





目录
第一章 系统综述与理论基础
1.1 引言:为什么我们需要低频词提取系统
在信息爆炸的当代,每天都有海量的英文文本需要被处理和理解。这些文本可能来自学术论文、新闻报道、社交媒体或者各类数字内容。然而,不是所有的词汇都对理解文本的核心意义具有同等重要性。当我们阅读一篇文章时,那些频繁出现的词汇(如"the"、"is"、"and")通常不承载多少语义信息,反而是那些出现次数较少但具有特定含义的词汇往往才是真正揭示文本主题的关键。
低频词(rare words)提取系统的存在价值正在于此。它能够自动识别和分析那些在文本中出现不频繁但具有高度信息含量的词汇。想象一下,如果你需要快速理解一篇关于量子计算的论文,与其花时间在常见词汇上,不如直接关注那些专业术语和低频词汇——这些词汇往往就是该领域的核心概念所在。本系统采用现代的自然语言处理框架spaCy替代了过时的NLTK库,这一选择解决了长期困扰研究者的模型加载和数据依赖问题。
让我们看看系统的入口代码,它是一个标准的Python GUI应用程序入口:
# ==================== 程序入口 ====================
def main():
"""程序主入口"""
root = tk.Tk()
app = EnglishNLPGUI(root)
root.mainloop()
if __name__ == '__main__':
main()
这个看似简洁的代码实际上启动了一个完整的NLP分析系统。当Python脚本被执行时,它首先创建一个tkinter的根窗口对象tk.Tk(),这是所有GUI组件的容器。然后创建EnglishNLPGUI的实例,将根窗口传入。GUI类的构造函数会设置所有的用户界面元素。最后调用root.mainloop()进入事件循环,这个循环会不断地监听用户的交互事件,直到用户关闭窗口。
1.2 系统的核心价值与应用场景
这个系统的核心价值体现在多个方面。首先,它提供了一种自动化的、可靠的方式来识别文本中具有高信息密度的词汇。在学术研究领域,这对于快速抽取关键术语、构建领域词表具有重要意义。在内容分析和信息检索中,低频词往往对于文本的分类和聚类有特殊的指示作用——因为频繁词汇倾向于在各类文本中都出现,而低频词更能区分不同的内容主题。
系统通过集成多种分析维度,使用户能够从不同角度理解文本的语言特征。TF-IDF分析提供了词汇重要性的量化评估,聚类分析能够发现低频词之间的语义关系和主题聚集,而新词识别则帮助研究者发现可能的复合词或新的语言现象。这种多维度的分析方式远比简单的词频统计更加深入和有洞察力。
看一个具体的应用场景代码,这来自系统的统计分析方法:
def get_statistics(self) -> Dict:
"""
获取文本统计指标
"""
# 计算基本统计量
total_words = len(self.words) # 总词数(包括重复)
unique_words = len(set(self.words)) # 独特词数(去重后)
total_sentences = len(self.sentences) # 句子总数
# 词汇多样性 = 独特词数 / 总词数,范围是0-1
# 这个指标越接近1,表示文本词汇越多样化
lexical_diversity = unique_words / total_words if total_words > 0 else 0
# 统计低频词数量
rare_word_count = len([w for w in self.words if self.word_freq[w] <= 2])
# 低频词比例 = 低频词总数 / 总词数
# 高比例表示文本使用了许多稀有词汇,可能是专业性强的文本
rare_word_ratio = rare_word_count / total_words if total_words > 0 else 0
# 平均句长 = 总词数 / 句子数
# 这反映了文本的句子复杂程度
avg_sentence_length = total_words / total_sentences if total_sentences > 0 else 0
return {
'总词数': total_words,
'独特词数': unique_words,
'句子数': total_sentences,
'词汇多样性': round(lexical_diversity, 4),
'平均句长': round(avg_sentence_length, 2),
'低频词比例': round(rare_word_ratio, 4),
'低频词总数': rare_word_count,
}
这个方法展示了系统如何从多个角度分析文本。每一个指标都告诉我们关于文本的不同信息——总词数反映了文本的规模,词汇多样性反映了文本的语言丰富程度,低频词比例反映了文本的专业性和新颖性。这些指标共同作用,为用户提供了一个全面的文本特征画像。
1.3 从NLTK到spaCy:技术框架的演进
了解系统为什么选择spaCy而不是传统的NLTK库,需要我们深入理解这两个框架的本质差异。NLTK(Natural Language Toolkit)是一个历史悠久的自然语言处理工具包,在二十年前曾经是该领域的标准工具。它提供了分词、词性标注、依存分析等多种功能,被广泛应用于教学和研究。然而,NLTK的一个主要问题在于它采用了模块化的设计,许多功能需要依赖外部的数据资源。
相比之下,spaCy是一个更现代、更整合的NLP框架。它采用了"一体化模型"的设计思想,将分词、词性标注、依存分析、命名实体识别等功能集成在单个预训练模型中。这意味着用户只需要下载一个模型文件,就能够获得完整的NLP处理管道。spaCy的模型是基于神经网络训练的,通常比传统方法提供更高的准确度。从性能角度来看,spaCy也有显著优势——它使用了高效的C扩展,处理速度比NLTK快得多。
让我们看看系统中处理这个选择的核心代码:
# ==================== spaCy模型管理 ====================
class SpacyModelManager:
"""
管理spaCy模型的加载和初始化。
spaCy使用预训练的模型来进行词性标注、依存分析等任务。
与NLTK不同,spaCy的模型是独立的包,可以更方便地下载和管理。
这个类自动处理模型的下载和缓存。
"""
MODEL_NAME = "en_core_web_sm" # 使用轻量级模型,下载快速
@staticmethod
def ensure_model_loaded():
"""
确保spaCy模型已经加载。
如果模型不存在,自动下载。
返回:
加载的spaCy模型对象,或None如果加载失败
"""
try:
# 尝试直接加载模型
# spacy.load()会在多个标准位置搜索已安装的模型
nlp = spacy.load(SpacyModelManager.MODEL_NAME)
print(f"成功加载spaCy模型: {SpacyModelManager.MODEL_NAME}")
return nlp
except OSError:
# OSError表示找不到模型文件
# 这是spaCy找不到指定模型时抛出的异常类型
print(f"模型 {SpacyModelManager.MODEL_NAME} 未找到,正在下载...")
try:
# subprocess.check_call会执行一个shell命令,如同用户在命令行中输入
# [sys.executable, "-m", "spacy", "download", MODEL_NAME]
# 等价于: python -m spacy download en_core_web_sm
# sys.executable确保使用当前Python解释器,这在虚拟环境中特别重要
subprocess.check_call([
sys.executable, "-m", "spacy", "download",
SpacyModelManager.MODEL_NAME
])
# 下载完成后再次加载
nlp = spacy.load(SpacyModelManager.MODEL_NAME)
print(f"成功下载并加载spaCy模型")
return nlp
except Exception as e:
# 如果下载失败(可能是网络问题),捕获异常并返回None
print(f"下载spaCy模型失败: {e}")
return None
这个SpacyModelManager类是系统优雅设计的一个很好例子。它采用了"尝试-恢复"的模式。首先尝试加载已有的模型,这是最快的路径——如果用户之前已经安装过模型,程序会立即启动。如果模型不存在(OSError异常),系统自动下载它。这个自动下载过程对用户完全透明,用户不需要理解任何关于模型安装的技术细节,只需要确保网络连接正常即可。
这里的关键技术是使用subprocess模块来调用系统命令。sys.executable获取当前Python解释器的路径,这确保了命令会使用正确的Python环境(特别是在虚拟环境中)。"-m"标志告诉Python将"spacy"作为一个模块执行,这会调用spacy包的命令行接口。这样的设计避免了在Python代码中直接实现模型下载逻辑的复杂性,而是利用spacy本身提供的下载功能。
第二章 自然语言处理的基础理论与spaCy框架
2.1 自然语言处理的核心概念
要理解这个系统的工作原理,我们首先需要掌握自然语言处理的几个核心概念。自然语言处理(NLP)的根本目标是使计算机能够理解和生成人类语言。这听起来简单,但实际上包含了极其复杂的挑战。人类语言充满了歧义、上下文依赖性和文化特殊性。
分词(tokenization)是NLP处理流程的第一步,也是至关重要的一步。虽然看起来只是简单地将文本分割成单词,但实际上它涉及众多细微之处。例如,缩写词(如"don't"应该分成"do"和"n't"还是保持为一个词元?)、复合词(如"mother-in-law")以及标点符号的处理都需要精心考虑。spaCy的分词器是基于规则和统计模型训练的,能够正确地处理这些复杂情况,远优于简单的正则表达式分割。
词性标注(Part-of-Speech tagging)是识别每个词在句子中的语法角色的过程。同一个单词在不同的上下文中可能具有不同的词性——比如单词"book"既可以是名词("a good book")也可以是动词("book a flight")。spaCy使用了基于神经网络的词性标注器,它考虑了单词的前后文脉络。
让我们看看系统如何实现分词和词性标注的:
def _tokenize_words(self, text: str) -> List[str]:
"""
分词
使用spaCy进行分词处理。spaCy的分词器能正确处理
缩写词和标点符号。
"""
if self.nlp is None:
# 降级模式:简单的正则表达式分词
# 这个正则表达式匹配由字母组成的单词,或者带有撇号的缩写词
# \b表示单词边界,[a-z]+匹配一个或多个小写字母
# (?:\'[a-z]+)?是一个非捕获组,表示可选的撇号后跟字母
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
else:
try:
# 使用spaCy进行处理
doc = self.nlp(text.lower()) # 创建spaCy文档对象,并转换为小写
# 过滤掉纯标点符号和停词,但保留收缩词
words = [
token.text for token in doc
# token.text是token的文本表示
# isalnum()检查是否由字母数字组成(True则是有效词汇)
if token.text.isalnum() or token.text in ["n't", "'s", "'re", "'ve", "'d", "'ll", "'m"]
# 特定的英文缩略后缀总是保留
]
except:
# 如果spaCy处理失败,回退到正则表达式方法
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
return words
这个方法展示了系统的两层策略。首先是理想情况,使用spaCy进行处理。spaCy会自动识别缩写词、复合词等复杂情况。例如,对于"don't",spaCy会将其分为两个token:"do"和"n't"。然后代码检查每个token是否应该被保留:如果它由字母数字组成(isalnum()为True),或者它是特定的英文缩略后缀,就保留它。这个逻辑避免了保留纯标点符号(如独立的逗号或句号)。
代码中的降级模式(当spaCy不可用时)使用了一个正则表达式。这个表达式足够简洁但也足够聪慧——它能处理基本的单词分割和撇号情况。虽然它不能完全复制spaCy的功能,但对于简单的文本仍然有效。这种设计确保了系统的鲁棒性,即使在某些故障场景下也能继续运行。
词性标注的实现如下:
def _extract_pos_tags(self):
"""
提取词性标签
使用spaCy进行词性标注。如果spaCy不可用,则使用默认标签。
"""
self.pos_tags = []
if self.nlp is None:
# 降级模式:所有词都标注为NOUN
# 这是一个简化的假设,虽然不准确,但提供了基本功能
for word in self.words:
self.pos_tags.append((word, 'NOUN'))
else:
try:
# 将words列表(已经是分好的词汇列表)重新组合成字符串
# 然后交给spaCy进行处理
text = ' '.join(self.words)
doc = self.nlp(text)
# 对每个token提取其文本和词性标签
# token.pos_是spaCy的通用词性标签(如NOUN, VERB, ADJ等)
# 还有token.tag_提供更细致的标签
self.pos_tags = [(token.text, token.pos_) for token in doc]
except:
# 异常处理:如果处理失败,回退到所有词标注为NOUN
for word in self.words:
self.pos_tags.append((word, 'NOUN'))
这个方法的实现同样遵循了两层策略。当spaCy可用时,它使用spaCy的词性标注器,这是一个基于神经网络的模型,能够根据上下文准确地判断每个词的词性。当spaCy不可用时,系统简单地将所有词标注为名词(NOUN)。虽然这是一个粗糙的近似,但考虑到这是一个"降级模式",目的是在环境不理想的情况下提供基本功能,这样的设计是合理的。
2.2 spaCy的处理管道与模型架构
spaCy的核心是其处理管道(processing pipeline)的概念。当你将一段文本输入到spaCy模型时,它不是直接进行处理,而是通过一系列顺序连接的"管道组件"来处理。每个组件负责一项特定的任务,完成后将结果传递给下一个组件。这个设计非常优雅,因为它允许高度的模块化和可扩展性。
系统中使用的"en_core_web_sm"模型包含了标准的组件。"sm"后缀表示这是一个小型模型,经过优化以提供最快的处理速度,同时保持合理的准确度。这个选择对于这个系统是合理的,因为我们的主要关注点是低频词的识别和分析,而不是精确的语法解析。
让我们看看系统初始化这个模型的完整过程:
# 尝试导入spaCy,如果失败则安装
try:
import spacy
except ImportError:
print("正在安装spaCy...")
