




 本文介绍了SegNet模型,重点阐述了其基于VGG16的编码器网络和对称的解码器网络在语义分割任务中的关键作用,包括特征提取、池化索引保存和解码过程。通过实例展示了SegNet在CamVid和SUNRGB-D数据集上的优势,以及模型在速度上的优化。
本文介绍了SegNet模型,重点阐述了其基于VGG16的编码器网络和对称的解码器网络在语义分割任务中的关键作用,包括特征提取、池化索引保存和解码过程。通过实例展示了SegNet在CamVid和SUNRGB-D数据集上的优势,以及模型在速度上的优化。
语义分割
语义分割的目的是对图像中每一个像素点进行分类,与普通的分类任务只输出某个类别不同,语义分割任务输出是与输入图像大小相同的图像,输出图像的每个像素对应了输入图像每个像素的类别。

图像语义分割就是机器自动分割并识别出图像中的内容,比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车,黑色表示背景。
网络模型
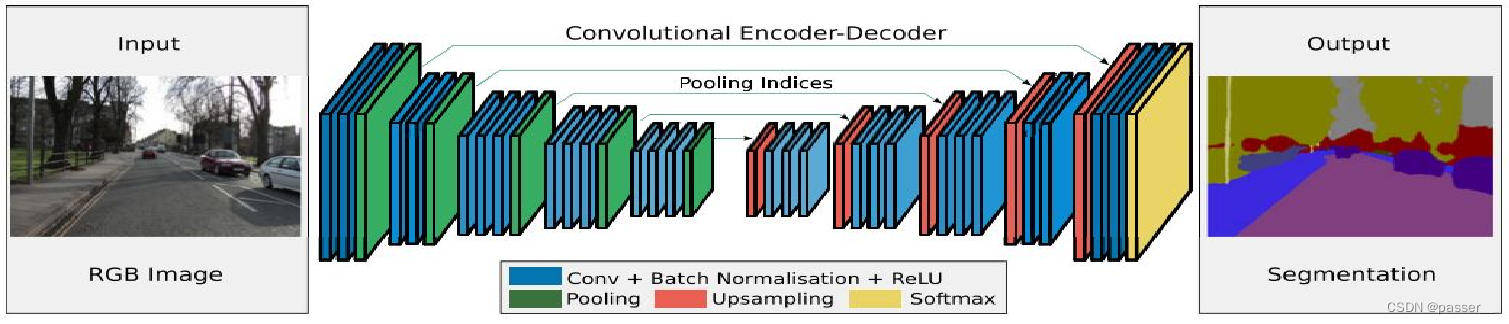
SegNet 其核心的训练引擎包含一个Encoder网络(采用VGG16,移除全连接层 ,和FCN一样),和一个对称的Decoder网络,即编码器-解码器结构,并跟随一个用于pixel-wise的分类层
编码器
-
在编码器处,执行卷积和最大池化。
-
VGG16 有 13 个卷积层,将原始的全连接层被替换成解码器。
-
在每个卷积层后添加BatchNormalization层。
-
在进行 2×2 最大池化时,会存储相应的最大池化索引(位置),用于解码器的反池化操作。
解码网络中复用max-pooling indics的好处:
-
改善了边界划分
-
减少了端到端训练的参数量
-
仅需要少量的修改而可合并到任何编码-解码形式的架构
解码器
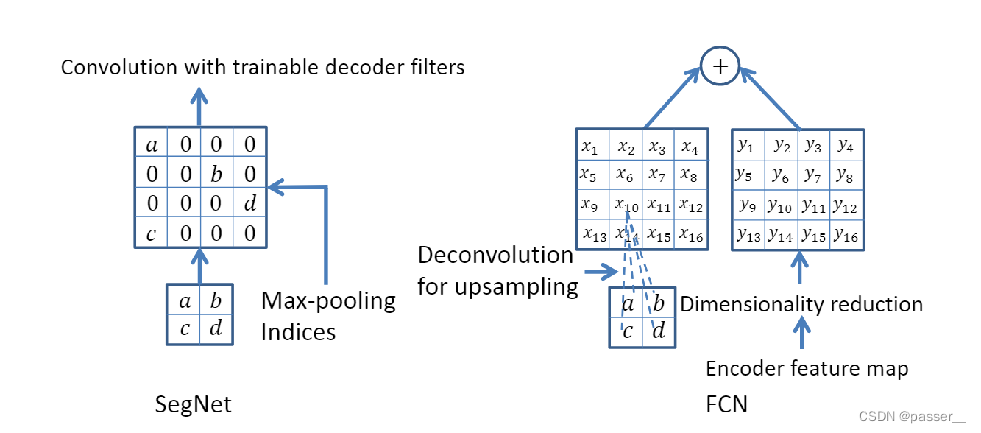
在解码器中主要是用到了编码器中存储的max_pooling的indicate的一些坐标,这样可以不需要通过计算就恢复出来一个尺寸更大的输入图。相对于转置卷积会减少很多的计算量。
总结
在CamVid(室外)上与传统方法相比:
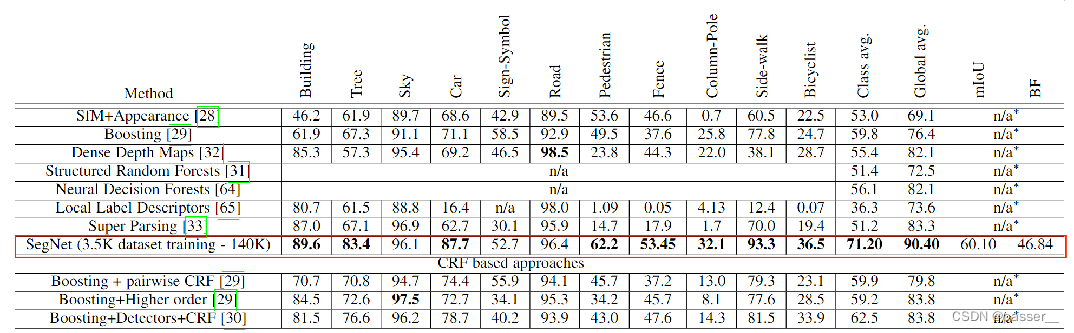
可以通过图像对比发现SegNet在很多种类上都是处于领先的正确率的水平。
在CamVid上与其他深层网络对比:

在SUN RGB-D(场景理解)上与其他深层网络相比:
模型时间和推断时间进行对比:


















 1565
1565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









