






效率工具
-
文献整理软件:
Zetoro,方便点:文献打Tag,方便检索
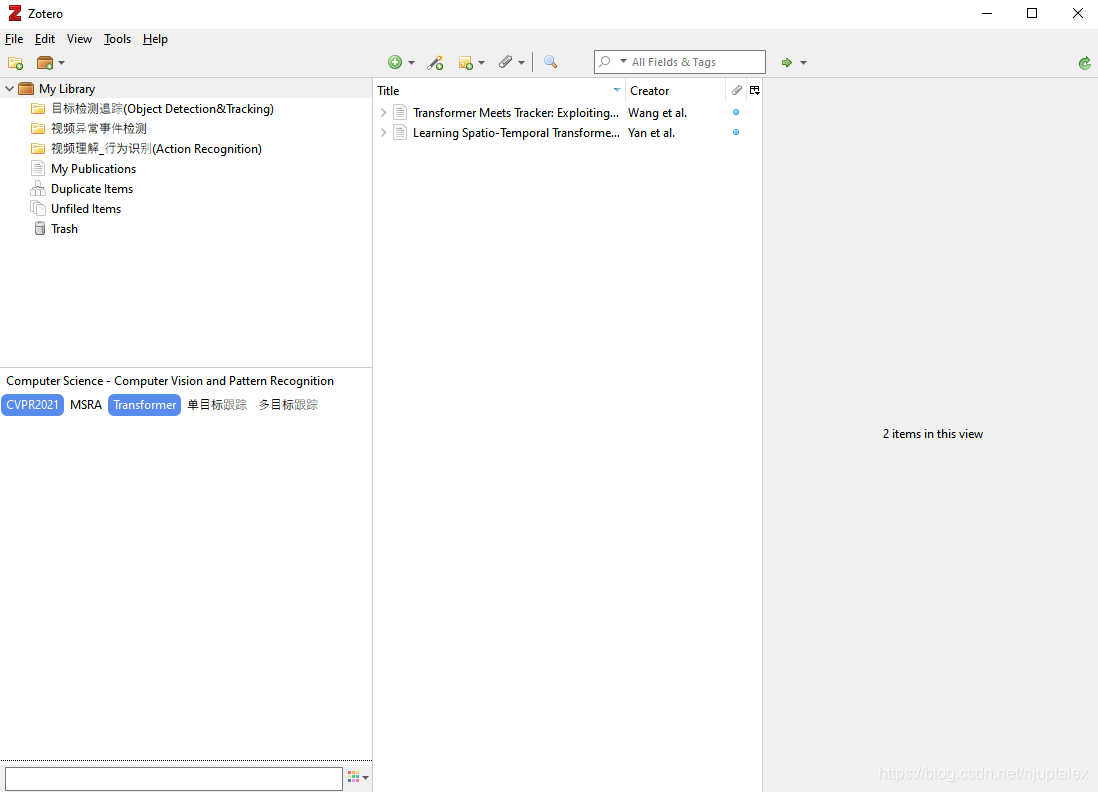
-
任务面板软件:
Notion,
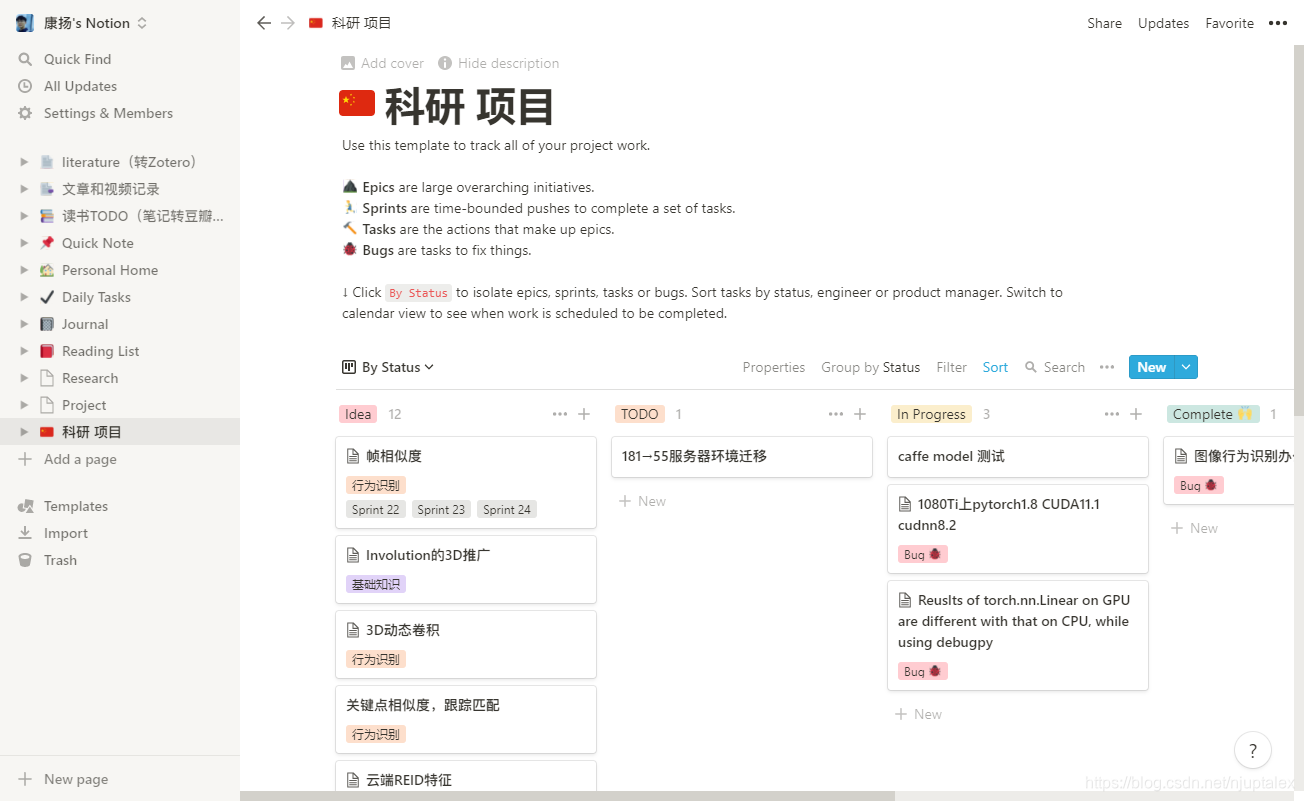
-
以上是近期最提升效率的两个软件。还有很多,有空出个合集
编译 Caffe 1.0
Fork 官方源代码 修改了一些编译选项和代码以适应新依赖
时间:2021.5.5
发布:Release v1.1
部署指南:README
重要依赖:
- Support: CentOS Linux release 7.2.1511 CUDA-11.1 CuDNN-8
- Support: gcc 9.1.0 c++11 cmake 3.20.1
- Support: opencv-4.3
- Support: python3.8 numpy 1.19.4 protobuf-3.6 Opencv4.3 gcc9.1
ISSUE
Reuslts of torch.nn.Linear on GPU are different with that on CPU, while using debugpy
vscode pydebug 在GPU上调试pytorch会出现计算结果不正确的BUG
- debugpy version: 1.3.0 (run import debugpy; print(debugpy.version) if uncertain)
- OS and version: CentOS Linux release 7.2.1511
- Python version 3.8.0 (& distribution if applicable, e.g. Anaconda): XXX
- Using VS Code or Visual Studio: VS Code
- NVIDIA-SMI 455.32.00 Driver Version: 455.32.00 CUDA Version: 11.1
- NVIDIA GTX 1080Ti
CUDA ERROR
GTX 1080Ti上pytorch1.8CUDA11.1cudnn8.2net.to("cuda:0")执行卷积推理的时候CUDNN_STATUS_INTERNAL_ERROR
