






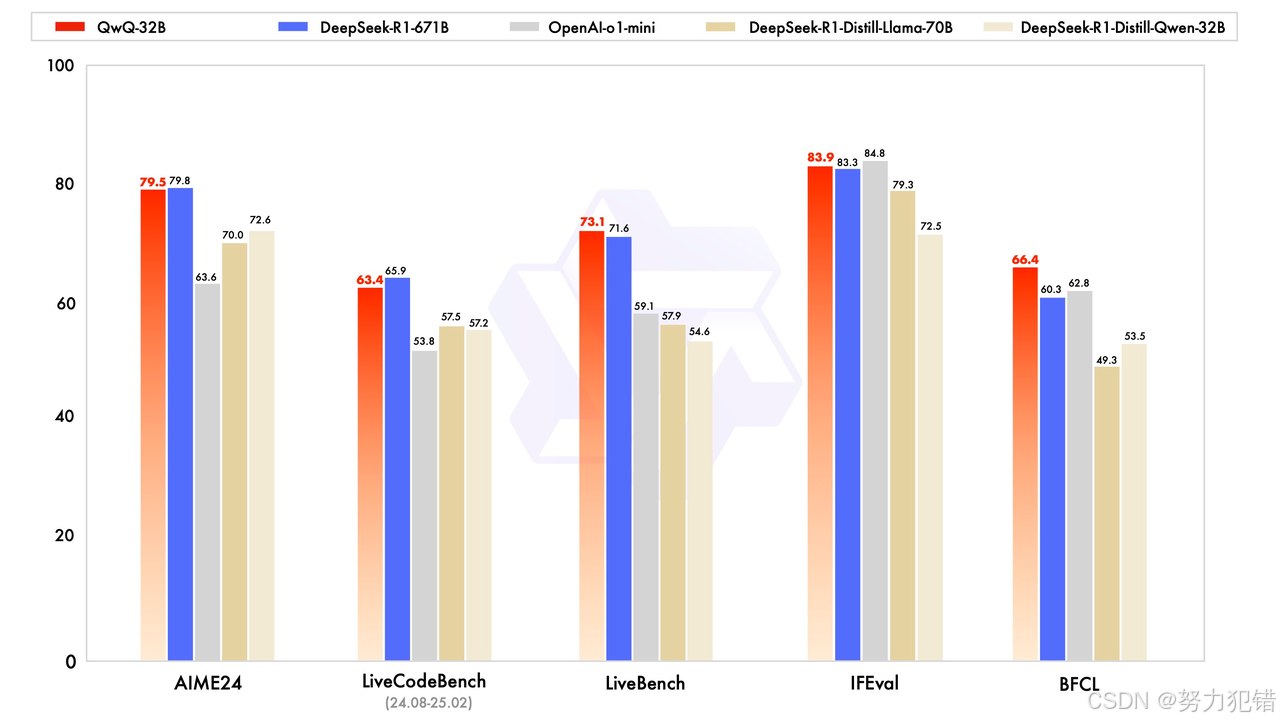
阿里千问团队推出的QwQ-32B模型近期引发热议,官方评测显示其性能直逼DeepSeek-R1,甚至在部分任务中表现更优。但面对动辄数百亿参数的模型,普通开发者如何用老旧GPU设备低成本部署?本文将以一台古董级V100服务器为例,手把手教你部署QwQ-32B,并验证其真实性能!
