







文章目录
摘要: 数据建模工具-PDManer使用技巧-贴源层
关键词: 数据建模 数据治理 数据模型 数据字典 数据血缘
一、总体介绍
在数据治理过程中,我们经常和数据模型打交道,这时候我们就需要一个好的工具,来完成建模这个过程,PDManer就是本文的主角。
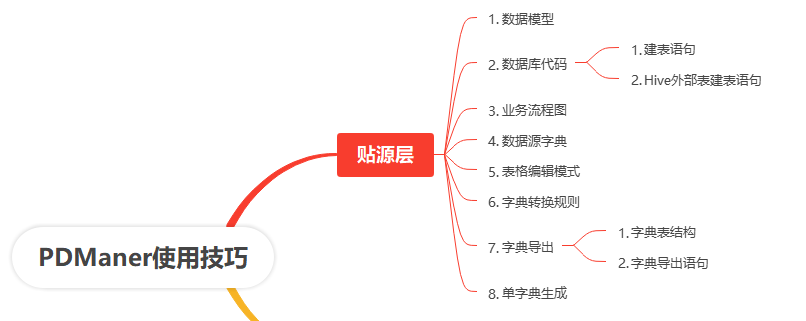
在数据治理过程中,分成贴源层、模型层、指标层等,这里就以贴源层为例介绍工具:
二、软件下载
官方网站:https://www.pdmaas.cn/home
个人使用,选择免费版本即可
如果需要多人协同,可以选择 PDMaas 私有云版本
三、使用技巧
3.1、贴源层
3.1.1、数据模型
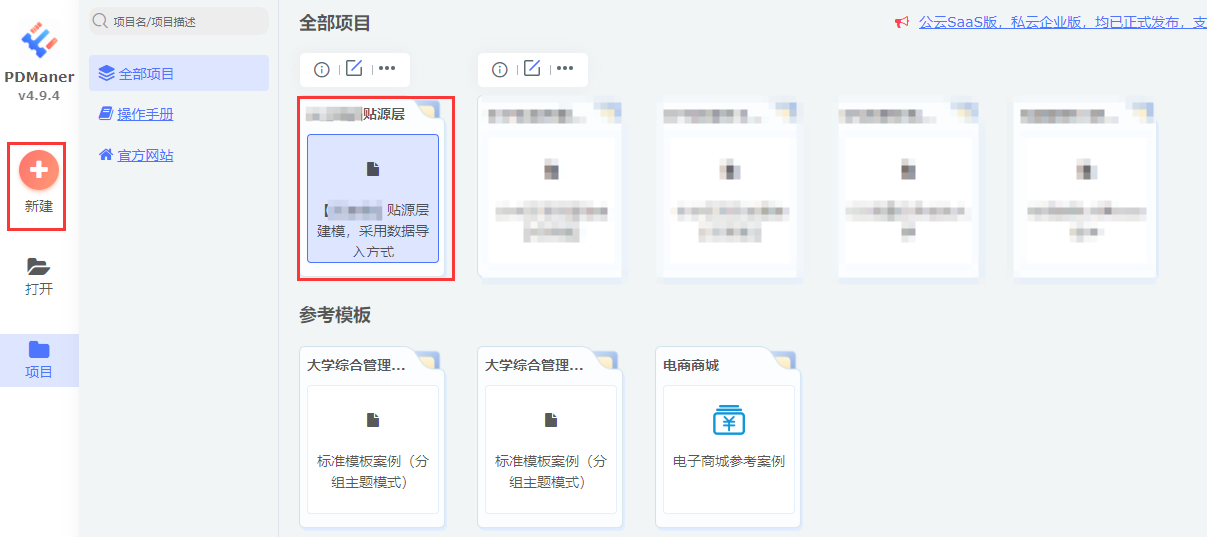
a.新建项目
新建"XX项目贴源层",如下图
贴源层特点: 和源系统保持一致,所以我们这层的模型采用数据库导入方式生成,不自己新增字段
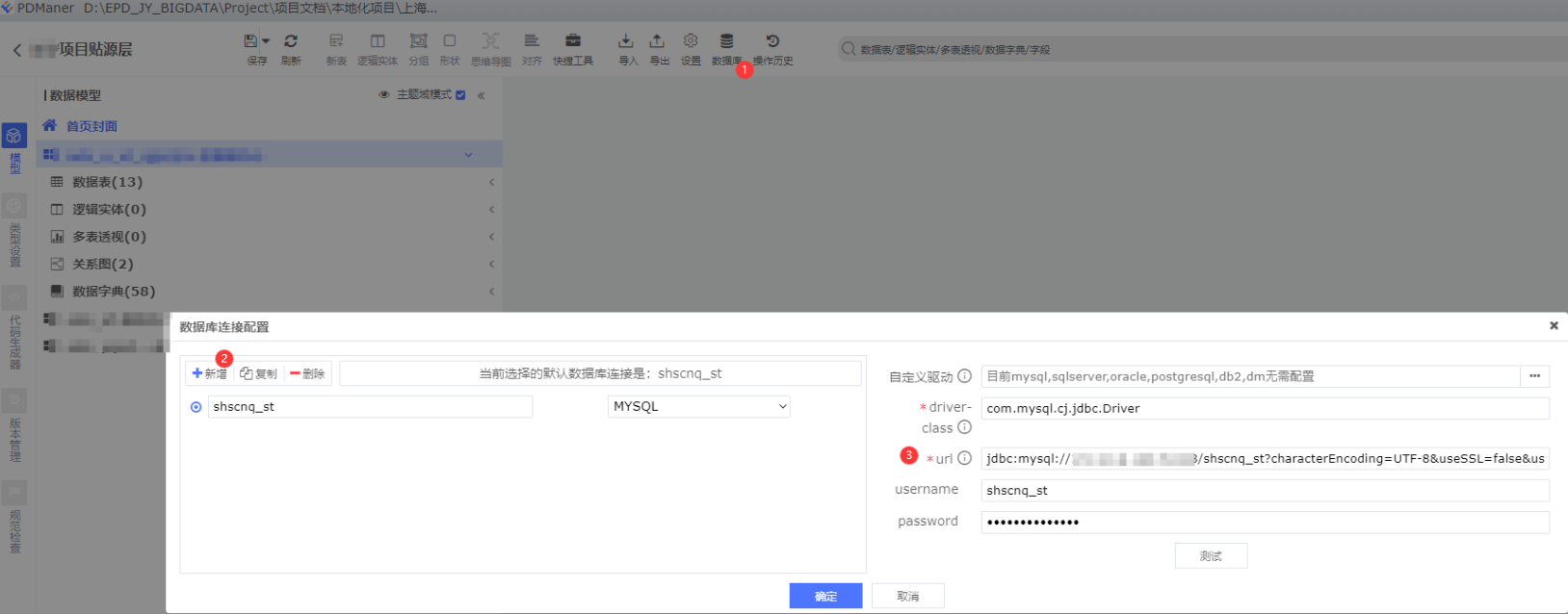
b.新增数据库连接
进入项目之后
依次点击:①数据库 -> ②新增 -> ③添加数据库
因为我的数据来源是Mysql,所以我连接了Mysql,并且这个数据库是测试数据库,我把生产的数据表结构,在测试数据库已经新建完毕。
c.新增主题域
这里的主题域,并不是模型层的意义,我们按照应用来区分
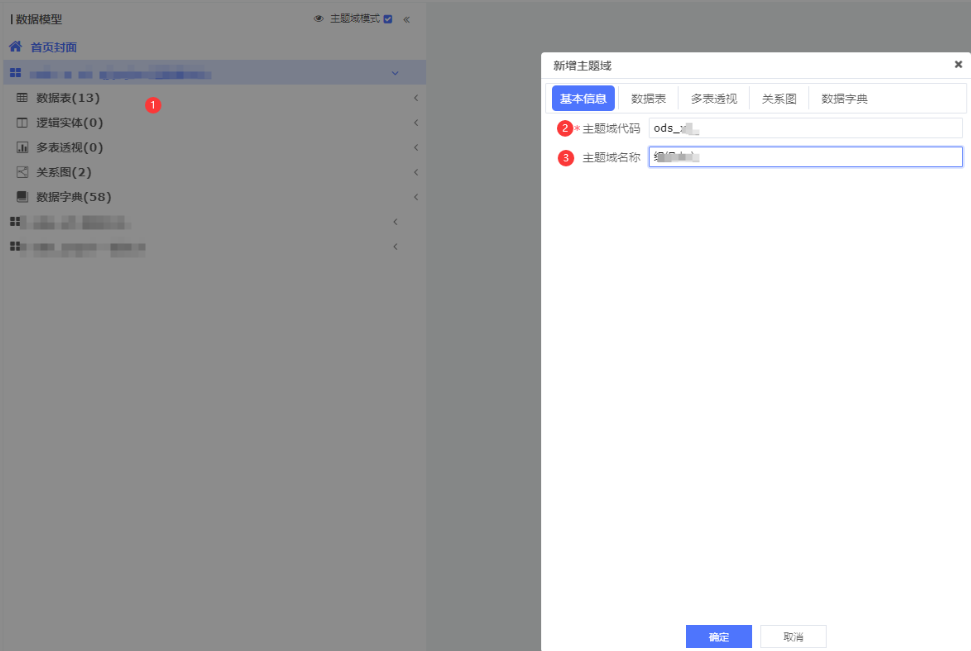
依次点击: ①点击左侧空白处,新增 -> ②数据应用贴源层表前缀 -> ③应用名称
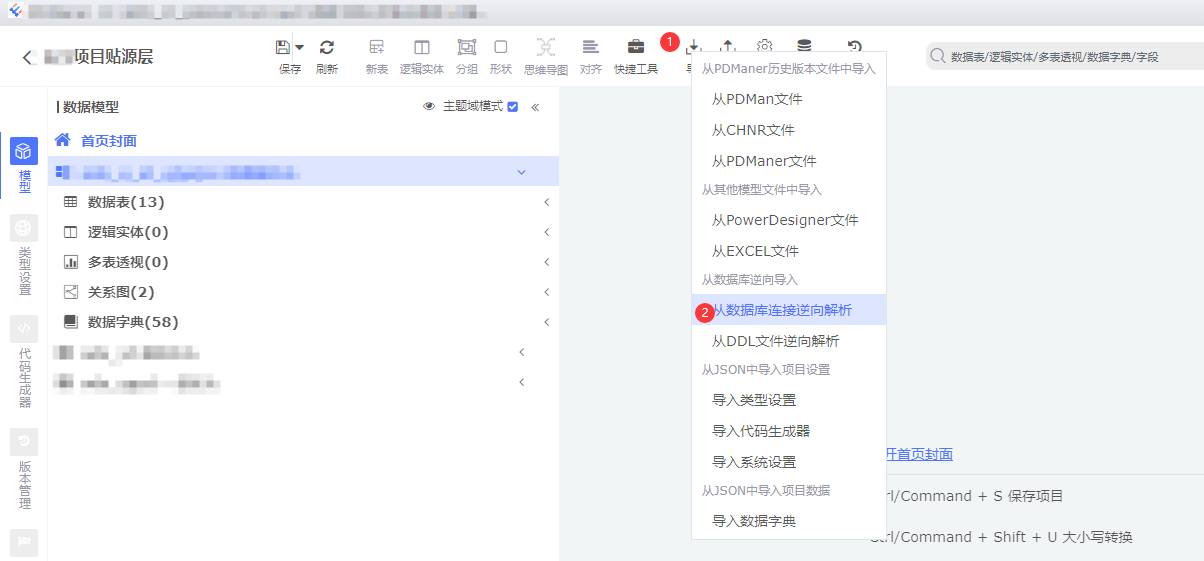
d.导入数据模型
依次点击: ①导入 -> ②从数据库连接逆向解析
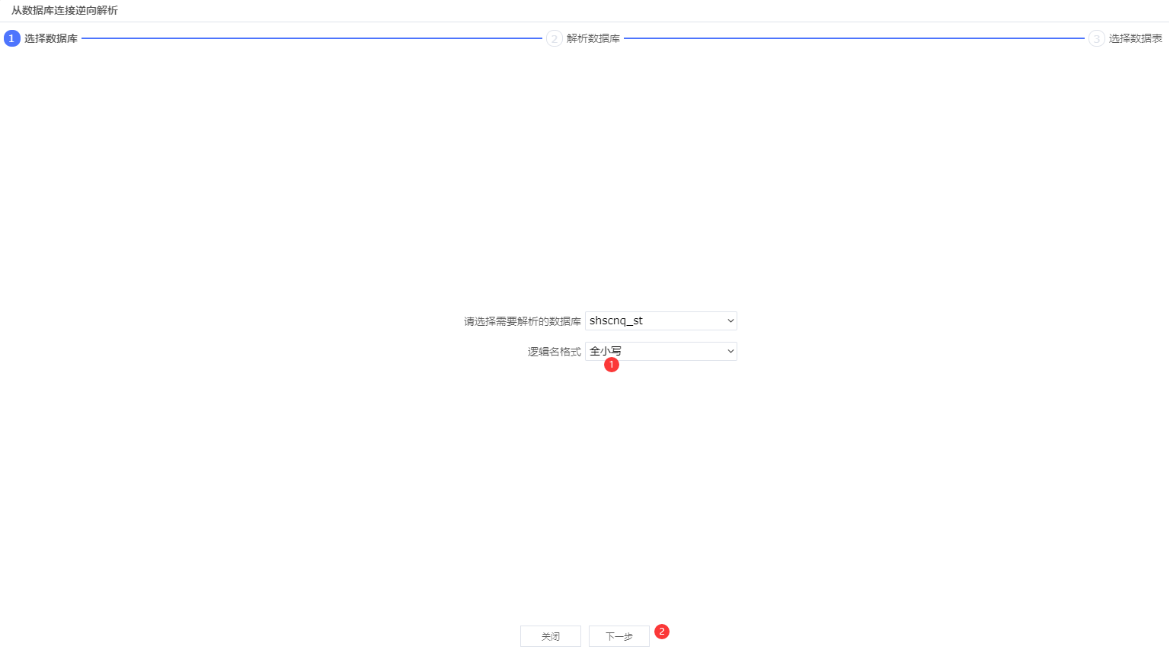
依次点击: ①选择全小写 -> ②下一步
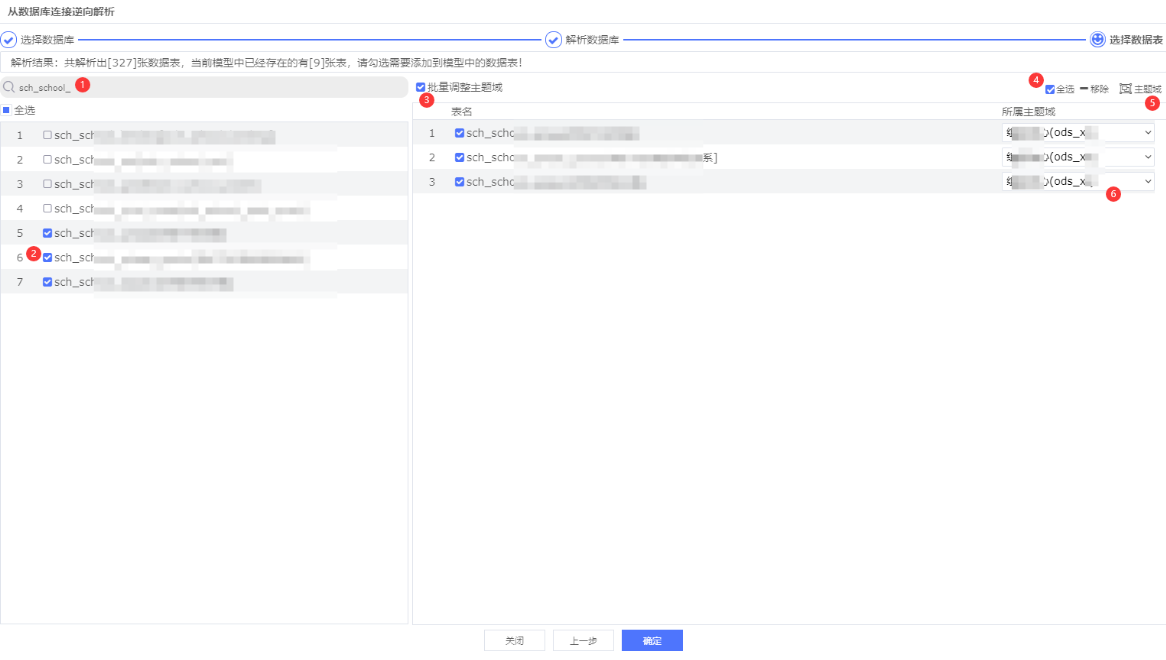
依次点击:①输入你想要的表名 -> ②选中多个表 -> ③批量调整 -> ④全选 -> ⑤选择主题域 -> ⑥选择前面新建的应用,点击确定
