




 本文介绍了机器学习中的梯度下降法,用于求解线性模型的参数。通过迭代最小化代价函数,找到最优解。接着讲解了逻辑回归的概念,使用sigmoid函数将连续值转换为0-1概率,适用于分类问题。最后,通过最大似然估计和梯度下降法求解逻辑回归模型的参数。
本文介绍了机器学习中的梯度下降法,用于求解线性模型的参数。通过迭代最小化代价函数,找到最优解。接着讲解了逻辑回归的概念,使用sigmoid函数将连续值转换为0-1概率,适用于分类问题。最后,通过最大似然估计和梯度下降法求解逻辑回归模型的参数。
下面介绍梯度下降法:
假设一个线性模型:

为了便于描述,定义:

我们需要选择合适的参数θ0和θ1,使得h(x)和样本中的y尽可能接近。
统计学中,利用最小二乘法可以得到两个参数的解析解:

但是我们将使用计算机科学的常用思想:迭代来求出这两个值,因为在这里模型的简单使得我们非常容易地计算出解析解。实际中我们的模型可能非常复杂,无法求出解析解,因此使用迭代思想是一种通用的解法。
我们的目标和最小二乘法一致,求出代价函数(cost function):

的最小值,即:

迭代的具体操作是梯度下降法,就是循环调用:
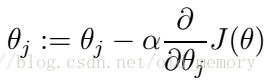
直到收敛,就是θj不再变化,那么必然是J(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









