






前言
在存储引擎方面,Apache Doris 采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
基本概念
在 Doris 中,数据都以表(Table)的形式进行逻辑上的描述。
一张表包括行(Row)和列(Column),Row:即用户的一行数据;Column:用于描述一行数据中不同的字段。
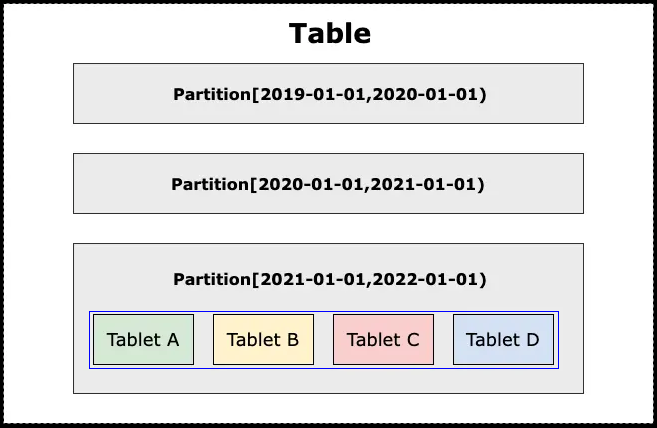
在 Doris 中,数据表(Table)按照分区(Partition)和分桶(Bucket)两种方式依次划分,最终同一个分桶中的数据形成数据分片(Tablet,可视作 Bucket)。
一张表(逻辑描述)有多个分区(逻辑描述),
一个分区(数据管理的最小逻辑单元)有多个分片(数据移动/复制等操作的最小物理存储单元,数据划分的最小逻辑单元),
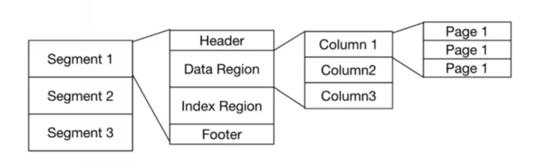
一个分片有多个分段(物理描述),
一个分段有多个数据页(数据读取的最小单元)。
分区
- 分区用于将数据划分成不同区间,逻辑上可以理解为将原始表划分成了多个子表,可以方便快速的按分区对数据进行管理。
- 分区列可以指定一列或多列,分区列必须为 KEY 列,不论分区列是什么类型,在写分区值时,都需要加双引号。
- 分区数量理论上没有上限。
- 当不指定分区建表时,系统会自动生成一个和表名同名的,全值范围的分区,该分区对用户不可见,且不可删改。 创建分区时不可添加范围重叠的分区。
分桶
- 建议采用区分度大的列做分桶, 避免出现数据倾斜。
- 如果是分区表,那么桶就是对分区进行Distributed划分,如果不是分区表那么就是对整个表进行划分。
- 分桶列只能是KEY列,分桶列可以和分区列相同或不同。
- 分桶列的多少取决于对“吞吐”和“并发”的一种权衡。
- 分桶列多,数据分布的更加均匀,适合大吞吐低并发的查询,不适合高并发的点查询。
- 分桶列少,适合高并发的点查询。
- 分桶数量理论上无上限,但是要结合实际资源情况进行设置。
- 一个表的 Tablet 总数量 = PARTITION - NUM * BUCKET - NUM 。
- 数量原则:一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
- 数据量原则: 建议单个桶的SIZE不要太大,保持在10GB以内,所以建表或增加分区时请合理考虑桶的数目,其中不同分区可指定不同的桶数。
- 当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
- 一个 Partition 的 Bucket 数量一旦指定,不可更改
手动分区
建表时,手动指定分区列。
动态分区
某个场景下,用户希望将表数据按天进行分区,如果采用手动管理分区会比较麻烦,也可能出现由于没有创建分区导致数据接入失败的情况,从而给用户带来额外的维护成本。所以,用户可以在建表时设定动态分区的规则,FE的后台会启动一个线程,根据用户指定的规则来创建或删除分区,这就是动态分区。Doris使用动态分区来处理重复性较高的时间分区需求,自动化创建和回收数据分区,通过指定分区单位、历史分区数量和未来分区数量,让 Doris根据现实时间自动完成分区的创建和回收。
(1)开启动态分区的表,将会按照设定的规则添加、删除分区,从而对表的分区实现生命周期管理(TTL),减少用户的使用负担;
(2)动态分区只支持在 DATE/DATETIME 列上进行 RANGE 类型的分区;