依次点击:显示三张表导入成功,确定
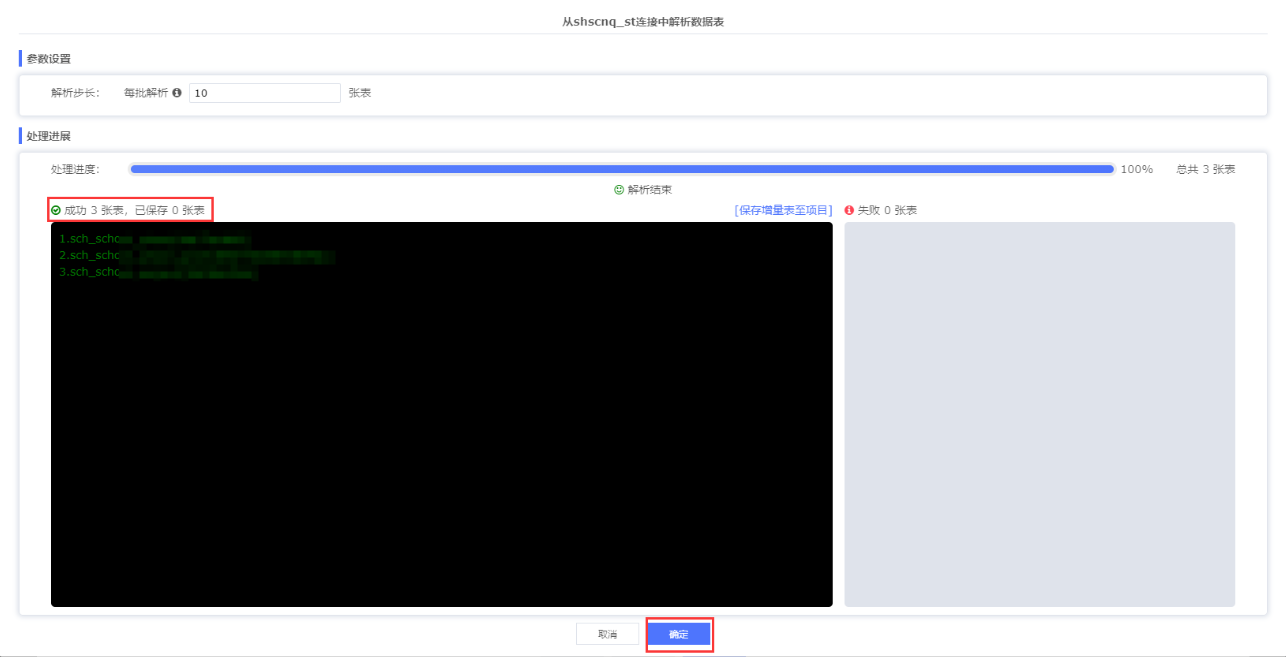
依次点击:①点击表模型 -> ②修改表前缀 -> ③修改表注释
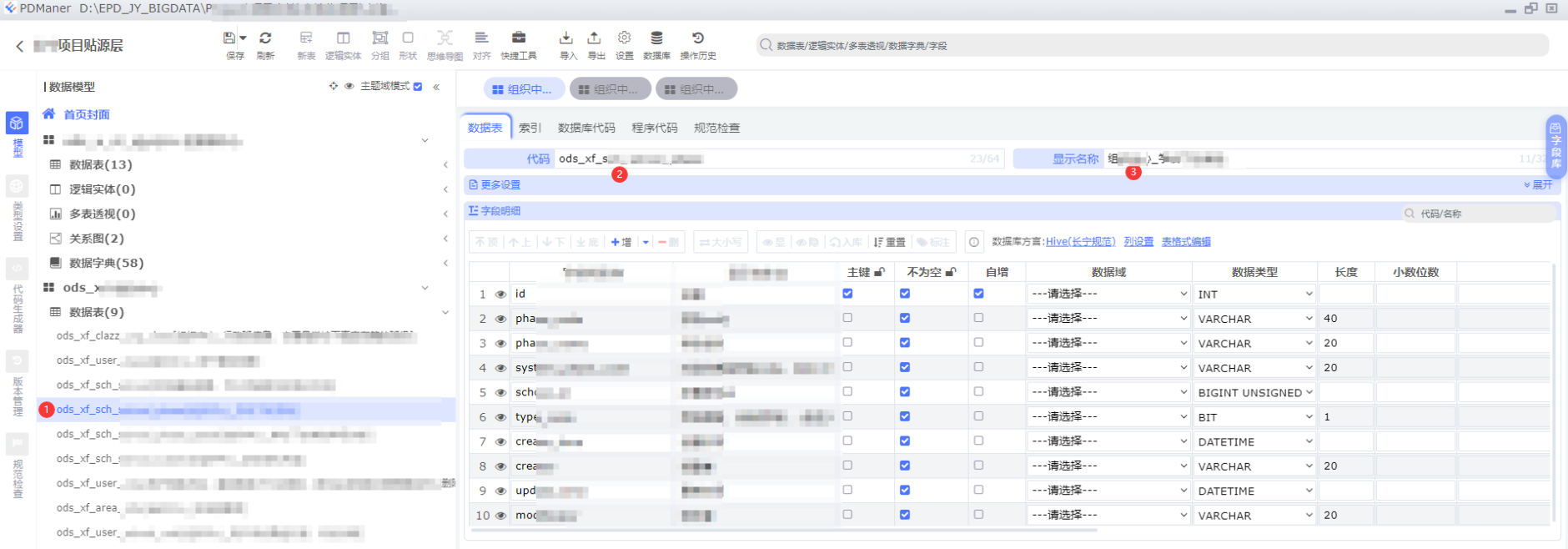
从上面截图可以看到,贴源层的表模型都已经成功导入,并且按照贴源层的规范,修改了表前缀。
3.1.2、数据库代码
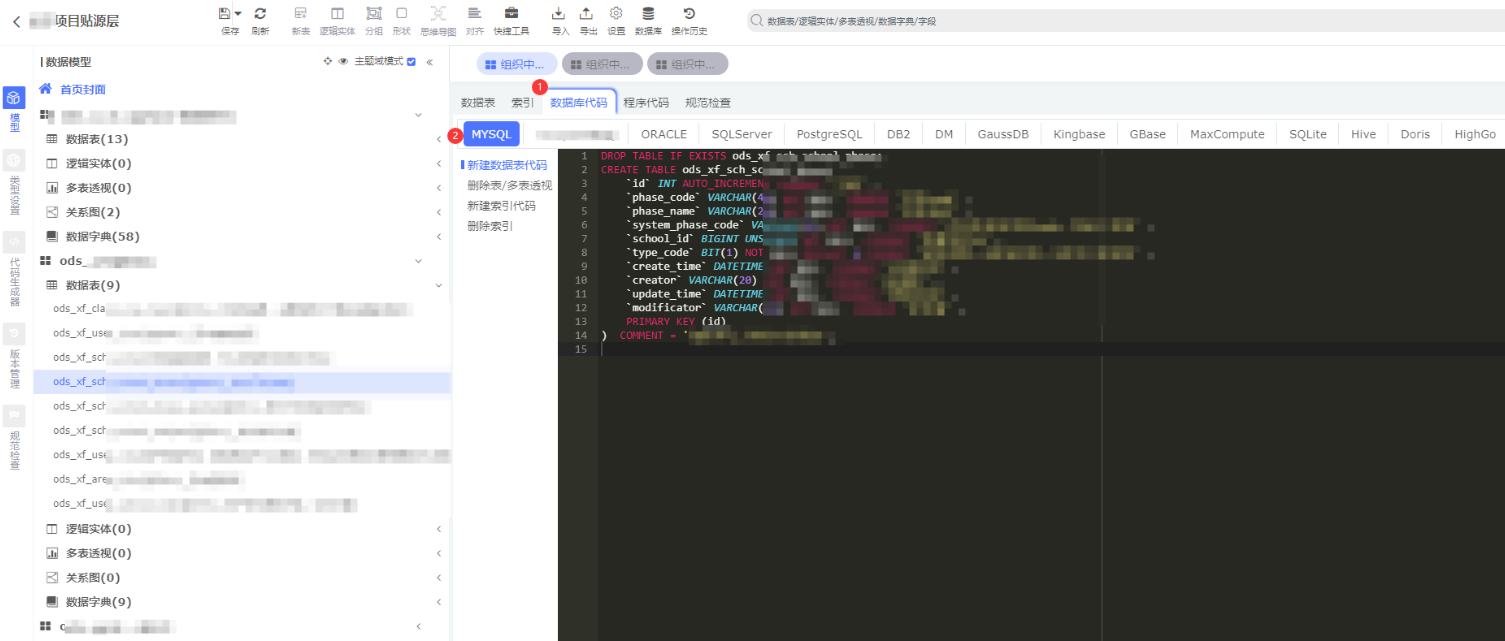
a.建表语句
依次点击:①数据库代码 -> ②MYSQL -> 看到建表语句
b.Hive外部表建表语句
当我们使用hive表的时候,我们通常有自己的规范,PDmaner自带的已经不支持了
所以我们新增类型
依次点击:①点击类型设置 -> ②数据库,点击新增 -> ③填写数据库(Hive(XX规范)) -> ④预览编辑 -> ⑤输入代码
代码内容如下
{{
let partitionedBy = it.entity.properties['partitioned by'];
partitionedBy = partitionedBy?partitionedBy:'请在扩展属性中配置[partitioned by]属性';
let defOds = it.entity.properties['defOds'];
defOds = defOds?defOds:'请在扩展属性中配置[defOds]属性';
}}
drop table if exists {{=it.entity.defKey}};
create external table if not exists {{=it.entity.defKey}}(
`cd_id` string COMMENT '集成记录唯一值',
`cd_time` string COMMENT '集成记录时间',
`cd_info` string COMMENT '集成记录信息',
{{ pkList = [] ; }}
{{~it.entity.fields:field:index}}