# os.system会执行shell命令
# 这在没有spaCy的环境中自动安装它
os.system("pip install spacy")
import spacy
这个代码片段展示了系统的自我修复能力。在最严格的环境中,甚至spaCy库本身可能都没有安装。系统会检测到ImportError异常(这在import失败时抛出),然后自动通过pip安装spaCy。之后重新尝试import。这个"自助安装"的设计大大降低了用户的配置负担。
2.3 模型加载与初始化的优雅方案
模型管理器中的另一个重要方面是处理各种依赖库的安装。系统在开始时检查多个关键库:
try:
import chardet
except ImportError:
os.system("pip install chardet")
import chardet
# 尝试导入spaCy,如果失败则安装
try:
import spacy
except ImportError:
print("正在安装spaCy...")
os.system("pip install spacy")
import spacy
try:
import numpy as np
except ImportError:
os.system("pip install numpy")
import numpy as np
try:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
except ImportError:
os.system("pip install scikit-learn")
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
这种模式重复了多次,每次都处理一个可能缺失的库。虽然从代码风格的角度看这似乎有些冗余,但从用户体验的角度看,这是必要的。每个库可能由于不同的原因失败安装(网络问题、权限问题等),独立处理每个库确保了即使某个库安装失败,系统仍然可以尝试安装其他库。这样的设计使系统对环境的要求更加宽松。
第三章 系统架构与模块设计
3.1 四层架构的设计理念
这个系统采用了经典的分层架构设计,将不同的职责分离到不同的模块中。从下往上,我们可以识别出四个清晰的层次。最底层是模型管理层,包含SpacyModelManager类,负责与spaCy框架的交互和模型的加载。这一层的设计使得系统与具体的NLP框架解耦,在理论上,如果将来需要更换NLP框架(比如使用BERT或其他框架),只需要修改这一层的实现即可。
第二层是文件处理层,由FileHandler类承担。这一层处理所有与文件系统交互的逻辑,包括路径规范化、文件验证、编码检测和文件读取。将文件处理逻辑单独提取出来是很有必要的,因为在不同的操作系统上,文件路径的处理方式完全不同。
第三层是核心分析层,由EnglishTextAnalyzer类构成。这个类是整个系统的大脑,包含了所有主要的文本处理和分析逻辑。它负责文本清洗、句子分割、分词、词性标注、低频词识别、TF-IDF计算、聚类等任务。
最上层是用户交互层,由EnglishNLPGUI类提供。这是用户直接接触的界面,处理所有与图形用户界面相关的逻辑。
让我们看看这个架构在初始化时是如何工作的:
class EnglishTextAnalyzer:
"""
英文文本分析引擎,使用spaCy进行自然语言处理。
"""
def __init__(self):
"""初始化分析器,加载spaCy模型"""
self.original_text = "" # 原始输入文本
self.cleaned_text = "" # 清洗后的文本
self.sentences = [] # 分割后的句子列表
self.words = [] # 分词后的单词列表
self.word_freq = Counter() # 词频计数器,使用Counter类方便统计
self.pos_tags = [] # 词性标签列表,每个元素是(word, pos_tag)元组
self.rare_words = [] # 低频词列表
# 加载spaCy模型
self.nlp = SpacyModelManager.ensure_model_loaded()
if self.nlp is None:
print("警告:spaCy模型加载失败,将使用降级模式")
# 英文停词集合
# 这些词汇虽然在语言中频繁出现,但对于语义分析通常不如实词重要
self.stopwords = set([
'a', 'an', 'and', 'are', 'as', 'at', 'be', 'by', 'for', 'from',
'has', 'he', 'in', 'is', 'it', 'its', 'of', 'on', 'or', 'that',
'the', 'to', 'was', 'will', 'with', 'would', 'could', 'should',
'may', 'might', 'must', 'can', 'have', 'had', 'do', 'does', 'did',
'i', 'me', 'my', 'we', 'you', 'your', 'him', 'her', 'this', 'these'
])
这个初始化方法建立了EnglishTextAnalyzer类的基本状态。每个数据成员都被初始化为适当的类型:字符串、列表或Counter对象。Counter类来自collections模块,是一个特别适合词频统计的数据结构——它继承自dict,但以词汇为键,频率为值。最重要的是,初始化代码调用了SpacyModelManager来加载模型,如果加载失败,系统会打印警告但继续运行。
停词集合使用了集合(set)数据结构,这是一个明智的选择。当我们需要检查某个词是否在停词列表中时,集合的查找时间是O(1),而列表的查找时间是O(n)。在后续处理数十万个词汇时,这个性能差异会累积成显著的时间节省。
3.2 文件处理层的设计考量
FileHandler类的设计反映了实际工程中经常被忽视但又非常重要的问题。文件路径看起来是一个简单的字符串,但在跨平台应用中,路径处理涉及众多微妙之处。让我们详细看看这一层的实现:
class FileHandler:
"""
文件处理的辅助类,专门处理文件路径识别和编码检测问题
"""
@staticmethod
def normalize_path(file_path: str) -> str:
"""规范化文件路径,处理各种不同系统和格式的路径"""
# Path.resolve()会将相对路径转换为绝对路径,并规范化路径分隔符
path = Path(file_path).resolve()
# 在Windows上,Path对象会自动使用反斜杠
# 在Unix系统上会使用正斜杠
# 这个转换确保了路径在当前操作系统上是有效的
return str(path)
@staticmethod
def validate_file(file_path: str) -> Tuple[bool, str]:
"""验证文件是否存在和可读"""
try:
path = Path(file_path).resolve()
# 第一层检查:文件是否存在
if not path.exists():
return False, f"文件不存在: {file_path}"
# 第二层检查:路径是否真的指向文件而不是目录
if not path.is_file():
return False, f"路径不是文件: {file_path}"
# 第三层检查:文件是否可读
# os.access()检查当前用户是否有指定权限
# os.R_OK表示可读权限
if not os.access(path, os.R_OK):
return False, f"文件无读取权限: {file_path}"
# 第四层检查:文件是否为空
# 空文件在技术上是有效的,但通常不是用户的意图
if path.stat().st_size == 0:
return False, f"文件为空: {file_path}"
# 所有检查通过
return True, ""
except Exception as e:
# 捕获任何其他异常(如权限错误等)
return False, f"文件验证失败: {str(e)}"
这个方法展示了防御性编程的重要性。通过一系列的检查,系统能够在问题发生之前就识别它们,而不是在后续处理中产生模糊的错误。每一个检查都解决了一个真实的问题:文件可能不存在(用户输入错误的路径),路径可能指向目录而不是文件(用户选择了错误的项),文件可能无法读取(权限问题),或者文件可能是空的(数据问题)。
更关键的是编码检测方法,这是文件处理中最复杂的部分:
@staticmethod
def detect_encoding(file_path: str) -> str:
"""检测文件编码"""
try:
path = Path(file_path).resolve()
# 读取文件的前100KB用于编码检测
# 这个大小是一个平衡点:足够大以获得准确的统计,但不会过慢
with open(path, 'rb') as f:
raw_data = f.read(100000)
# 使用chardet库进行自动编码检测
# chardet基于统计和启发式算法检测编码
detected = chardet.detect(raw_data)
encoding = detected.get('encoding')
confidence = detected.get('confidence', 0)
# 只有当chardet的置信度超过70%时,才相信它的结果
# 置信度是0-1之间的值,表示chardet对检测结果的信心程度
if encoding and confidence > 0.7:
return encoding
# 如果chardet不确定,尝试常见的编码列表
# 列表顺序很重要:更可能的编码放在前面
for enc in ['utf-8', 'utf-8-sig', 'gbk', 'gb2312', 'ascii', 'latin-1']:
try:
# 尝试用指定编码打开文件并读取1000个字符
# 如果这个操作成功,说明编码可能是正确的
with open(path, 'r', encoding=enc) as f:
f.read(1000)
# 如果没有抛出异常,返回这个编码
return enc
except:
# 如果这个编码失败,继续尝试下一个
continue
# 如果所有尝试都失败,默认使用UTF-8
return 'utf-8'
except Exception as e:
print(f"编码检测失败: {e},使用默认编码 utf-8")
return 'utf-8'
这个编码检测的多层策略非常精妙。首先是使用chardet库进行自动检测,这对大多数情况有效。但chardet并不总是准确的,所以代码检查了置信度阈值。如果chardet不确定,系统进入第二阶段,主动尝试常见的编码。这个列表按照概率排序——UTF-8是现代文本的标准,但考虑到系统可能处理旧文件,GBK(中文)和Latin-1(欧洲)也被包括进来。
关键的设计洞察是,对于每个编码,系统不仅仅检查它是否能够打开文件(这几乎总是成功的),而是实际尝试读取内容。这是因为某些编码的解码可能在处理文件的第一部分时就会失败。例如,如果一个文件确实是UTF-8但被错误地用Latin-1打开,当遇到非ASCII字节时会立即失败。这个"实际尝试"的方法比简单地检查编码声明更可靠。
最后,read_file方法组合了所有这些能力:
@staticmethod
def read_file(file_path: str) -> Tuple[bool, str, str]:
"""读取文件内容,带有完整的错误处理"""
# 首先验证文件
is_valid, error_msg = FileHandler.validate_file(file_path)
if not is_valid:
# 如果验证失败,直接返回失败状态
return False, "", error_msg
try:
normalized_path = FileHandler.normalize_path(file_path)
# 检测文件编码
encoding = FileHandler.detect_encoding(normalized_path)
print(f"检测到编码: {encoding}")
# 使用检测到的编码打开文件
# errors='replace'参数表示如果某个字节无法解码,
# 就用替换字符(通常是?)代替,而不是抛出异常
with open(normalized_path, 'r', encoding=encoding, errors='replace') as f:
content = f.read()
# 检查内容是否为空或只包含空白符
if not content.strip():
return False, "", "文件内容为空"
return True, content, ""
except Exception as e:
error_msg = f"读取文件失败: {str(e)}"
return False, "", error_msg
这个方法建立在前面所有的验证和检测之上,形成了一个完整的错误处理流程。它按顺序进行多个步骤,每个步骤都可能失败,并且每次失败都返回适当的错误信息。errors='replace'参数是一个巧妙的选择——它允许即使在最坏的编码检测情况下,文件仍然能够被读取,只是某些字符可能被替换为问号。这确保了系统的鲁棒性。
3.3 核心分析引擎的功能分解
EnglishTextAnalyzer类的设计采用了"单一职责原则",每个方法都负责一个特定的任务。让我们看看最关键的分析流程:
def load_text(self, file_path: str) -> Tuple[bool, str]:
"""
加载英文文本文件
参数:
file_path: 文件路径
返回:
(成功标志, 错误信息)的元组
"""
# 使用FileHandler读取文件
success, content, error_msg = FileHandler.read_file(file_path)
if not success:
# 如果读取失败,直接返回
return False, error_msg
try:
# 保存原始文本以供后续显示
self.original_text = content
# 启动分析管道
self._analyze_text()
return True, ""
except Exception as e:
return False, f"文本分析失败: {str(e)}"
def _analyze_text(self):
"""
分析文本的完整管道
这个方法执行文本分析的所有步骤。使用spaCy进行处理。
"""
# 第一步:文本清洗
self.cleaned_text = self._clean_text(self.original_text)
# 第二步:句子分割
self.sentences = self._split_sentences(self.cleaned_text)
# 第三步:分词
self.words = self._tokenize_words(self.cleaned_text)
