







 本文主要介绍了神经网络优化的基础知识,包括梯度下降法、优化算法的选择及其工作原理,为后续深入学习和实践神经网络调优奠定基础。
本文主要介绍了神经网络优化的基础知识,包括梯度下降法、优化算法的选择及其工作原理,为后续深入学习和实践神经网络调优奠定基础。
| //李宏毅视频官网:http://speech.ee.ntu.edu.tw/~tlkagk/courses.html 点击此处返回总目录 //邱锡鹏《神经网络与深度学习》官网:https://nndl.github.io
现在要讲几个deep learning的tips。
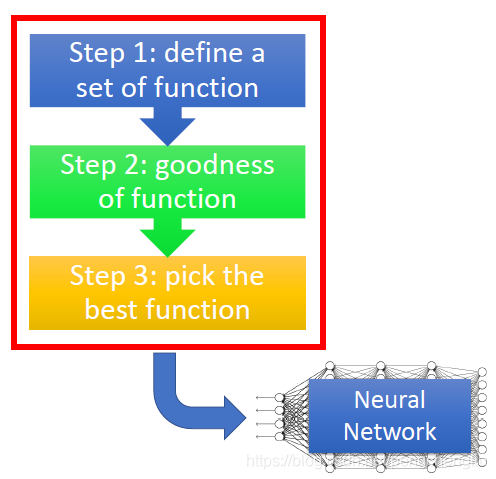
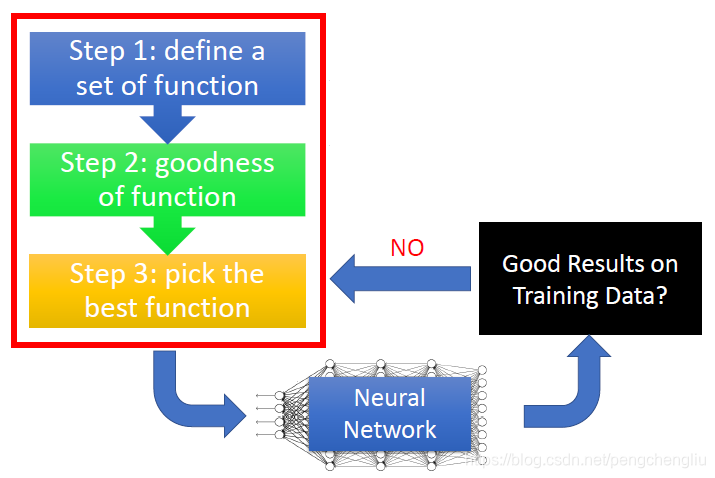
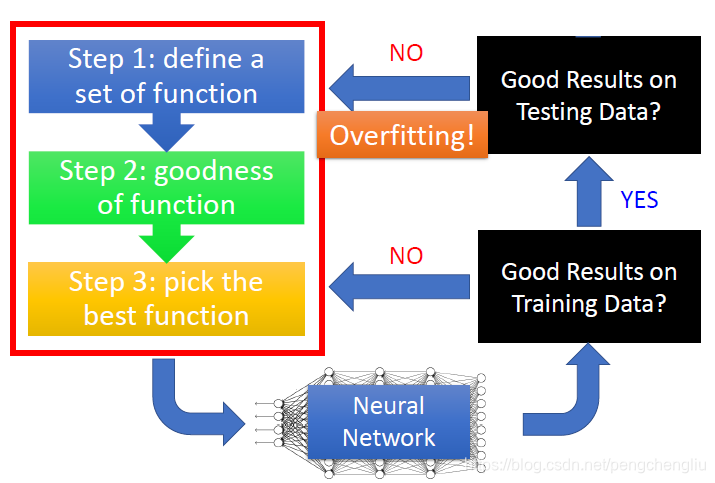
最重要的观念是深度学习的流程,如果在训练一个深度学习的网络时,他的流程应该是什么样子。 我们知道,deep learning是三个steps。做完这些以后,会得到一个learn好的神经网络。 接下来你要做什么样的事情呢? 首先要看,这个网络在你training data上有没有得到好的结果,如果没有的话,你就回头去看看三个steps里面是不是哪一个出了问题,可以做什么样的修改,让你在training set上能够得到好的结果。 先检查training data performance其实是一个deep learning非常unique的地方。像其他的方法,比如k近邻、决策树这种方法,做完以后,其实不太会想要检查training set的结果,因为在training set上的performance 正确率就是100。做完决策树,做完K近邻,正确率就是100,没有什么好检查的。所以有人说deep learning,看这个参数这么多,看起来很容易overfitting。我跟你讲,deep learning才不容易overfitting。我们说的overfitting就是在training set上performance很好,在testing set上performance没有那么好。 像k近邻、决策树在training data上正确率都是100,才是非常容易overfitting。而对deeping learning来说,不是说deep learning不会遇到overfitting的问题,而是overfitting不是你第一个遇到的问题。