






1 引言:当我们认真算一次“强人工智能账单”
强人工智能到底要多少算力、多少数据、多少“算法魔法”才能跑得起来?这个问题过去更多是科幻迷和未来学家的谈资,如今却变成了一个非常现实的工程问题。OpenAI 在 2018 年那篇著名的“AI and Compute”分析中指出,自 2012 年到 2018 年,最大训练运行所用的计算量大约每 3.4 个月翻一番,远远快于摩尔定律两年翻番的节奏,这意味着短短六年间,头部模型的训练算力增长了 30 万倍以上。(OpenAI) 2020 年之后,大模型时代全面开启,GPT-3、GPT-4、Gemini、Llama 等一系列模型以近乎失控的速度推高了“单次训练”所需要的浮点运算次数和 GPU 数量,而最近的统计表明,规模达到或超过 GPT-4 级别(训练 FLOPs 达到 10²⁵ 量级)的模型已经不止一个,而是“至少 30 多个”。(Epoch AI)
与此同时,另一条看上去“温柔一点”的曲线也在悄悄爬升。OpenAI 的“AI and Efficiency”研究显示,如果我们盯着同一个性能指标(比如 ImageNet 上达到 AlexNet 水平),从 2012 年到 2019 年,实现同样效果所需的训练算力下降了约 44 倍,等价于“算法效率”每 16 个月翻一番,这个速度甚至比硬件性能提升还要快。(OpenAI) 换句话说,算力需求在失控式膨胀,算法在拼命“省电”,两条力量在正面撞车,强人工智能的计算需求就卡在这场拉扯的正中央。
更有意思的是,如果把视角从一个模型扩展到整个行业,会发现“算力战争”已经和地缘政治、能源结构、产业链安全深度纠缠在一起。Epoch AI 的最新测算认为,当前全世界 Nvidia GPU 的装机总算力约相当于 400 万块 H100 的等效性能,峰值总算力达到 4×10²¹ FLOP/s 量级;(Epoch AI) 另一份对未来 AI 算力产能的预测则认为,如果供应链瓶颈按当前节奏演进,到 2027 年全球 AI 相关算力可能比 2025 年再放大 10 倍,达到 1 亿片 H100 等效的规模。(ai-2027.com) 这些数字背后,是天文数字的资本开支、数据中心用电以及散热、选址、监管等一整套问题。
讨论“强人工智能的计算需求到底有多恐怖”,如果只是感叹“好贵好大”,其实意义不大。更有价值的,是把这件事拆开来看:到底是哪一部分在烧钱,是算力硬件,是数据采集与标注,还是算法本身的复杂度;在当前和可预见的未来,哪一块是刚性约束,哪一块还有优化空间;对于普通企业和开发者来说,在这个被巨头算力碾压的时代,是否还有参与“强人工智能”实验的现实路径。
本文尝试沿着“算力—数据—算法复杂度”这三条主线,把现有开源文献和公开数据串成一张尽量直观的“成本地图”。一方面,我们会用相对粗糙但量纲清晰的方式估算 GPT-3、GPT-4 级别模型的训练 FLOPs、时间和资金开销;另一方面,也会借助 scaling laws、数据枯竭分析和算法效率研究,看看在同样算力下算法可以省出多少空间,在同样数据量下还能挖出多少“有效信息”,最后再讨论这些趋势叠加后,对可能出现的“强人工智能”意味着什么。
2 算力:从一块 GPU 到一座“电厂”
2.1 训练一次 GPT-3 / GPT-4 需要多少 FLOPs
要直观感受强人工智能的算力需求,最简单粗暴的方式就是给大家拉一张“账单”。以 GPT-3 为例,根据第三方技术拆解,175B 参数的 GPT-3 在训练阶段大约消耗了 3.1×10²³ 次浮点运算,假设采用 28 TFLOP 的 V100 GPU,理论上等价于 355 块 V100 连续满负载跑一整年,或者一块 RTX 级别 GPU 连续跑 600 多年。(Lambda) 这还只是 2020 年的“旧时代”模型。
到了 GPT-4,情况明显变得更加夸张。不同机构对 GPT-4 训练 FLOPs 的估算略有差异,Epoch AI 和后续分析给出的区间大致在 10²⁵ 量级,有的估计值为 2.2×10²⁵ FLOPs,有的则以 10²⁵ FLOPs 作为 GPT-4 级模型的下限基准;更激进的一些讨论甚至给出 10²⁵ 到 10²⁶ FLOPs 的范围,并强调 GPT-4 相比 GPT-2 的训练算力增长约为 3000 到 10000 倍。(Epoch AI) 2025 年初 Epoch 的统计显示,至少已经有 30 多个模型的训练 FLOPs 达到了 GPT-4 这个规模,甚至部分开源模型(如 Llama 3.1-405B)在估算时给出的训练 FLOPs 也逼近或超过了 3.8×10²⁵。(Epoch AI)
如果把这些数据对比在一起,可以构造一张非常直观的“训练规模演化表”。
表 1 典型大模型训练计算量与成本量级示意(公开估算)
| 模型与年份 | 参数规模大致量级 | 估算训练 FLOPs 量级 | 估算单次训练直接成本量级(美元) | 主要参考来源与说明 |
|---|---|---|---|---|