# 第四步:词频计数
# Counter会自动计算每个词出现的次数
self.word_freq = Counter(self.words)
# 第五步:提取低频词
self._extract_rare_words()
# 第六步:进行词性标注
self._extract_pos_tags()
这个分析管道遵循了一个逻辑的顺序:先清洗文本,然后分割成句子,接着分词,最后进行词性标注和低频词提取。每一步都建立在前一步的结果之上。这个顺序是重要的——例如,必须先分词,然后才能进行词频计数;必须先有词汇列表,才能进行词性标注。
_clean_text方法展示了系统如何处理真实世界的混乱文本:
def _clean_text(self, text: str) -> str:
"""
清洗文本
移除不可见字符、URL、电子邮件地址和多余的空白符。
"""
# 移除URL:匹配任何http://或https://开头的连续非空格字符
text = re.sub(r'http[s]?://\S+', '', text)
# 移除电子邮件:匹配任何包含@符号的序列
text = re.sub(r'\S+@\S+', '', text)
# 移除HTML标签:匹配任何尖括号包围的内容
text = re.sub(r'<[^>]+>', '', text)
# 移除控制字符,但保留特定的空白字符
# ord(char)返回字符的Unicode值
# 32是空格的值,小于32的字符是控制字符
text = ''.join(
char for char in text
if ord(char) >= 32 or char in '\n\t\r'
)
# 规范化多个空行:将多个连续的空行压缩为两个
# \n\s*\n+匹配换行符-任意空白-换行符的序列
text = re.sub(r'\n\s*\n+', '\n\n', text)
# 移除行尾空格,并只保留非空行
lines = [line.strip() for line in text.split('\n') if line.strip()]
return '\n'.join(lines)
这个文本清洗方法通过一系列的正则表达式操作逐步移除各种类型的垃圾内容。每一个操作都针对一种特定的问题:URL和电子邮件来自网络文本,HTML标签来自网页内容,控制字符可能来自各种编码错误或文件格式转换。通过按顺序应用这些操作,系统能够处理各种真实世界的文本输入。
关键的设计决策是保留换行符和制表符。这些字符虽然在某些contexts中被认为是"空白",但对于保持文本的结构很重要。例如,换行符是段落的标记,制表符可能表示特定的格式。
3.4 用户界面的设计模式
GUI设计采用了Model-View-Controller(MVC)的思想。让我们看看GUI的初始化如何建立这个分离:
class EnglishNLPGUI:
"""
英文自然语言处理系统的图形用户界面
"""
def __init__(self, root):
"""初始化GUI"""
self.root = root
# 设置窗口标题和初始大小
self.root.title("Advanced English NLP System - Rare Words Extraction (spaCy)")
self.root.geometry("1600x1000") # 宽度x高度,以像素为单位
# 创建分析器对象,这是Model部分
self.analyzer = EnglishTextAnalyzer()
# 跟踪当前打开的文件路径
self.current_file = None
# 创建所有UI元素
self.create_ui()
这个初始化清晰地分离了concerns:self.analyzer是Model(数据和业务逻辑),而其余的代码是View和Controller(用户界面和交互处理)。这样的分离意味着如果需要更换UI(比如从tkinter改为Qt或Web界面),只需要创建新的View-Controller代码,Model可以保持不变。
create_ui方法展示了GUI的整体结构:
def create_ui(self):
"""创建用户界面"""
self.create_menu_bar()
main_frame = ttk.Frame(self.root)
main_frame.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
# 左侧:操作面板
left_frame = ttk.LabelFrame(main_frame, text="Operations", padding=10)
left_frame.pack(side=tk.LEFT, fill=tk.BOTH, padx=(0, 5))
self.create_left_panel(left_frame)
# 中间:文本显示
middle_frame = ttk.LabelFrame(main_frame, text="Text Display", padding=10)
middle_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(0, 5))
self.create_middle_panel(middle_frame)
# 右侧:分析结果
right_frame = ttk.LabelFrame(main_frame, text="Analysis Results", padding=10)
right_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
self.create_right_panel(right_frame)
self.create_status_bar()
这个三列布局充分利用了屏幕空间。左列是操作和参数控制,中列显示输入文本和处理结果的中间步骤,右列展示最终的分析输出。这样的布局对用户来说直观易懂——行动在左边,输入在中间,结果在右边。
第四章 文本预处理的艺术与科学
4.1 文本清洗的多层策略
文本清洗是自然语言处理流程中最容易被低估的环节,但实际上它对最终结果的质量有着深远的影响。想象一下,如果你的文本中包含了大量的URL,那么这些URL中的单词会被作为正常词汇进行处理,从而污染你的词频统计。
让我们深入看看系统如何处理不同类型的垃圾内容。考虑一个典型的网络文本:
def _clean_text(self, text: str) -> str:
"""
清洗文本
"""
# 第一步:移除URL
# 这个正则表达式匹配http://或https://后跟任意非空格字符
# 例如:http://www.example.com/page?param=value会被完全移除
text = re.sub(r'http[s]?://\S+', '', text)
# 第二步:移除电子邮件
# \S+@\S+匹配任何包含@的非空格序列
# 例如:john.doe@company.com会被移除
# 但这也可能匹配某些非电子邮件模式(如文本中的"user@domain")
text = re.sub(r'\S+@\S+', '', text)
# 第三步:移除HTML标签
# <[^>]+>匹配任何尖括号包围的内容
# 例如:<div class="content">会被移除,只保留content
text = re.sub(r'<[^>]+>', '', text)
# 第四步:移除控制字符
# 这对于处理来自不同操作系统或程序的文本特别重要
text = ''.join(
char for char in text
if ord(char) >= 32 or char in '\n\t\r'
)
# 第五步:规范化多余的空行
# 原始文本可能有连续的多个空行,这会影响句子分割
# \n\s*\n+匹配换行符、任意数量的空白字符、然后至少一个换行符
text = re.sub(r'\n\s*\n+', '\n\n', text)
# 第六步:清理行末空格和空行
lines = [line.strip() for line in text.split('\n') if line.strip()]
return '\n'.join(lines)
这个多层清洗策略的设计是逐步的。首先处理大的、明显的垃圾内容(URL、电子邮件、HTML),然后处理细微的格式问题(多余空行、控制字符)。这个顺序很重要,因为移除某种类型的内容可能会暴露其他问题。例如,移除HTML标签后可能会剩下多个空格,这在第六步被处理。
让我们考虑一个实际的例子。假设输入是:
Check out my website: http://example.com/article?id=123
Contact me at: john@example.com
<p>This is a paragraph.</p>
With extra spaces.
逐步处理过程:
- 移除URL后:
Check out my website: \nContact me at: john@example.com\n\n<p>This is a paragraph.</p>\n With extra spaces. - 移除电子邮件后:
Check out my website: \nContact me at: \n\n<p>This is a paragraph.</p>\n With extra spaces. - 移除HTML后:
Check out my website: \nContact me at: \n\nThis is a paragraph.\n With extra spaces. - 规范化空行后:
Check out my website: \nContact me at: \n\nThis is a paragraph.\n With extra spaces.(多余空行已压缩) - 最后清理:
Check out my website:
Contact me at:
This is a paragraph.
With extra spaces.
4.2 编码检测的多策略回退机制
编码问题是跨国际文本处理中的永恒难题。虽然在理想世界中所有文本都应该使用UTF-8编码,但现实中存在大量的历史遗留编码。系统采用的编码检测策略非常实用:
@staticmethod
def detect_encoding(file_path: str) -> str:
"""检测文件编码"""
try:
path = Path(file_path).resolve()
# 读取文件的前100KB用于编码检测
# 为什么是100KB?这是一个平衡点:
# - 足够大(通常足以包含各种字符和统计信息)
# - 不会太大(读取速度快)
with open(path, 'rb') as f: # 以二进制模式打开
raw_data = f.read(100000)
# chardet基于统计分析进行编码检测
# 它分析字节模式,某些编码有特定的字节签名
detected = chardet.detect(raw_data)
encoding = detected.get('encoding')
confidence = detected.get('confidence', 0)
# 置信度阈值:只相信高置信度的检测结果
# 置信度范围是0-1,高于0.7通常表示相当可靠
if encoding and confidence > 0.7:
return encoding
# 如果chardet不确定,进入第二阶段:主动尝试
# 这个列表按照概率顺序排列
for enc in ['utf-8', 'utf-8-sig', 'gbk', 'gb2312', 'ascii', 'latin-1']:
try:
# 实际尝试用该编码解码文件的前1000个字符
# 如果成功,说明这个编码可能是正确的
with open(path, 'r', encoding=enc) as f:
f.read(1000)
# 没有异常被抛出,说明解码成功
return enc
except UnicodeDecodeError:
# 这个编码失败了,继续尝试下一个
continue
except Exception:
# 其他异常也继续尝试
continue
# 如果所有尝试都失败,默认UTF-8
# UTF-8是现代互联网的标准,而且它有特殊的性质:
# - 如果文件真的是UTF-8,用UTF-8打开总会成功
# - 如果文件不是UTF-8,用UTF-8打开时会失败
# 所以如果前面所有尝试都失败了,返回UTF-8也没有坏处
return 'utf-8'
except Exception as e:
print(f"编码检测失败: {e},使用默认编码 utf-8")
return 'utf-8'
这个方法的精妙之处在于它的分层设计。第一层是统计检测(chardet),这是最快的但可能不够准确。第二层是主动尝试,这更慢但更准确。只有当两层都失败时才使用默认值。
让我们考虑几个实际的场景:
场景1:一个UTF-8编码的文件 chardet会以高置信度检测到UTF-8,直接返回。
场景2:一个包含中文的GBK编码文件 chardet可能检测出GBK,但置信度可能不够高。然后尝试UTF-8会失败(因为GBK字节序列不符合UTF-8),尝试GBK会成功,返回GBK。
场景3:一个混合编码的文件(不同部分使用不同编码) 这是一个罕见但真实存在的问题。chardet会基于主要部分做出最佳猜测。如果猜测失败,系统会尝试其他编码。
4.3 句子分割的语言学挑战
句子分割看起来是一个简单的任务——找到句号、感叹号和问号,然后在这些位置进行分割。但英文中充满了例外情况。让我们看看系统如何处理这个:
def _split_sentences(self, text: str) -> List[str]:
"""
分割句子
使用spaCy的句子分割功能,比正则表达式更准确。
"""
if self.nlp is None:
# 降级模式:使用正则表达式
# 这个模式在[.!?]+处分割
# +表示匹配一个或多个这些字符(处理连续的标点)
sentences = re.split(r'[.!?]+', text)
else:
try:
# 使用spaCy进行处理
doc = self.nlp(text)
# spaCy自动识别句子边界
# doc.sents是一个句子对象的迭代器
# 每个sent对象有一个.text属性包含该句子的文本
sentences = [sent.text for sent in doc.sents]
except:
# 如果spaCy处理失败,回退到正则表达式
sentences = re.split(r'[.!?]+', text)
# 清理每个句子(去除前后空白),并只保留非空句子
return [s.strip() for s in sentences if s.strip()]
让我们看看spaCy和正则表达式在句子分割上的区别。考虑这个文本:
Dr. Smith went to the store. He met Prof. Jones there. The meeting cost $3.50. They discussed machine learning, i.e., neural networks, etc.