你第一个会遇到的问题是说,你在training的时候,他有可能在training set上根本没有办法给你一个好的正确率。 假设现在幸运地是,你已经在training set上得到好的performance。虽然得到100%的正确率没那么容易,但有可能你已经得到99.8%的正确率了。接下来呢,你要把你的网络apply到testing set上,testing set上的performance才是我们最后真正关心的performance。在testing set上的performance怎么样呢?如果现在得到的结果是No的话,那就是overfitting。你要回头做某些事情,解决overfitting这个问题。但有时候,你加了新的策略,去解决overfitting这个问题的时候,你其实反而会让training set上的结果反而变坏了。所以做完了修改之后,要回头去检查training set上的结果是怎么样的。如果training set上的结果变坏了的话,要从头对3个step做调整。
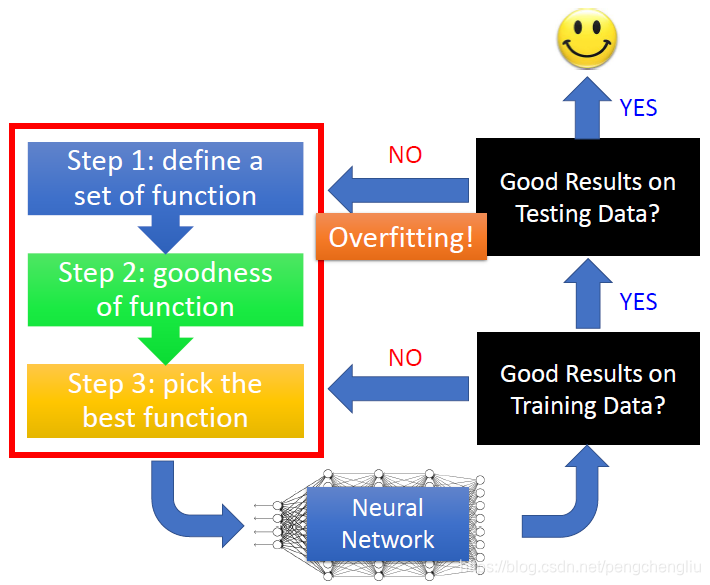
如果同时在training set和testing set上都得到好的结果的话,最后你就可以把你的系统用在真正的应用上面,你就成功了。
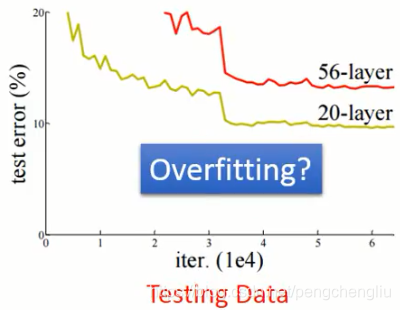
----------------------------------------------------------------------------------------------------------------------- 这边有一个重点就是,不要看到所有不好的performance就说是overfitting。 举例来说,下面是文献上的图,我在现实生活中也常常看到这样的状况。这个是testing data 上的结果,横坐标是参数更新的次数,纵坐标是error rate,越低越好。如果我们现在比较一个20层的网络和一个56层的网络,你会发现,56层的网络它的error rate比较高,它的performance比较差,而20层的网络它的表现是比较好的。 有些人看到这个图,就会得到结论说,56层参数太多了,56层果然没有必要,这个是overfitting。但是真的是这样子么?
