




在大数据时代,面对每日激增的PB级数据,如何设计高效的数据表结构,成为每个数据工程师的必修课。Apache Doris作为实时分析领域的明星产品,其独特的分区、分桶策略和智能管理能力,能帮助企业轻松应对海量数据挑战。本文将带你解锁Doris分区设计的核心技巧,让你的数据查询效率提升10倍!
数据分布概述
为了确保数据均匀分布在各 BE 节点,避免数据倾斜导致部分节点过载,Doris 引入了分区和分桶两层逻辑对数据进行划分。分区和传统数据库没有本质的区别,主要是从业务逻辑的角度对数据进行划分;而分桶则是基于 Hash 或 Random 算法直接将数据从物理层面进一步打散。
- 数据写入时,Doris 根据表的分区策略将数据行分配到对应的分区,并根据分桶策略将数据进一步映射到分区内的具体分片,从而确定数据行的存储位置。分片是 Doris 中数据管理的最小单元,也是数据移动和复制的基本单位;
- 数据查询时,Doris 优化器会根据分区和分桶策略裁剪数据,减少数据扫描范围。
分区和分桶策略
Doris 分区支持两种类型:
- Range 分区:根据分区列的值范围将数据行分配到对应分区,适用于时间和序列号等单向递增数据类型;
- List 分区:根据分区列的具体值将数据行分配到对应的分区,适用于取值范围比较固定的数据类型,比如省份和地区等。
分桶也支持两种方式:
- Hash 分桶:通过计算分桶列值的 crc32 哈希值,对分桶数取模,将数据行均匀分布到分片中;
- Random 分桶:不依赖于某个字段的 Hash 值,随机分配数据行到分片中。Random 分桶能够确保数据均匀分散,避免由于分桶健选择不当而引发的数据倾斜问题。
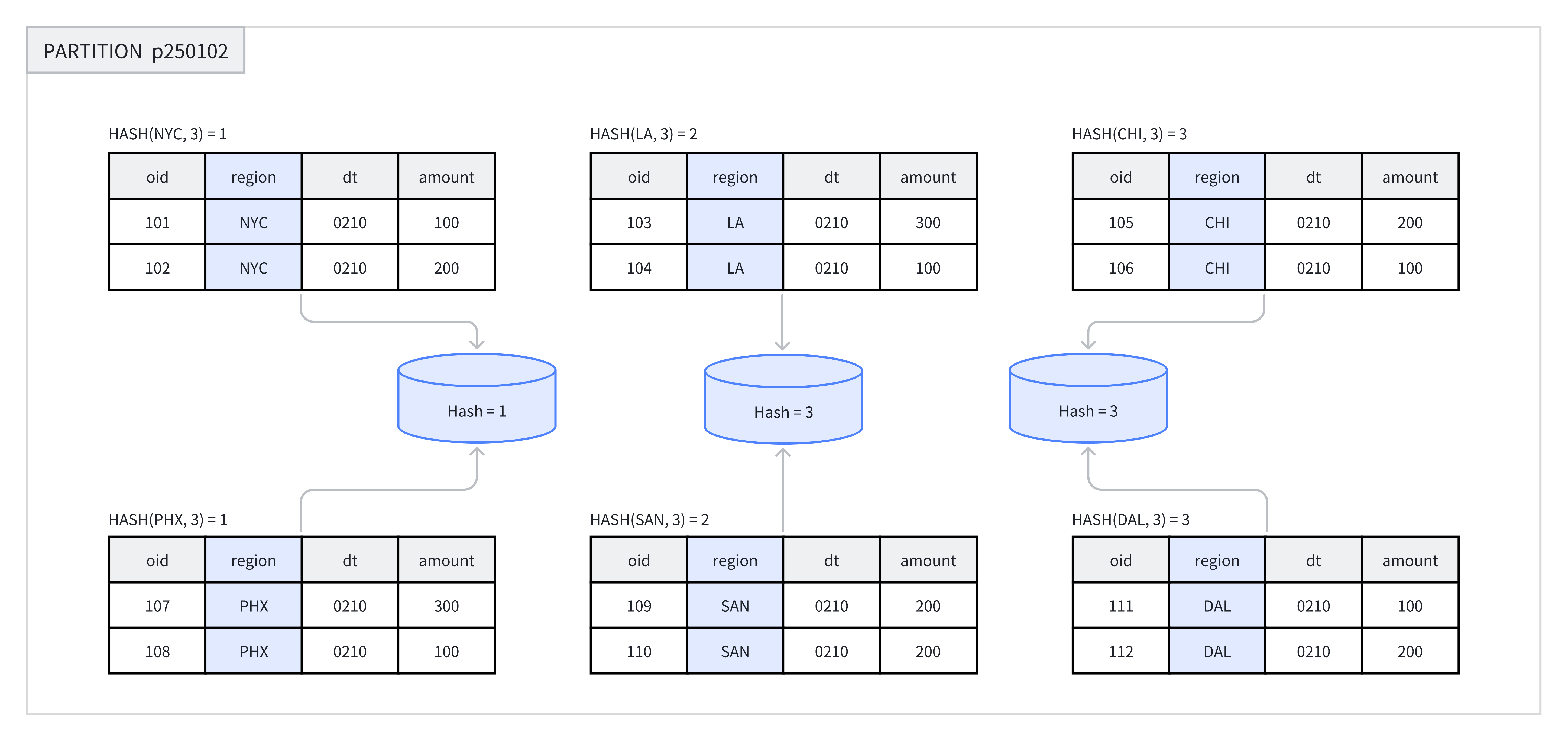
Doris 中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