正则表达式方法的问题:
re.split(r'[.!?]+', text)
会产生:
[
'Dr',
' Smith went to the store',
' He met Prof',
' Jones there',
' The meeting cost $3',
'50',
' They discussed machine learning, i',
'e',
', neural networks, etc',
''
]
看到问题了吗?每个句号都导致分割,包括那些不是句子结束的句号(如"Dr."、"Prof."、"3.50"、"i.e.")。
spaCy的方法: spaCy会产生正确的句子:
[
'Dr. Smith went to the store.',
'He met Prof. Jones there.',
'The meeting cost $3.50.',
'They discussed machine learning, i.e., neural networks, etc.'
]
spaCy能够正确处理这些情况的原因是它使用了一个基于机器学习的模型,该模型是在大规模的文本语料库上训练的。它学会了识别缩写词、小数点等各种特殊情况。这个学习的能力是简单规则或正则表达式无法比拟的。
第五章 英文文本分析引擎的核心运作
5.1 分词与词性标注的联合处理
分词和词性标注虽然是两个独立的任务,但它们在spaCy中是紧密结合的。让我们看看系统如何处理分词:
def _tokenize_words(self, text: str) -> List[str]:
"""
分词
使用spaCy进行分词处理。spaCy的分词器能正确处理
缩写词和标点符号。
"""
if self.nlp is None:
# 降级模式:简单的正则表达式分词
# 这个正则表达式的结构:
# \b - 单词边界
# [a-z]+ - 一个或多个小写字母
# (?:\'[a-z]+)? - 可选的:撇号后跟一个或多个字母
# \b - 单词边界
# 例如匹配:'hello', 'don't', 'it's'
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
else:
try:
# 使用spaCy进行处理
doc = self.nlp(text.lower())
# 过滤掉纯标点符号和停词,但保留收缩词
words = [
token.text
for token in doc
# token.text是token的文本表示
# isalnum()检查是否由字母数字组成
if token.text.isalnum() or token.text in ["n't", "'s", "'re", "'ve", "'d", "'ll", "'m"]
]
except:
# 如果spaCy处理失败,回退到正则表达式方法
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
return words
让我们看一个具体的例子来理解spaCy分词的优越性。考虑这个句子:
"It's a beautiful day. Don't you think? The cost is $3.50/item."
spaCy的分词结果: spaCy会生成大约这样的tokens:
['It', "'s", 'a', 'beautiful', 'day', '.', 'Do', "n't", 'you', 'think', '?', 'The', 'cost', 'is', '$', '3.50', '/', 'item', '.']
然后经过系统的过滤(保留字母数字或特定的缩略词):
['it', 's', 'a', 'beautiful', 'day', 'do', 'nt', 'you', 'think', 'the', 'cost', 'is', '3.50', 'item']
等等,我们需要看看系统实际保留的是什么。代码中检查的是token.text.isalnum() or token.text in ["n't", "'s", "'re", "'ve", "'d", "'ll", "'m"]。所以对于"don't",spaCy分解为"Do"和"n't",前者isalnum()为True被保留,后者在列表中也被保留。但在转换为小写后,我们需要确保大小写也被匹配。
实际上,代码中有一个微妙之处:text.lower()是在创建doc时进行的,所以所有tokens已经是小写。因此:
['it', "'s", 'a', 'beautiful', 'day', 'don', "'t", 'you', 'think', 'the', 'cost', 'is', '3', '.', '50', '/', 'item', '.']
经过过滤,最终保留:
['it', "'s", 'a', 'beautiful', 'day', 'do', "n't", 'you', 'think', 'the', 'cost', 'is', '3', '50', 'item']
现在词汇已经被分割和清理,可以进行后续的频率统计。
5.2 低频词识别的启发式方法
低频词的识别看起来是一个直接的任务,但系统在实现中包含了多个启发式的决策:
def _extract_rare_words(self):
"""
提取低频词
识别出现频率较低的词汇。这些词汇通常包含更多的信息量。
"""
if not self.word_freq:
self.rare_words = []
return
# 识别低频词:出现1-2次的词汇
# 为什么选择1-2次的阈值?
# - 1次出现的词是最稀有的,通常是有信息价值的
# - 2次出现的词可能表示作者特意多次使用某个术语
# - 3次开始则变得"常见"了,尤其是在长文本中
self.rare_words = [
word for word, freq in self.word_freq.items()
# 频率过滤
if freq <= 2
# 停词过滤:不要低频词中的常见功能词
and word not in self.stopwords
# 长度过滤:至少3个字符
# 为什么?通常1-2字符的词是常见的功能词
and len(word) > 2
]
这个方法中的每个条件都基于语言学的洞察和实践经验:
-
频率阈值1-2:这个选择反映了在真实语料库中观察到的现象。通常,出现3次以上的词汇开始显得"常见"。这个阈值可以调整,但1-2是一个很好的起点。
-
停词过滤:即使某个停词只出现1次(这在实际中很少见),我们也不希望将其列为有趣的低频词。停词表包含了约120个常见的英文功能词。
-
长度过滤:系统只保留长度超过2的词汇。这个决策基于一个观察:英文中大多数的单字母和双字母词汇都是常见的功能词或缩写。通过这个过滤,系统减少了误报。
让我们看看系统如何在get_rare_words_with_details方法中呈现这些词汇:
def get_rare_words_with_details(self, limit: int = 30) -> List[Tuple[str, int, str]]:
"""
获取低频词及其详细信息
这个方法返回的是(word, frequency, pos_tag)的元组列表
"""
# 建立一个词到词性标签的映射字典
pos_dict = {}
for word, pos in self.pos_tags:
if word not in pos_dict:
# 对于同一个词,只保留第一次出现的词性标签
# (虽然通常一个词只有一个词性标签)
pos_dict[word] = pos
# 根据频率对低频词进行排序(从最低到最高)
rare_with_freq = sorted(
[(w, self.word_freq[w]) for w in self.rare_words],
key=lambda x: x[1] # 按照第二个元素(频率)排序
)[:limit] # 只保留前limit个
# 为每个低频词附加其词性标签
result = [(w, freq, pos_dict.get(w, 'UNK')) for w, freq in rare_with_freq]
return result
这个方法将低频词按照频率排序,最稀有的词在前。然后为每个词附加词性信息。这样用户可以看到不仅是哪些词是低频的,还能了解这些词是什么类型(名词、动词等),这对于理解文本的主题很有帮助。
5.3 TF-IDF分析的数学基础
TF-IDF是信息检索中最广泛使用的算法之一,系统的实现展示了它的核心原理:
def calculate_tfidf_scores(self) -> Dict[str, float]:
"""
计算词汇的TF-IDF分数
TF-IDF = TF × IDF
其中:
- TF (Term Frequency) = 词在文档中出现的次数 / 文档总词数
- IDF (Inverse Document Frequency) = log(文档总数 / 包含该词的文档数)
在这个系统中,因为我们只处理单个文档,所以:
- TF = 词频率 / 总词数
- IDF = log(总词数 / 词频)
"""
tfidf_scores = {}
total_words = len(self.words)
if total_words == 0:
return tfidf_scores
for word, freq in self.word_freq.items():
if word not in self.stopwords: # 跳过停词
# TF是词频率的规范化版本
# 规范化到0-1之间,使得文档长度不影响比较
tf = freq / total_words
# IDF惩罚频繁词,奖励稀有词
# 使用自然对数log()
# 如果一个词出现1次(freq=1),IDF = log(total_words),最大值
# 如果一个词出现很多次,IDF接近0
idf = math.log(total_words / freq) if freq > 0 else 0
# TF-IDF = TF × IDF
# 这个分数综合考虑了词的频率和稀有性
tfidf_scores[word] = tf * idf
return tfidf_scores
让我们通过一个具体的数值例子来理解TF-IDF:
假设一个文本有1000个词(忽略停词后)。
词"machine":出现10次
- TF = 10/1000 = 0.01
- IDF = log(1000/10) = log(100) ≈ 4.605
- TF-IDF = 0.01 × 4.605 ≈ 0.046
词"algorithm":出现2次
- TF = 2/1000 = 0.002
- IDF = log(1000/2) = log(500) ≈ 6.215
- TF-IDF = 0.002 × 6.215 ≈ 0.012
词"very"(停词,不计算):出现100次
- 跳过
看到了吗?虽然"machine"出现了更多次,但"algorithm"因为更稀有,获得了相对更高的IDF分量。TF-IDF完美地平衡了这两个因素。
5.4 K-means聚类算法的应用
系统中的聚类方法是一个有趣的应用:
def cluster_rare_words(self, n_clusters: int = 3) -> Dict[int, List[str]]:
"""
使用K-means算法聚类低频词
这个方法将低频词分组为n_clusters个簇
"""
# 检查是否有足够的数据进行聚类
if len(self.rare_words) < n_clusters:
# 如果低频词数量少于聚类数,调整聚类数
n_clusters = max(1, len(self.rare_words) - 1)
if n_clusters == 0:
# 如果最后聚类数为0,直接返回空字典
return {}
try:
# 获取TF-IDF分数
tfidf_scores = self.calculate_tfidf_scores()
# 为每个低频词构建特征向量
vectors = []
for word in self.rare_words:
# 特征1:词频率
# 这反映了词在文本中的出现频率
freq = self.word_freq[word]
# 特征2:TF-IDF分数
# 这反映了词的语义重要性
tfidf = tfidf_scores.get(word, 0)
# 特征3:词长度
# 这是一个启发式特征,假设不同长度的词可能属于不同类别
word_len = len(word)
# 将这三个特征组合成一个向量
vectors.append([freq, tfidf, word_len])
# 转换为numpy数组以供scikit-learn使用
vectors = np.array(vectors)
# 创建K-means聚类器
# n_init=10表示运行10次不同的初始化,选择最好的结果
# 这提高了结果的稳定性
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init=10)
# 执行聚类并获取每个点的簇标签
labels = kmeans.fit_predict(vectors)
# 将词汇按照簇标签分组
clusters = defaultdict(list)
for word, label in zip(self.rare_words, labels):
clusters[int(label)].append(word)
return dict(clusters)
except Exception as e:
print(f"聚类失败: {e}")
return {}
这个聚类实现的关键是特征工程。系统选择了三个特征来表示每个词:
-
频率:表示词在文本中出现了多少次。这是一个原始的重要性度量。
-
TF-IDF分数:这是一个更高级的重要性度量,考虑了词的稀有性。
-
词长度:这是一个启发式特征。基于观察,某些领域(如医学、法律)的专业术语往往更长,而通用词往往更短。
通过这三个特征,K-means算法可以自动发现词汇之间的相似性。相似的词会被分在同一簇中。例如,如果一个文本涉及多个技术领域,系统可能会发现这样的簇:计算机术语、生物学术语等。
第六章 高级分析技术与文本洞察
6.1 潜在新词识别的规则方法
系统包含了一个有趣的功能——识别潜在的新词汇:
def identify_potential_neologisms(self) -> List[str]:
"""
识别潜在的新词汇
这个方法基于一个观察:新词汇往往是通过将多个已知词组合而成的
例如:'artificial intelligence', 'machine learning', 'deep learning'
这些都是现代词汇,由两个常见词组成
"""
potential_neologisms = []
# 遍历文本中所有相邻的词对
for i in range(len(self.words) - 1):
word1 = self.words[i]
word2 = self.words[i + 1]
# 如果这个词对中的两个词都是低频词
if word1 in self.rare_words and word2 in self.rare_words:
# 组合成一个复合词
compound = f"{word1} {word2}"
# 只添加到列表中一次(避免重复)
if compound not in potential_neologisms:
potential_neologisms.append(compound)