`{{=it.func.lowerCase(field.defKey)}}` string comment '{{=it.func.join(field.defName,field.comment,';')}}' {{= index < it.entity.fields.length-1 ? ',' : ( pkList.length>0 ? ',' :'' ) }}
{{~}}
{{? pkList.length >0 }}
{{?}}
)
comment '{{=it.func.join(it.entity.defName,';') }}'
stored as parquet
location '/project/shscnq/db/u_ods/{{=it.entity.defKey}}'
;
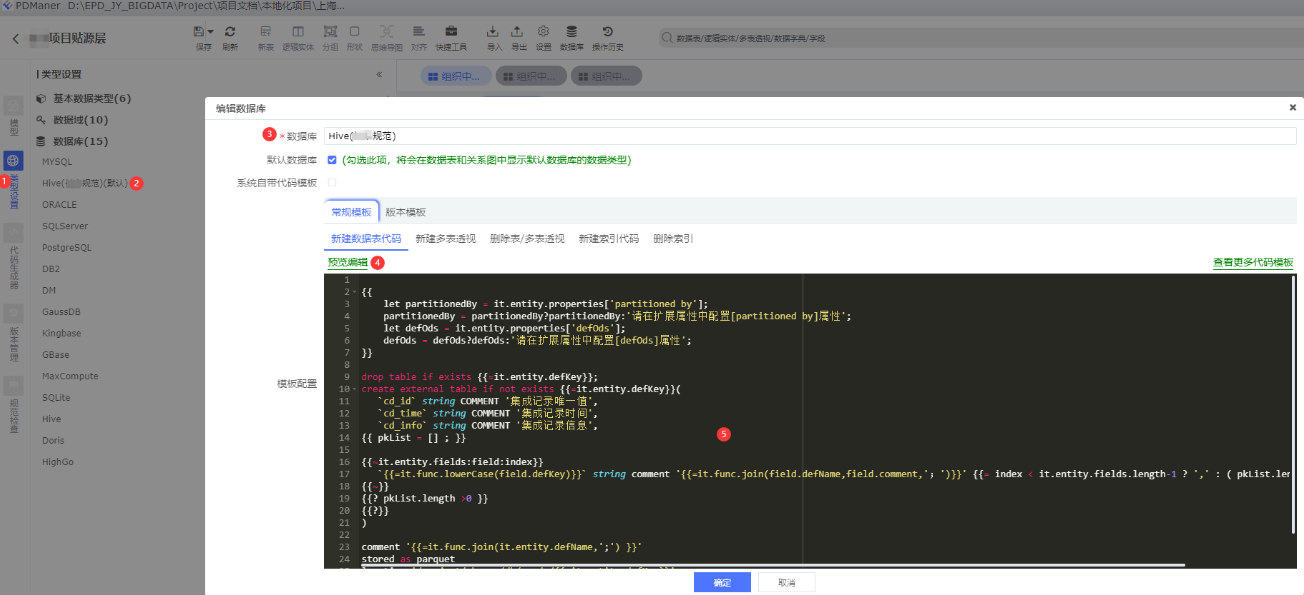
再返回数据模型
依次点击:①点击表模型 -> ②数据库代码 -> ③Hive(XX规范) -> 可以看到按照XX规范的Hive表数据库代码
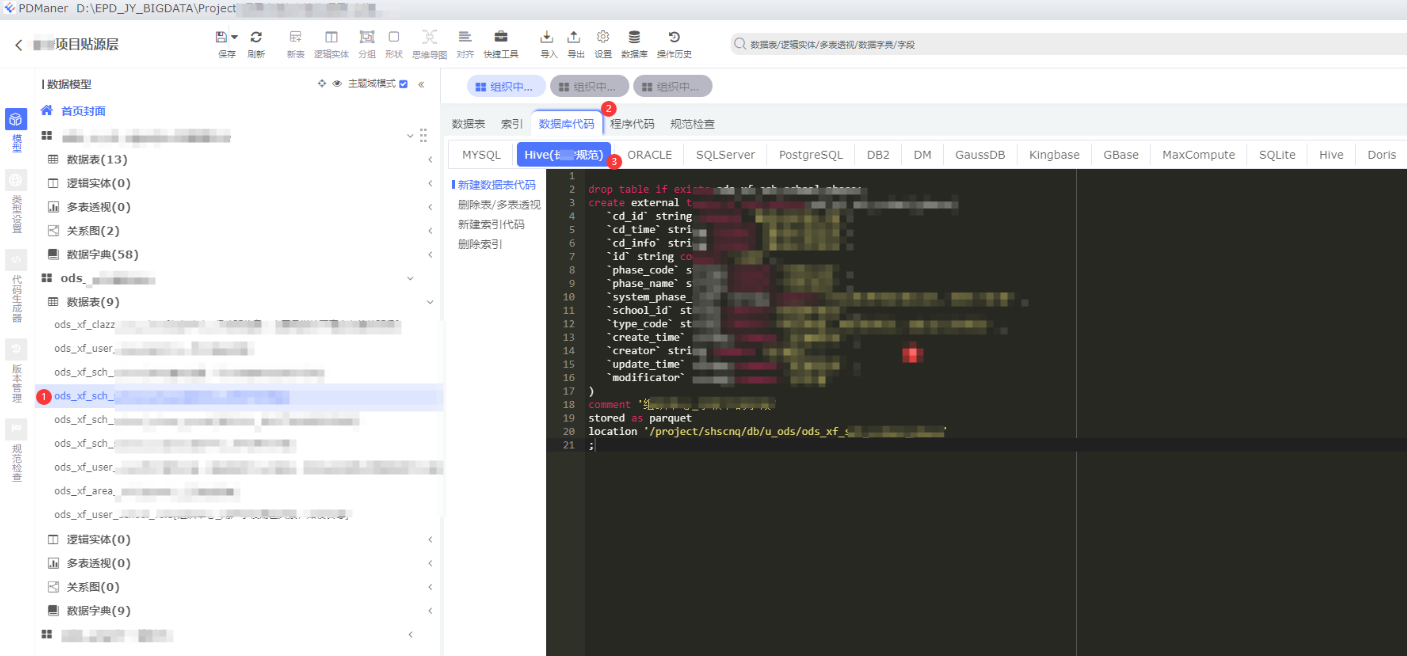
这里说一下XX项目贴源层规范:
1.所有Hive表都必须建外部表
2.字段类型必须是String
3.固定三个字段cd_id、cd_time、cd_info
4.外部表前缀 “/project/shscnq/db/u_ods/”
5.必须使用parquet数据格式存储
经过这样的Hive(XX规范)类型增加之后,之后所有的数据模型,都会按照我们的规范来生成,一次修改,后面的建表语句自动生成
3.1.3、业务流程图
随着我们集成到业务数据库的表数据,我们在接入之前,或许已经了解到业务相关流程,也有可能我们根据数据表才能自己嗅探到,这时候我们需要绘制业务流程图,可以绘制流程图或者思维导图,都支持,这次以思维导图为例。
依次点击:①关系图 -> ②新增 -> ③思维导图 -> ④绘制业务
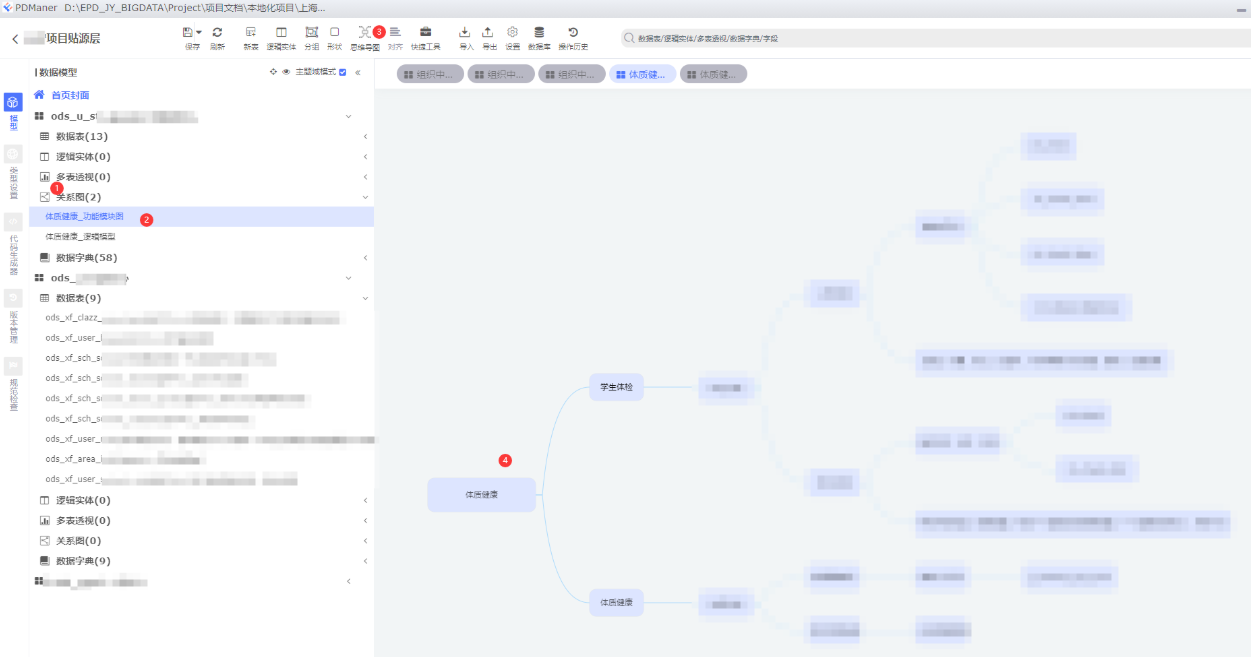
优势:
1.把所有的流程图和建模都汇集在一个工具里,方便
2.他还有逻辑模型、物理模型ER图,都可以在这里绘制