| GPT-2(2019) | 1.5B | 约 10²¹ | 百万级以下 | 由 GPT-4 相对 GPT-2 的倍数反推,非精确数值(SITUATIONAL AWARENESS - The Decade Ahead) |
| GPT-3(2020) | 175B | 3.1×10²³ | 数百万到千万级 | 第三方技术分析估算训练 FLOPs 与成本(Lambda) |
| GPT-4(2023) | 未公开(数百 B 级) | 10²⁵ 左右(约为 GPT-3 的百倍级) | 约 4000 万美元直接训练成本 | 2024 年成本分析论文估算 GPT-4 训练费用(arXiv) |
| Gemini Ultra 等前沿模型 | 数百 B 级 | 10²⁵ 量级 | 约 3000 万美元训练成本 | 同一论文对 Google Gemini Ultra 成本估算(arXiv) |
| “Gen2” 前沿模型群(2023–24) | 数百 B 级到万亿级 | 10²⁵–10²⁶ 之间 | 单次训练成本可达 1 亿美元甚至更高 | 行业综述对第二代前沿模型 compute 与成本的汇总(oneusefulthing.org) |
可以看到,仅从 2020 年到 2023 年,代表性语言模型的训练 FLOPs 至少增长了两个数量级,而单次训练的直观资金成本从几百万美元推高到数千万甚至上亿美元。这还没有考虑到失败实验、调参试错和多版本迭代所消耗的额外资源。2024 年一篇关于“训练前沿模型成本”的系统分析指出,在公开披露的案例中,GPT-4 训练成本约 4000 万美元,Google Gemini Ultra 约 3000 万美元,而且近几年前沿模型的训练成本普遍呈上升趋势,这意味着“性能换钱”的边际代价在快速变大。(arXiv)
如果再把这些 FLOPs 映射到具体硬件,比如 Nvidia H100,就更加生动。H100 官方标称的 BF16 / FP8 张量核心理论峰值性能可达 1500 TFLOPS 左右,(NVIDIA Developer) 假设一个 2048 块 H100 规模的训练集群,在优化良好、利用率较高的情况下,针对 10²⁵ FLOPs 量级的训练任务理论上也要跑数周甚至更长时间,而且任何一次训练失败、超参数失误或者数据 pipeline 问题,都会让这几周的 GPU 时间直接蒸发成一条警告邮件。
从这个视角看,“强人工智能”的算力需求之所以显得恐怖,首先在于它把传统意义上的“超级计算任务”变成了可以反复尝试和迭代的日常工作流:以前只有国家级气象模拟、天体物理或核模拟才会占用 10²⁵ FLOPs 级别的计算量,而现在一个改进版的前沿大模型预训练就能轻松达到甚至超出这个级别,而且还可能要迭代好几轮。
2.2 全球算力基建、能耗与“电厂级 AI”
当我们把视角从单次训练转向全球算力基建,会发现“强人工智能的计算需求”正在对整个基础设施体系提出前所未有的挑战。Epoch AI 在 2025 年初发布的一项分析估计,目前全世界基于 Nvidia GPU 的总算力约为 4×10²¹ FLOP/s,相当于大约 400 万块 H100 的等效性能;这也是首次有团队尝试将全球 GPU 存量统一折算成单一“H100 等效”指标。(Epoch AI) 另一份面向 2027 年的算力预测报告则指出,如果当前产能扩张和效率提升趋势延续,全球 AI 相关算力有望在 2027 年前后达到 1 亿片 H100 等效,比 2025 年大约再扩大 10 倍。(ai-2027.com)
中国关于智算中心和 AIDC(AI 数据中心)产业的白皮书则从另一个角度给出了类似的“暴涨曲线”。一份 2025 年发布的报告显示,到 2023 年全球智能算力规模已经达到约 875 EFLOPS(10¹⁸ FLOPS),首次超过传统基础算力,并且美国和中国两国合计占据了超过七成的全球算力份额;同一报告还指出,新一代 AI 服务器的单机总功耗已经突破 14kW,使得传统风冷数据中心的 PUE 优化遇到瓶颈,被迫加速向液冷等高效散热方案迁移。(DFCFW PDF)
另一方面,具体企业在算力扩张上的“放卫星式”目标也让人直观感受到了什么叫“电厂级 AI”。例如,xAI 宣称计划在未来数年内将其 AI 训练算力扩展到相当于 5000 万块 H100 的水平,对应约 50 ExaFLOPS 的计算能力。根据媒体估计,如果完全使用当前 H100 级别硬件,这样的集群在满负载下的功耗可能高达 30–35GW,而即便采用未来更高效的芯片架构,保守估算也需要 4–5GW 左右的持续功率,大致相当于数座大型核电站的发电能力。(Tom's Hardware) 这还仅仅是“一个公司”的规划,而非整个行业的合计需求。
可以用一张简单的表格,把“从单 GPU 到全球算力”和“从机架功耗到电厂级耗能”的数量级拉在一起,形成一个比较直观的对照。
表 2 算力与能耗量级对照示意(粗略估算,非精确数据)