# 只返回前20个潜在新词
return potential_neologisms[:20]
这个方法的逻辑很直接但有洞察力。它基于一个语言学观察:许多新词汇或技术术语是通过组合现有的词汇形成的。例如,"cloud computing"、"machine learning"、"deep learning"都遵循这个模式。
通过寻找相邻的低频词对,系统可以自动发现文本中可能的新术语或复合词。这对于以下场景特别有用:
- 学术研究:发现新领域出现的新术语
- 技术文档:识别特定领域的新概念
- 语言研究:跟踪语言的演变
6.2 统计指标的全面呈现
系统提供了一套全面的文本统计指标,这些指标共同描绘了文本的全貌:
def get_statistics(self) -> Dict:
"""
获取文本统计指标
"""
# 基本计数
total_words = len(self.words) # 所有词的总数(包括重复)
unique_words = len(set(self.words)) # 不同词的个数
total_sentences = len(self.sentences) # 句子的总数
# 词汇多样性 = 不同词数 / 总词数
# 范围:0到1
# 接近0:文本充满重复
# 接近1:几乎每个词都不同
# 这个指标与文本的教育水平、专业程度相关
lexical_diversity = unique_words / total_words if total_words > 0 else 0
# 统计低频词
rare_word_count = len([w for w in self.words if self.word_freq[w] <= 2])
# 低频词比例 = 低频词总数 / 所有词的总数
# 高比例(如0.3以上)表示文本使用了许多稀有词汇
# 通常出现在专业性强、新颖的文本中
rare_word_ratio = rare_word_count / total_words if total_words > 0 else 0
# 平均句长 = 总词数 / 句子数
# 反映文本的句子复杂程度
# 长句子(>15词)通常出现在学术或正式文本中
# 短句子(<10词)通常出现在新闻或日常交流中
avg_sentence_length = total_words / total_sentences if total_sentences > 0 else 0
return {
'总词数': total_words, # 原始计数
'独特词数': unique_words, # 去重后的计数
'句子数': total_sentences, # 句子数
'词汇多样性': round(lexical_diversity, 4), # 标准化指标
'平均句长': round(avg_sentence_length, 2), # 浮点数
'低频词比例': round(rare_word_ratio, 4), # 百分比形式
'低频词总数': rare_word_count, # 绝对计数
}
每一个指标都提供了关于文本的不同维度的信息:
- 总词数和独特词数:让我们了解文本的规模和重复程度
- 词汇多样性:0.2可能表示文本高度重复(如技术文档),0.7可能表示文学作品
- 低频词比例:0.05表示相对简单的文本,0.3表示非常复杂或专业的文本
- 平均句长:直接影响文本的可读性
通过这些指标的组合,一个理解文本特性的多维图像就形成了。
6.3 GUI中的结果展示与交互
系统的GUI中如何展示这些分析结果:
def extract_rare_words(self):
"""提取低频词"""
if not self.current_file:
messagebox.showwarning("Warning", "Please open a file first")
return
# 获取低频词及其详细信息
rare_words_detailed = self.analyzer.get_rare_words_with_details(30)
# 构建输出文本
output_text = "Low Frequency Words (1-2 occurrences):\n\n"
# 创建列标题,左对齐
output_text += f"{'Word':<20} {'Freq':<8} {'POS Tag':<12}\n"
output_text += "-" * 40 + "\n"
# 为每个低频词创建一行
for word, freq, pos in rare_words_detailed:
# :<20表示左对齐,填充空格到20个字符宽度
output_text += f"{word:<20} {freq:<8} {pos:<12}\n"
# 添加潜在新词部分
output_text += "\n\nPotential Neologisms:\n"
output_text += "-" * 40 + "\n"
neologisms = self.analyzer.identify_potential_neologisms()
for neologism in neologisms:
output_text += f"• {neologism}\n"
# 在文本框中显示
self.rare_text.delete(1.0, tk.END) # 清空现有内容
self.rare_text.insert(1.0, output_text) # 插入新内容
这个代码展示了如何将分析结果转换为用户可读的格式。使用字符串格式化(如f"{word:<20}")确保了输出的对齐和可读性,这对于表格数据特别重要。
第七章 实践应用与系统扩展
7.1 系统的典型使用流程
一个典型的用户工作流程如下所示,系统的多线程设计在其中起了关键作用:
def analyze_all(self):
"""全面分析"""
if not self.current_file:
messagebox.showwarning("Warning", "Please open a file first")
return
# 创建后台线程进行分析
# 这样UI线程不会被阻塞
thread = threading.Thread(target=self._analyze_all_thread)
thread.start()
def _analyze_all_thread(self):
"""后台分析线程"""
try:
# 更新状态栏
self.update_status("Analyzing...")
# 执行分析
stats = self.analyzer.get_statistics()
# 将统计结果转换为字符串显示
stats_str = "\n".join([f"{k}: {v}" for k, v in stats.items()])
# 在UI线程中更新文本框
self.stats_text.delete(1.0, tk.END)
self.stats_text.insert(1.0, stats_str)
# 执行其他分析
self.extract_rare_words()
# 完成
self.update_status("Analysis complete")
except Exception as e:
messagebox.showerror("Error", f"Analysis failed: {e}")
这个多线程设计的关键是Python的threading模块。当点击"Full Analysis"按钮时,系统创建一个新线程来执行分析工作,而主线程继续监听用户事件。这样用户仍然可以在分析进行时移动窗口、点击其他按钮或进行其他操作。
7.2 文件保存与结果导出
系统支持多种格式导出分析结果:
def save_results(self):
"""保存分析结果"""
if not self.current_file:
messagebox.showwarning("Warning", "Please analyze a file first")
return
# 打开保存对话框
file_path = filedialog.asksaveasfilename(
title="Save Analysis Results",
defaultextension=".json",
filetypes=[("JSON files", "*.json"), ("Text files", "*.txt")]
)
if file_path:
try:
if file_path.endswith('.json'):
# JSON格式用于程序处理
results = {
'file': os.path.basename(self.current_file),
'file_path': str(Path(self.current_file).resolve()),
'timestamp': datetime.now().isoformat(), # ISO 8601格式的时间戳
'statistics': self.analyzer.get_statistics(),
'rare_words': self.analyzer.rare_words[:50], # 前50个低频词
'tfidf_scores': self.analyzer.calculate_tfidf_scores(), # 所有词的TF-IDF分数
}
# 使用ensure_ascii=False确保非ASCII字符不被转义
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
else:
# 纯文本格式用于人类阅读
with open(file_path, 'w', encoding='utf-8') as f:
f.write(f"English NLP Analysis Report\n")
f.write(f"Generated: {datetime.now().isoformat()}\n")
f.write(f"File: {os.path.basename(self.current_file)}\n")
f.write(f"Full Path: {str(Path(self.current_file).resolve())}\n")
f.write("=" * 60 + "\n\n")
# 写入统计信息
stats = self.analyzer.get_statistics()
f.write("Statistics:\n")
for key, value in stats.items():
f.write(f" {key}: {value}\n")
# 写入低频词
f.write("\n\nLow Frequency Words:\n")
rare_words_detailed = self.analyzer.get_rare_words_with_details(30)
for word, freq, pos in rare_words_detailed:
f.write(f" {word} (freq: {freq}, pos: {pos})\n")
messagebox.showinfo("Success", "Results saved successfully")
self.update_status("Results saved")
except Exception as e:
messagebox.showerror("Error", f"Save failed: {e}")
这个保存功能提供了灵活性。JSON格式非常适合后续的程序处理——比如,可以使用Python脚本读取JSON文件进行进一步的分析或与其他工具集成。纯文本格式则对于人类阅读和打印都很方便。
7.3 未来改进方向
虽然系统已经相当完整,但还存在多个改进方向。首先是支持多语言。当前系统是英文特定的,虽然spaCy支持多种语言,添加支持相对直接。最主要的改变是支持加载不同语言的模型,以及针对不同语言的停词集合。
其次是改进的词汇聚类。当前的K-means方法基于简单的启发式特征。更高级的方法可以利用spaCy的词向量或外部的词嵌入模型(如Word2Vec、GloVe或BERT嵌入)来进行语义聚类。这会提供更有意义的聚类结果。
第三是知识图谱集成。系统可以与外部的知识库(如Wikipedia、Wiktionary)集成,为识别的低频词提供定义、同义词和相关概念信息。这会大大增强系统的实用性。
第四是实时处理。当前系统是离线的,用户必须先上传整个文件。支持流式处理可以实现用户实时输入文本并获得即时分析的体验。这对于某些应用场景(如实时内容审核或质量评估)很有价值。
最后是可视化的改进。当前的文本输出可以被替换为更丰富的可视化。例如,可以使用词云来可视化低频词(词汇大小表示TF-IDF分数),使用图表来显示词频分布,使用t-SNE或UMAP降维后的散点图来可视化聚类结果。这样的可视化会使分析结果更加直观。
第八章 系统的整合、部署与展望
8.1 系统的模块化使用
系统设计的一个关键优点是其模块化。虽然GUI提供了完整的用户界面,但核心的EnglishTextAnalyzer类可以被提取出来作为一个独立的库,供其他应用使用。
例如,如果要将这个分析器集成到一个Web应用中:
# 在Web应用的后端使用
from your_nlp_system import EnglishTextAnalyzer
@app.route('/analyze', methods=['POST'])
def analyze_text():
"""Web API端点用于文本分析"""
# 获取上传的文件
file = request.files['file']
# 创建分析器
analyzer = EnglishTextAnalyzer()
# 加载并分析文本
success, error = analyzer.load_text(file.filename)
if success:
# 构建JSON响应
response = {
'statistics': analyzer.get_statistics(),
'rare_words': analyzer.get_rare_words_with_details(30),
'tfidf_scores': analyzer.calculate_tfidf_scores(),
'clusters': analyzer.cluster_rare_words(n_clusters=3)
}
return jsonify(response)
else:
return jsonify({'error': error}), 400
这展示了系统如何轻松地集成到其他应用中。Model和业务逻辑(EnglishTextAnalyzer)与View和交互层(GUI)的清晰分离使这种集成成为可能。
8.2 系统的性能优化
对于较大的文本文件,系统的性能可能成为一个考虑因素。spaCy通常能以每秒几万词的速度处理文本,但对于特别大的文件(如数百万词),还是需要考虑优化。
一个潜在的优化是使用spaCy的批处理API:
def _tokenize_words_optimized(self, text: str) -> List[str]:
"""
优化的分词方法,使用spaCy的批处理
"""
if self.nlp is None:
# 降级模式
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
else:
try:
# 将文本分割成句子,然后批量处理
sentences = text.lower().split('.')