3.1.4、数据源字典
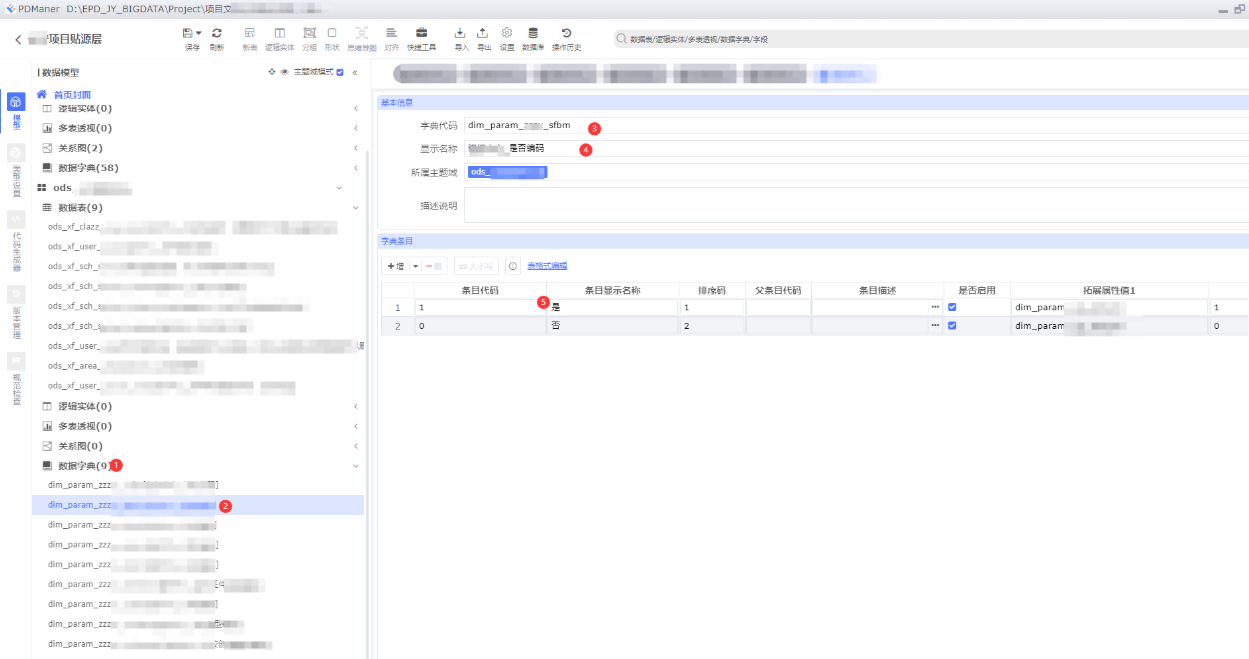
当我们把模型和业务流程图做完之后,我们就开始整理数据源字典了
依次点击:①数据字典 -> ②新增字典 -> ③填写字典代码 -> ④填写字典名称 -> ⑤填写字典各个条目
3.1.5、表格编辑模式
在我们整理数据源字典的时候,我们发现,数据源字典来源方式有很多
1.对方表建表语句备注
2.对方的字典表
3.对方手工给的Excel
所以没法像表一样,都能导入,所以我们可以使用表格编辑模式
依次点击:①表格式编辑
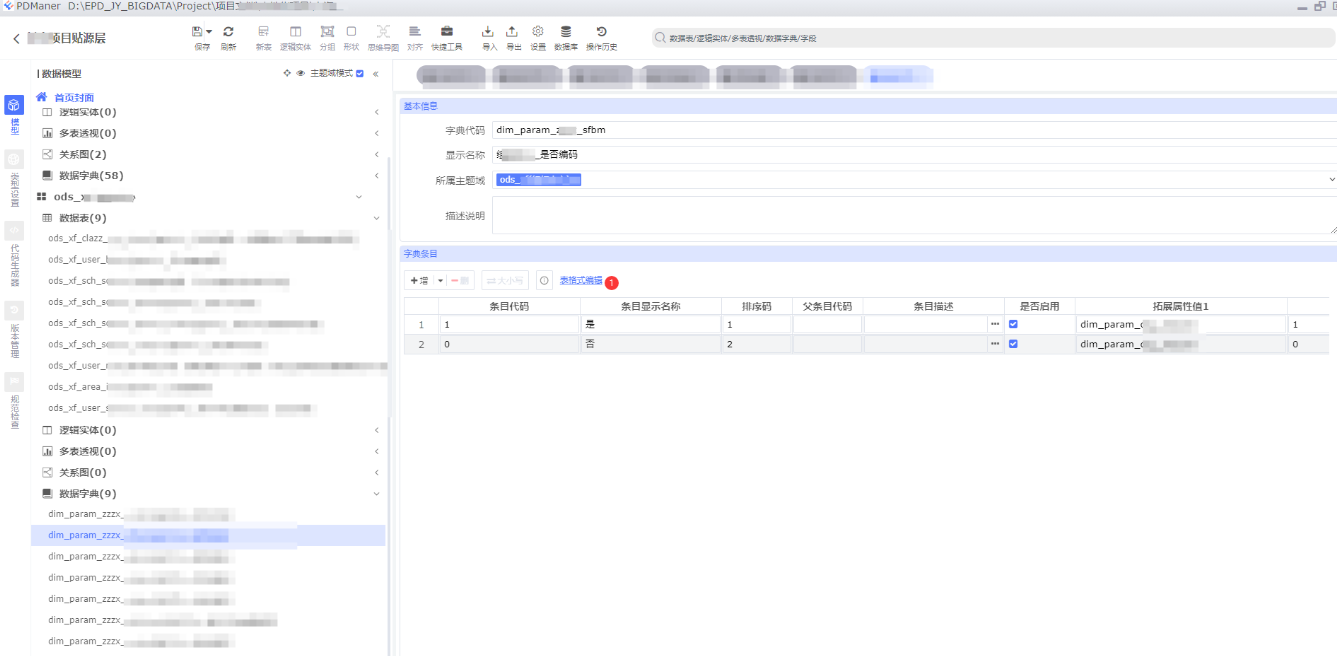
可以像编辑Excel一样编辑,也可以批量粘贴数据
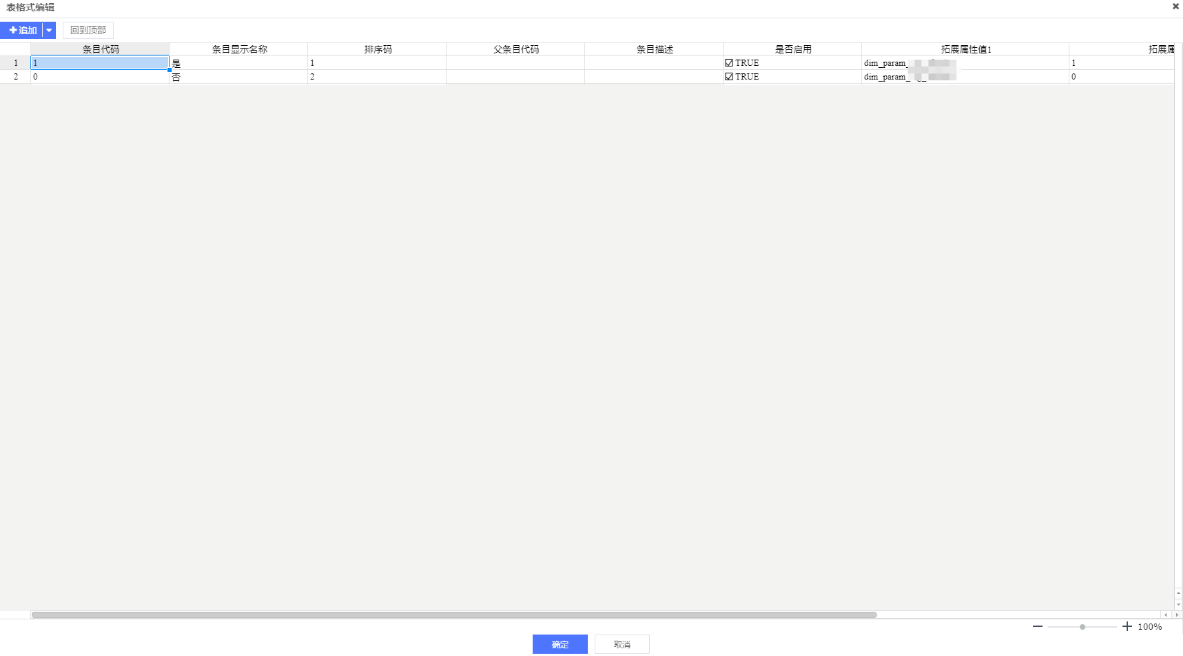
3.1.6、字典转换规则
在数据治理过程中,我们有很大一部分工作就是做数据字典的映射,把各个数据源的字典映射成一个统一的标准字典(这里的标准字典,在模型层维护,在后面会描述),但是这个映射的关系,我们之前都是写在Excel里或者是存储在数据表里,维护比较麻烦。
这里我们可以维护在PDmaner里。
点击一个字典表,进入表格式编辑
①转换目的标准字典表名
②转换目的标准字典表字典编码值
③转换目的标准字典表字典中文值
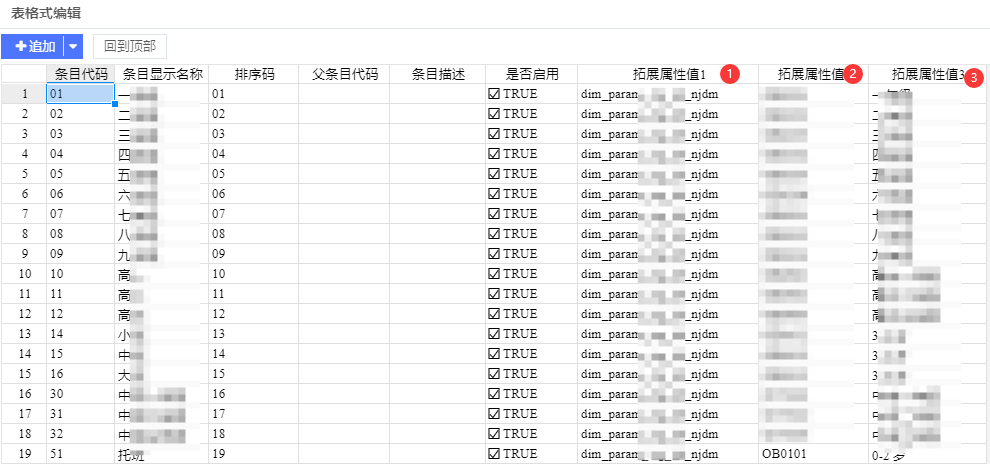
3.1.7、字典导出
到这里就会有人说了,字典表是维护好了,但是这些字典我要在sql里关联使用呀,怎么导出去,怎么关联啊
a.字典表结构
首先导出去的表需要数据表存储,表结构如下
create table sys_dict
(
table_name varchar(255) null comment '维度表名',
table_comment varchar(255) null comment '维度表注释',
`desc` varchar(255) null comment '描述说明',
version varchar(255) null comment '版本'
)
comment '字典总表';
