




 本文介绍了MobileNet系列网络,包括V1的Depthwise Convolution,V2的Inverted Residuals和线性瓶颈,以及V3的Block更新和激活函数设计。MobileNet系列在网络结构优化和轻量化方面做出了重大贡献。此外,针对高光谱图像处理,提出了HybridSN模型,结合3D和2D卷积,有效利用光谱和空间信息,提高处理效率。模型经过训练,显示出良好的分类性能。
本文介绍了MobileNet系列网络,包括V1的Depthwise Convolution,V2的Inverted Residuals和线性瓶颈,以及V3的Block更新和激活函数设计。MobileNet系列在网络结构优化和轻量化方面做出了重大贡献。此外,针对高光谱图像处理,提出了HybridSN模型,结合3D和2D卷积,有效利用光谱和空间信息,提高处理效率。模型经过训练,显示出良好的分类性能。
第4周学习:MobileNetV1, V2, V3
Part1 论文阅读与视频学习:
MobileNet V1
传统卷积神经网络,内存需求大、运算量大 导致无法在移动设备以及嵌入式设备上运行。MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入
式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降
低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,
但模型参数只有VGG的1/32)
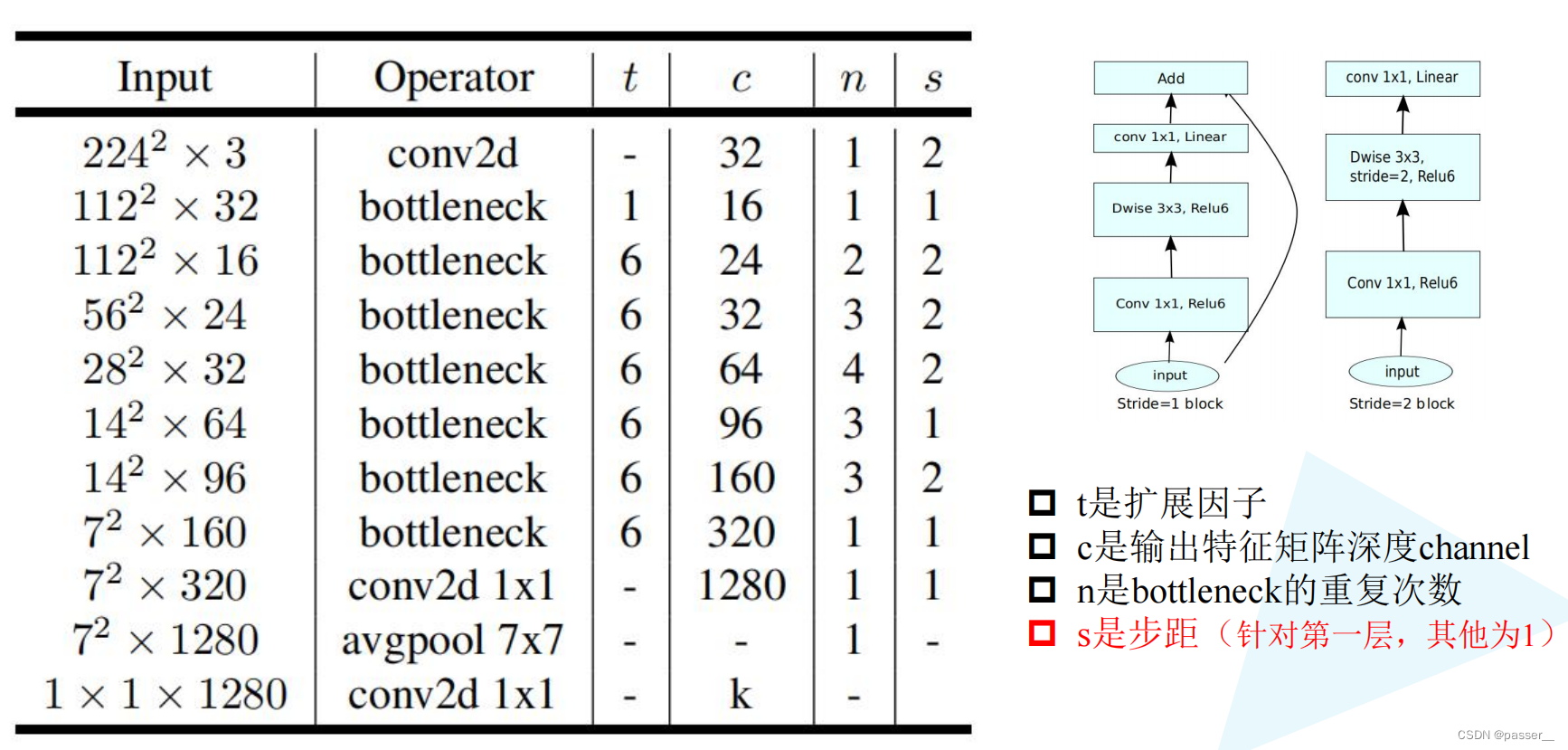
MobileNet V1结构如下:
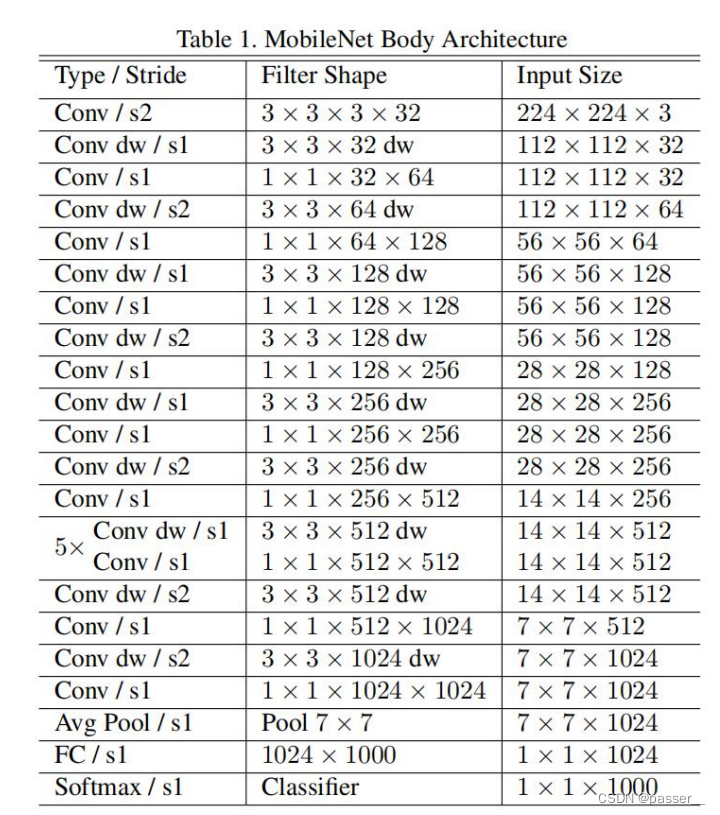
MobileNet V1网络中的亮点:
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数α、β
Depthwise Convolution和传统卷积的区别
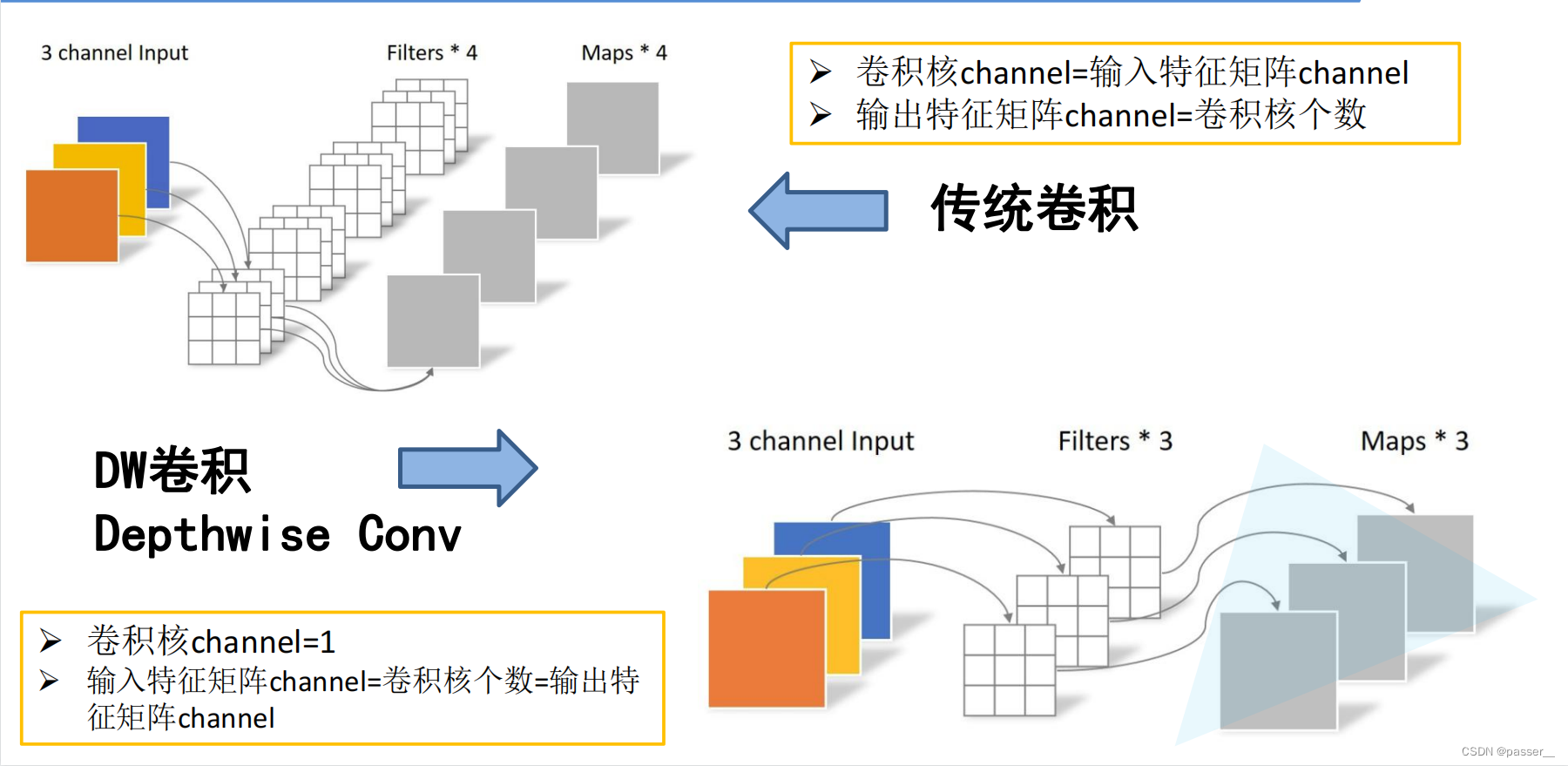
MobileNet V1网络把普通的卷积分解为两步来做,第一步DW,第二部PW
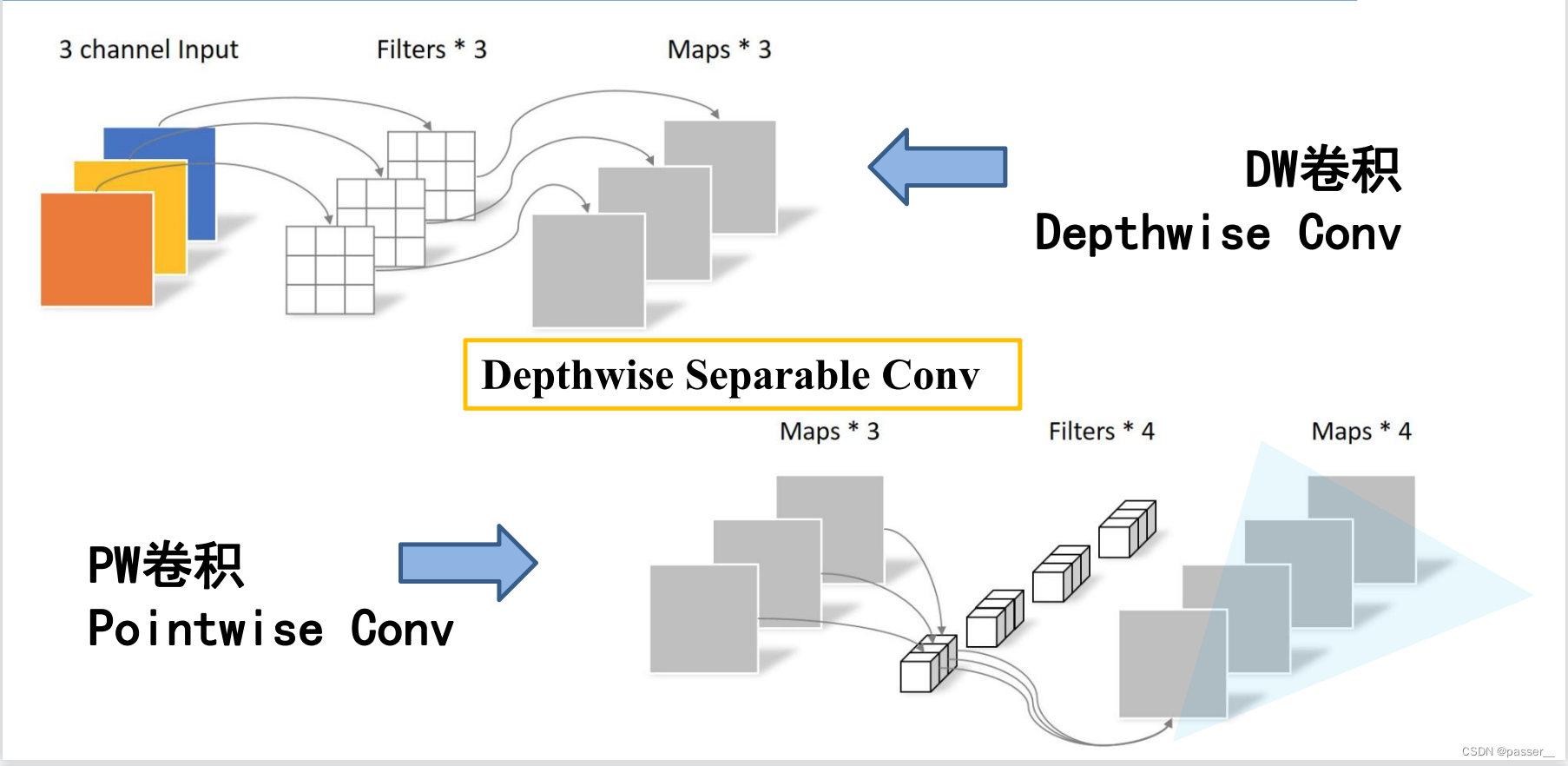
MobileNet V2
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网
络,准确率更高,模型更小
MobileNet v2网络中的亮点:
- Inverted Residuals (倒残差结构)
- Linear Bottlenecks
传统残差结构和倒残差结构的对比:
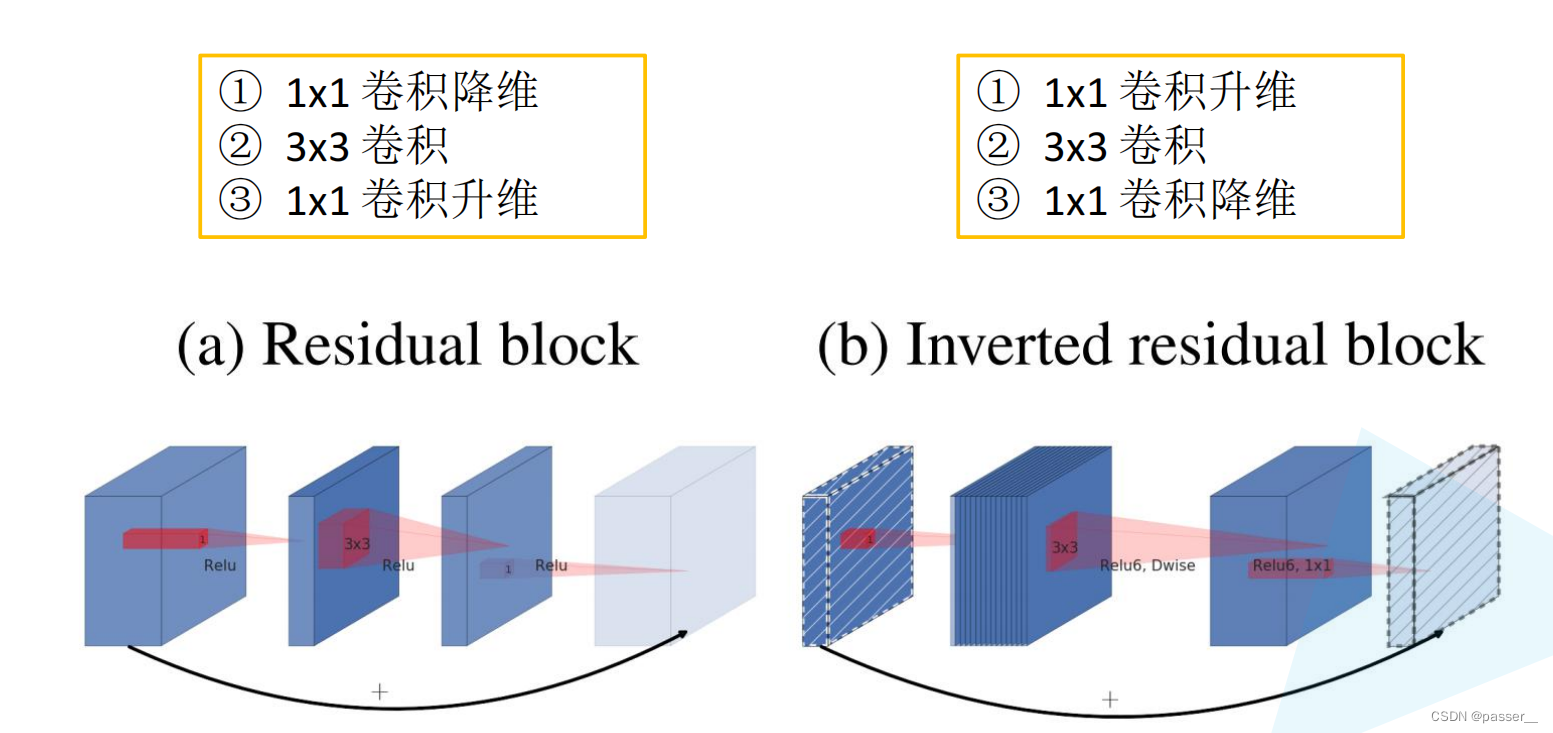
使用了新的激活函数 Relu6.
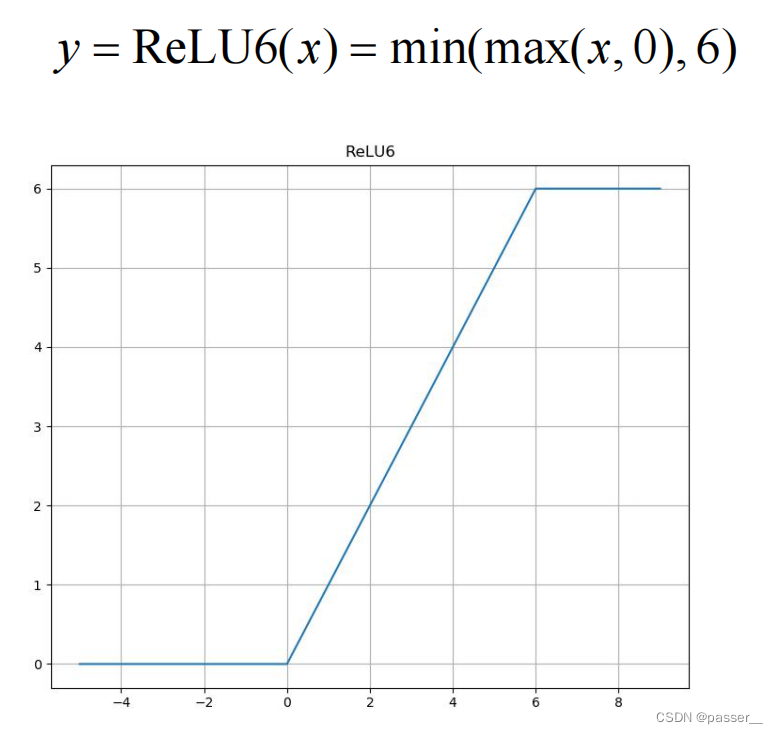
通过大量的炼丹发现ReLU激活函数对低维特征信息照成大量损失,所以改用线性的Linear Bottlenecks

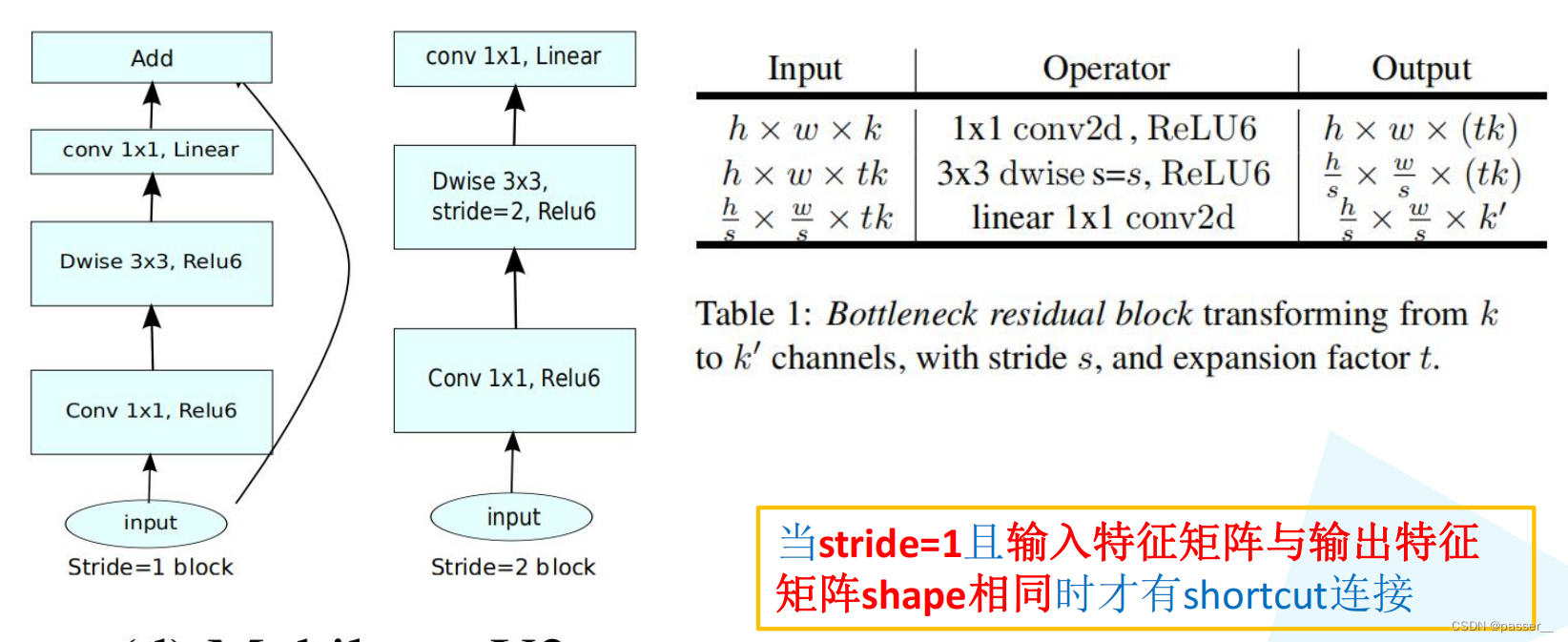
倒残差结构并不是所有的都需要加shorcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接,所以对于n>=2的时候,才会有shorcut,因为经过bottleneck之后的维度已经发生改变,但是再经历重复的bottleneck的时候输入和输出的维度是一致的所以可以利用shorcut连接。