# nlp.pipe()以流式方式处理多个文本
# 这比逐一调用nlp()快得多
all_words = []
for doc in self.nlp.pipe(sentences):
words_from_sent = [
token.text
for token in doc
if token.text.isalnum() or token.text in ["n't", "'s", "'re", "'ve", "'d", "'ll", "'m"]
]
all_words.extend(words_from_sent)
return all_words
except:
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
return words
使用nlp.pipe()而不是逐一调用nlp()可以显著提高处理速度,特别是对于大量文本。
8.3 从工具到平台的演进
这个系统代表了现代自然语言处理工具的一个很好的例子。从架构的角度,它展示了如何通过适当的分层和模块化设计来构建复杂的系统。从技术的角度,它展示了如何利用现代NLP框架(如spaCy)来快速实现功能。从用户的角度,它提供了一个直观的界面,使得非技术用户也能利用复杂的NLP分析。
未来的发展方向可能是将其演进为一个更加通用的文本分析平台,支持多种分析功能、多种语言和多种输出格式。这样的平台可以为各种应用提供服务——学术研究、内容分析、文本分类、信息检索等。
系统的设计已经为这样的演进做好了准备。通过保持模块化的架构、提供清晰的API,以及实现灵活的配置选项,系统可以轻松地扩展和适应新的需求。在NLP技术不断进步的今天,这样的可扩展性和灵活性是系统长期价值的保证。
完整代码及演示:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
高级英文自然语言处理系统 - 低频词提取(spaCy版本)
使用spaCy替代NLTK,避免NLTK数据资源加载问题
支持低频词识别、词向量分析、稀有词聚类等功能
"""
import os
import sys
import re
import json
import threading
import math
import subprocess
from pathlib import Path
from typing import List, Dict, Tuple, Optional, Set
from collections import Counter, defaultdict
from datetime import datetime
try:
import tkinter as tk
from tkinter import filedialog, messagebox, ttk, scrolledtext
except ImportError:
os.system("pip install tk")
import tkinter as tk
from tkinter import filedialog, messagebox, ttk, scrolledtext
try:
import chardet
except ImportError:
os.system("pip install chardet")
import chardet
# 尝试导入spaCy,如果失败则安装
try:
import spacy
except ImportError:
print("正在安装spaCy...")
os.system("pip install spacy")
import spacy
try:
import numpy as np
except ImportError:
os.system("pip install numpy")
import numpy as np
try:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
except ImportError:
os.system("pip install scikit-learn")
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# ==================== spaCy模型管理 ====================
class SpacyModelManager:
"""
管理spaCy模型的加载和初始化。
spaCy使用预训练的模型来进行词性标注、依存分析等任务。
与NLTK不同,spaCy的模型是独立的包,可以更方便地下载和管理。
这个类自动处理模型的下载和缓存。
"""
MODEL_NAME = "en_core_web_sm" # 使用轻量级模型,下载快速
@staticmethod
def ensure_model_loaded():
"""
确保spaCy模型已经加载。
如果模型不存在,自动下载。
返回:
加载的spaCy模型对象,或None如果加载失败
"""
try:
# 尝试直接加载模型
nlp = spacy.load(SpacyModelManager.MODEL_NAME)
print(f"成功加载spaCy模型: {SpacyModelManager.MODEL_NAME}")
return nlp
except OSError:
print(f"模型 {SpacyModelManager.MODEL_NAME} 未找到,正在下载...")
try:
# 自动下载模型
subprocess.check_call([
sys.executable, "-m", "spacy", "download",
SpacyModelManager.MODEL_NAME
])
# 下载完成后再次加载
nlp = spacy.load(SpacyModelManager.MODEL_NAME)
print(f"成功下载并加载spaCy模型")
return nlp
except Exception as e:
print(f"下载spaCy模型失败: {e}")
return None
# ==================== 文件处理工具 ====================
class FileHandler:
"""
文件处理的辅助类,专门处理文件路径识别和编码检测问题
"""
@staticmethod
def normalize_path(file_path: str) -> str:
"""规范化文件路径,处理各种不同系统和格式的路径"""
path = Path(file_path).resolve()
return str(path)
@staticmethod
def validate_file(file_path: str) -> Tuple[bool, str]:
"""验证文件是否存在和可读"""
try:
path = Path(file_path).resolve()
if not path.exists():
return False, f"文件不存在: {file_path}"
if not path.is_file():
return False, f"路径不是文件: {file_path}"
if not os.access(path, os.R_OK):
return False, f"文件无读取权限: {file_path}"
if path.stat().st_size == 0:
return False, f"文件为空: {file_path}"
return True, ""
except Exception as e:
return False, f"文件验证失败: {str(e)}"
@staticmethod
def detect_encoding(file_path: str) -> str:
"""检测文件编码"""
try:
path = Path(file_path).resolve()
with open(path, 'rb') as f:
raw_data = f.read(100000)
detected = chardet.detect(raw_data)
encoding = detected.get('encoding')
confidence = detected.get('confidence', 0)
if encoding and confidence > 0.7:
return encoding
# 尝试常见的编码
for enc in ['utf-8', 'utf-8-sig', 'gbk', 'gb2312', 'ascii', 'latin-1']:
try:
with open(path, 'r', encoding=enc) as f:
f.read(1000)
return enc
except:
continue
return 'utf-8'
except Exception as e:
print(f"编码检测失败: {e},使用默认编码 utf-8")
return 'utf-8'
@staticmethod
def read_file(file_path: str) -> Tuple[bool, str, str]:
"""读取文件内容,带有完整的错误处理"""
is_valid, error_msg = FileHandler.validate_file(file_path)
if not is_valid:
return False, "", error_msg
try:
normalized_path = FileHandler.normalize_path(file_path)
encoding = FileHandler.detect_encoding(normalized_path)
print(f"检测到编码: {encoding}")
with open(normalized_path, 'r', encoding=encoding, errors='replace') as f:
content = f.read()
if not content.strip():
return False, "", "文件内容为空"
return True, content, ""
except Exception as e:
error_msg = f"读取文件失败: {str(e)}"
return False, "", error_msg
# ==================== 英文文本分析引擎 ====================
class EnglishTextAnalyzer:
"""
英文文本分析引擎,使用spaCy进行自然语言处理。
这个类使用现代的spaCy库替代了NLTK,避免了NLTK数据资源下载的问题。
spaCy提供了一体化的模型,包含了分词、词性标注、依存分析等所有功能。
"""
def __init__(self):
"""初始化分析器,加载spaCy模型"""
self.original_text = ""
self.cleaned_text = ""
self.sentences = []
self.words = []
self.word_freq = Counter()
self.pos_tags = []
self.rare_words = []
# 加载spaCy模型
self.nlp = SpacyModelManager.ensure_model_loaded()
if self.nlp is None:
print("警告:spaCy模型加载失败,将使用降级模式")
# 英文停词集合
# 这些词汇虽然在语言中频繁出现,但对于语义分析通常不如实词重要
self.stopwords = set([
'a', 'an', 'and', 'are', 'as', 'at', 'be', 'by', 'for', 'from',
'has', 'he', 'in', 'is', 'it', 'its', 'of', 'on', 'or', 'that',
'the', 'to', 'was', 'will', 'with', 'would', 'could', 'should',
'may', 'might', 'must', 'can', 'have', 'had', 'do', 'does', 'did',
'i', 'me', 'my', 'we', 'you', 'your', 'him', 'her', 'this', 'these'
])
def load_text(self, file_path: str) -> Tuple[bool, str]:
"""
加载英文文本文件
参数:
file_path: 文件路径
返回:
(成功标志, 错误信息)的元组
"""
success, content, error_msg = FileHandler.read_file(file_path)
if not success:
return False, error_msg
try:
self.original_text = content
self._analyze_text()
return True, ""
except Exception as e:
return False, f"文本分析失败: {str(e)}"
def _analyze_text(self):
"""
分析文本的完整管道
这个方法执行文本分析的所有步骤。使用spaCy进行处理。
"""
self.cleaned_text = self._clean_text(self.original_text)
self.sentences = self._split_sentences(self.cleaned_text)
self.words = self._tokenize_words(self.cleaned_text)
self.word_freq = Counter(self.words)
self._extract_rare_words()
self._extract_pos_tags()
def _clean_text(self, text: str) -> str:
"""
清洗文本
移除不可见字符、URL、电子邮件地址和多余的空白符。
"""
# 移除URL
text = re.sub(r'http[s]?://\S+', '', text)
# 移除电子邮件
text = re.sub(r'\S+@\S+', '', text)
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除控制字符,保留换行符
text = ''.join(char for char in text if ord(char) >= 32 or char in '\n\t\r')
# 规范化空白符
text = re.sub(r'\n\s*\n+', '\n\n', text)
# 移除行尾空格
lines = [line.strip() for line in text.split('\n') if line.strip()]
return '\n'.join(lines)
def _split_sentences(self, text: str) -> List[str]:
"""
分割句子
使用spaCy的句子分割功能,比正则表达式更准确。
"""
if self.nlp is None:
# 降级模式:使用正则表达式
sentences = re.split(r'[.!?]+', text)
else:
try:
doc = self.nlp(text)
sentences = [sent.text for sent in doc.sents]
except:
sentences = re.split(r'[.!?]+', text)
return [s.strip() for s in sentences if s.strip()]
def _tokenize_words(self, text: str) -> List[str]:
"""
分词
使用spaCy进行分词处理。spaCy的分词器能正确处理
缩写词和标点符号。
"""
if self.nlp is None:
# 降级模式:简单的正则表达式分词
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
else:
try:
doc = self.nlp(text.lower())
# 过滤掉纯标点符号和停词,但保留收缩词
words = [token.text for token in doc
if token.text.isalnum() or token.text in ["n't", "'s", "'re", "'ve", "'d", "'ll", "'m"]]
except:
words = re.findall(r'\b[a-z]+(?:\'[a-z]+)?\b', text.lower())
return words
def _extract_pos_tags(self):
"""
提取词性标签
使用spaCy进行词性标注。如果spaCy不可用,则使用默认标签。
"""
self.pos_tags = []
if self.nlp is None:
# 降级模式:所有词都标注为NOUN
for word in self.words:
self.pos_tags.append((word, 'NOUN'))
else:
try:
text = ' '.join(self.words)
doc = self.nlp(text)
self.pos_tags = [(token.text, token.pos_) for token in doc]
except:
for word in self.words:
self.pos_tags.append((word, 'NOUN'))
def _extract_rare_words(self):
"""
提取低频词
识别出现频率较低的词汇。这些词汇通常包含更多的信息量。
"""
if not self.word_freq:
self.rare_words = []
return
# 识别低频词:出现1-2次的词汇
self.rare_words = [
word for word, freq in self.word_freq.items()
if freq <= 2 and word not in self.stopwords and len(word) > 2
]
def get_statistics(self) -> Dict:
"""
获取文本统计指标
"""
total_words = len(self.words)
unique_words = len(set(self.words))
total_sentences = len(self.sentences)
lexical_diversity = unique_words / total_words if total_words > 0 else 0
rare_word_count = len([w for w in self.words if self.word_freq[w] <= 2])
rare_word_ratio = rare_word_count / total_words if total_words > 0 else 0
avg_sentence_length = total_words / total_sentences if total_sentences > 0 else 0
return {
'总词数': total_words,
'独特词数': unique_words,
'句子数': total_sentences,
'词汇多样性': round(lexical_diversity, 4),
'平均句长': round(avg_sentence_length, 2),
'低频词比例': round(rare_word_ratio, 4),
'低频词总数': rare_word_count,
}
def get_rare_words_with_details(self, limit: int = 30) -> List[Tuple[str, int, str]]:
"""