create table sys_dict_item
(
table_name varchar(255) null comment '维度表名',
dim_code varchar(255) null comment '维度字典编码',
dim_name varchar(255) null comment '维度字典名称',
sort varchar(255) null comment '排序',
parent_dim_code varchar(255) null comment '父级维度字典编码',
`desc` varchar(255) null comment '描述',
enabled varchar(255) null comment '是否启用',
version varchar(255) null comment '版本',
target_table_name varchar(255) null comment '转换目标表名',
target_dim_code varchar(255) null comment '转换目标维度字典编码',
target_dim_name varchar(255) null comment '转换目标维度字典名称'
)
comment '字典明细表';
b.字典导出语句
PDmaner自带导出字典功能
但是表字段和我们的字典表不同,需要修改
依次点击:①设置 -> ②数据字典SQL模板
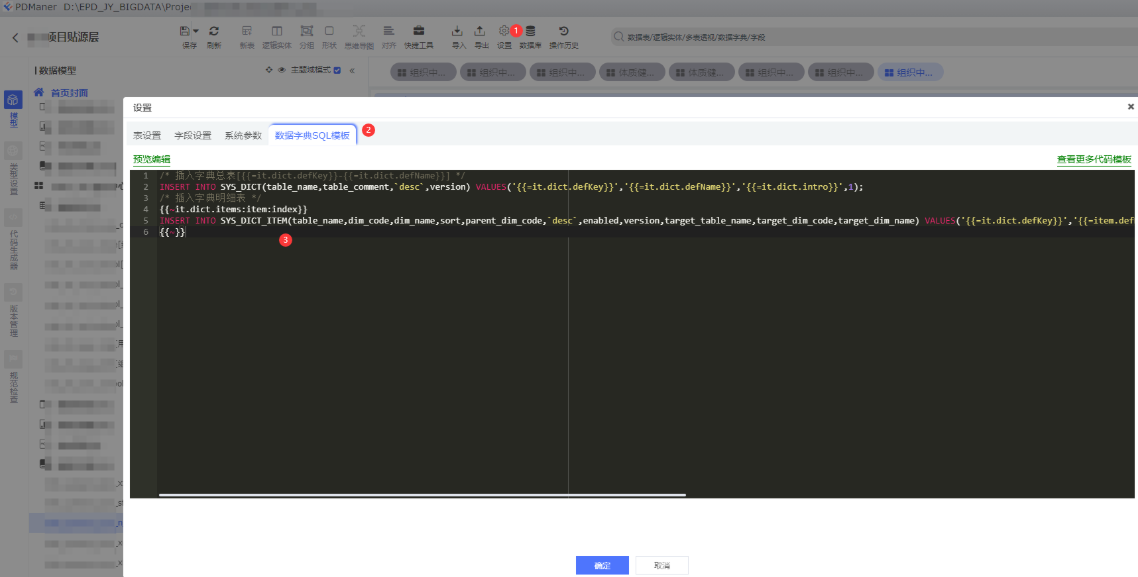
编辑内容如下
/* 插入字典总表[{{=it.dict.defKey}}-{{=it.dict.defName}}] */
INSERT INTO SYS_DICT(table_name,table_comment,`desc`,version) VALUES('{{=it.dict.defKey}}','{{=it.dict.defName}}','{{=it.dict.intro}}',1);
/* 插入字典明细表 */
{{~it.dict.items:item:index}}
