



引言
智源研究院发布了一款开源的中英文语义向量模型BGE(BAAI General Embedding),在中英文语义检索精度与整体语义表征能力方面全面超越了OpenAI、Meta等同类模型。BGE模型的发布,标志着语义向量模型(Embedding Model)在搜索、推荐、数据挖掘等领域的应用迈入了一个新的阶段。
模型性能
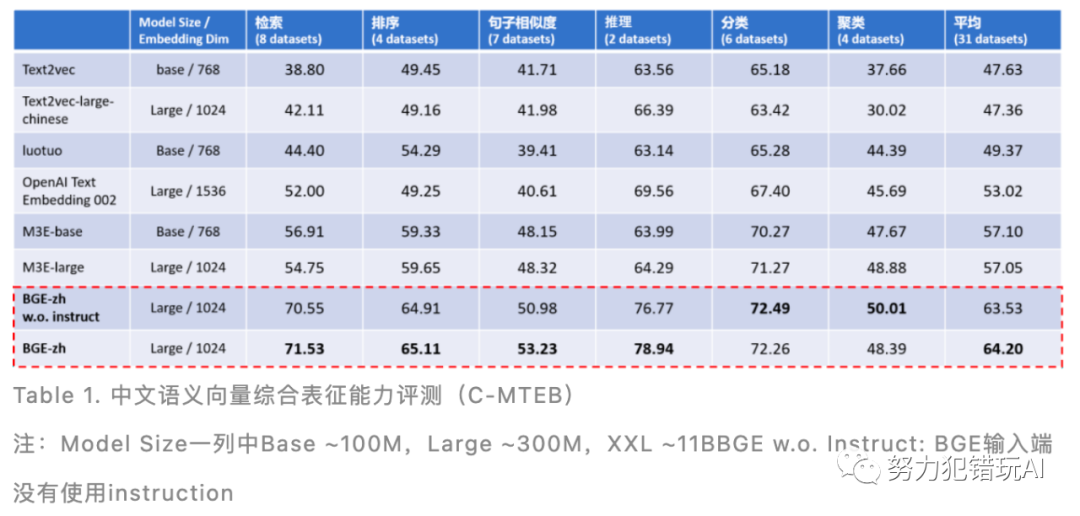
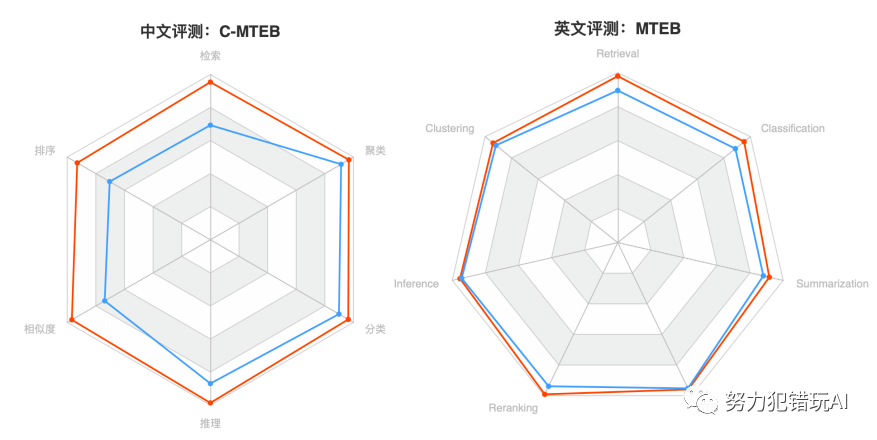
BGE模型在中文语义向量综合表征能力评测C-MTEB中表现卓越。在检索精度方面,BGE中文模型(BGE-zh)约为OpenAI Text Embedding 002的1.4倍。
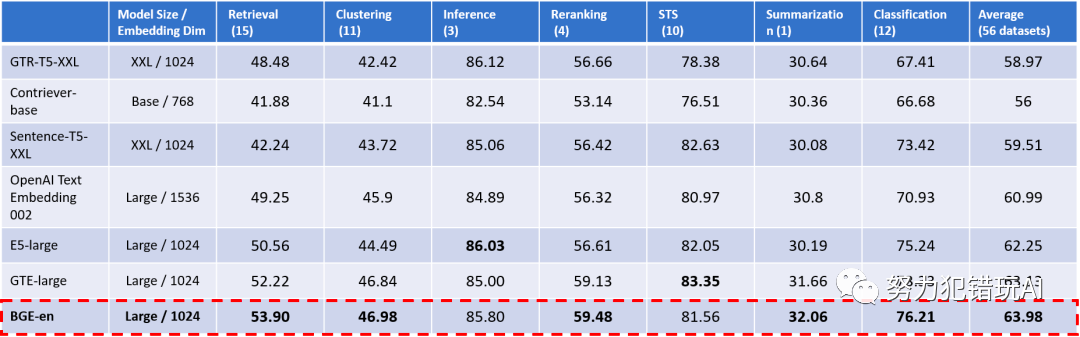
