




Note to the reader : a dynamic version of this article can be found HERE, including interactive data-visualisations.
Over the past few years, natural language interfaces have been transforming the way we interact with technology. Voice assistants in particular have had strong adoption in cases where it’s simpler to speak than write or use a complex user interface. This becomes particularly relevant for IoT, where devices often don’t have touchscreens, making voice a natural interaction mechanism. And since speaking doesn’t require adaptation (unlike learning to use a new app or device), we can hope for a larger adoption of technology across all age groups.
Building a robust AI assistant, however, is still rather complicated. A number of companies are addressing this issue by providing natural language understanding (NLU) solutions that developers can use to augment their product with natural language capabilities.
In this article, we present the results of a benchmark conducted across multiple major providers and startups: Amazon’s Alexa, Google’s Api.ai, Microsoft’s Luis, Apple’s SiriKit, IBM’s Watson, Facebook’s Wit, and Snips (disclaimer: we work at Snips).
Beyond performance, the ability to operate offline can be a game-changer for use cases like connected cars, where internet connectivity cannot be guaranteed. Privacy is also mission critical in areas such as healthcare or banking, and is generally a growing concern for consumers, so sending data to the cloud might not always be an option. Finally, some systems have pre-built models for specific application domains, while others enable custom intents to be built.
Here is a table comparing the main existing solutions on each one of these aspects:
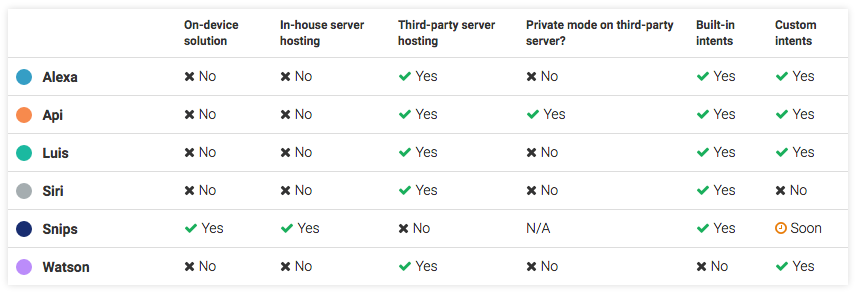
In order to guarantee privacy by design, the solution we built at Snips can run fully on device, without the need for a server. Snips does not offer hosting services and thus never sees any user data. As such, models had to be trained without user data, leading to a natural question around the tradeoff of privacy vs. AI performance.
The benchmark relies on a set of 328 queries built by the business team at Snips, and kept secret from data scientists and engineers throughout the development of the solution. The dataset, as well as raw performance metrics and benchmark results are openly accessible on github.
Built-in intents are compared to similar domains across providers. Providers not offering built-in intents were not included in this benchmark. The performance of these service depends on the efforts made by developers when training their custom intents, which makes comparisons methodologically more complicated. In the end, we tested the following services: Snips (10 intents), Google Api.ai (6 intents), Amazon Alexa (2 intents), Microsoft Luis (3 intents) and Apple Siri (1 intent).
Understanding natural language queries
All commercially available natural language understanding (NLU) services currently work in a similar way:
- Natural language query is sent to the service (e.g. “where is the closest sushi”)
- The intention is detected (e.g. “place search”)
- The specific parameters are extracted (e.g. type=sushi, location=42.78,2.38)
- A structured description of the user query is sent back
These steps each introduce uncertainty and require different models to be trained.
Step 1: Detecting user intentions
Since every provider has their own way of describing intents (called an ontology), we first had to build a baseline by creating a joint ontology across services. Different domains have been identified, and similar intents have been grouped together in performance estimates.
The metric we are providing is the the fraction of properly classified queries for each intent, along with its 95% confidence interval. The latter enables more robust conclusions, given that the size of the test dataset is limited.