MobileNet V3
MobileNet v3网络中的亮点:
- 更新Block(bneck)
- 使用NAS搜索参数(Neural Architecture Search)
- 重新设计耗时层结构
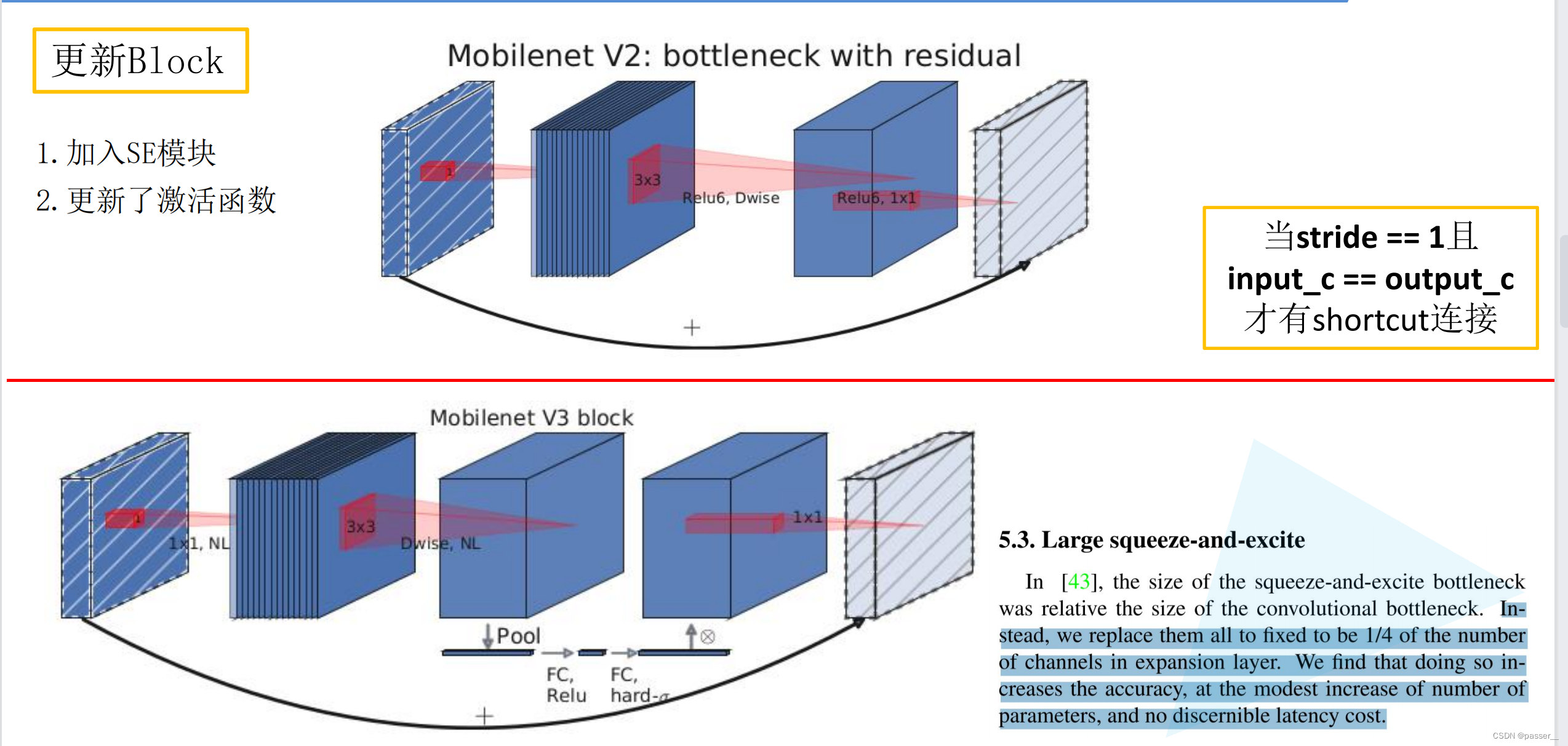
更新Block(bneck)
在倒残差结构的基础上加入了SE模块,更新了激活函数,同时在不同层的激活函数不同。
重新设计耗时层结构
- 减少第一个卷积层的卷积核个数(32->16)
- 精简Last Stage
优化前后结构对比: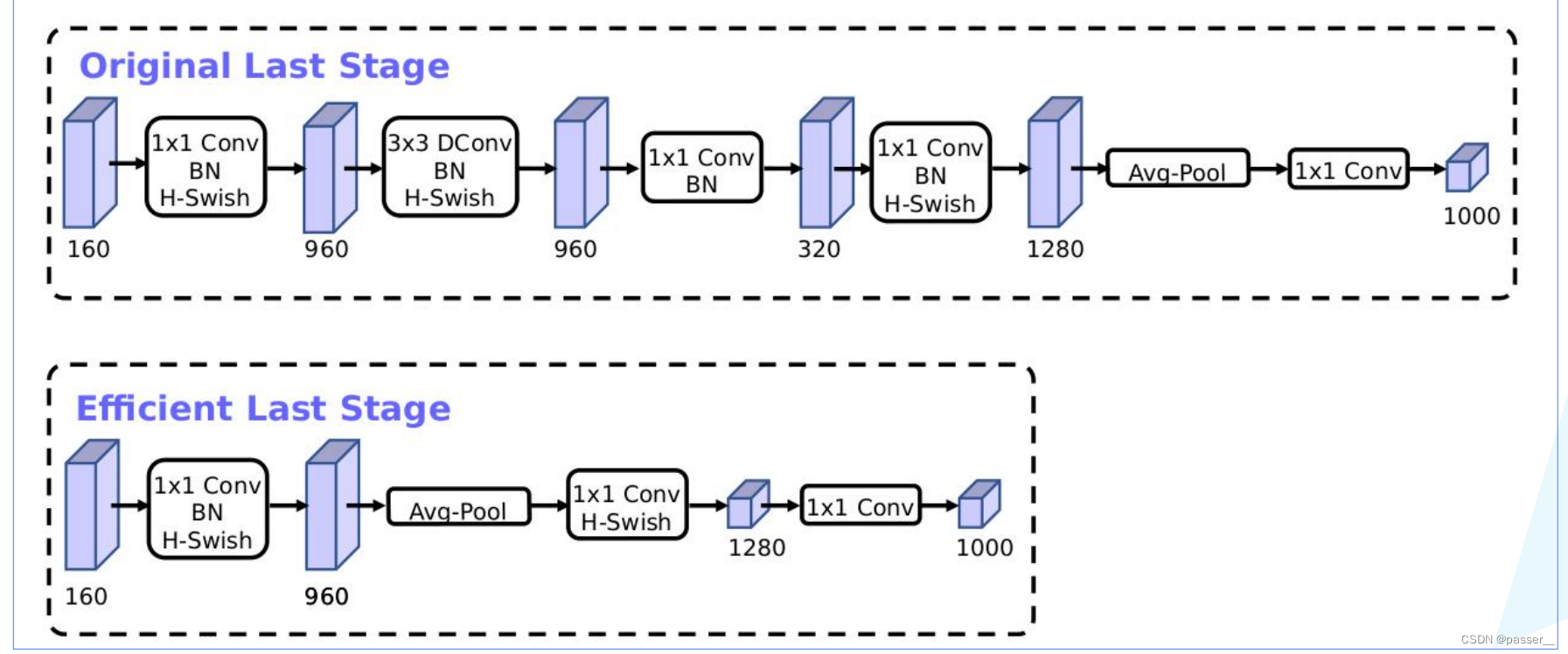
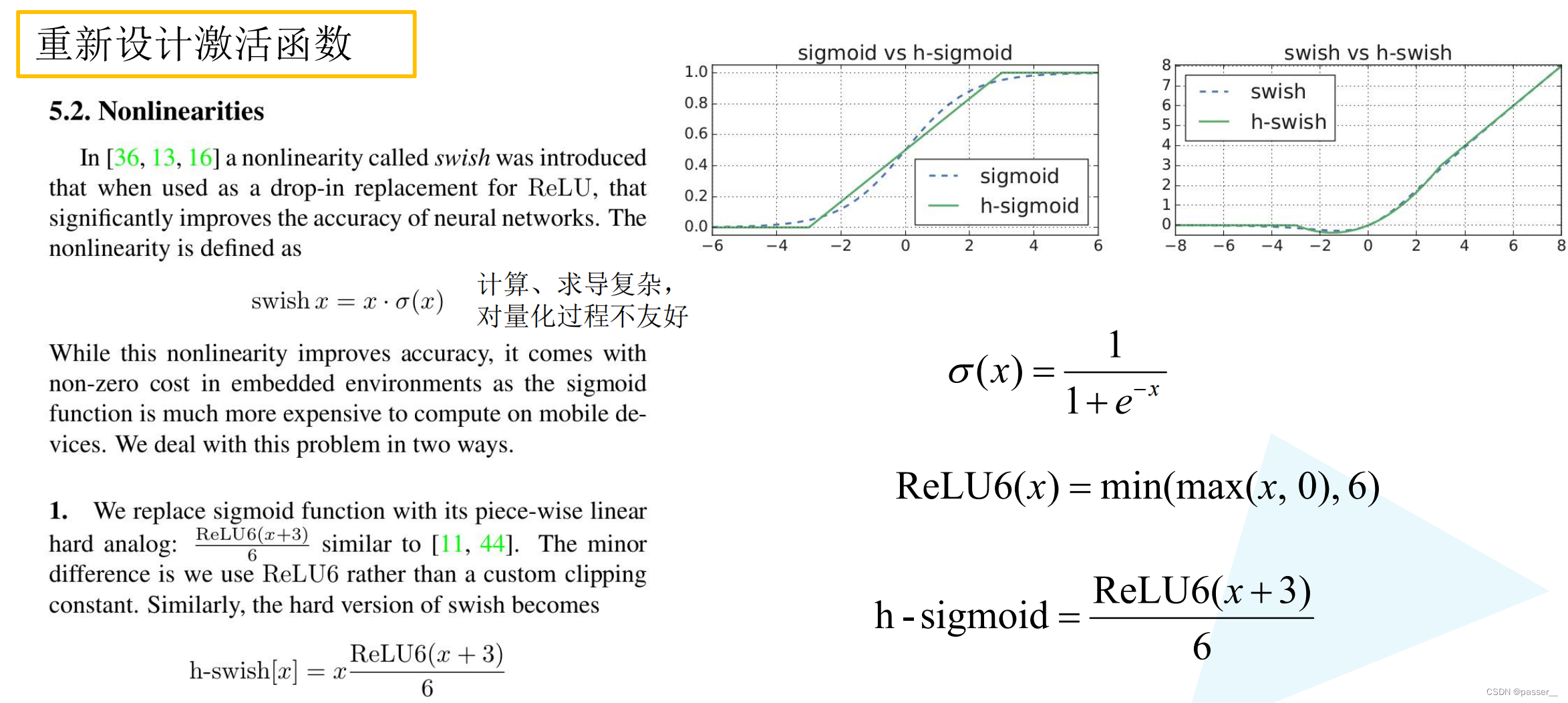
重新设计激活函数
SeNet
SE模块如下图所示:
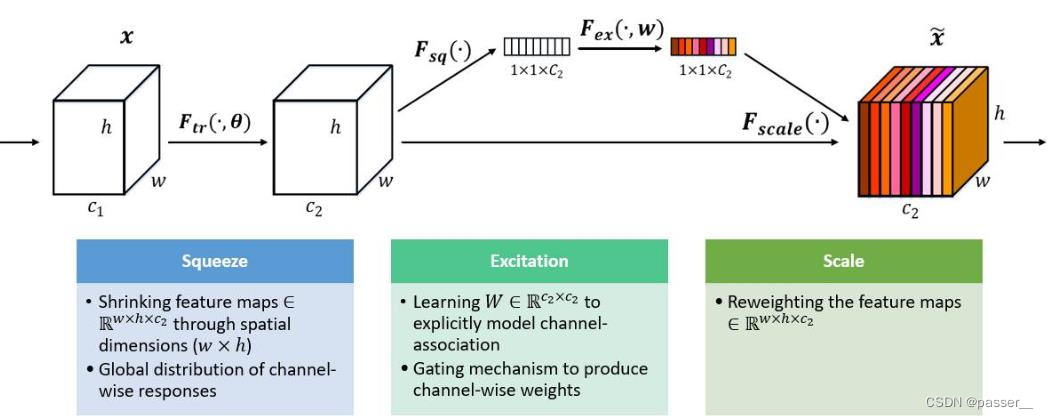
SeNet操作顺序:
- Squeeze 操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,表征着在特征通道上响应的全局分布
- Excitation 操作,类似于循环神经网络门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。(这里是两个全连接层)
- Reweight 的操作,将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道上对原始特征的重标定。
左图SE模块嵌入到Inception结构,右图将SE 嵌入到ResNet模块中: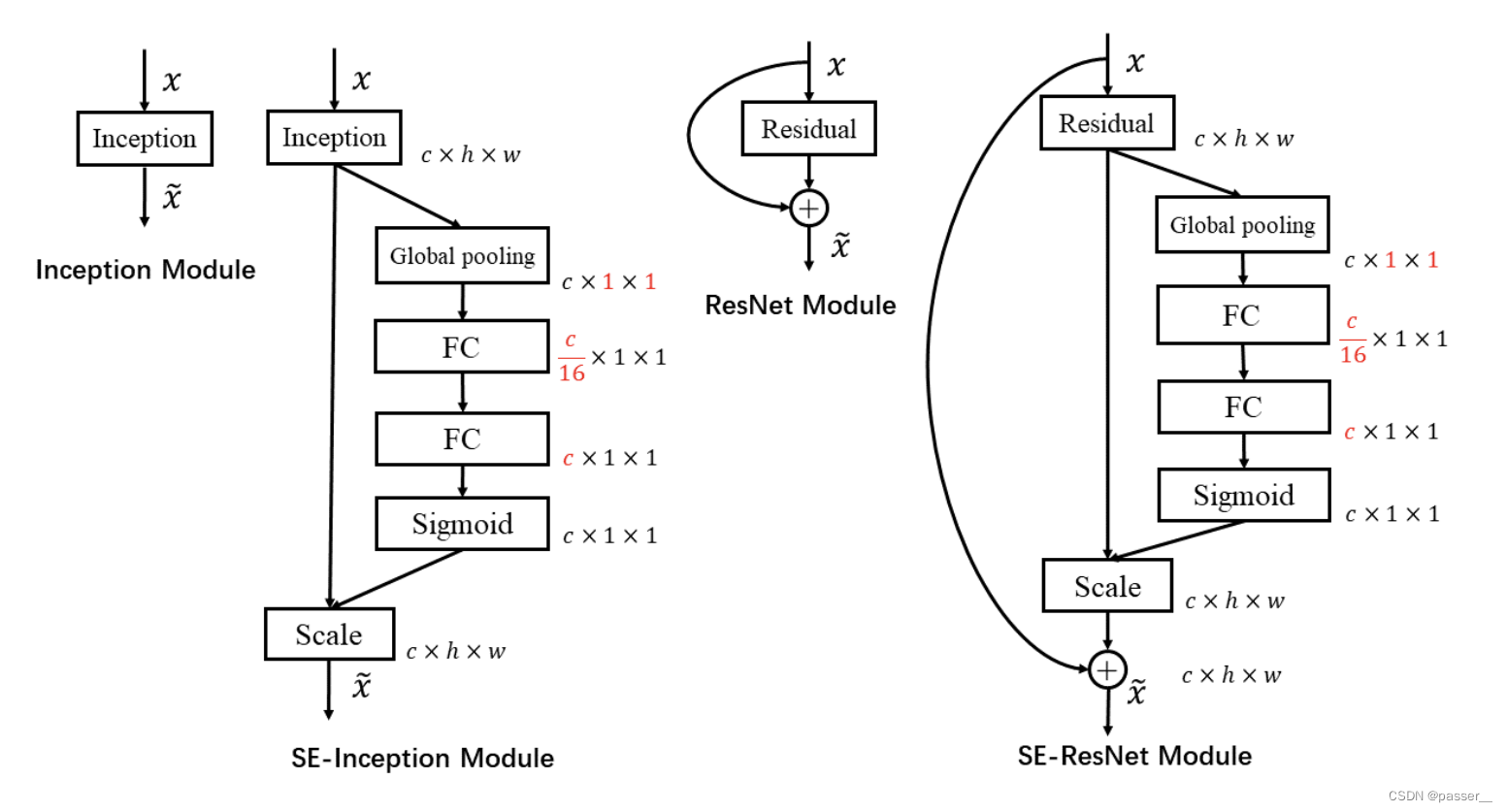
SENet构造非常简单,而且很容易被部署,不需要引入新的函数或者层。除此之外,它还在模型和计算复杂度上具有良好的特性。
Part2 代码作业:
对于卷积网络,处理高光谱图像时,会有一些技术问题:
- 2-D-CNN无法处理数据的第三维度——光谱信息(前两维度是图像本身的x轴和y轴)
- 传统的2D-卷积处理不好这种三维的高光谱图像
- 若只使用3D-卷积,虽然可以提取第三维——光谱维度的特征,能同时进行空间和空间特征表示,但数据计算量特别大,且对特征的表现能力比较差(因为许多光谱带上的纹理是相似的)
所以,作者提出HybirdSN模型(全称是Hybrid SpectralNet——我大致翻译为:混合了2D、3D卷积的光谱网络):将空间光谱和光谱的互补信息分别以3D-CNN和2D-CNN层组合到了一起,从而充分利用了光谱和空间特征图,来克服以上缺点。HybirdSN模型比3D-CNN模型的计算效率更高。在小的训练数据上也显示出了优越的性能。
定义 HybridSN 类
模型的网络结构为如下图所示:
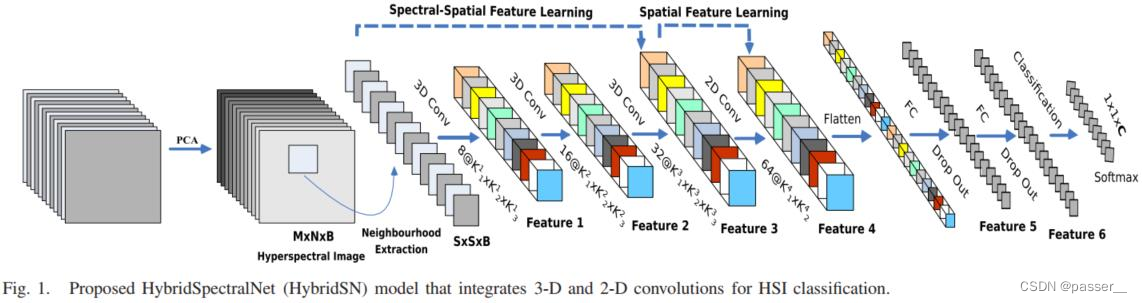
三维卷积部分:
- conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
HybridSN 类:
from torch.nn.modules.activation import ReLU