| 级别场景 | 典型硬件或集群规模 | 理论峰值算力量级 | 典型功耗或能耗量级 | 说明 |
|---|---|---|---|---|
| 单块高端 GPU(如 H100 SXM) | 1 GPU | 百万亿 FLOPS(10¹⁵) | 数百到近千瓦 | 官方标称 TFLOPS 与 TDP 范围(NVIDIA Developer) |
| 千卡级训练集群 | 1000–2000 GPU | 百万亿到千万亿 FLOPS(10¹⁷–10¹⁸) | 数百千瓦到数兆瓦 | 大模型预训练常见规模 |
| 超大规模前沿模型训练集群 | 10 万级 GPU | 约 1–5 ExaFLOPS(10¹⁸–10¹⁹) | 数十兆瓦到百兆瓦 | 用于 GPT-4 级乃至更大模型多轮训练 |
| 全球 GPU 装机总量(2025 估计) | 约 400 万 H100 等效 | 约 4×10²¹ FLOP/s | 数百到近千 GW(假设高负载) | Epoch AI 对全球 GPU 容量的估算(Epoch AI) |
| xAI 规划的 50M H100 等效算力集群 | 约 50 ExaFLOPS 目标 | 约 5×10¹⁹ FLOP/s | 4–35 GW(视芯片技术而定) | 媒体对 Colossus 2 等超大集群的功耗估算(Tom's Hardware) |
从表中可以看出,当我们讨论“强人工智能的计算需求”时,实际上已经很难把它当作一个“计算机科学内部”的问题来看待。一个 10 万 GPU 级别的训练集群不仅仅是非常贵的服务器集合,它同时意味着持续数十兆瓦的电力消耗、复杂到近乎艺术的散热与供电工程,以及对电网、用地、冷却系统和碳排放指标的长期影响。
这也是为什么近两年“算力治理”和“以训练 FLOPs 作为监管阈值”的讨论开始在政策圈频繁出现。有研究建议,针对可能带来系统性风险的前沿模型,通过设置“训练 compute 阈值”来触发更严格的评估与报告要求,因为训练算力与模型能力之间存在较强相关,而算力本身又相对容易监管和审计。(Institute for Law & AI)
2.3 算力增长的速度极限与经济极限
从短期趋势来看,算力似乎还没有遇到真正的“硬天花板”:一方面,Nvidia 等厂商在 Hopper、Blackwell 等新架构上持续把单芯片性能推向新的指数级台阶,例如官方宣称 B200 / B300 相比上一代 H200 在多种精度下能提供两倍以上的吞吐提升;(exxactcorp.com) 另一方面,产业界也在通过 Chiplet、光互连、3D 堆叠和系统级优化,不断压缩每 TFLOP 的边际成本。
然而,从整个模型家族的发展轨迹来看,“单纯堆算力”的路线已经开始出现明显的边际收益递减现象。一篇 2025 年的分析指出,从 GPT-2 到 GPT-3 再到 GPT-4,每一代前沿模型大致使用了前一代 70 倍左右的训练 FLOPs(约从 4×10²¹ 到 3×10²³ 再到 2×10²⁵),但带来的性能跃迁并没有呈线性对应关系。(Forethought) 同期政策和战略分析报告也提醒,如果当前趋势持续,到了 2030 年左右,训练一次“前沿 AGI 候选模型”可能需要比 GPT-4 高 1000 倍的物理算力,而算法优化导致的“有效算力”甚至可能达到 GPT-4 的百万倍,这种规模的投资和能耗会对整个社会产生结构性的影响。(CNAS)
因此,算力增长不仅存在物理极限(半导体工艺、散热、光速、能量密度等),也存在经济与政治层面的极限。2024 年关于前沿模型成本的实证研究指出,2016 年以来,每年训练成本都有明显抬升趋势,且受限于高端 GPU 的供应链、数据中心建设周期以及能源成本,算力扩张不可能无限延续。(arXiv) 这也解释了为什么越来越多的顶级研究者开始公开质疑“只靠 scaling laws 堆到 AGI”的路线,认为没有算法范式上的新突破,仅仅提升参数、数据和算力,终究会在收益递减和成本炸裂之间撞墙。(Business Insider)
3 数据:从“喂不饱”到“数据要用光了”
3.1 语言模型的数据胃口到底有多大
如果说算力是“肌肉”,那数据就是语言模型的“粮食”。在 scaling laws 的研究中,数据规模与模型大小、训练 compute 一起构成了性能的三大核心变量。Kaplan 等人 2020 年的经典工作发现,模型的交叉熵损失与参数规模、训练 token 数和计算量之间遵循相当稳定的幂律关系,在很长的数量级范围内成立;在给定 compute 预算的前提下,存在一个最优的数据规模与参数规模组合。(arXiv)
然而,这个“最优组合”在最初版本的 scaling laws 中偏向“大模型少数据”的方向。直到 2022 年 DeepMind 的 Chinchilla 工作系统性扫描了不同参数规模和数据大小的组合后,才指出此前的大模型大多是“严重欠训”的:在同样的 compute 预算下,与其训练一个巨大参数但数据不够的模型,不如采用更小的参数规模配上更多训练 token。Chinchilla 论文指出,在计算最优条件下,模型参数量和训练 token 数应该大致等比例增长,即模型大小翻倍时训练 token 也应翻倍,这实际上将主流实践从“参数优先”拉回到“数据与参数平衡”。(arXiv)
