




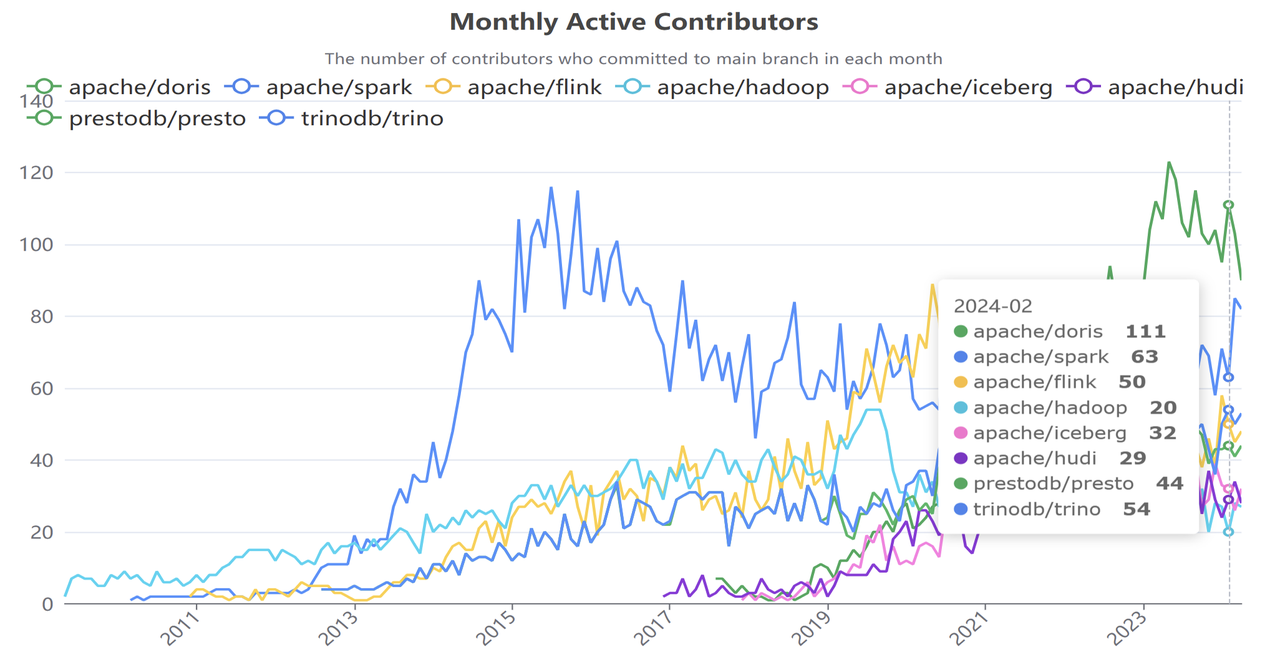
Apache Doris 是一款开源的 MPP 数据库,以其优异的分析性能著称,被各行各业广泛应用在实时数据分析、湖仓融合分析、日志与可观测性分析、湖仓构建等场景。Apache Doris 目前被 5000 多家中大型的企业深度应用在生产系统中,包含互联网、金融、制造、电信、能源、物流、政务等行业。目前项目已在 GitHub 获得超过 13000 Star,汇集 600 多名社区开发者,月度活跃贡献者数量连续数月位居全球大数据开源项目榜首,成为全球大数据领域最活跃的开源项目之一。
SelectDB 是北京飞轮数据科技有限公司基于 Apache Doris 研发的现代化实时数据仓库,提供包括面向私有化部署的 SelectDB Enterprise 和云原生存算分离的 SelectDB Cloud 云数仓服务。SelectDB 兼容 Apache Doris 的所有能力和接口,相比开源自建在安全、稳定、资源弹性等方面有明显优势。本文将对 Doris & SelectDB 适合的分析场景和技术能力进行概述解析。
1. Doris & SelectDB 典型分析场景
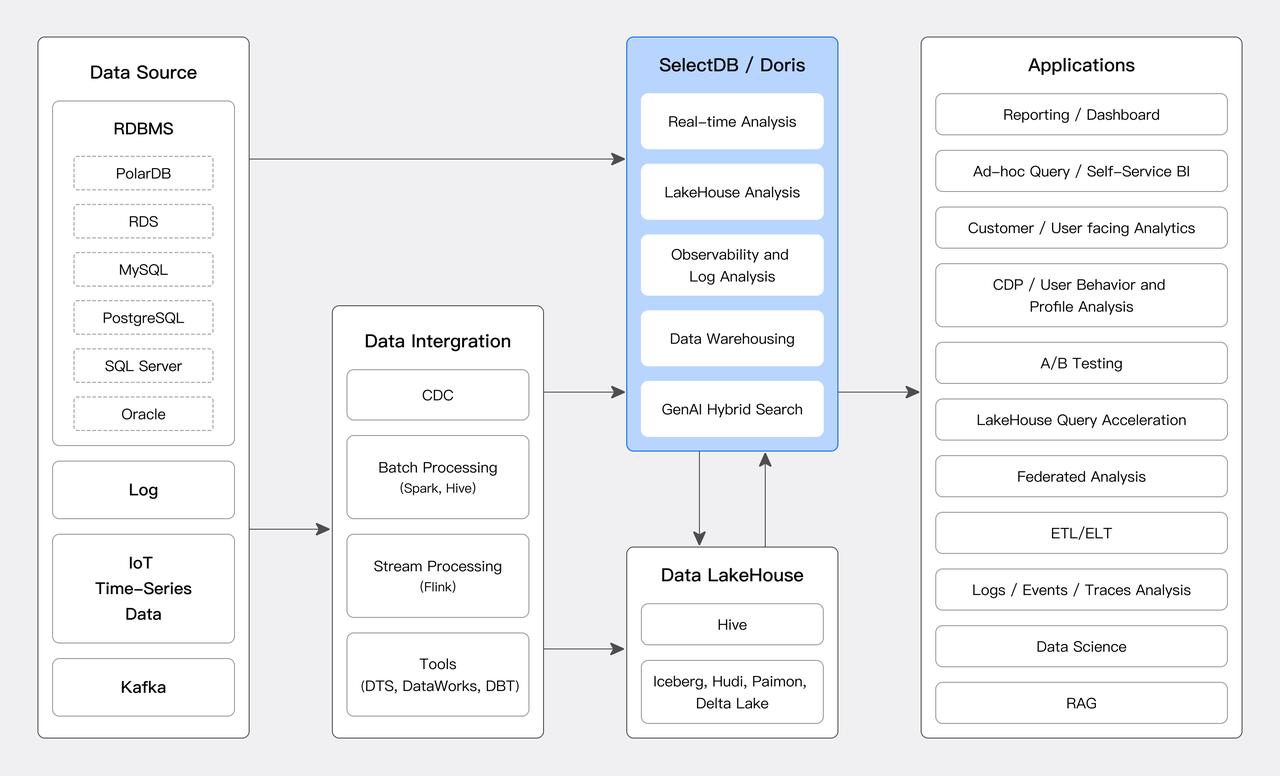
SelectDB & Doris 在如下的分析场景中通常是最优选择:
- 实时分析
- 面向内部的实时报表和 Dashboard。