一、官方评测数据(Hugging Face榜单)
| 评测集 | QwQ-32B得分 | 对比模型得分(DeepSeek-R1) |
| AIME24(数学) | 79.5 | 79.8 |
| LiveCodeBench(代码) | 63.4 | 65.9 |
| LiveBench(综合) | 73.1 | 71.6 |
| IFEval(指令遵循) | 84.3 | 82.7 |
| BFCL(工具调用) | 92.5% | 90.1% |
从官方评测数据看,qwq-32B数据非常亮眼,在小尺寸模型上面接近了deepseek 的671B。
根据官方介绍,大规模强化学习(RL)有潜力超越传统的预训练和后训练方法来提升模型性能,同时qwen团队还在推理模型中集成了与 Agent 相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程,使得qwq-32B有媲美deepseek 671B的能力。
二、古董机器
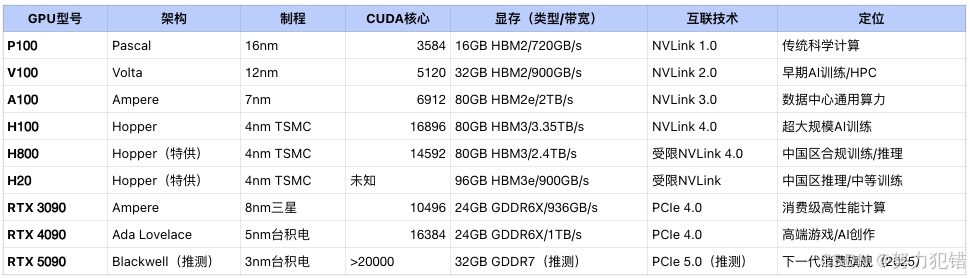
手边有一台古董的V100机器,计划部署这个QwQ-32B,看看是不是能让旧机器发挥作用。V100有多么古老,请看下面的表格数据:
V100与主流GPU的架构与核心参数对照
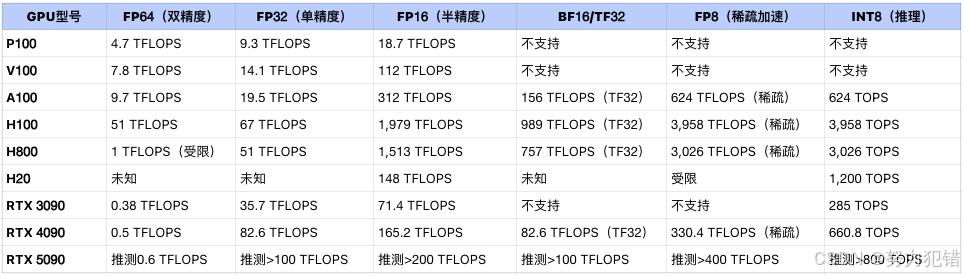
V100 与主流GPU精度算力参数对比
二、原生部署流程(ModelScope)
环境准备
这台测试机是一个古董级的老旧设备,性能远低于当下的4090、H20等显卡,虽然显卡的显存不小,但算力实在是拉胯的厉害。
# Python 3.11 + CUDA 12.1
conda create -n qwq python=3.11
conda activate qwq
pip install modelscope torch==2.3.0 accelerate模型下载
从huggingface国内镜像站AI快站下载QwQ-32B模型,或者从摩搭社区下载:
- AI快站下载
访问AI快站的下载地址:Qwen/QwQ-32B · Hugging Face,然后通过以下命令下载模型:
# 下载hf-fast.sh wget https://fast360.xyz/images/hf-fast.sh chmod a+x hf-fast.sh # 下载AI模型 ./hf-fast.sh Qwen/QwQ-32B - 摩搭社区下载
从摩搭社区下载完整模型需要约80GB的磁盘空间,使用以下代码:
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/QwQ-32B', revision='v1.0.0')推理验证代码
完成模型下载后,我们可以通过编写简单的推理验证代码来测试模型是否能够正常运行。以下是示例代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"qwen/QwQ-32B",
device_map="auto",
torch_dtype="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("qwen/QwQ-32B")
inputs = tokenizer("解释量子纠缠现象", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=500)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))这段代码首先加载了模型和分词器,然后对输入的文本“解释量子纠缠现象”进行编码,并将其传递给模型进行生成,最后解码输出结果并打印。
三、Ollama量化部署
如果你追求更快速、更轻量级的部署体验,Ollama 是一个非常不错的选择。 Ollama 能够将大模型量化压缩,降低显存占用,让低配置设备也能流畅运行。
环境要求
• 最低配置:NVIDIA RTX 3060(12GB显存)
• 推荐配置:RTX 4090(24GB显存)
安装部署
通过以下命令一键安装Ollama(支持Linux、MacOS、Windows系统):
curl -fsSL https://ollama.com/install.sh | sh然后拉取量化后的QwQ-32B模型(20GB Q4版本):
OLLAMA_NUM_GPU=4 ollama run qwq多卡加速配置
在“~/.ollama/config.yaml”文件中进行多卡加速配置:
# ~/.ollama/config.yaml
num_gpu: 4
model_loader: "auto"
quantization: "q4_k_m" 验证部署
查看显存分配情况:
nvidia-smi --query-gpu=memory.used --format=csv启动交互式对话进行测试:
ollama run qwq:32b-q4_k_m --verbose补充一句
看到有人说QwQ-32B质量很差,这个需要看看是不是用了ollama或者其他量化版本,满血版的QwQ-32B感觉还是挺能打的。有可能他的稠密模型量化后,质量损失太严重吧,这里的ollama就是试一试而已。
部署验证要点
- 1. 性能基准测试
# 数学能力验证
"求积分∫_0^π x*sin(x)dx的值,给出分步推导过程"
# 代码生成验证
"用Python实现支持断点续传的HTTP下载器,要求添加进度条"- 2. 显存占用参考
| 量化级别 | 显存占用 | 生成速度(tokens/s) |
| FP16 | 24GB | 32 |
| Q8 | 18GB | 45 |
| Q4_K_M | 14GB | 62 |
故障排除
常见问题
• 显存不足:添加--quantization q4_0参数
• 下载中断:配置镜像源OLLAMA_HOST=mirror.aliyun.com
• CUDA版本冲突:强制指定TORCH_CUDA_VERSION=12.1
高级功能
• 工具调用集成:参考qwen/agent仓库配置API网关
• 长上下文支持:启动时添加--ctx-size 131000参数
四、evalscope的简单测试
为了更直观地了解 QwQ-32B 的性能,我们使用 evalscope 工具进行了简单的评测。 评测数据集选择了 gsm8k (数学题) 和 arc (常识推理)。
~$ evalscope eval --model /data/models/QwQ-32B/ --datasets gsm8k arc --limit 5 |tee eval.log
2025-03-11 08:57:09,212 - evalscope - INFO - Args: Task config is provided with CommandLine type.