基于 Chinchilla scaling laws 的二次解读和工程经验,一种粗略的经验规律逐渐被行业接受:对于大语言模型而言,想要实现接近 compute-optimal 的训练,大致需要“约 20 个 token 喂一个参数”。以 70B 参数模型为例,理论上需要大约 1.4 万亿 token;对于 400B 级别的模型,训练数据则可能需要 8 万亿 token 左右。(Dr Alan D. Thompson – LifeArchitect.ai) 这也是为什么近两年关于“数据要不够用了”“我们会不会把互联网上能抓的文本都喂干净”这类问题,开始频繁出现在技术博客和论文当中。
中国社区在中文预训练数据方面的讨论也在迅速升温。以 优快云 和知乎上多篇数据集综述为例,许多开发者都提到英文高质量数据集(如 Common Crawl 精炼版)的规模和清洗程度远超中文,导致中文大模型在数据侧常常面临“体量不足、质量不齐”的双重难题;一些专门收集中文高质量语料的项目(如 Chinese FineWeb、BELLE 中文指令数据等)则尝试通过更严格的筛选与去重工序,弥补单纯“爬全网”的低效。(知乎专栏) 对于立志做强通用智能的团队来说,如何在多语言、多领域、多模态上构建足够大又足够干净的数据资源,已经成为算力之外的第二道硬门槛。
3.2 “我们会不会用光数据”:从 300T token 到 2026–2032
围绕“数据枯竭”的最系统分析来自 Epoch 团队的一组研究。2022 年的一篇论文和后续 2024 年更新的博客中,他们尝试估计全球可用于训练大语言模型的高质量人类文本总量,控制重复度和质量后,给出的数量级约为 300 万亿(3×10¹⁴)个 token。(arXiv) 在此基础上,如果按照当前大模型发展趋势估算,只要继续沿着“模型变大、数据跟着放大”的路径前进,那么在 2026 到 2032 年之间,我们很可能就会把这些高质量数据几乎全部消耗殆尽。
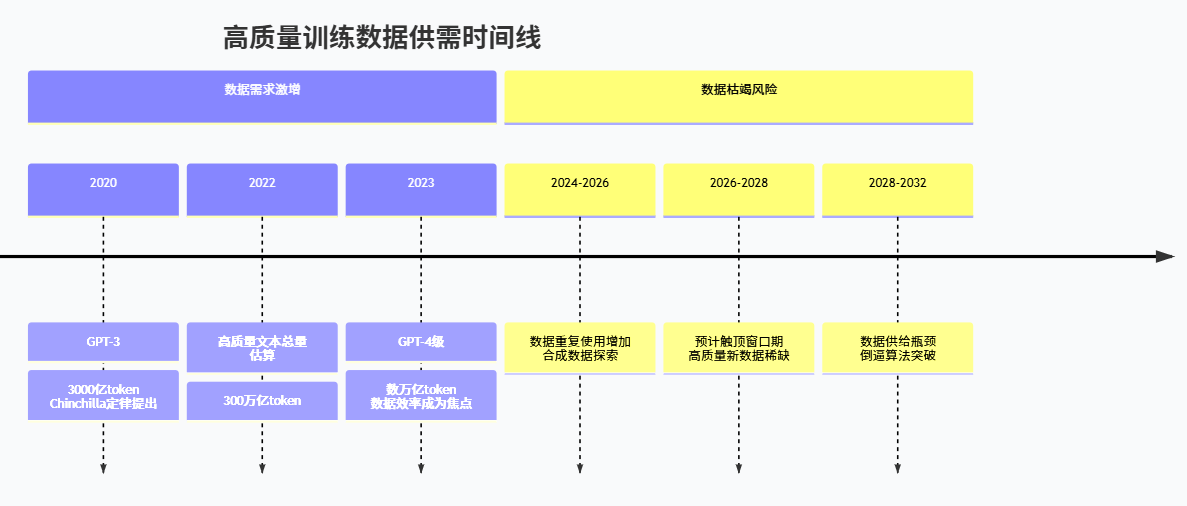
更细致的更新分析指出,原先在 2022 年的乐观预测认为高质量文本可能在 2024 左右就被“用光”,但随着对数据质量和训练方法的理解加深,重新估算后发现真正触顶的时间可能会往后推移到 2028 年甚至更远一些。然而,这并不意味着问题消失了,而只是说明对“什么算可用数据”的界定变得更宽松,或者我们在重复利用和合成数据上更有技巧。(Epoch AI)
为了把数据侧的约束感形象化,可以构造一张简化的“数据供需对照表”。
表 3 高质量文本数据供需量级对照示意(基于公开研究的粗略估算)
| 指标或场景 | 量级估算 | 说明与来源 |
|---|---|---|
| 高质量人类文本数据总量(去重后) | 约 3×10¹⁴ token(300 万亿) | Epoch 团队针对公开人类文本的综合估计(arXiv) |
| GPT-3 类模型单次训练消耗 | 数百亿到千亿级 token | OpenAI 论文与技术拆解中对 GPT-3 训练数据规模的公开信息(arXiv) |
| Chinchilla-optimal 70B 模型需求 | 约 1.4×10¹² token(1.4 万亿) | 约 20 token/parameter 经验规律(arXiv) |
| GPT-4 级模型(数百 B)单次训练需求 | 数万亿到数十万亿 token(视 scaling 假设而定) | 综合 scaling laws 与第三方估算区间(arXiv) |
| 按当前趋势预计数据“触顶”时间 | 约 2026–2032 年区间 | Epoch 关于数据枯竭时间窗口的综合预测(arXiv) |
这张表要表达的其实是一个朴素但容易被忽视的事实:相比算力可以通过投资数据中心和芯片产能来扩展,高质量训练数据的“产能扩展”要困难得多。你当然可以生成大量合成数据,也可以撬动多模态、多语言甚至机器交互产生的行为轨迹,但想要得到与人类生产的高质量文本同量级的“真正新信息”,并不是简单堆用户数、堆采集通道就能解决的。
这也是为什么在近两年的 AGI 路线图讨论中,“数据利用效率”被反复强调。有研究指出,如果我们在算法和训练范式上没有重大突破,仅仅依靠增加算力和数据规模,那么当人类自产数据用尽之后,语言模型的性能提升曲线很可能出现明显弯折,甚至提前进入收益递减区。反过来,如果能通过更好的 self-supervised 目标、更高质量的数据清洗、对长尾知识的针对性补齐以及合理的合成数据策略,在相同数据规模下挖掘出更多“有效梯度”,那么对算力和数据的依赖都可以显著缓解。(arXiv)
4 算法与复杂度:效率翻倍与“思维链”的代价