- Ad-Hoc 分析和自助式 BI。
- 面向终端客户 / 用户的高并发分析(Customer / User Facing Analysis):比如电商平台面向数百万广告主 / 店铺的数据分析、面向数十万快递员的分析,这类分析通常需要非常高的并发和较低的延时。
- 用户行为和画像分析(CDP,Customer Data Platform):分析用户参与、留存、转化等行为,A/B Testing,支持人群洞察和人群圈选等画像分析,实现精细化的运营和精准的营销。
- 湖仓融合分析
- 湖仓查询和计算加速:作为查询引擎直接查询 Iceberg, Hudi, Paimon, DeltaLake, Hive 等湖仓中的数据,在不移动数据的情况下,实现查询分析的数倍加速。
- 多源联邦分析:作为统一的查询网关,支持跨多个数据源查询位于数据湖、数据仓库、数据库中的数据,实现联邦查询,简化架构并消除数据孤岛。
- 可观测性和日志分析
- 实现对日志、事件、traces 的高效存储和分析,替换 Elasticsearch, Loki, ClickHouse 等方案,实现数倍的性价比提升。
- 湖仓构建
- 对数据进行 ETL / ELT 实现数据的加工和建模,数据可以统一在 SelectDB & Doris 中存储管理,也可以将加工处理过的数据回写到 Iceberg,Hudi,Paimon,DeltaLake,Hive 等 Data LakeHouse 中,实现湖仓融合构建。