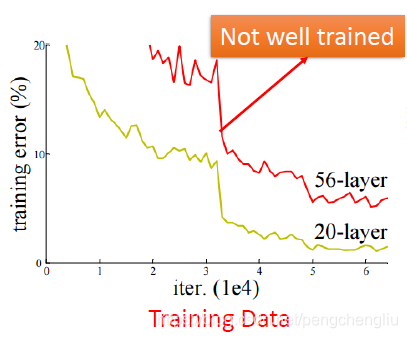
当在说现在的结果是overfitting之前,你要先检查一下,你在training set上的结果。对某些方法来说你不用检查这件事,比如k近邻、决策树。但是对神经网络来说,你是需要检查这件事的。为什么呢? 因为有可能你在training set上得到的结果是这个样子的。横轴是更新参数的次数,纵轴是error rate。如果比较20层的网络和56层的网络,你会发现在training set上20层的网络的performance本来就比56层的好,56层的网络的performance是比较差的。那为什么会是这样子呢?在训练网络的时候,有太多太多的问题会让你的training的结果是不好的,比如说有local minimum的问题,有saddle point的问题,有plateau的问题等等,有种种的问题。所以有可能这个56层的网络,它train的时候,就卡在了一个local minimum的地方,它得到了一个差的参数。所以这个并不是overfitting,是在training的时候就没有train好。
有人会说,这个叫做underfitting。我觉得可能不叫underfitting,但这只是名次定义的问题,所以你要怎么说都行。但是,在我心里面,underfitting意思是这个model的参数不够多,所以它的capacity不足以解除这个问题。但是对于这个56层的网络来说,虽然得到比较差的performance,但是它其实是在20层网络后面再堆另外36层的网络,它的参数其实是比20层的网络还多。理论上,20层的网络能做的事情,56层的网络一定能够做到。只要前面20层做跟20层的网络一样的事情,后面36层就啥事也不干就好了。明明可以做到20层的事情,为什么做不到呢?但是因为很多问题,让你没有办法做到。所以这个56层的网络差,并不是因为能力不够,就是没有train好。我还不知道用什么名字来说这个问题。
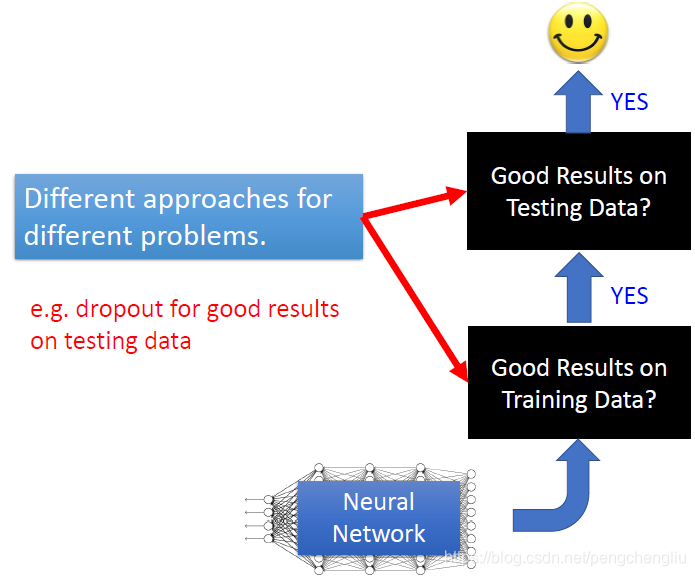
所以呢,在deep learning的文件上,当你读到一个方法的时候,你永远要想一下,这个方法它是要解决什么样的问题。因为在deep learning里面有两个问题:一个是training set上的performance不好,一个是在testing set的performance不好。当提出了一个方法的时候,它往往就是针对这两个问题的其中一个做处理。举例来说,dropout方法。很多人一看到performance不好,就apply dropout。但是,你要仔细想一下,dropout方法是什么时候用的,dropout是你在testing data上的结果不好的时候,你才会使用。在testing set上的结果好的时候,是不会用dropout的。如果今天的问题是,你在training set上不好,使用dropout,只会那越训练越差。所以,不同的方法对治什么样的症状,必须要在心里想清楚。
|


















 9513
9513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