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv3d(in_channels=1, out_channels=8, kernel_size=(7, 3, 3)),
nn.BatchNorm3d(8),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv3d(in_channels=8, out_channels=16, kernel_size=(5, 3, 3)),
nn.BatchNorm3d(16),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv3d(in_channels=16, out_channels=32, kernel_size=(3, 3, 3)),
nn.BatchNorm3d(32),
nn.ReLU(inplace=True)
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=576, out_channels=64, kernel_size=(3, 3)),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.fc1 = nn.Linear(in_features=18496, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=128)
self.fc3 = nn.Linear(in_features=128, out_features=class_num)
self.drop = nn.Dropout(p=0.4)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = out.reshape(out.shape[0], -1, 19, 19)
out = self.conv4(out)
out = out.reshape(out.shape[0],-1)
out = F.relu(self.drop(self.fc1(out)))
out = F.relu(self.drop(self.fc2(out)))
out = self.fc3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
开始训练
[Epoch: 1] [loss avg: 20.1837] [current loss: 2.1699]
[Epoch: 2] [loss avg: 16.5647] [current loss: 1.3456]
[Epoch: 3] [loss avg: 14.0039] [current loss: 0.9215]
[Epoch: 4] [loss avg: 11.9883] [current loss: 0.5639]
[Epoch: 5] [loss avg: 10.3622] [current loss: 0.5434]
[Epoch: 6] [loss avg: 9.1040] [current loss: 0.3172]
[Epoch: 7] [loss avg: 8.1050] [current loss: 0.2468]
[Epoch: 8] [loss avg: 7.2796] [current loss: 0.0851]