2. Doris & SelectDB 技术能力解析
2.1 极速
Doris & SelectDB 的查询分析性能非常优异,在宽表聚合分析和复杂多表关联场景中均表现突出:
- 在宽表聚合场景下,使用 SSB-FLAT benchmark 测试,相同资源下,是 ClickHouse 的 3.4 倍,是 Presto 的 92 倍,是业界标杆产品 Snowflake 的 6 倍。
- 在多表关联场景下,使用 TPC-H benchmark 测试,相同资源下,其性能可达到 Redshift 的 1.5 倍,ClickHouse 的 49 倍,是业界标杆产品 Snowflake 的 2.5 倍,是 Greenplum 和 Presto 的 15 倍。
Doris & SelectDB 如此卓越的性能主要得益于以下技术加持:
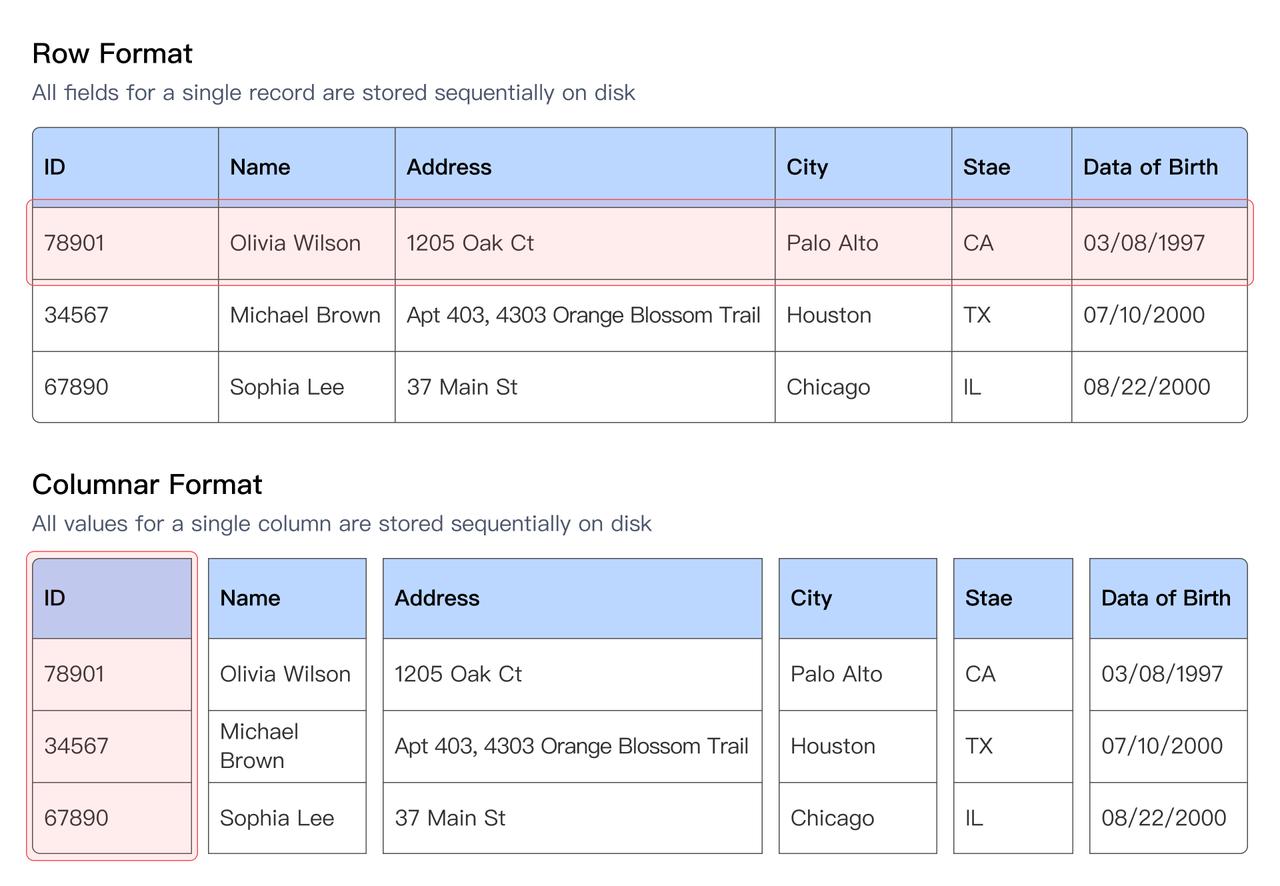
2.1.1 列式存储
Doris & SelectDB 默认使用列式存储组织数据,在数据分析场景下,相比行存储通常有 5-10 倍的性能提升,这是因为:
- 只需要读取 SQL 查询涉及的列,不相关的列无需读取和解压过滤,大大降低了 IO 和 CPU 开销。
- 同一列的数据类型一致,方便进行高效的数据编码和压缩。数值类型采用 RLE 编码,字符串使用字典编码。编码后使用 LZ4 或者 ZSTD 等压缩算法压缩,大幅减少了数据存储空间,也节省了读取 IO。