4.1 Scaling Laws:性能、算力和复杂度的三角关系
谈“计算需求”如果只看 FLOPs 和 GPU 数量,会落入一个非常粗糙的视角。真正决定强人工智能成本的,其实是性能、算力和算法复杂度三者之间的耦合关系。Kaplan 等人的 scaling laws 工作从经验上给出了一个令人印象深刻的结论:在相当长的范围内,语言模型的损失函数与模型大小、数据规模和算力之间可以用简单的幂律公式来拟合,其他架构细节的影响相对次要;换句话说,只要你沿着这条幂律曲线成比例放大三者,就几乎可以“预测”性能会如何提升。(arXiv)
Chinchilla 工作进一步补全了 scaling 图景:它说明此前主流实践下的模型往往是 compute-suboptimal 的,即在给定算力预算下,模型参数偏大而数据偏少,从而浪费了大量算力;一旦按照更新后的 scaling 规律调整到“参数和数据同步扩展”的区域,同样的训练 FLOPs 可以换来明显更好的性能表现。(arXiv)
最近两年,一些研究和工程博客对 scaling laws 做了更工程化的解读,强调它们其实是一种“经验性的成本曲线”:你可以把性能看作输出,把算力和数据看作投入,scaling laws 告诉你在某个“操作区间”内,大致需要付出多少 compute 才能获得某个性能增益;而当你试图把性能推向更高档位时,就会发现算力成本不是线性增加,而是呈现某种“超线性”的高度陡峭曲线。(Epoch AI)
更麻烦的是,随着模型被部署到更复杂的推理任务上,推理时的“算法复杂度”也在迅速上涨。比如,链式思维(Chain-of-Thought)和自反思推理(self-reflection)虽然大幅提升了模型在数学、编程和逻辑推理任务上的表现,却也让每个问题的平均 token 消耗成倍增加;最近的一些“推理特化模型”(如 o1 系列和其他鼓励模型长时间“思考”的架构)在 benchmark 上展现了强大的 reasoning 能力,但代价是单次推理的 compute 和延迟都远高于传统对话模型。(Le Monde.fr)
从复杂度角度看,这其实是把一部分“本来在训练阶段付出”的算力,搬到了推理阶段。传统做法是用极高的训练算力把知识“烤进参数里”,推理时只需做相对简单的前向传播;而推理增强模型则允许在推理时执行多步搜索、规划和反思,让模型在每一个问题上“临时展开复杂运算”。这种做法有利于性能和可靠性,但对整体算力需求而言是个巨大乘数。
4.2 算法效率:每 16 个月省一半算力
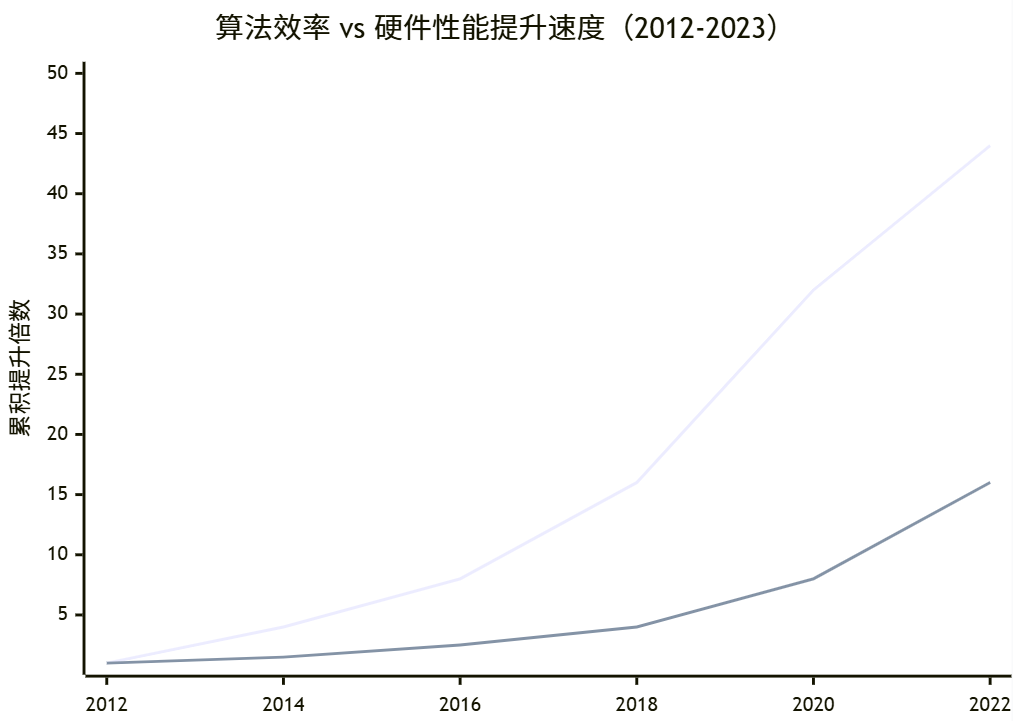
所谓“算法效率”,可以理解为在同样性能目标下所需的算力。OpenAI 的 “AI and Efficiency” 分析通过一个 clever 的办法来测量这一指标:固定住一个基准任务(例如在 ImageNet 上达到 AlexNet 性能),然后用更现代的网络结构和训练技巧去达成同样效果,比较所需的训练 FLOPs 变化。结果显示,从 2012 年到 2019 年,实现同样性能所需的算力下降了约 44 倍,折合为“效率提升”就是每 16 个月翻一番,远快于同期硬件性能提升。(OpenAI)
后续的一些综述和经验总结也印证了类似的趋势:通过更好的优化器、更稳定的归一化技术、更合理的正则化、更高效的并行训练策略以及更贴合硬件的模型结构,我们在不改变“模型能力等级”的前提下,的确持续压缩了训练同等水平模型所需要的 FLOPs。(mlsysbook.ai) 在近期关于“前沿模型训练成本”的论文中,研究者们同样强调,需要把硬件性能提升与算法效率提升看成一对相乘关系,而不是简单相加:硬件提供了原始算力上限,算法决定了在这个上限下能用多少算力转化为“有效梯度”。(arXiv)
从强人工智能的角度看,这个结论既让人绝望,也让人乐观。绝望之处在于,即便算法效率每 16 个月翻倍,算力需求依然在很大程度上被前沿模型的 scaling 曲线拉着狂奔,导致整体成本仍然呈指数上涨;乐观之处在于,这意味着我们并不完全被物理算力锁死,而是在算法和训练范式上存在极大的优化空间。
4.3 推理复杂度:强推理模型的“隐形账单”
前面提到的 o1 一类推理特化模型,给我们展示了另一个维度的复杂度问题。根据媒体和技术分析报道,这类模型之所以能在复杂推理任务上取得突破,很大程度上是因为它们在推理阶段执行了更多步骤的内在搜索、反思和计划,相当于为每个问题“开小灶”,而不是像传统生成模型那样对每个 token 做一次简单预测就完事。(Le Monde.fr)
如果从复杂度角度粗略估计,假设一个普通的聊天请求平均消耗几百到一千个 token 前向传播,那么链式思维和自反思机制可能会把这个数字增加一倍甚至数倍,而更极端的“树状思维”“反复自检”等技巧则更进一步放大这一倍数。在大规模应用场景下,这意味着同样的用户请求量,会带来数倍的推理算力开销,而这些开销往往很难完全通过模型压缩或蒸馏来抵消。