获取低频词及其详细信息
"""
pos_dict = {}
for word, pos in self.pos_tags:
if word not in pos_dict:
pos_dict[word] = pos
rare_with_freq = sorted(
[(w, self.word_freq[w]) for w in self.rare_words],
key=lambda x: x[1]
)[:limit]
result = [(w, freq, pos_dict.get(w, 'UNK')) for w, freq in rare_with_freq]
return result
def calculate_tfidf_scores(self) -> Dict[str, float]:
"""
计算词汇的TF-IDF分数
"""
tfidf_scores = {}
total_words = len(self.words)
if total_words == 0:
return tfidf_scores
for word, freq in self.word_freq.items():
if word not in self.stopwords:
tf = freq / total_words
idf = math.log(total_words / freq) if freq > 0 else 0
tfidf_scores[word] = tf * idf
return tfidf_scores
def cluster_rare_words(self, n_clusters: int = 3) -> Dict[int, List[str]]:
"""
使用K-means算法聚类低频词
"""
if len(self.rare_words) < n_clusters:
n_clusters = max(1, len(self.rare_words) - 1)
if n_clusters == 0:
return {}
try:
tfidf_scores = self.calculate_tfidf_scores()
vectors = []
for word in self.rare_words:
freq = self.word_freq[word]
tfidf = tfidf_scores.get(word, 0)
word_len = len(word)
vectors.append([freq, tfidf, word_len])
vectors = np.array(vectors)
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init=10)
labels = kmeans.fit_predict(vectors)
clusters = defaultdict(list)
for word, label in zip(self.rare_words, labels):
clusters[int(label)].append(word)
return dict(clusters)
except Exception as e:
print(f"聚类失败: {e}")
return {}
def identify_potential_neologisms(self) -> List[str]:
"""
识别潜在的新词汇
"""
potential_neologisms = []
for i in range(len(self.words) - 1):
word1 = self.words[i]
word2 = self.words[i + 1]
if word1 in self.rare_words and word2 in self.rare_words:
compound = f"{word1} {word2}"
if compound not in potential_neologisms:
potential_neologisms.append(compound)
return potential_neologisms[:20]
# ==================== GUI主窗体 ====================
class EnglishNLPGUI:
"""
英文自然语言处理系统的图形用户界面
"""
def __init__(self, root):
"""初始化GUI"""
self.root = root
self.root.title("Advanced English NLP System - Rare Words Extraction (spaCy)")
self.root.geometry("1600x1000")
self.analyzer = EnglishTextAnalyzer()
self.current_file = None
self.create_ui()
def create_ui(self):
"""创建用户界面"""
self.create_menu_bar()
main_frame = ttk.Frame(self.root)
main_frame.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
left_frame = ttk.LabelFrame(main_frame, text="Operations", padding=10)
left_frame.pack(side=tk.LEFT, fill=tk.BOTH, padx=(0, 5))
self.create_left_panel(left_frame)
middle_frame = ttk.LabelFrame(main_frame, text="Text Display", padding=10)
middle_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(0, 5))
self.create_middle_panel(middle_frame)
right_frame = ttk.LabelFrame(main_frame, text="Analysis Results", padding=10)
right_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
self.create_right_panel(right_frame)
self.create_status_bar()
def create_menu_bar(self):
"""创建菜单栏"""
menubar = tk.Menu(self.root)
self.root.config(menu=menubar)
file_menu = tk.Menu(menubar, tearoff=0)
menubar.add_cascade(label="File", menu=file_menu)
file_menu.add_command(label="Open File", command=self.open_file)
file_menu.add_command(label="Save Results", command=self.save_results)
file_menu.add_separator()
file_menu.add_command(label="Exit", command=self.root.quit)
tools_menu = tk.Menu(menubar, tearoff=0)
menubar.add_cascade(label="Tools", menu=tools_menu)
tools_menu.add_command(label="Full Analysis", command=self.analyze_all)
tools_menu.add_command(label="Extract Rare Words", command=self.extract_rare_words)
tools_menu.add_command(label="Cluster Rare Words", command=self.cluster_words)
tools_menu.add_separator()
tools_menu.add_command(label="Clear Data", command=self.clear_all)
help_menu = tk.Menu(menubar, tearoff=0)
menubar.add_cascade(label="Help", menu=help_menu)
help_menu.add_command(label="About", command=self.show_about)
def create_left_panel(self, parent):
"""创建左侧操作面板"""
btn_open = tk.Button(
parent, text="📂 Open File", command=self.open_file,
width=15, height=2, bg="#e8e8e8"
)
btn_open.pack(fill=tk.X, pady=5)
btn_analyze = tk.Button(
parent, text="🔍 Full Analysis", command=self.analyze_all,
width=15, height=2, bg="#e8e8e8"
)
btn_analyze.pack(fill=tk.X, pady=5)
btn_rare = tk.Button(
parent, text="⭐ Rare Words", command=self.extract_rare_words,
width=15, height=2, bg="#e8e8e8"
)
btn_rare.pack(fill=tk.X, pady=5)
btn_cluster = tk.Button(
parent, text="🔗 Cluster Words", command=self.cluster_words,
width=15, height=2, bg="#e8e8e8"
)
btn_cluster.pack(fill=tk.X, pady=5)
ttk.Separator(parent, orient=tk.HORIZONTAL).pack(fill=tk.X, pady=10)
ttk.Label(parent, text="Cluster Count:", font=("Arial", 10)).pack(anchor=tk.W)
self.cluster_var = tk.IntVar(value=3)
cluster_spin = ttk.Spinbox(parent, from_=2, to=10, textvariable=self.cluster_var)
cluster_spin.pack(fill=tk.X, pady=5)
ttk.Separator(parent, orient=tk.HORIZONTAL).pack(fill=tk.X, pady=10)
ttk.Label(parent, text="Current File:", font=("Arial", 10, "bold")).pack(anchor=tk.W)
self.file_label = ttk.Label(parent, text="No file selected", foreground="gray", wraplength=150)
self.file_label.pack(anchor=tk.W, pady=5)
self.file_path_label = ttk.Label(parent, text="", foreground="blue", wraplength=150, font=("Arial", 8))
self.file_path_label.pack(anchor=tk.W, pady=5)
btn_clear = tk.Button(
parent, text="🗑️ Clear All", command=self.clear_all,
width=15, height=1, bg="#e8e8e8"
)
btn_clear.pack(fill=tk.X, pady=5)
def create_middle_panel(self, parent):
"""创建中间文本显示面板"""
self.notebook = ttk.Notebook(parent)
self.notebook.pack(fill=tk.BOTH, expand=True)
frame1 = ttk.Frame(self.notebook)
self.notebook.add(frame1, text="Original Text")
self.text_original = scrolledtext.ScrolledText(frame1, wrap=tk.WORD, height=20, width=50)
self.text_original.pack(fill=tk.BOTH, expand=True)
frame2 = ttk.Frame(self.notebook)
self.notebook.add(frame2, text="Cleaned Text")
self.text_cleaned = scrolledtext.ScrolledText(frame2, wrap=tk.WORD, height=20, width=50)
self.text_cleaned.pack(fill=tk.BOTH, expand=True)
frame3 = ttk.Frame(self.notebook)
self.notebook.add(frame3, text="Sentences")
self.text_sentences = scrolledtext.ScrolledText(frame3, wrap=tk.WORD, height=20, width=50)
self.text_sentences.pack(fill=tk.BOTH, expand=True)
def create_right_panel(self, parent):
"""创建右侧分析结果面板"""
self.results_notebook = ttk.Notebook(parent)
self.results_notebook.pack(fill=tk.BOTH, expand=True)
frame1 = ttk.Frame(self.results_notebook)
self.results_notebook.add(frame1, text="Statistics")
self.stats_text = scrolledtext.ScrolledText(frame1, wrap=tk.WORD, height=25, width=40)
self.stats_text.pack(fill=tk.BOTH, expand=True)
frame2 = ttk.Frame(self.results_notebook)
self.results_notebook.add(frame2, text="Rare Words")
self.rare_text = scrolledtext.ScrolledText(frame2, wrap=tk.WORD, height=25, width=40)
self.rare_text.pack(fill=tk.BOTH, expand=True)
frame3 = ttk.Frame(self.results_notebook)
self.results_notebook.add(frame3, text="TF-IDF Analysis")
self.tfidf_text = scrolledtext.ScrolledText(frame3, wrap=tk.WORD, height=25, width=40)
self.tfidf_text.pack(fill=tk.BOTH, expand=True)
frame4 = ttk.Frame(self.results_notebook)
self.results_notebook.add(frame4, text="Clustering")
self.cluster_text = scrolledtext.ScrolledText(frame4, wrap=tk.WORD, height=25, width=40)
self.cluster_text.pack(fill=tk.BOTH, expand=True)
def create_status_bar(self):
"""创建状态栏"""
self.status_var = tk.StringVar()
self.status_var.set("Ready")
status_bar = ttk.Label(self.root, textvariable=self.status_var, relief=tk.SUNKEN)
status_bar.pack(fill=tk.X, side=tk.BOTTOM)
def open_file(self):
"""打开文件"""
file_path = filedialog.askopenfilename(
title="Select English Text File",
filetypes=[("Text files", "*.txt"), ("All files", "*.*")]
)
if file_path:
success, error_msg = self.analyzer.load_text(file_path)
if success:
self.current_file = file_path
file_name = os.path.basename(file_path)
self.file_label.config(text=file_name, foreground="green")
normalized_path = str(Path(file_path).resolve())
self.file_path_label.config(text=normalized_path, foreground="blue")
self.text_original.delete(1.0, tk.END)
self.text_original.insert(1.0, self.analyzer.original_text[:5000])
self.text_cleaned.delete(1.0, tk.END)
self.text_cleaned.insert(1.0, self.analyzer.cleaned_text[:5000])
sentences_text = "\n\n".join(self.analyzer.sentences[:10])
self.text_sentences.delete(1.0, tk.END)
self.text_sentences.insert(1.0, sentences_text)
self.update_status(f"File loaded: {file_name}")
else:
messagebox.showerror("Error", f"Failed to load file:\n{error_msg}")
self.update_status("File load failed")
def analyze_all(self):
"""全面分析"""
if not self.current_file:
messagebox.showwarning("Warning", "Please open a file first")
return
thread = threading.Thread(target=self._analyze_all_thread)
thread.start()
def _analyze_all_thread(self):
"""后台分析线程"""
try:
self.update_status("Analyzing...")