2.1.2 丰富的索引
Doris & SelectDB 支持丰富的索引机制,通过索引机制,可以大幅减少对不相关数据的读取和处理,从而能够大幅提升性能。从加速的查询和原理来看,Doris & SelectDB 的索引分为点查索引和跳数索引两大类。
-
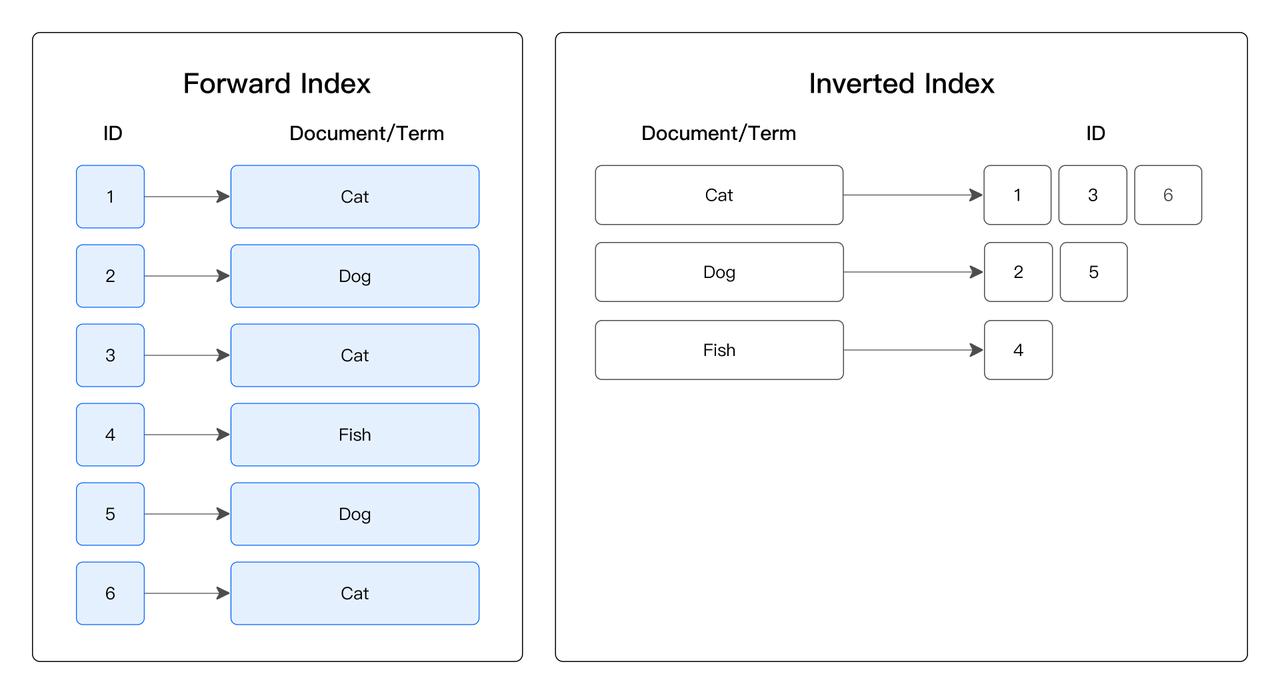
点查索引:常用于加速点查。 其原理是通过索引定位到满足 WHERE 条件的位置,直接读取其所在行。点查索引在满足条件的行数较少时,效果尤为显著。其点查索引包括前缀索引和倒排索引。
- 前缀索引:按照排序键以有序的方式存储数据,并每隔 1024 行数据创建一个稀疏前缀索引。索引中的 Key 是当前 1024 行中第一行中排序列的值。如果查询涉及已排序列,系统将找到相关 1024 行组的第一行,并从该行开始扫描。
- 倒排索引:对创建了倒排索引的列,建立每个值到对应行号集合的倒排表。对于等值查询,先从倒排表中查到行号集合,然后直接读取对应行的数据,而无需逐行扫描匹配数据,从而减少 I/O 、加速查询。倒排索引还能加速范围过滤、文本关键词匹配,算法更加复杂但基本原理类似。
-
**跳数索引:常用于加速分析。**原理是通过索引确定不满足 WHERE 条件的数据块,跳过这些不满足条件的数据块,只读取可能满足条件的数据块并再进行一次逐行过滤,最终得到满足条件的行。跳数索引在满足条件的行比较多时效果较好。其跳数索引包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引。
- ZoneMap 索引:自动维护每一列的统计信息,为每一个数据文件(Segment)和数据块(Page)记录最大值、最小值、是否有 NULL、Sum。对于等值查询、范围查询、IS NULL,可以通过最大值、最小值、是否有 NULL 来判断数据文件和数据块是否可以包含满足条件的数据,如果没有则跳过不读对应的文件或数据块减少 I/O 加速查询。比如下方 SQL 所示,有一个过滤条件
a<='100101',总共有三个数据块,第一个数据块通过读 ZoneMap 索引发现,最大值是 100101,整个数据块都满足条件,那么直接从 ZoneMap 中取得 sum 结果作为第一个数据块的聚合结果,
- ZoneMap 索引:自动维护每一列的统计信息,为每一个数据文件(Segment)和数据块(Page)记录最大值、最小值、是否有 NULL、Sum。对于等值查询、范围查询、IS NULL,可以通过最大值、最小值、是否有 NULL 来判断数据文件和数据块是否可以包含满足条件的数据,如果没有则跳过不读对应的文件或数据块减少 I/O 加速查询。比如下方 SQL 所示,有一个过滤条件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











