




 MNIST 是一个广泛使用的手写数字识别数据集,包含60,000个训练样本和10,000个测试样本。每个样本是28x28像素的灰度图像,用于机器学习和深度学习中的图像分类任务。这个数据集常被用来入门神经网络和图像识别技术,是评估不同算法性能的标准基准之一。"
125029623,7924214,理解Kafka:核心概念与特性解析,"['大数据', '消息中间件', '实时处理', 'Kafka']
MNIST 是一个广泛使用的手写数字识别数据集,包含60,000个训练样本和10,000个测试样本。每个样本是28x28像素的灰度图像,用于机器学习和深度学习中的图像分类任务。这个数据集常被用来入门神经网络和图像识别技术,是评估不同算法性能的标准基准之一。"
125029623,7924214,理解Kafka:核心概念与特性解析,"['大数据', '消息中间件', '实时处理', 'Kafka']
| 一、MNIST数据集介绍 点击此处返回总目录 二、MNIST数据集下载 三、常用的操作
一、MNIST数据集介绍 共有7万张图片。其中6万张用于训练神经网络,1万张用于测试神经网络。 每张图片是一个28*28像素点的0~9的手写数字图片。 黑底白字。黑底用0表示,白字用0~1之间的浮点数表示,越接近1,颜色越百。
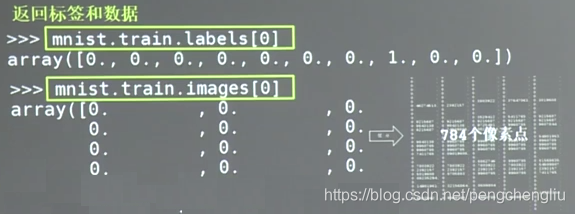
我们把784个像素点组成一个长度为784的一维数组,这个一维数据就是我们要喂入神经网络的输入特征。MNIST数据集还提供了每张图片对应的标签,以一个长度为10的一维数组给出。
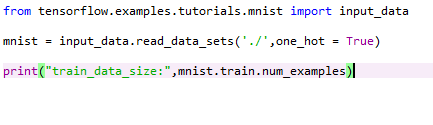
二、MNIST数据集下载 TensorFlow官方提供了input_data模块,input_data模块使用read_data_sets()函数自动加载数据集。函数第一个参数,是数据集存放路径。第二个参数one_hot=True表示以独热码的形式存取。 当函数运行时,会自动检查存放路径下是否有该数据集,如果没有,会自动下载MNIST数据集,并分为Train、Validation、Test三个子集。
我们的程序使用子集Train训练模型参数,使用子集Test测试模型准确率。
【注意】 有可能会报错,下不下来。那怎么办呢? 1.到下面这个网址,手动下载4个文件。 地址:http://yann.lecun.com/exdb/mnist/ 下载: 2. 将这4个压缩文件,放到与"dataset.py"同级的目录下: 其中,文件名叫"dataset.py",如果改成其他文件名,可能不行。比如我之前写了个"aaa.py"就不行,改成“dataset.py”就行。
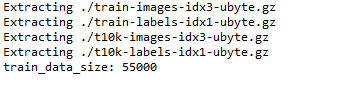
3. 编写dataset.py,内容为: 4. 运行py程序,可以看到成功导入了数据集。
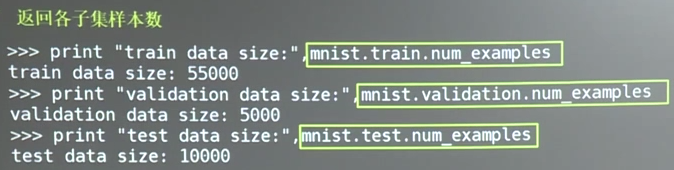
三、常用的操作 我们可以用mnist.train.num_examples、mnist.validation.num_examples、minst.test.num_examples三个分别打印出训练集、验证集、测试集所含有的样本数。
可以用mnist.train.labels[i]、mnist.train.images[i]查看训练集中指定编号的标签或者图片。labels[0]表示第0张图的标签,images[0]表示第0张图的784个像素点。
例:
运行结果: Extracting ./train-images-idx3-ubyte.gz
当定义好每轮输入的一小撮数据大小后(即BATCH_SIZE),可以使用mnist.train.next_batch(BATCH_SIZE)从训练集中随机抽取BATCH_SIZE组数据和标签,分别赋值给xs和ys。打印xs的形状,为200行,每行784个像素点,为输入的特征。打印ys的形状,为200行,每行10个数字。
我们记几个函数:
tf.get_collection("") 会从collection的集合中,取出全部变量,生成一个列表。 tf.add_n([]) 会把列表内的所有元素相加。 tf.cast(x,dtype) 会把x转换为指定类型。 tf.argmax(x,axis) 会返回axis指定的维度中,x最大值对应的索引号。这个x是个列表。比如tf.argmax([1,0,0],1)表示在第一个维度,找最大值的索引号。 os.path.join()是os模块的函数,这个函数可以把字符串按照路径的命名规则进行拼接。 字符串.split()用于字符串切分。 with tf.Graph().as_default() as g: 表示在其内定义的节点在计算图g中。一般用这种方法复现已经定义好的神经网络。网络做应用时,我们会用这种方法把神经网络复现到计算图。
我们说一下模型的保存和加载。
在反向传播中,如果想每隔一定轮数把模型保存下来,需要加上两句话。 首先是实例化saver对象。然后在with结构中,每隔一定轮数,把当前会话的参数等信息保存到MODEL_SAVE_PATH/MODEL_NAME这个路径,并在文件尾加上当前的训练轮数。
加载模型的时候,在with结构中加载ckpt,如果ckpt和模型存在,则用saver.restore()把模型参数加载到当前会话中。
如果训练过程中,使用过滑动平均,每个参数的滑动平均值也会被保存到模型中。我们使用模型识别图片时,更希望加载参数的滑动平均值,用这样三句话,实例化可以还原滑动平均值的saver对象。这样在运行加载模型的参数时,每个参数就会加载各自的滑动平均值了。
在手写数字的识别中,我们用这个方法评估模型的准确性。y是神经网络喂入的BATCH_SIZE的数据后的结果,是BATCH_SIZE*10的二维数组,每一行表示一轮BATCH前向传播的结果。tf.argmax(y,1)的第二个参数1,表示选取最大值的操作仅在第1个维度进行,也就是,返回每一行最大值所对应的列表索引号。tf.argmax(y,1)会得到一个长度为BATCH的一维数组,这个一维数组中的值就表示了每一轮样本推算出的数字识别结果。tf.equal()判断两个张量中每一维是否相等,如果相等返回True,否则返回False。 tf.cast(corect_prediction,tf.float32)将boolean型转换成实数型。然后计算平均值。这个平均值就是模型在这一组数据上的准确率。
|


























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