INSERT INTO SYS_DICT_ITEM(table_name,dim_code,dim_name,sort,parent_dim_code,`desc`,enabled,version,target_table_name,target_dim_code,target_dim_name) VALUES('{{=it.dict.defKey}}','{{=item.defKey}}','{{=item.defName}}','{{=item.sort}}','{{=item.parentKey}}','{{=item.intro}}','{{=item.enabled}}',1,'{{=item.attr1}}','{{=item.attr2}}','{{=item.attr3}}');
{{~}}
依次点击:①点击导出 -> ②导出数据字典SQL
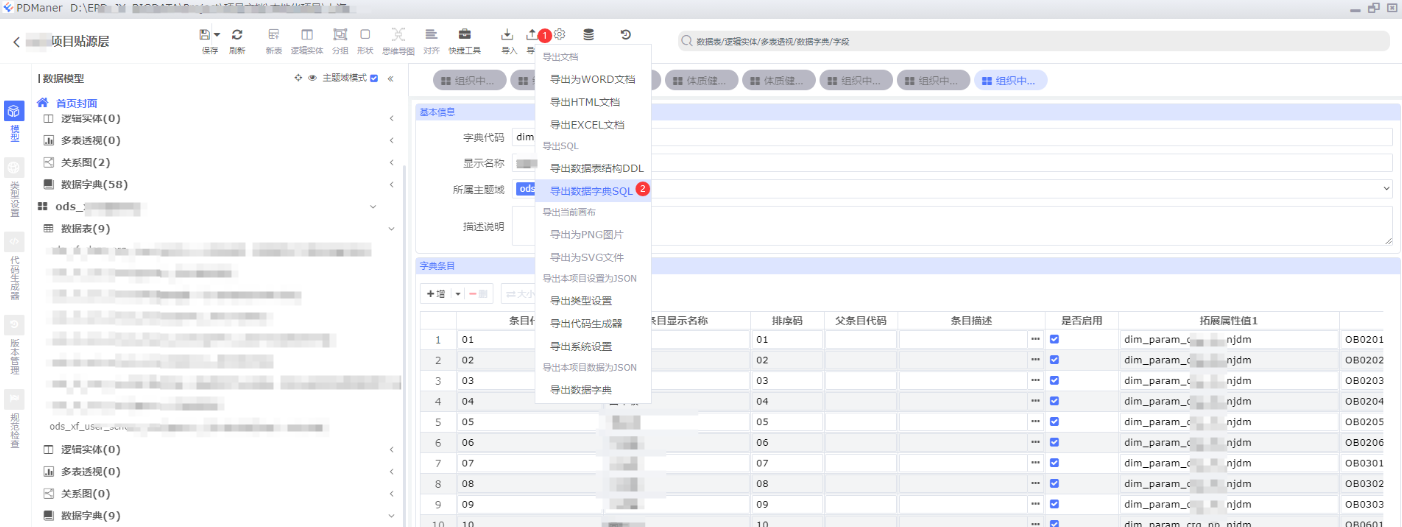
依次点击:①选择需要导出的数据字典 -> ②选择字典表
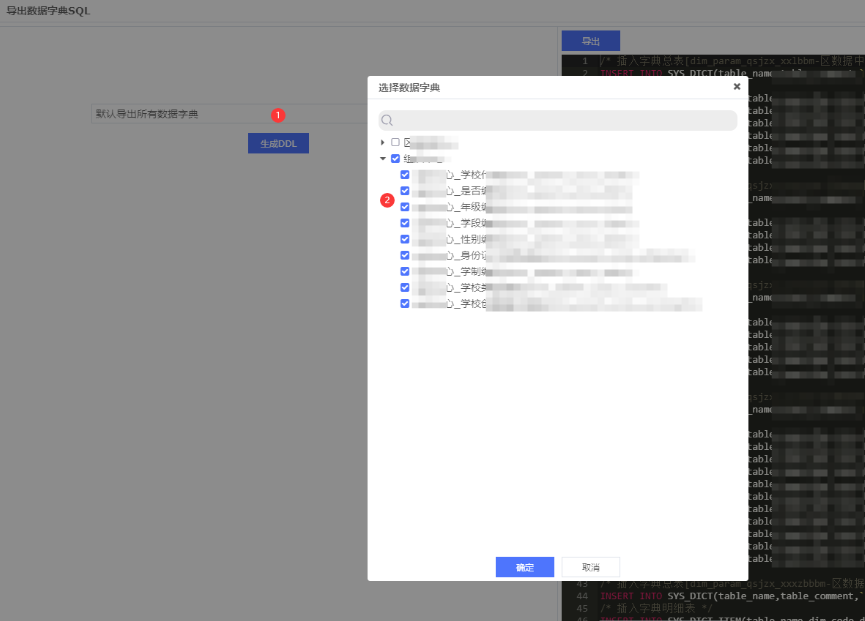
依次点击:①生成DDL -> ②导出,或者选择SQL复制也可以
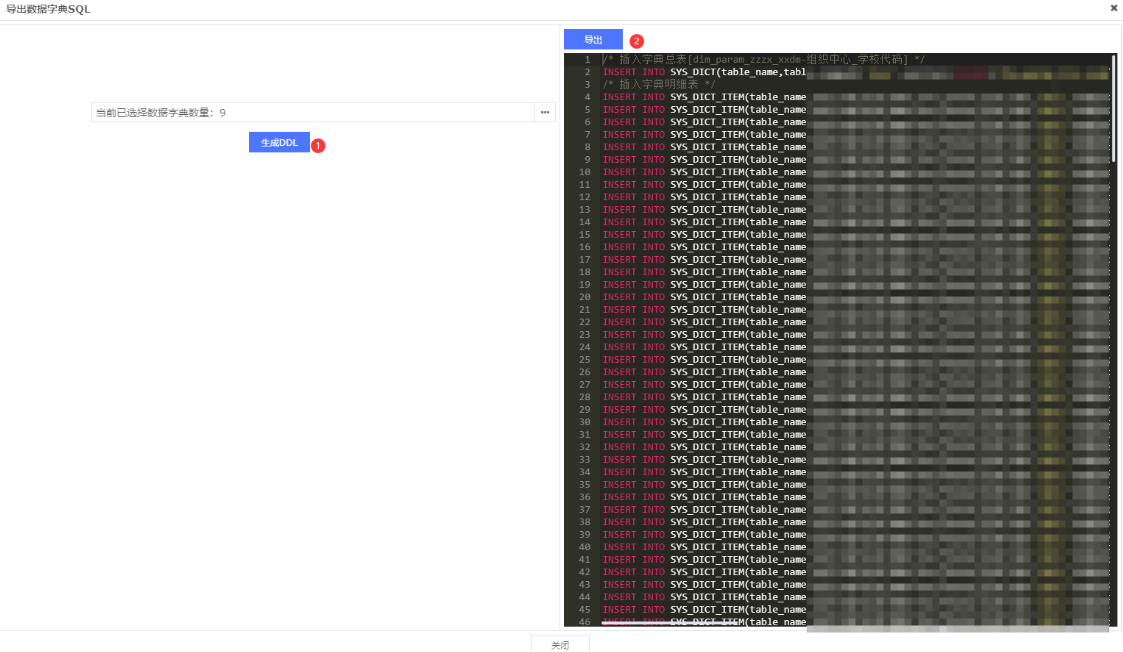
这样执行这些SQL就能得到所有字典表的数据
3.1.8、单字典生成
字典总表生成之后,还有需求会每个字典,单独生成字典,这样就能够单独使用
通过SQL生成,以下是本人自定义使用,仅供参考
create table sys_dim_template
(
table_template longtext null comment '表模板',
insert_template longtext null comment '插入语句模板',
table_sql longtext null comment '建表语句SQL',
insert_sql longtext null comment '插入语句SQL',
table_rows_diff longtext null comment '表条数验证'
);
表模板
DROP TABLE IF EXISTS `${table_name}`;