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 14/14 [00:25<00:00, 1.84s/it]
2025-03-11 08:57:36,158 - evalscope - WARNING - Got local model dir: /data/models/QwQ-32B/
2025-03-11 08:57:36,159 - evalscope - INFO - Updating generation config ...
2025-03-11 08:57:36,159 - evalscope - INFO - Dump task config to ./outputs/20250311_085709/configs/task_config_789aa3.yaml
2025-03-11 08:57:36,163 - evalscope - INFO - {
"model": "/data/models/QwQ-32B/",
"model_id": "",
"model_args": {
"revision": "master",
"precision": "torch.float16"
},
"template_type": null,
"chat_template": null,
"datasets": [
"gsm8k",
"arc"
],
"dataset_args": {
"gsm8k": {
"name": "gsm8k",
"dataset_id": "modelscope/gsm8k",
"model_adapter": "generation",
"output_types": [
"generation"
],
"subset_list": [
"main"
],
"metric_list": [
"AverageAccuracy"
],
"few_shot_num": 4,
"few_shot_random": false,
"train_split": null,
"eval_split": "test",
"prompt_template": "Question: {query}\nLet's think step by step\nAnswer:",
"system_prompt": null,
"query_template": null,
"pretty_name": "GSM8K",
"filters": null
},
"arc": {
"name": "arc",
"dataset_id": "modelscope/ai2_arc",
"model_adapter": "multiple_choice_logits",
"output_types": [
"multiple_choice_logits",
"generation"
],
"subset_list": [
"ARC-Easy",
"ARC-Challenge"
],
"metric_list": [
"AverageAccuracy"
],
"few_shot_num": 0,
"few_shot_random": false,
"train_split": "train",
"eval_split": "test",
"prompt_template": "The following are multiple choice questions, please output correct answer in the form of A or B or C or D, do not output explanation:\n{query}",
"system_prompt": null,
"query_template": null,
"pretty_name": "ARC",
"filters": null
}
},
"dataset_dir": "/home/turboai/.cache/modelscope/hub/datasets",
"dataset_hub": "modelscope",
"generation_config": {
"max_length": 2048,
"max_new_tokens": 512,
"do_sample": false,
"top_k": 50,
"top_p": 1.0,
"temperature": 1.0
},
"eval_type": "checkpoint",
"eval_backend": "Native",
"eval_config": null,
"stage": "all",
"limit": 5,
"eval_batch_size": 1,
"mem_cache": false,
"use_cache": null,
"work_dir": "./outputs/20250311_085709",
"outputs": null,
"debug": false,
"dry_run": false,
"seed": 42,
"api_url": null,
"api_key": "EMPTY",
"timeout": null,
"stream": false
}
2025-03-11 08:57:36,163 - evalscope - INFO - **** Start evaluating on dataset modelscope/gsm8k ****
2025-03-11 08:57:36,163 - evalscope - INFO - Loading dataset from hub: modelscope/gsm8k
2025-03-11 08:57:36,387 - evalscope - INFO - Loading dataset: dataset_name: modelscope/gsm8k > subsets: ['main']
2025-03-11 08:57:36,387 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from gsm8k. Please make sure that you can trust the external codes.
2025-03-11 08:57:37,552 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/gsm8k. Please make sure that you can trust the external codes.