此外,BGE英文模型(BGE-en)在英文评测基准MTEB中同样展现了出色的语义表征能力,总体指标与检索能力两个核心维度均超越了此前开源的所有同类模型。
技术创新
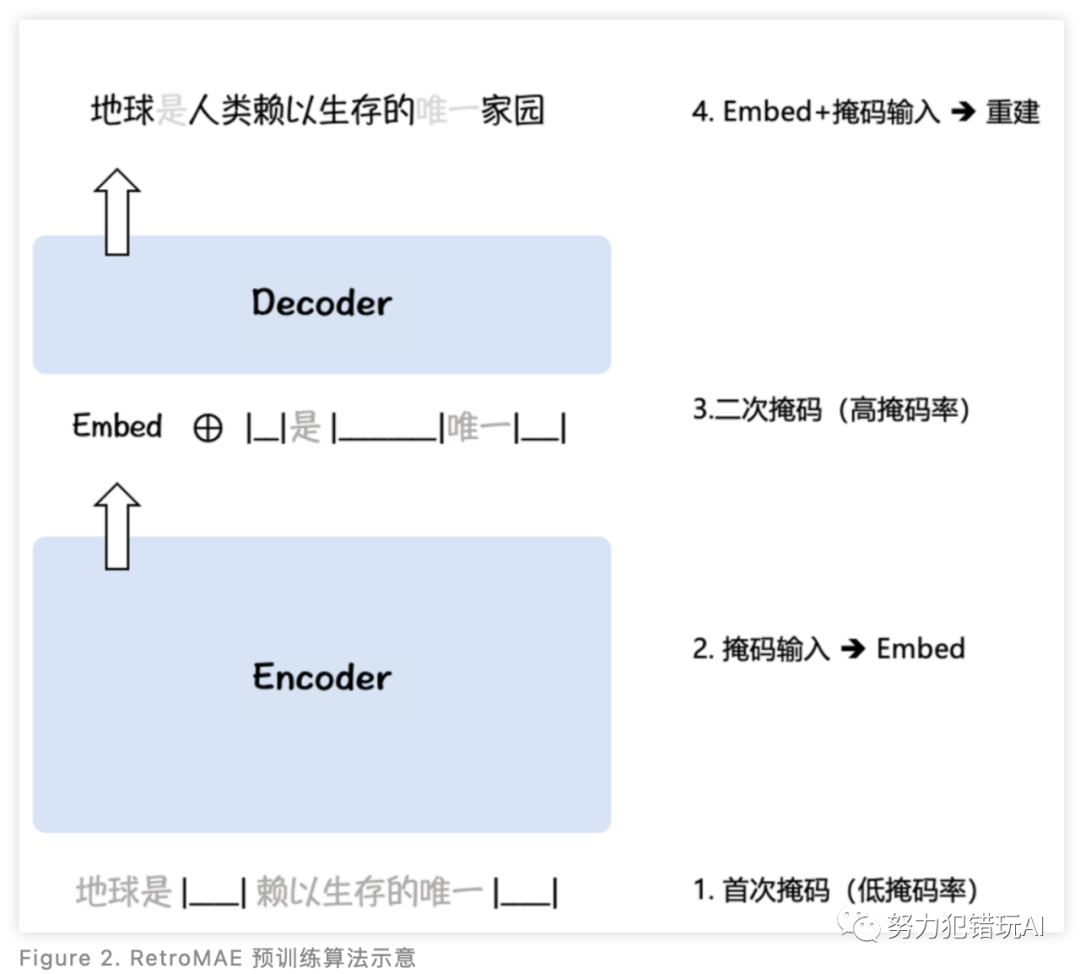
BGE模型的卓越性能源于其高效的预训练和大规模文本对微调两方面要素。BGE采用了针对表征的预训练算法RetroMAE,利用无标签语料实现语言模型基座对语义表征任务的适配。同时,BGE针对中文、英文分别构建了多达120M、232M的样本对数据,帮助模型掌握实际场景中各种不同的语义匹配任务。
应用前景
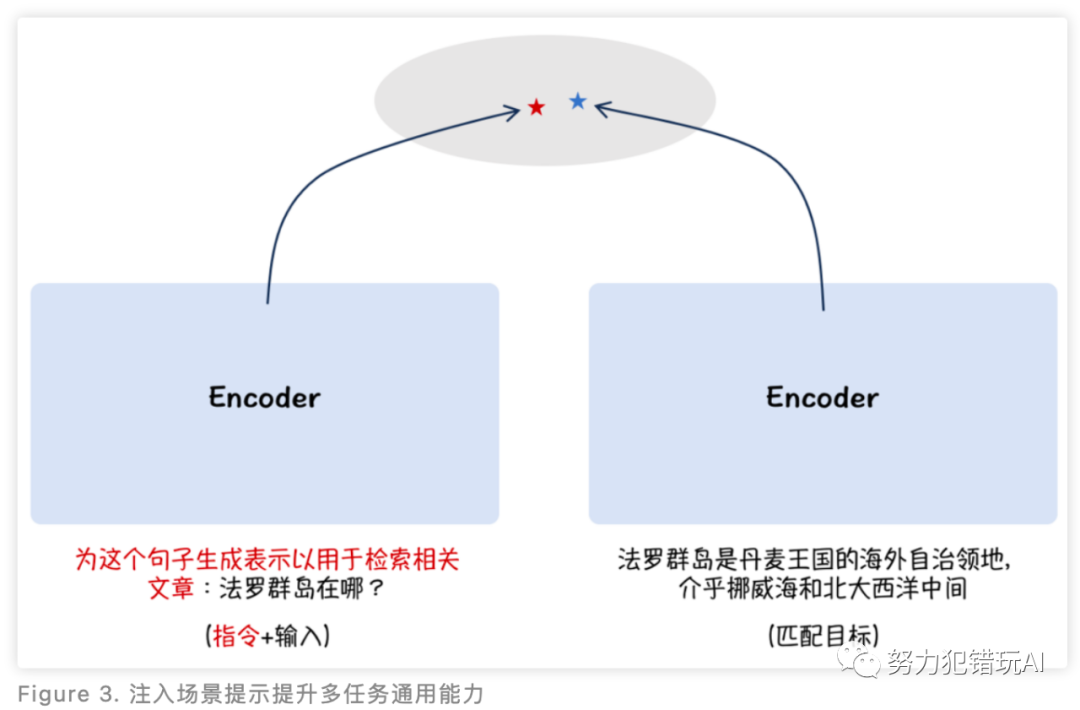
此外,BGE模型在技术上还采取了非对称的指令添加方式,提升了语义向量在多任务场景下的通用能力。这一创新使得BGE模型在构建大语言模型应用(如阅读理解、开放域问答、知识型对话)时,展现了更加强大的功能。
效率与开源
值得一提的是,BGE模型在保持卓越性能的同时,并未增加模型规模与向量的维度,因而保持了相同的运行、存储效率。目前,BGE中英文模型均已开源,代码及权重均采用MIT协议,支持免费商用。
结论
总结来说,BGE模型的发布,不仅为中英文语义向量模型领域带来了一次重大突破,也为大模型生态基础设施建设提供了强有力的支持。其在语义检索能力上的领先优势,以及在多任务场景下的通用能力,都预示着BGE将在未来的大模型应用开发中发挥重要作用。
参考资料
Github
https://github.com/FlagOpen/FlagEmbedding
HuggingFace
https://huggingface.co/BAAI/
AI快站模型免费加速下载
https://aifasthub.com/models/BAAI


















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