CREATE TABLE `${table_name}` (
`id` varchar(64) NOT NULL COMMENT '唯一编号',
`bm` varchar(100) NOT NULL COMMENT '代码',
`mc` varchar(255) NOT NULL COMMENT '名称',
`jc` varchar(100) DEFAULT NULL COMMENT '简称',
`pyjp` varchar(100) DEFAULT NULL COMMENT '拼音简拼',
`px` varchar(100) DEFAULT NULL COMMENT '排序',
`ms` varchar(500) DEFAULT NULL COMMENT '描述',
`yxx` varchar(10) DEFAULT NULL COMMENT '有效性,0有效,1无效',
`effdate` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`expdate` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`sjbm` varchar(100) DEFAULT NULL COMMENT '国家标准编号',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `unique_key` (`bm`,`yxx`)
) ENGINE=InnoDB COMMENT='${table_comment}'
;
插入语句模板
insert into `${table_name}`(`id`,`bm`,`mc`,`jc`,`pyjp`,`px`,`ms`,`yxx`,`expdate`,`sjbm`) values (uuid(),"${KEY_}","${LABEL}","${JC}","${PYJP}","${SORT_}","","0","2097-01-01 00:00:00","");
建表语句SQL
select replace(replace(t2.table_template, "${table_name}", t1.table_name), "${table_comment}", t1.table_comment)
from sys_dict t1
join sys_dim_template t2
插入语句SQL
select
replace(
replace(
replace(
replace(
replace(
replace(t2.insert_template, "${KEY_}", t1.dim_code),
"${LABEL}", t1.dim_name),
"${JC}", pinyin(t1.dim_name)),
"${PYJP}", pinyin(t1.dim_name)
),
"${SORT_}", t1.sort
),
"${table_name}", t1.table_name
)
from sys_dict_item t1
join sys_dim_template t2
表条数验证
select
t1.table_name,t1.table_num,t2.TABLE_ROWS
from (
select table_name, count(*) as table_num
from SYS_DICT_ITEM
group by table_name
order by table_name
) t1
left join
(
select table_name,TABLE_ROWS
from information_schema.TABLES
where TABLE_SCHEMA = 'shscnq_st'
) t2
on t1.table_name = t2.table_name
通过执行 “建表语句SQL”和“插入语句SQL”,就能得到各个字典表的建表语句和插入语句,执行之后,所有字典表都能生成了。如果要验证字典的表字典条数和实际生成的字典表条数,可以用“表条数验证”来验证。



















 5102
5102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