[Epoch: 9] [loss avg: 6.5843] [current loss: 0.1613]
[Epoch: 10] [loss avg: 6.0362] [current loss: 0.0942]
[Epoch: 11] [loss avg: 5.5672] [current loss: 0.1328]
[Epoch: 12] [loss avg: 5.1621] [current loss: 0.1088]
[Epoch: 13] [loss avg: 4.8150] [current loss: 0.0686]
[Epoch: 14] [loss avg: 4.5110] [current loss: 0.0537]
[Epoch: 15] [loss avg: 4.2453] [current loss: 0.1282]
[Epoch: 16] [loss avg: 4.0101] [current loss: 0.0515]
[Epoch: 17] [loss avg: 3.7989] [current loss: 0.1051]
[Epoch: 18] [loss avg: 3.6087] [current loss: 0.0348]
[Epoch: 19] [loss avg: 3.4343] [current loss: 0.0130]
[Epoch: 20] [loss avg: 3.2741] [current loss: 0.0388]
[Epoch: 21] [loss avg: 3.1271] [current loss: 0.0113]
[Epoch: 22] [loss avg: 2.9975] [current loss: 0.0174]
[Epoch: 23] [loss avg: 2.8807] [current loss: 0.0718]
[Epoch: 24] [loss avg: 2.7721] [current loss: 0.0236]
[Epoch: 25] [loss avg: 2.6727] [current loss: 0.0890]
[Epoch: 26] [loss avg: 2.5802] [current loss: 0.0370]
[Epoch: 27] [loss avg: 2.4916] [current loss: 0.0338]
[Epoch: 28] [loss avg: 2.4095] [current loss: 0.0378]
[Epoch: 29] [loss avg: 2.3295] [current loss: 0.0145]
[Epoch: 30] [loss avg: 2.2549] [current loss: 0.0391]
[Epoch: 31] [loss avg: 2.1854] [current loss: 0.0048]
[Epoch: 32] [loss avg: 2.1215] [current loss: 0.0242]
[Epoch: 33] [loss avg: 2.0598] [current loss: 0.0199]
[Epoch: 34] [loss avg: 2.0028] [current loss: 0.0310]
[Epoch: 35] [loss avg: 1.9494] [current loss: 0.0516]
