





 本文介绍如何使用Docker及Docker Compose部署Apache Flink集群,并通过具体示例演示构建Flink镜像及运行WordCount任务的过程。
本文介绍如何使用Docker及Docker Compose部署Apache Flink集群,并通过具体示例演示构建Flink镜像及运行WordCount任务的过程。
1 Overview
/path/to/flink/flink-container/docker
├── Dockerfile
├── README.md
├── build.sh
├── docker-compose.yml
├── docker-entrypoint.sh
└── test-job-cluster.sh
0 directories, 6 files
Flink Dockerfile 走读已经介绍了 Flink 的镜像应该如何构建了,接下来,本文解释一下如何利用 Docker 来部署 Flink。
2 Docker Compose
以下是 docker-compose.yml 的内容。
# 省略 License
# Docker compose file for a Flink job cluster deployment.
# 注意下面这些参数的设置
# Parameters:
# * FLINK_DOCKER_IMAGE_NAME - Image name to use for the deployment (default: flink-job:latest)
# * FLINK_JOB - Name of the Flink job to execute (default: none)
# * DEFAULT_PARALLELISM - Default parallelism with which to start the job (default: 1)
# * FLINK_JOB_ARGUMENTS - Additional arguments which will be passed to the job cluster (default: none)
# * SAVEPOINT_OPTIONS - Savepoint options to start the cluster with (default: none)
version: "2.2"
services:
job-cluster:
image: ${FLINK_DOCKER_IMAGE_NAME:-flink-job}
ports:
- "8081:8081"