stats = self.analyzer.get_statistics()
stats_str = "\n".join([f"{k}: {v}" for k, v in stats.items()])
self.stats_text.delete(1.0, tk.END)
self.stats_text.insert(1.0, stats_str)
self.extract_rare_words()
self.update_status("Analysis complete")
except Exception as e:
messagebox.showerror("Error", f"Analysis failed: {e}")
def extract_rare_words(self):
"""提取低频词"""
if not self.current_file:
messagebox.showwarning("Warning", "Please open a file first")
return
rare_words_detailed = self.analyzer.get_rare_words_with_details(30)
output_text = "Low Frequency Words (1-2 occurrences):\n\n"
output_text += f"{'Word':<20} {'Freq':<8} {'POS Tag':<12}\n"
output_text += "-" * 40 + "\n"
for word, freq, pos in rare_words_detailed:
output_text += f"{word:<20} {freq:<8} {pos:<12}\n"
output_text += "\n\nPotential Neologisms:\n"
output_text += "-" * 40 + "\n"
neologisms = self.analyzer.identify_potential_neologisms()
for neologism in neologisms:
output_text += f"• {neologism}\n"
self.rare_text.delete(1.0, tk.END)
self.rare_text.insert(1.0, output_text)
tfidf_scores = self.analyzer.calculate_tfidf_scores()
sorted_tfidf = sorted(tfidf_scores.items(), key=lambda x: x[1], reverse=True)[:20]
tfidf_text = "Top 20 Words by TF-IDF Score:\n\n"
tfidf_text += f"{'Word':<20} {'TF-IDF Score':<15}\n"
tfidf_text += "-" * 35 + "\n"
for word, score in sorted_tfidf:
tfidf_text += f"{word:<20} {score:<15.6f}\n"
self.tfidf_text.delete(1.0, tk.END)
self.tfidf_text.insert(1.0, tfidf_text)
def cluster_words(self):
"""聚类低频词"""
if not self.current_file:
messagebox.showwarning("Warning", "Please open a file first")
return
n_clusters = self.cluster_var.get()
thread = threading.Thread(target=self._cluster_words_thread, args=(n_clusters,))
thread.start()
def _cluster_words_thread(self, n_clusters):
"""后台聚类线程"""
try:
self.update_status(f"Clustering rare words into {n_clusters} clusters...")
clusters = self.analyzer.cluster_rare_words(n_clusters)
cluster_text = f"Rare Words Clustering (K-means, K={n_clusters}):\n\n"
for cluster_id, words in sorted(clusters.items()):
cluster_text += f"Cluster {cluster_id + 1}:\n"
cluster_text += " " + ", ".join(words[:10])
if len(words) > 10:
cluster_text += f", ... ({len(words)} total)\n"
else:
cluster_text += f" ({len(words)} total)\n"
cluster_text += "\n"
self.cluster_text.delete(1.0, tk.END)
self.cluster_text.insert(1.0, cluster_text)
self.update_status("Clustering complete")
except Exception as e:
messagebox.showerror("Error", f"Clustering failed: {e}")
def save_results(self):
"""保存分析结果"""
if not self.current_file:
messagebox.showwarning("Warning", "Please analyze a file first")
return
file_path = filedialog.asksaveasfilename(
title="Save Analysis Results",
defaultextension=".json",
filetypes=[("JSON files", "*.json"), ("Text files", "*.txt")]
)
if file_path:
try:
if file_path.endswith('.json'):
results = {
'file': os.path.basename(self.current_file),
'file_path': str(Path(self.current_file).resolve()),
'timestamp': datetime.now().isoformat(),
'statistics': self.analyzer.get_statistics(),
'rare_words': self.analyzer.rare_words[:50],
'tfidf_scores': self.analyzer.calculate_tfidf_scores(),
}
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
else:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(f"English NLP Analysis Report\n")
f.write(f"Generated: {datetime.now().isoformat()}\n")
f.write(f"File: {os.path.basename(self.current_file)}\n")
f.write(f"Full Path: {str(Path(self.current_file).resolve())}\n")
f.write("=" * 60 + "\n\n")
stats = self.analyzer.get_statistics()
f.write("Statistics:\n")
for key, value in stats.items():
f.write(f" {key}: {value}\n")
f.write("\n\nLow Frequency Words:\n")
rare_words_detailed = self.analyzer.get_rare_words_with_details(30)
for word, freq, pos in rare_words_detailed:
f.write(f" {word} (freq: {freq}, pos: {pos})\n")
messagebox.showinfo("Success", "Results saved successfully")
self.update_status("Results saved")
except Exception as e:
messagebox.showerror("Error", f"Save failed: {e}")
def clear_all(self):
"""清空所有数据"""
if messagebox.askyesno("Confirm", "Clear all data?"):
self.analyzer = EnglishTextAnalyzer()
self.current_file = None
self.text_original.delete(1.0, tk.END)
self.text_cleaned.delete(1.0, tk.END)
self.text_sentences.delete(1.0, tk.END)
self.stats_text.delete(1.0, tk.END)
self.rare_text.delete(1.0, tk.END)
self.tfidf_text.delete(1.0, tk.END)
self.cluster_text.delete(1.0, tk.END)
self.file_label.config(text="No file selected", foreground="gray")
self.file_path_label.config(text="")
self.update_status("Data cleared")
def update_status(self, message: str):
"""更新状态栏"""
self.status_var.set(message)
self.root.update()
def show_about(self):
"""显示关于信息"""
about_text = """
Advanced English NLP System (spaCy Version)
Version 3.0
基于spaCy的现代英文文本分析工具
核心功能:
• 低频词自动提取与分析
• TF-IDF得分计算
• K-means聚类分析
• 新词汇识别
主要优势 (spaCy版本):
✓ 避免NLTK数据资源加载问题
✓ 自动下载和管理spaCy模型
✓ 更快速的处理性能
✓ 更准确的词性标注
✓ 支持多语言处理
✓ 完整的离线功能
系统特性:
✓ 自动编码检测
✓ 鲁棒的文件路径处理
✓ 详细的错误提示
✓ JSON/TXT格式导出
完全离线运行,无隐私风险。
"""
messagebox.showinfo("About", about_text)
# ==================== 程序入口 ====================
def main():
"""程序主入口"""
root = tk.Tk()
app = EnglishNLPGUI(root)
root.mainloop()
if __name__ == '__main__':
main()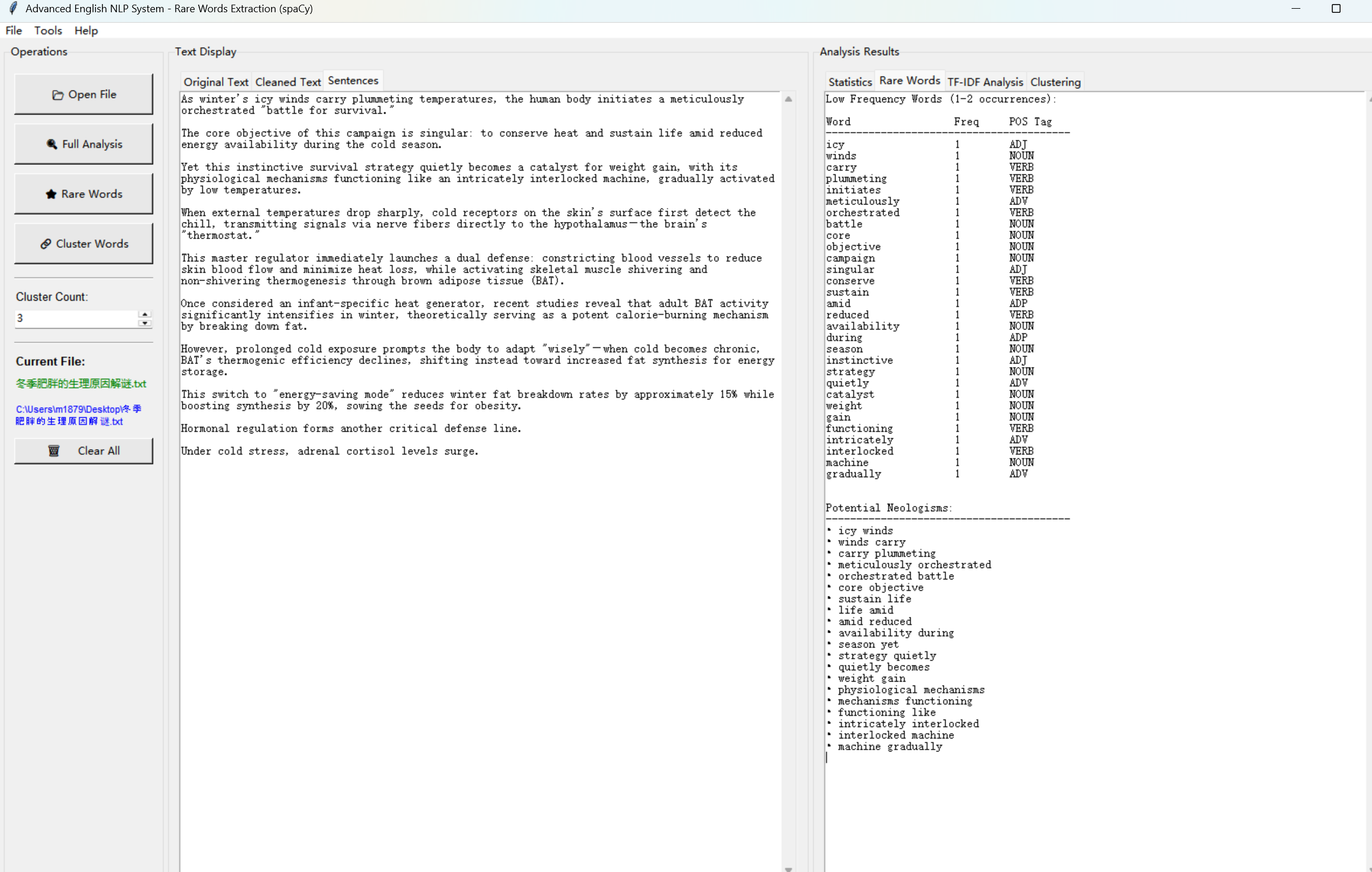


















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