[Epoch: 36] [loss avg: 1.8992] [current loss: 0.0268]
[Epoch: 37] [loss avg: 1.8536] [current loss: 0.0666]
[Epoch: 38] [loss avg: 1.8137] [current loss: 0.0623]
[Epoch: 39] [loss avg: 1.7712] [current loss: 0.0044]
[Epoch: 40] [loss avg: 1.7316] [current loss: 0.0288]
[Epoch: 41] [loss avg: 1.6927] [current loss: 0.0091]
[Epoch: 42] [loss avg: 1.6545] [current loss: 0.0193]
[Epoch: 43] [loss avg: 1.6208] [current loss: 0.0340]
[Epoch: 44] [loss avg: 1.5910] [current loss: 0.0532]
[Epoch: 45] [loss avg: 1.5611] [current loss: 0.0358]
[Epoch: 46] [loss avg: 1.5335] [current loss: 0.0540]
[Epoch: 47] [loss avg: 1.5049] [current loss: 0.0162]
[Epoch: 48] [loss avg: 1.4794] [current loss: 0.0838]
[Epoch: 49] [loss avg: 1.4518] [current loss: 0.0038]
[Epoch: 50] [loss avg: 1.4279] [current loss: 0.0176]
[Epoch: 51] [loss avg: 1.4029] [current loss: 0.0392]
[Epoch: 52] [loss avg: 1.3789] [current loss: 0.0310]
[Epoch: 53] [loss avg: 1.3576] [current loss: 0.0889]
[Epoch: 54] [loss avg: 1.3381] [current loss: 0.1023]
[Epoch: 55] [loss avg: 1.3156] [current loss: 0.0078]
[Epoch: 56] [loss avg: 1.2943] [current loss: 0.0376]
[Epoch: 57] [loss avg: 1.2753] [current loss: 0.1190]
[Epoch: 58] [loss avg: 1.2550] [current loss: 0.0101]
[Epoch: 59] [loss avg: 1.2373] [current loss: 0.0424]
[Epoch: 60] [loss avg: 1.2176] [current loss: 0.0221]
[Epoch: 61] [loss avg: 1.2005] [current loss: 0.0024]
[Epoch: 62] [loss avg: 1.1835] [current loss: 0.0484]