因此,当我们谈论“强人工智能”的计算需求时不能只盯着训练阶段,推理阶段的复杂度同样是重要一环。尤其是在面向 AGI 的设想中,系统不再只是被动回答问题,而是要持续在后台运行世界模型、执行长期规划、与海量外部工具和环境交互,这些过程必然显著放大推理侧的算力消耗。换句话说,AGI 不再是“偶尔训练一次的大型工程”,而可能是“24×7 不停做复杂推理的在线系统”,这从根本上改变了算力需求的时间结构。(CNAS)
5 综合算一笔账:假想“类 GPT-5 级”强 AI 的计算画像
5.1 假设场景与关键参数
为了把前面零散的讨论收束成一个更直观的图景,可以做一个非常粗糙的假设:假设在 2030 年前后,有团队推出一个“类 GPT-5 级”的强人工智能基础模型,其能力明显超越当今的 GPT-4 / o1 / Gemini Ultra 组合,已经可以在多数专业领域实现接近人类专家水平的综合推理和决策能力。政策智库对未来前沿模型的 compute 走势曾做过一个估算,认为到 2020 年代末至 2030 年初,单次训练所需的算力可能达到 GPT-4 的 1000 倍规模,而考虑算法效率的进步后,等效 compute 甚至可能达到 GPT-4 的百万倍。(CNAS)
同时,结合 scaling laws 和 Chinchilla 规律,我们可以假设这个“类 GPT-5”模型采用了较为 compute-optimal 的参数与数据配置,例如参数规模在若干万亿(1–10T)之间,训练 token 在数十万亿到上百万亿的量级;训练过程中采用高度并行化的硬件和优化过的训练算法,整体效率显著优于 GPT-4 时代。(arXiv)
在这样的前提下,我们可以构造一个简单的“账本”,把训练 FLOPs、需要的 GPU 数量、训练时间、能耗和直接成本粗略对应起来。
5.2 粗略的 FLOPs、GPU 和时间估算
如果以 GPT-4 训练 FLOPs 为基准,假设其为 2×10²⁵ 级别,那么一个 1000×GPT-4 compute 的训练运行意味着约 2×10²⁸ 次浮点运算。(Epoch AI) 假设那时主流 GPU 的单卡有效训练性能相当于今日 H100 的数倍,例如下一代或下下一代 Blackwell / Rubin 系列在 FP8 / BF16 下可以提供 3000 TFLOPS 甚至更高的有效吞吐,那么一个包含 10 万块这类 GPU 的集群在理想情况下可以提供 3×10²º FLOP/s 的理论峰值。(NVIDIA Developer) 在现实中考虑到通信开销、负载不均衡和训练调度等因素,能利用到的也许只有峰值的一半甚至更少。
在这种非常理想化的设定下,训练一次 2×10²⁸ FLOPs 的任务大致需要数天到十多天的连续训练;如果考虑到多次“试跑”、不同超参数组合尝试、以及中途发现问题重训等现实因素,整个项目的总训练 compute 可能要再乘上一个 2–5 的系数。
可以用一张表来描述这种“类 GPT-5 级”训练的量级感。
表 4 假想“类 GPT-5 级”模型训练资源量级估算(极粗略,假设性场景)
| 项目或指标 | 粗略数值或量级 | 说明与假设 |
|---|---|---|
| 基准模型:GPT-4 训练 FLOPs | 约 10²⁵–10²⁵.⁵ FLOPs | 综合多方估计取中间值(Epoch AI) |
| 假想“类 GPT-5”单次训练 FLOPs | 约 10²⁸ FLOPs(GPT-4 的 1000×) | 参考政策报告中“千倍 GPT-4”假设(CNAS) |
| 单卡有效训练性能 | 约 3×10¹⁵ FLOP/s(下一代高端 GPU) | 假设较 H100 再提升数倍(NVIDIA Developer) |
| 集群规模 | 约 10 万 GPU | 类比 xAI 等规划的超大集群规模(Tom's Hardware) |
| 理论峰值集群算力 | 约 3×10²⁰ FLOP/s | 单卡性能乘以 GPU 数量 |
| 单次训练时间(理想利用率) | 约数天到一两周 | 10²⁸ ÷ 3×10²⁰ 得到的级别,未计入利用率损失 |
| 总项目训练 compute(含重训与试验) | 约数 ×10²⁸ FLOPs | 乘上 2–5 的系数以考虑多次训练 |
| 直接训练硬件与电力成本 | 保守估计为数亿美元甚至十亿美元级 | 参考当前 GPT-4 训练 4000 万美元成本与硬件价格走势(arXiv) |
可以看到,即便在非常乐观的硬件与算法效率假设下,面向“类 GPT-5 级”强人工智能模型的单次训练仍然是一个“几天到十多天、10 万 GPU 全天候满载”的超级工程,任何一次严重错误都意味着数亿美元级别的资源浪费。这也是为什么在战略分析中,很多人开始把“训练 compute 本身”视为一种需要被审慎治理、甚至有可能成为限制条件的核心变量。(CNAS)
5.3 能源、散热与全生命周期成本