(3)动态分区适用于分区列的时间数据随现实世界同步增长的情况,此时可以灵活的按照与现实世界同步的时间维度对数据进行分区,自动地根据设置对数据进行冷热分层或者回收;
(4)动态分区的规则可以在建表时指定,或者在运行时进行修改,当前仅支持对单分区列的分区表设定动态分区规则,动态分区功能在被 CCR(跨级群数据同步,能够在库/表级别将源集群的数据变更同步到目标集群) 同步时将会失效。
为什么要提出自动分区?
由于动态分区参数限定了分区的固定范围,用户只能在约定范围内管理分区,若需要管理更久远的历史数据,不得不将START值调大,而这会导致集群中元数据的不必要浪费,因此,在使用动态分区功能时,需要权衡实时管理的便利性与元数据管理的效率。
当遇到以下两种特定场景时,则无法使用动态分区进行分区管理:
(1)当分区的时间维度不再和当前现实时间相关,而是对历史数据进行重放计算,例如:处理过往某一年的数据,且需要进行天级别的分区的时候怎么办?
(2)当前数据导入过程中,偶尔发生历史数据变更,例如:在天级别的分区表中,偶尔导入若干年前的数据,是否需要将动态分区的 START调整到非常大的级别以容纳这些数据?
因为动态分区存在以下3个不足:
(1)仅支持 Range分区,而无法支持 List 分区;
(2)只能应用于与现实世界时间维度一致的数据,如果数据与现实时间无关则无法使用;
(3)只能包含一个连续分区段,无法容纳该范围以外的分区。
自动分区
基于自动分区存在的问题,我们是否可以将分区的创建从建表时或者日常轮询时,延后到数据到达时?从预先构造分区的分布,转为定义“从数据到分区”的映射规则,等数据入库后等待分区容纳时,再根据规则创建对应的分区。这样,相较于手动分区,整个流程都是自动发生的,不再需要人工维护;相较于动态分区,避免了有而无用和用而没有的分区情况。 自动分区同时支持按时间维度的 Range 分区,和支持多种数据类型的 List 分区,按照导入数据的实际分布来创建分区,提供了更为灵活的分区创建手段,相比于动态分区,保证流程自动化的前提下极大提升了分区使用的自由度。表会在导入数据之后,自动创建数据所属的对应分区,而没有数据的分区不会自动创建;
自动分区在功能上基本覆盖了动态分区的使用场景,并带来分区规则前置的拓展,减轻了DBA 在管理数据时的工作负担;
LIST 自动分区支持多列分区,每个自动创建的分区仅包含一个分区值,分区名长度不能超过 50;
RANGE 自动分区支持单个分区列,分区列类型必须为 DATE 或 DATETIME;
LIST 自动分区支持 NULLABLE 分区列和实际插入 NULL 值;RANGE 自动分区不支持 NULLABLE 分区列。
动态分区和自动分区的区别

建议
(1)对于日志、交易记录等基础业务场景,数据的时间维度较为明确,我们一般按照时间维度创建 Range 分区。
(2)对于实时数据收集的场景,如:ODS 层直接从外部数据源(如 Kafka)接收数据时,动态分区功能尤为适用。
(3)如果 OLAP 表的分桶方式设置的是 Random,在数据导入时可以设置单分片导入模式(将 load_to_single_tablet 设置为 true)。那么在大数据量的导入时,一个任务在将数据写入对应的分区时将只写入一个分片,这样将能提高数据导入的并发度和吞吐量,减少数据导入和 Compaction 导致的写放大问题,保障集群的稳定性。



















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