2025-03-11 08:57:37,552 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/gsm8k. Please make sure that you can trust the external codes.
Predicting(main): 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [02:33<00:00, 30.79s/it]
2025-03-11 09:00:24,191 - evalscope - INFO - Dump predictions to ./outputs/20250311_085709/predictions/gsm8k_main.jsonl.
Reviewing(main): 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 3006.24it/s]
2025-03-11 09:00:24,197 - evalscope - INFO - Dump report: ./outputs/20250311_085709/reports/gsm8k.json
2025-03-11 09:00:24,200 - evalscope - INFO - Report table:
+---------+-----------+-----------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=========+===========+=================+==========+=======+=========+=========+
| | gsm8k | AverageAccuracy | main | 5 | 0.6 | default |
+---------+-----------+-----------------+----------+-------+---------+---------+
2025-03-11 09:00:24,200 - evalscope - INFO - **** Evaluation finished on modelscope/gsm8k ****
2025-03-11 09:00:24,200 - evalscope - INFO - **** Start evaluating on dataset modelscope/ai2_arc ****
2025-03-11 09:00:24,200 - evalscope - INFO - Loading dataset from hub: modelscope/ai2_arc
2025-03-11 09:00:24,200 - evalscope - INFO - Loading dataset: dataset_name: modelscope/ai2_arc > subsets: ['ARC-Easy', 'ARC-Challenge']
2025-03-11 09:00:24,200 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:25,441 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:25,441 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:25,441 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:32,825 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:33,752 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:33,752 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:33,752 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:43,019 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:45,431 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:45,431 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:45,432 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:55,263 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:56,283 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:56,283 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:00:56,283 - modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from modelscope/ai2_arc. Please make sure that you can trust the external codes.
2025-03-11 09:01:02,645 - evalscope - INFO - Use default settings: > few_shot_num: 0, > few_shot_split: train, > target_eval_split: test
Predicting(ARC-Easy): 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 16.81it/s]
2025-03-11 09:01:03,219 - evalscope - INFO - Dump predictions to ./outputs/20250311_085709/predictions/arc_ARC-Easy.jsonl.
Reviewing(ARC-Easy): 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 5655.75it/s]
Predicting(ARC-Challenge): 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 19.15it/s]
2025-03-11 09:01:03,483 - evalscope - INFO - Dump predictions to ./outputs/20250311_085709/predictions/arc_ARC-Challenge.jsonl.
Reviewing(ARC-Challenge): 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 5959.51it/s]
2025-03-11 09:01:03,488 - evalscope - INFO - Dump report: ./outputs/20250311_085709/reports/arc.json
2025-03-11 09:01:03,492 - evalscope - INFO - Report table:
+---------+-----------+-----------------+---------------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=========+===========+=================+===============+=======+=========+=========+
| | arc | AverageAccuracy | ARC-Easy | 5 | 0.4 | default |
+---------+-----------+-----------------+---------------+-------+---------+---------+
| | arc | AverageAccuracy | ARC-Challenge | 5 | 0.2 | default |
+---------+-----------+-----------------+---------------+-------+---------+---------+
| | gsm8k | AverageAccuracy | main | 5 | 0.6 | default |
+---------+-----------+-----------------+---------------+-------+---------+---------+
2025-03-11 09:01:03,492 - evalscope - INFO - **** Evaluation finished on modelscope/ai2_arc ****
评测结果显示:
- gsm8k(数学问题)得分0.6,
- arc(简单考试,难度考试)得分0.2~0.4
虽然只是简单的测试,但 QwQ-32B 的表现已经 超过了 qwen2.5-70B 的得分! 考虑到这是一款 32B 参数的模型,其性能表现已经相当出色。
五、总结
通过本文的部署教程和简单评测,我们可以看到:
- QwQ-32B 模型部署友好: 无论是原生 ModelScope 部署还是 Ollama 量化部署,都非常简单快捷。
- 老旧 GPU 也能流畅运行: 在 V100 这样的老旧 GPU 上,QwQ-32B 也能跑起来,甚至 Ollama 量化版本对硬件要求更低。
- 性能表现亮眼: 评测数据和简单测试都表明,QwQ-32B 在多个任务上都展现出优秀的性能。
如果你也想体验这款“平民级”大模型,不妨按照本文教程,让你的老旧 GPU 焕发新生! 相信 QwQ-32B 会给你带来意想不到的惊喜!
文末互动:你在低配设备上部署过哪些大模型?欢迎评论区分享经验!

















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