command: job-cluster --job-classname ${FLINK_JOB} -Djobmanager.rpc.address=job-cluster -Dparallelism.default=${DEFAULT_PARALLELISM:-1} ${SAVEPOINT_OPTIONS} ${FLINK_JOB_ARGUMENTS}
taskmanager:
image: ${FLINK_DOCKER_IMAGE_NAME:-flink-job}
command: task-manager -Djobmanager.rpc.address=job-cluster
scale: ${DEFAULT_PARALLELISM:-1}
3 Example
好了,万事俱备,现在就在本地跑起来一个 Flink Job on Docker!
首先先构建镜像,可以参考下面的命令,当然这些变量可以根据文档自行定义。因为我没有自己写的用户代码,这里用 Flink 的 Example 下面的 WordCount.jar 来构建镜像,到时候就跑一个 WordCount 的 Job。而且我用的是官网下载的发行版,所以可以看到参数 --from-archive。默认构建的镜像叫做 flink-job:latest。
./build.sh --from-archive ~/Downloads/flink-1.8.1-bin-scala_2.11.tgz --job-artifacts /Users/runzhliu/Downloads/flink-1.8.1/examples/batch/WordCount.jar
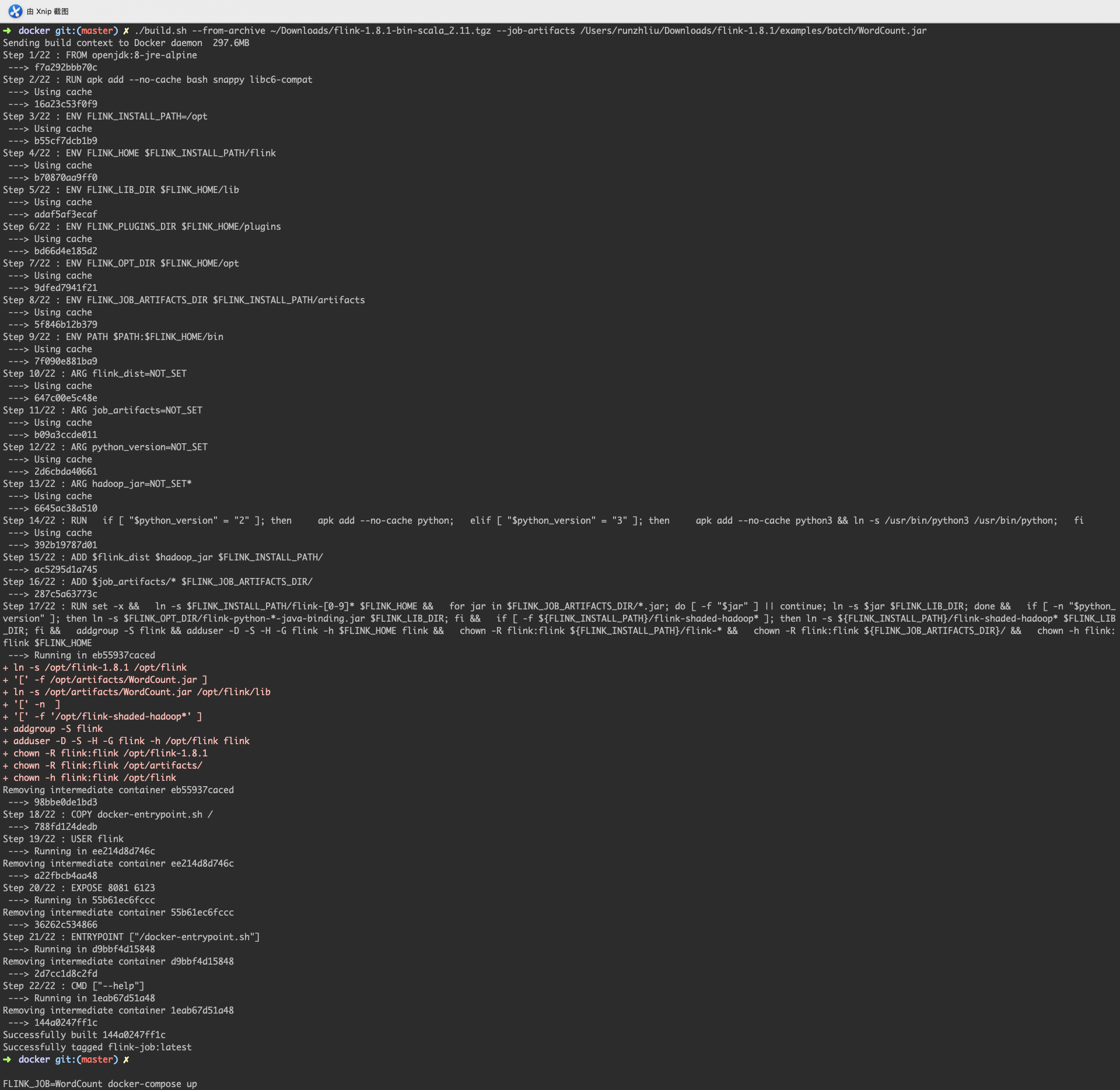
镜像构建好了,就用 docker compose up,启动容器。可以参考下面的命令。注意 FLINK_JOB 需要输入包含包名的类名,否则会找不到类。
FLINK_JOB=org.apache.flink.examples.java.wordcount.WordCount docker-compose up
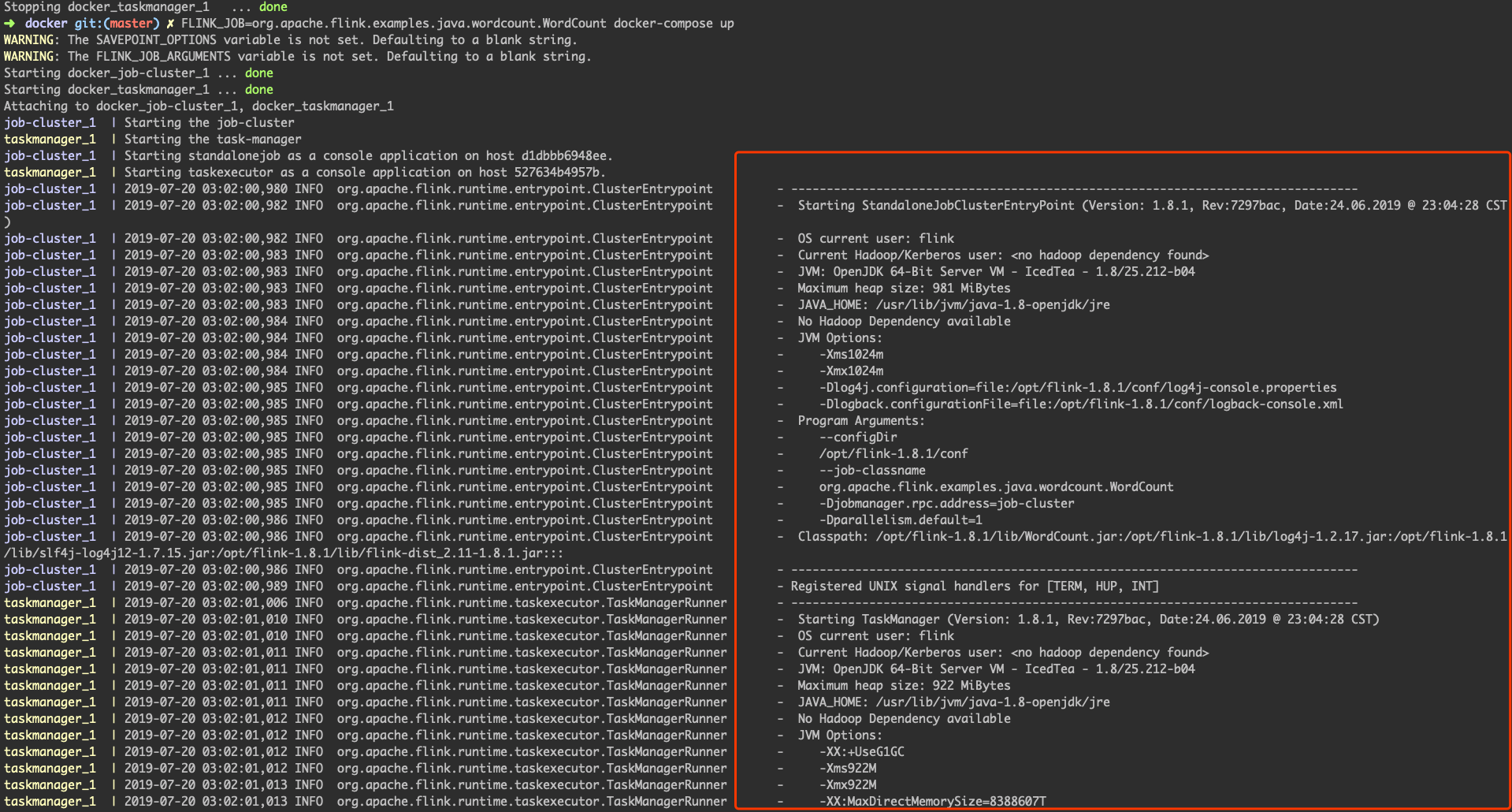
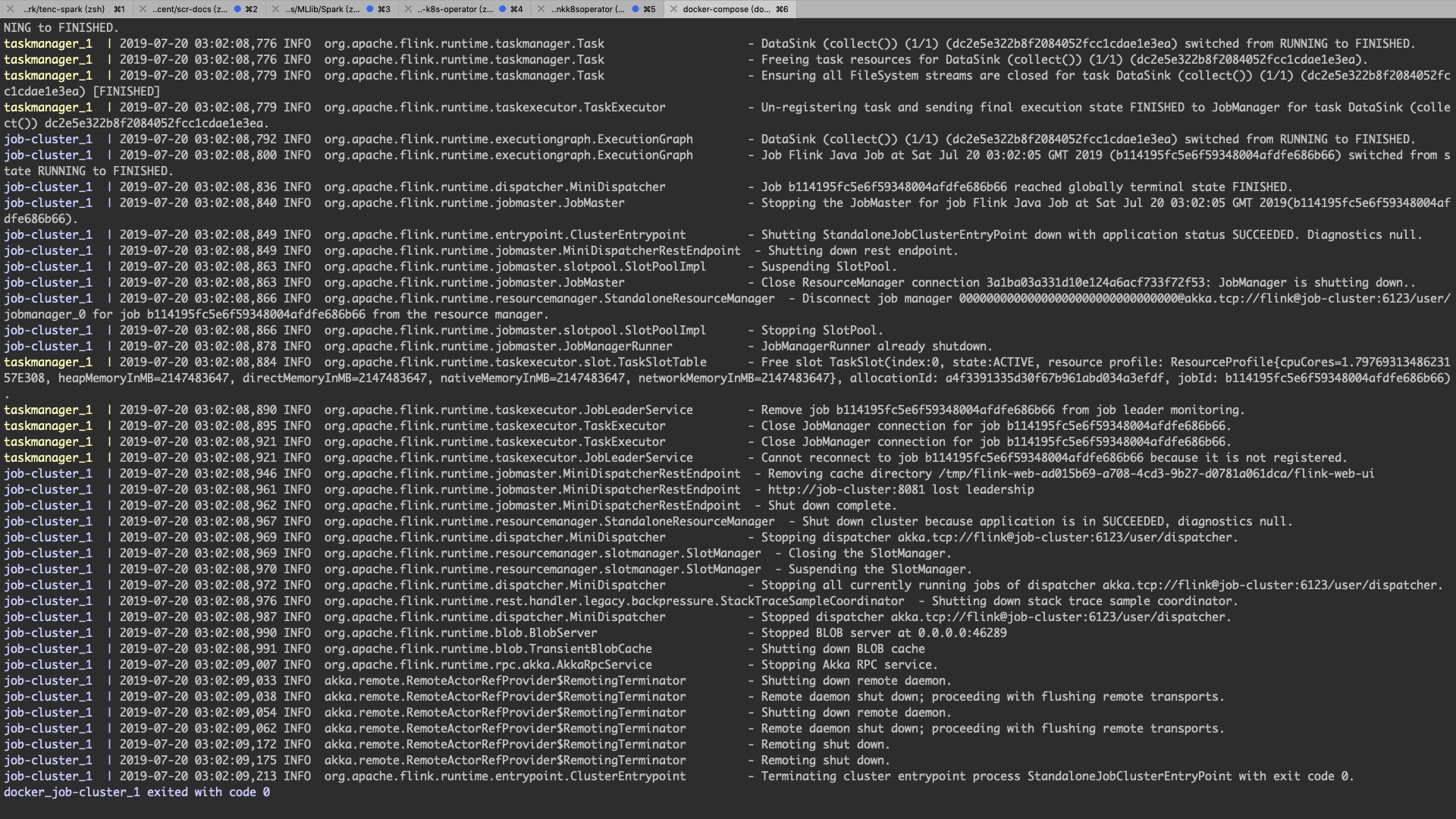
运行中的日志。
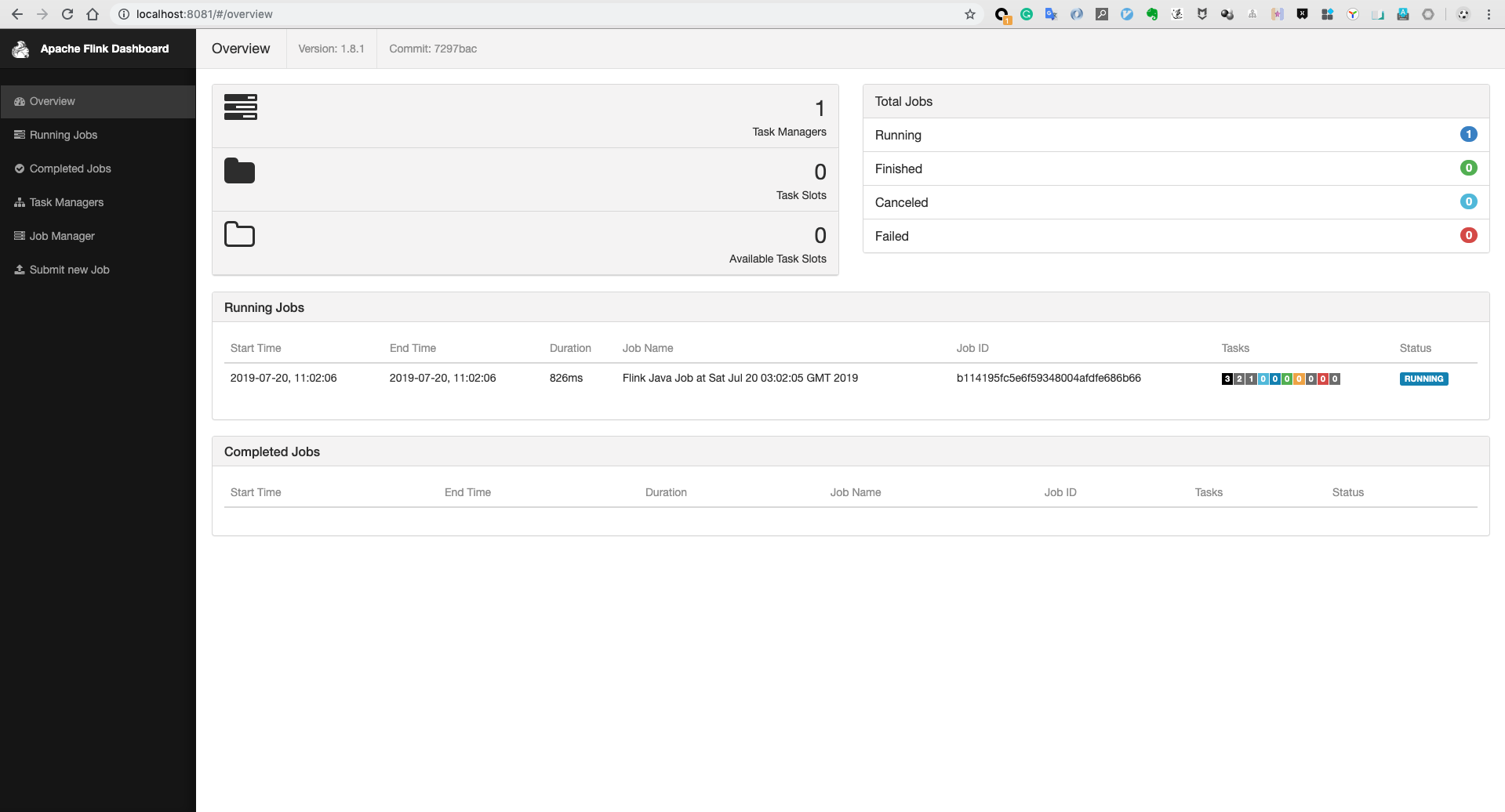
如果速度快,可以看到 Flink UI。
4 Summary
根据官方提供的工具,现在就已经可以将 Flink Job 以 Docker 的方式运行起来了,这是给后面将 Flink Job 运行在 K8S 上的基础。

















 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