[Epoch: 63] [loss avg: 1.1675] [current loss: 0.0575]
[Epoch: 64] [loss avg: 1.1505] [current loss: 0.0204]
[Epoch: 65] [loss avg: 1.1334] [current loss: 0.0082]
[Epoch: 66] [loss avg: 1.1170] [current loss: 0.0009]
[Epoch: 67] [loss avg: 1.1006] [current loss: 0.0043]
[Epoch: 68] [loss avg: 1.0860] [current loss: 0.0004]
[Epoch: 69] [loss avg: 1.0706] [current loss: 0.0059]
[Epoch: 70] [loss avg: 1.0572] [current loss: 0.0766]
[Epoch: 71] [loss avg: 1.0433] [current loss: 0.0097]
[Epoch: 72] [loss avg: 1.0302] [current loss: 0.0057]
[Epoch: 73] [loss avg: 1.0172] [current loss: 0.0186]
[Epoch: 74] [loss avg: 1.0037] [current loss: 0.0027]
[Epoch: 75] [loss avg: 0.9920] [current loss: 0.0293]
[Epoch: 76] [loss avg: 0.9827] [current loss: 0.1205]
[Epoch: 77] [loss avg: 0.9736] [current loss: 0.0104]
[Epoch: 78] [loss avg: 0.9635] [current loss: 0.0020]
[Epoch: 79] [loss avg: 0.9535] [current loss: 0.0142]
[Epoch: 80] [loss avg: 0.9435] [current loss: 0.0404]
[Epoch: 81] [loss avg: 0.9330] [current loss: 0.0010]
[Epoch: 82] [loss avg: 0.9244] [current loss: 0.0695]
[Epoch: 83] [loss avg: 0.9141] [current loss: 0.0162]
[Epoch: 84] [loss avg: 0.9039] [current loss: 0.0079]
[Epoch: 85] [loss avg: 0.8937] [current loss: 0.0113]
[Epoch: 86] [loss avg: 0.8843] [current loss: 0.0133]
[Epoch: 87] [loss avg: 0.8758] [current loss: 0.0435]
[Epoch: 88] [loss avg: 0.8670] [current loss: 0.0104]
[Epoch: 89] [loss avg: 0.8590] [current loss: 0.0059]
[Epoch: 90] [loss avg: 0.8498] [current loss: 0.0073]
