




目录
1,car文件夹下创建mydata.yaml(当然别的位置创建也行)
一,构建数据集
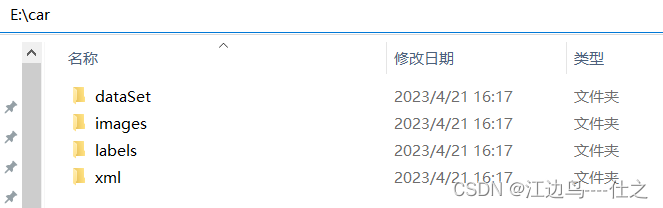
1,任意位置新建如下文件夹
|------car(目标检测类别名)
| |------dataSet(后续在文件夹下生成存放images中图像路径的txt文件)
| |------images(不可改名,存放图像文件,图像不需要统一格式)
| |------labels(不可改名,存放标签文件,标签与图像根据文件名一一对应)
| |------xml(存放xml文件,labelImg的VOC格式打标生成的xml文件)
labelImg打标,可以打标为VOC格式(xml文件)和YOLO格式(txt文件)
如果打标为VOC格式,后续需要转成YOLO格式,也就是xml文件转换为txt文件
所以直接打标为YOLO格式就不需要xml转txt,也不需要xml文件夹。
但是,xml转txt容易,txt转xml就难了
labelimg安装与使用:labelimg数据打标
2,xml转txt
代码如下,按提示修改即可
#trans
# voc_to_yolo.py
import os
import xml.etree.ElementTree as ET
from fnmatch import fnmatch
# 转换之前先修改类别和路径
classes = ["car"]
# 指定路径
IN_PATH = "./xml" # xml文件夹路径
OUT_PATH = "./labels" # txt文件夹路径
# 一般情况不修改:类别起始编号start_number
start_number = 0
# (lx,ly,rx,ry) -> (cx,xy,w,h)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(in_path, out_path, img_id):
i_p = os.path.join(in_path, img_id+'.xml')
in_file = open(i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+









 到【灌水乐园】发言
到【灌水乐园】发言