These results suggest is that intent classification remains a difficult problem, on which competing solutions perform quite differently. Luis is significantly outperformed by competing solutions. Api.ai and Snips generally yield indistinguishable performances, aside from place search and request ride in which performances are significantly lower for Api.ai than for competitors. Alexa, Siri and Snips systematically rank among the best solutions on the intents they were tested on.
Step 2: Identifying the parameters of the query
Aggregated performances
The second step of the NLU process is to extract the parameters related to the detected intent, a process commonly called “slot filling”.
For example, when booking a taxi, these parameters would be: origin, destination and party size (how many people would be part of the trip). Again, each service has defined its own system of intents, and each intent comes with its specific set of parameters. The intents covered in this benchmark have between 1 and 18 parameters (slots).
In the graph below, the dots represent the aggregated precision and recall scores of all slots for a given intent. Recall represents the fraction of relevant slots that are retrieved. Precision accounts for the fraction of retrieved slots that are relevant.
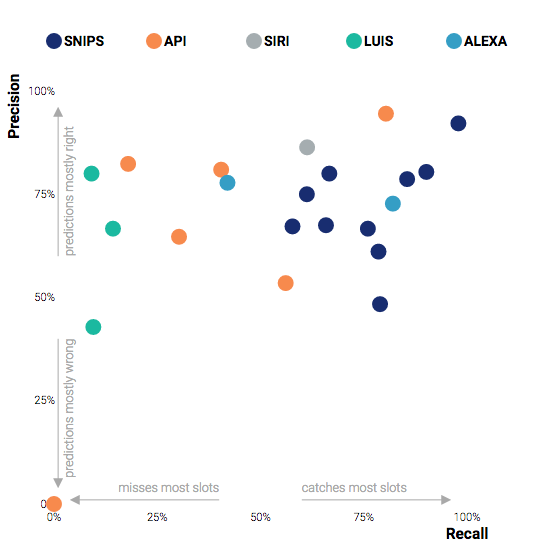
These results show that all solutions behave similarly in terms of precision. For all solutions, average precision per intent spans between 50% and 90%. The later suggest that all solutions are perfectible, and have a certain risk of misinterpreting user queries.
In terms of recall, however, significant differences can be identified between different solutions. Luis is once again outperformed by other solutions: average recall per intent is systematically below 14%. Performances for api.ai are highly variable: they span between 0% (taxi.search), and 80% (weather.search). The highest levels of recall can be observed for Alexa (42% and 82%), Siri (61%), and Snips (between 57% and 97%).
Diving into the raw data
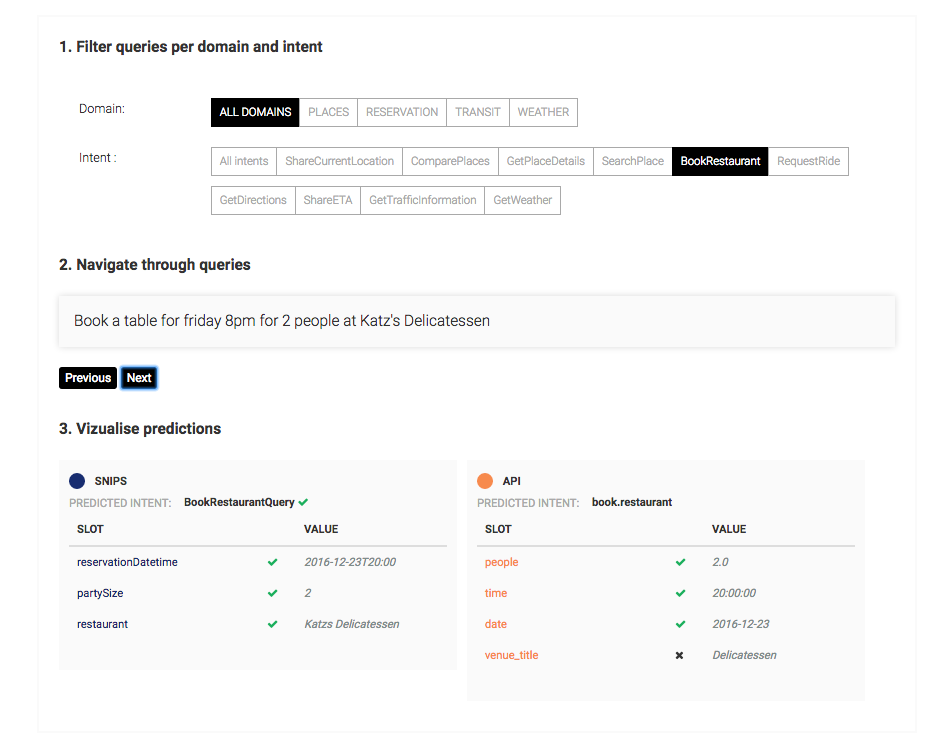
Global performances give an indication of how different services perform relatively to each other. To get a better feel for how acceptable these solutions are from an end user perspective, we can dive deeper into the raw data. Navigating from query to query below shows what each service would return.
Limits and key takeaways
A difficult task
This benchmark shows that there is currently no silver bullet. More precisely, there is no solution that doesn’t misinterpret user queries, and no solution that understands every query.
Unlike other areas of Artificial Intelligence, machines haven’t reached yet the level of human performance when it comes to NLU.
What this benchmark also shows is how important such tests and methodologies are needed: there are important differences between solutions available to developers.
As the saying goes, you can’t optimize what you don’t measure. At least we now know that some solutions lack robustness when it comes to variations in how things are asked, while all of them would benefit from improvement in how they fill slots.
Another good surprise (for us!), is that our solution, Snips, compares favorably with others. It achieves comparable outcomes than Alexa or Siri, while running fully on device, and without access to the vast amount of training data others have. Hopefully this starts to show that AI performance and Privacy can co-exist, and hence should be the default.
There is still much to be done
The data used for this benchmark is publicly available on Github. It has been designed to cover an important variety of cases, formulations and levels of complexity in order to make metrics as representative as possible. Still, the choices remain manual and arbitrary, which is why we are transparently making the raw data public. In addition, the supervision of results cannot always be automated, resulting in significant amounts of work. This also explains why our test dataset has a limited size: every time it made sense, we added the corresponding 95% confidence intervals.
Any contribution in extending the benchmark to a wider set of queries is of course welcome, and would contribute to bringing greater transparency to the NLU industry. Feel free to contact us should you have any questions / comments.
原文地址: https://medium.com/snips-ai/benchmarking-natural-language-understanding-systems-d35be6ce568d

















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