[Epoch: 91] [loss avg: 0.8410] [current loss: 0.0013]
[Epoch: 92] [loss avg: 0.8326] [current loss: 0.0072]
[Epoch: 93] [loss avg: 0.8243] [current loss: 0.0086]
[Epoch: 94] [loss avg: 0.8166] [current loss: 0.0053]
[Epoch: 95] [loss avg: 0.8114] [current loss: 0.0036]
[Epoch: 96] [loss avg: 0.8044] [current loss: 0.0547]
[Epoch: 97] [loss avg: 0.7970] [current loss: 0.0007]
[Epoch: 98] [loss avg: 0.7894] [current loss: 0.0009]
[Epoch: 99] [loss avg: 0.7821] [current loss: 0.0101]
[Epoch: 100] [loss avg: 0.7749] [current loss: 0.0076]
Finished Training
模型测试&生成报告
测试结果1:
precision recall f1-score support
0.0 0.9302 0.9756 0.9524 41
1.0 0.9903 0.9556 0.9727 1285
2.0 0.9840 0.9853 0.9846 747
3.0 0.9857 0.9718 0.9787 213
4.0 0.9905 0.9586 0.9743 435
5.0 0.9969 0.9711 0.9838 657
6.0 1.0000 1.0000 1.0000 25
7.0 0.9953 0.9907 0.9930 430
8.0 0.8000 0.8889 0.8421 18
9.0 0.9875 0.9943 0.9909 875
10.0 0.9687 0.9928 0.9806 2210
11.0 0.9595 0.9757 0.9675 534
12.0 0.9529 0.9838 0.9681 185
13.0 0.9861 0.9974 0.9917 1139
14.0 0.9828 0.9885 0.9856 347
15.0 0.9855 0.8095 0.8889 84
accuracy 0.9807 9225
macro avg 0.9685 0.9650 0.9659 9225
weighted avg 0.9810 0.9807 0.9806 9225
测试结果2:
precision recall f1-score support
0.0 0.9231 0.8780 0.9000 41
1.0 0.9188 0.9603 0.9391 1285
2.0 0.9510 0.9612 0.9561 747
3.0 0.9841 0.8732 0.9254 213
4.0 0.9813 0.9632 0.9722 435
5.0 0.9588 0.9909 0.9746 657
6.0 1.0000 0.9600 0.9796 25
7.0 0.9977 0.9884 0.9930 430