上述估算还只是训练阶段的“直接账单”。如果把视角扩展到整个生命周期,还需要考虑模型上线后的推理算力、日常维护与升级、蒸馏和压缩模型的训练开销、不断更新的数据管线等一系列因素。2024–2025 年多篇行业报告都提到,随着大模型部署规模的扩张,推理侧的算力开销已经开始超过训练侧,而且在很多企业场景中,推理延迟和成本直接决定了产品的商业可行性。(arXiv)
在能耗方面,中国和海外关于算力中心的白皮书反复强调“功耗激增倒逼散热技术升级”的现实:单服务器超过 14kW 的功耗意味着传统风冷数据中心的 PUE 很难再显著优化,不转向液冷就无法部署足够高的功率密度;同时,为了满足大模型训练与推理的持续供电需求,越来越多的数据中心开始考虑与可再生能源基地、核电站甚至新型储能设施直接绑定。(DFCFW PDF)
从这个意义上说,强人工智能的计算需求“恐怖”之处不在于某一个模型用掉了多少 GPU,而在于它把整个计算基础设施、能源系统和算法研发绑成了一根绳:硬件架构、芯片产能、数据中心建设、电力系统和算法创新,任何一个环节失速,都会拖慢整条路径的推进速度。
6 对工程实践的启示:普通团队如何在“算力地震”中活下去
6.1 算力鸿沟与“穷人的 AGI 路线”
MIT 等机构最近的一项研究在学术圈引发了广泛讨论:随着基础模型变得越来越大、训练成本越来越高,学术界和中小企业与大厂之间出现了明显的“算力鸿沟”,能够真正参与训练前沿模型的机构越来越少,大量研究者被迫转向只在大厂模型上做微调和下游应用。(techwalker.com)
然而,这并不意味着普通团队就完全没有机会参与“强人工智能”的探索。相反,很多开源与研究工作都在积极展示一条“穷人的 AGI 路线”:通过高效的开源模型、良好的知识蒸馏、精准的数据工程和巧妙的系统架构,把有限的算力集中在真正产生差异化价值的地方。Meta 等公司在开源 Llama 系列模型的过程中,已经展示了利用相对有限的内部算力训练高质量基础模型的可能性;大量中文开源模型和指令数据集则在数据侧进行持续积累,让更多人可以在不具备百亿级预算的情况下,体验并参与“类前沿智能”的工程实践。(GitHub)
在这种背景下,“算力分层”变得格外重要。一些行业分析和技术博客建议,普通团队可以把问题划分为三个层级:在最底层,尽可能利用开源基础模型和云厂商提供的推理 API,避免从零开始训练大模型;在中间层,围绕具体业务场景构建高质量的小规模数据集,进行针对性的微调和知识蒸馏,训练自己的“专科小模型”;在顶层,通过智能编排框架把多个基础模型、专科模型和传统系统组合起来,构建类似 Agent 的复合系统,从系统层面逼近“强人工智能”的某些能力,而不必执着于单一模型本身是否达到 AGI 水平。(oneusefulthing.org)
6.2 模型压缩、蒸馏与“用小模型做大事”
在算力紧张而应用需求繁多的环境中,模型压缩和蒸馏技术的重要性不断上升。近年来的研究表明,通过精准的知识蒸馏、小心设计的 student 模型结构和针对具体任务的蒸馏过程,小模型在很多场景中可以接近甚至超越原始大模型的表现,同时显著降低推理成本和延迟。行业实践中常见的做法包括:使用大模型生成合成指令数据,对小模型进行监督微调;利用强化学习或偏好建模,让小模型学习大模型在人类偏好上的表现;针对特定模态(如代码、数学、法律文本)训练专门的轻量模型,以替代在这些任务上泛用大模型的高昂成本。(Le Monde.fr)
在国内大模型生态中,一些团队已经借助开源基础模型、精心构造的中文数据和多轮迭代蒸馏,训练出了适合本地场景的轻量模型,并通过量化、推理图优化和编译器技术,把这些模型部署在边缘设备或本地服务器上。(GitHub) 这些实践共同指向一个结论:即使在强人工智能的远景中,我们也极不可能看到“一统天下”的超级模型,反而更可能出现一个“巨型基础模型 + 大量蒸馏专科模型 + 传统系统 + 工程 glue 代码”的混合生态。
6.3 数据治理、对齐与“有效算力”
在算力和数据都极其昂贵的前提下,“有效算力”这个概念越来越值得强调。所谓有效算力,可以理解为真正用于学习有用模式、构建世界模型和对齐目标的那部分 compute,而不是被浪费在重复数据、噪声样本、坏标注、无意义的字符模式或失败的训练实验上。
从现有文献来看,提升有效算力的途径大致可以归为几个方向:通过更严格的数据去重、质量评估和采样策略,减少模型在重复和低价值数据上的梯度更新;利用 curriculum learning、active learning 等方法,让模型在训练过程中优先接触更有“教学价值”的样本;通过更好的训练监控和中间指标,尽早发现训练过程中的模式崩溃或过拟合,避免浪费大量算力在注定失败的配置上;在对齐过程中,设计更高效的偏好标注和强化学习流程,让每一条人类反馈都产生尽可能大的策略改进。(OpenAI)
中国与国际上的政策与产业报告则在更高层面提醒我们,算力和数据已经成为一种新的“生产要素”,如何在安全可控的前提下开放算力、共享数据和工具,同时防止极少数机构对前沿算力形成垄断,是关系到强人工智能未来形态的重要议题。(npc.gov.cn)
7 结语:强人工智能的计算需求会无限膨胀吗?
