复值
日志一般没有常规意义上的业务主键,一般是自增主键,但是我们在做到指标层时,一般不会保留自增主键,容易出现重复值问题,所以要注意去重
3.5、日志增量方案
-
每日正常增量
常规方案,在有增量日期的时候,使用
-
全字段md5对比
当我们没有增量识别字段时,采用全字段 MD5 值,来比对,实现增量,不过这种要求,每次增量的数据本身并不大, 当每次增量数据很大,就不太适用了




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