8.0 0.8333 0.8333 0.8333 18
9.0 0.9523 0.9817 0.9668 875
10.0 0.9807 0.9448 0.9624 2210
11.0 0.9550 0.9139 0.9340 534
12.0 0.9577 0.9784 0.9679 185
13.0 0.9521 0.9947 0.9729 1139
14.0 0.9633 0.9078 0.9347 347
15.0 0.9091 0.8333 0.8696 84
accuracy 0.9585 9225
macro avg 0.9511 0.9352 0.9426 9225
weighted avg 0.9591 0.9585 0.9584 9225
可视化效果:
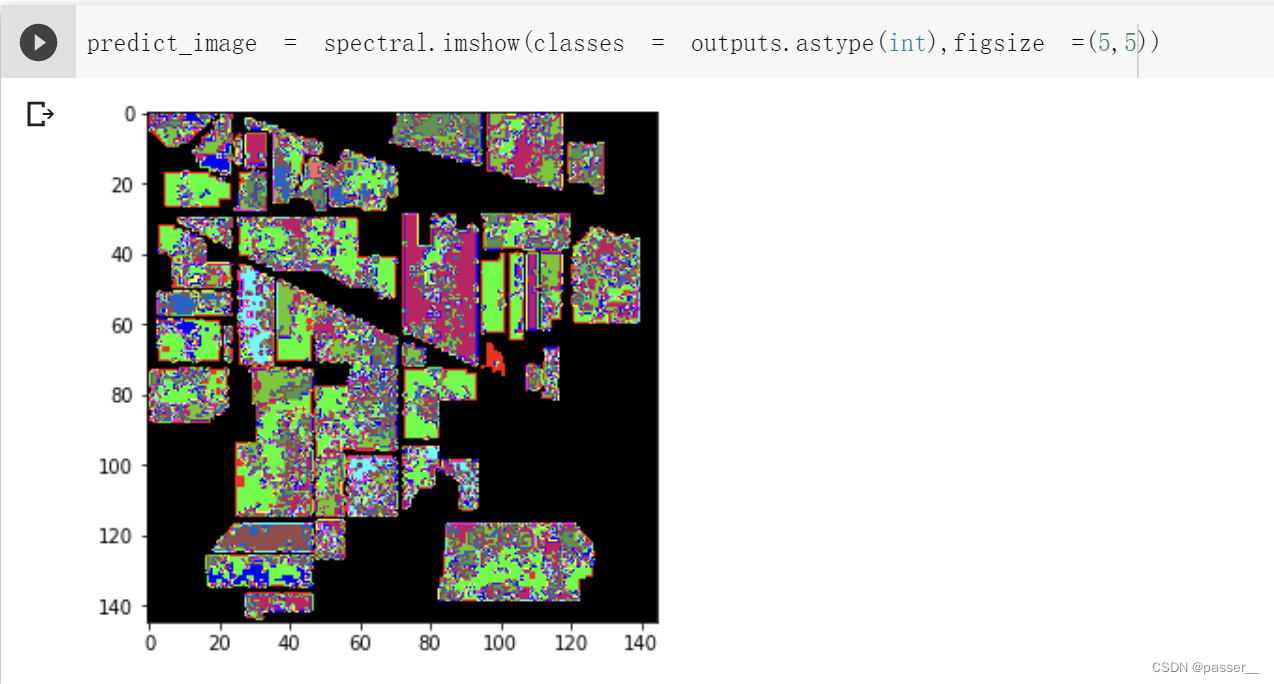
加入
net.train()
net.eval()
测试结果:
precision recall f1-score support
0.0 1.0000 0.9512 0.9750 41
1.0 0.9871 0.9525 0.9695 1285
2.0 0.9960 0.9946 0.9953 747
3.0 0.9952 0.9765 0.9858 213
4.0 0.9953 0.9770 0.9861 435
5.0 0.9907 0.9711 0.9808 657
6.0 1.0000 1.0000 1.0000 25
7.0 1.0000 1.0000 1.0000 430
8.0 0.8182 1.0000 0.9000 18
9.0 0.9885 0.9863 0.9874 875
10.0 0.9645 0.9964 0.9802 2210
11.0 0.9924 0.9794 0.9859 534
12.0 0.9893 1.0000 0.9946 185
13.0 0.9991 0.9947 0.9969 1139
14.0 0.9858 1.0000 0.9928 347
15.0 0.9195 0.9524 0.9357 84
accuracy 0.9846 9225
macro avg 0.9764 0.9833 0.9791 9225
weighted avg 0.9849 0.9846 0.9846 9225
测试结果图:
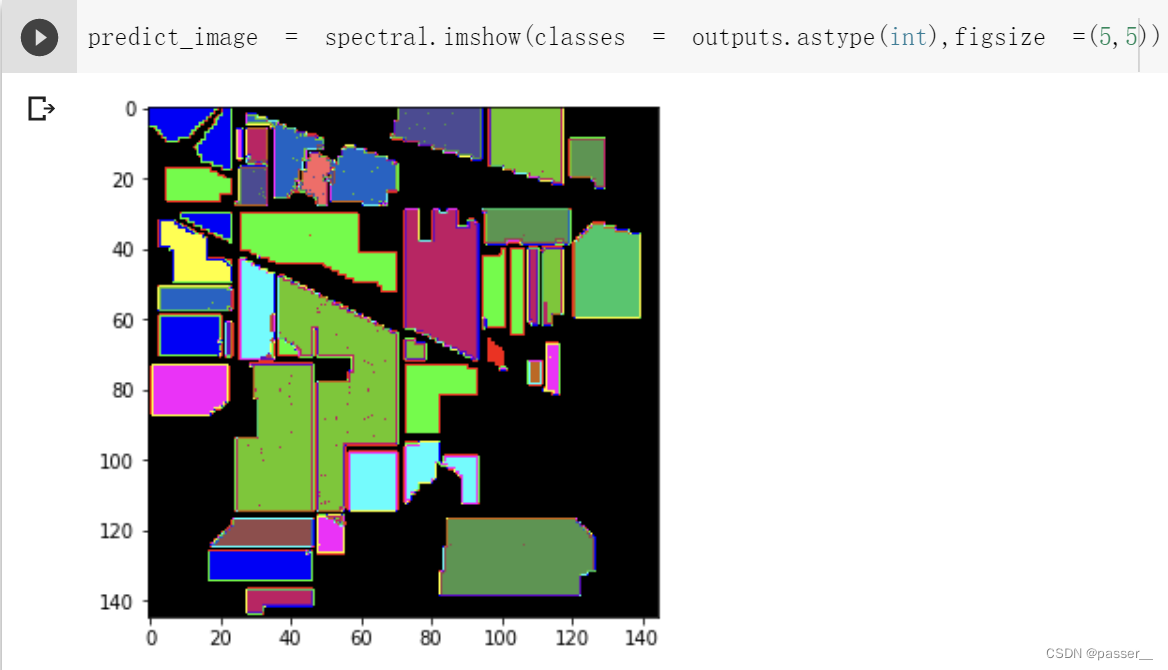
思考
- 思考3D卷积和2D卷积的区别
在二维卷积中,输入的大图片与二维的卷积核进行卷积,输出的是一张二维的特征矩阵(特征图),当然也只能提取二维的平面特征。如果数据类型其本身的特征分布是三维的,那么仅仅用二维卷积提取到的特征就会不全面,都没有完全利用输入数据。三维卷积可以同时提取三个维度的数据的特征,能同时进行空间和空间特征表示.
- 训练网络,然后多测试几次,会发现每次分类的结果都不一样
测试模型的时候,随机的drop,就会导致最终结果的不一致.在训练模型的时候要加上model.train()开启drop;在测试模型的时候加上model.eval()关掉drop,以此来保持结果一致。
- 如果想要进一步提升高光谱图像的分类性能,可以如何改进
可以借鉴一下SeNet的SE模块或者增加残差模块

















 2574
2574




 到【灌水乐园】发言
到【灌水乐园】发言