回到本文开头的问题:“强人工智能的计算需求到底有多恐怖?”从算力的角度看,OpenAI 在 2018 年画出的那条“每 3.4 个月翻一番”的曲线已经足够惊心动魄,而 2018 年之后的前沿模型发展在相当长时间里基本沿着这条曲线向上狂飙,直到近几年才因算法效率提升、硬件供应约束和投资风险等多重因素而略微放缓节奏。(OpenAI) 从数据的角度看,针对高质量文本数据的“存量测算”表明,如果继续沿着 naive scaling 路线走下去,人类可用的高质量文本极有可能在 2026–2032 年之间被现有范式吃到边际收益极低的程度,这迫使行业必须在数据获取、数据利用和合成数据策略上做出创新。(arXiv) 从算法复杂度的角度看,scaling laws 一方面为我们提供了相对可靠的性能预测工具,另一方面也暴露出“性能换算力”的陡峭成本结构;推理特化模型在提升 reasoning 能力的同时,让每一次“思考”都变得更加昂贵。(arXiv)
然而,恐怖的并不仅仅是这些数字本身,而是它们所指向的那种系统性压力:当训练一个模型需要 10²⁵–10²⁸ 级别的 FLOPs,需要动辄数万到十万 GPU,需要与电力系统和冷却技术捆绑设计,需要投入数亿美元甚至十亿美元的预算时,强人工智能就不再只是一个技术问题,而是被嵌入到了整个社会技术-经济结构之中。谁能负担得起这样的算力,谁能积累足够的数据,谁掌握更高效的训练和推理算法,谁就在未来的智能生态中握有更大的主动权。(arXiv)
乐观的一面在于,我们并不是无能为力的旁观者。历史经验表明,每当硬件和资源的压力逼近某种极限时,算法和系统架构往往会爆发出新的创造力;OpenAI 的“AI and Efficiency”展示了算法效率可以如何以快于硬件的速度提升,Chinchilla 和一系列后续工作则说明,在合理的 scaling 区域内,我们可以用更聪明的训练策略“少花冤枉算力”;关于数据枯竭的研究则推动更多人认真思考高质量数据的采集、去重和合成问题;而对于普通开发者和企业来说,开源模型、蒸馏技术和系统级创新仍然提供了广阔的空间,让我们可以在有限算力下做出真正有用的智能系统。(OpenAI)
或许,真正值得警惕的不是“算力到底有多恐怖”,而是如果我们只在一条简单的 scaling 曲线上一味向右狂奔,可能会在某个时间点同时撞上算力、数据和能耗这三道墙。真正面向强人工智能的技术路线,很可能是“算力扩张、数据治理和算法创新”三者交替接力的过程:在某个阶段,算力成为主要瓶颈,推动硬件和基础设施升级;在另一个阶段,数据成为主要瓶颈,迫使我们重新思考模型如何高效利用信息;而在更长远的阶段,算法和架构范式的突破,也许会让我们在更低的算力和数据需求下,逼近甚至跨越当前想象中的“强人工智能”边界。
参考资料(部分开源文献与公开资料)
[1] Dario Amodei, Danny Hernandez et al., “AI and Compute”, OpenAI Blog, 2018;及后续 CSET 报告对该趋势的延伸分析。(OpenAI)
[2] Jared Kaplan et al., “Scaling Laws for Neural Language Models”, arXiv:2001.08361, 2020。(arXiv)
[3] Jordan Hoffmann et al., “Training Compute-Optimal Large Language Models (Chinchilla)”, NeurIPS 2022。(arXiv)
[4] Danny Hernandez, Tom Brown, “AI and Efficiency”, OpenAI Blog, 2020;及相关教材中对算法效率曲线的总结。(OpenAI)
[5] Jaime Sevilla, Lennart Heim et al., “Compute trends across three eras of machine learning”, Epoch AI Blog, 2022。(Epoch AI)
[6] Tamay Besiroglu et al., “Will we run out of data? Limits of LLM scaling based on human-generated data”, arXiv:2211.04325, 2022;及 2024 年更新博客。(arXiv)
[7] Epoch AI, “Over 30 AI models have been trained at the scale of GPT-4 (≥1e25 FLOP)”, Data Insight, 2025。(Epoch AI)
[8] Epoch AI, “NVIDIA chip production and installed base”, 2025;以及 AI-2027 对全球 H100 等效算力增长的预测。(Epoch AI)
[9] Lennart Heim, “Transformative AI and Compute”, 2021;讨论 compute 与算法效率在 AI 进步中的乘法效应。(Blog - Lennart Heim)
[10] Lennart Heim, Marius Hobbhahn et al., “The rising costs of training frontier AI models”, arXiv:2405.21015, 2024。(arXiv)
[11] Nvidia 官方资料与技术博客,“NVIDIA H100 Tensor Core GPU” 产品页面及性能介绍;以及 H100 在 HPC/AI 场景中的性能实测。(NVIDIA Developer)
[12] Ethan Mollick, “Scaling: The State of Play in AI”, One Useful Thing, 2024。(oneusefulthing.org)
[13] CNAS, “Future-Proofing Frontier AI Regulation”, Policy Report, 2024。(CNAS)
[14] Law-AI.org, “The role of compute thresholds for AI governance”, 2025。(Institute for Law & AI)
[15] Epoch AI & 80000hours 对 Danny Hernandez 的访谈与经验总结,讨论算法效率与 compute 进步的相对重要性。(80,000 Hours)
[16] 国内多篇关于算力中心、AIDC 和大模型产业的白皮书与分析报告,包括 2025 年中国 AIDC 产业白皮书以及大模型投资策略报告等。(DFCFW PDF)
[17] 国内外关于中文预训练数据集、开源大模型及实践经验的文章与项目文档,包括 优快云、知乎和 GitHub 上的大模型数据集与中文 LLM 汇总。(知乎专栏)
[18] 各类技术媒体和新闻报道,对 xAI、OpenAI、Meta 等公司在前沿算力和模型路线上的公开信息的跟踪分析。(Tom's Hardware)


















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