Sceenshots
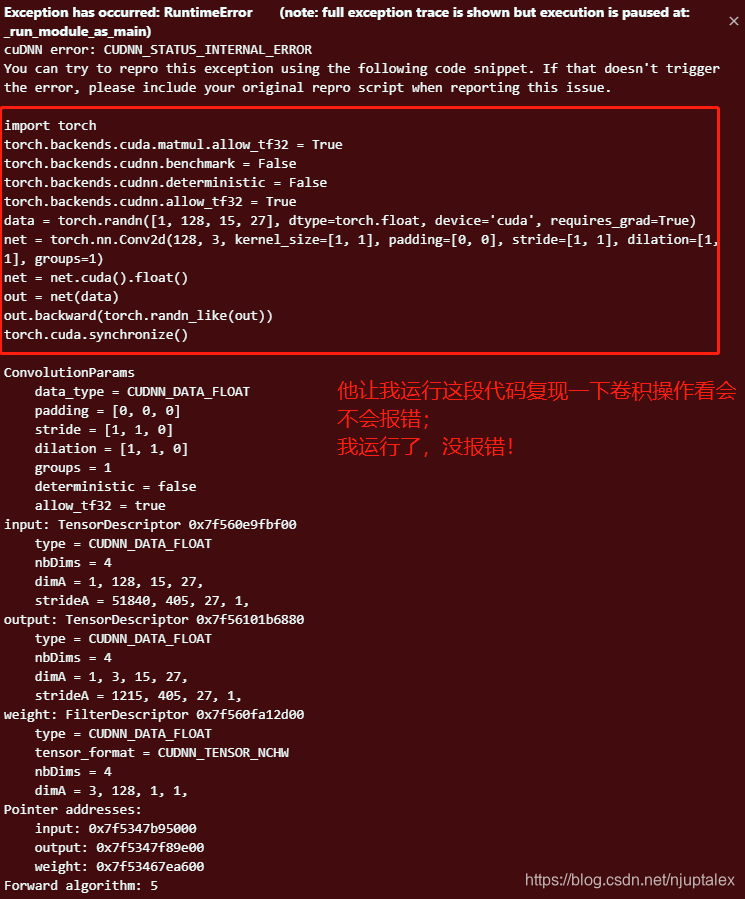
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.allow_tf32 = True
device = torch.device("cuda:0")
data = torch.randn([1, 128, 8, 14], dtype=torch.float, requires_grad=True)
data = data.to(device)
net = torch.nn.Conv2d(128, 128, kernel_size=[3, 3], padding=[1, 1], stride=[1, 1], dilation=[1, 1], groups=1)
net = net.float()
net = net.to(device)
# with torch.no_grad():
out = net(data)
out.backward(torch.randn_like(out))
torch.cuda.synchronize()
# CUDA_VISIBLE_DEVICES=2 python cudnn_test.py
Recommendations
- NNPACK needs AVX2 CPU instructions, You could potentially build PyTorch from source without NNPACK to silence this warning or ignore it. 可能要重新编译
pytorch, - 因为在
RTX 3090上不会报任何的错误,因此应该是1080TiCUDA11.1pytorch1.8cudnn8.2不兼容的错误。如果要在1080Ti上使用pytorch1.8,应该降低CUDA和Cudnn版本; 比如pytorch1.4CUDA10.2Cudnn 5 CUDA版本和GPU硬件绑定,安装必须要root权限;Cudnn版本用户可以随意切换, 只需要指定.so地址
cat cudnn.h | grep CUDNN_MAJOR -A 2` # 查看CUDNN版本
python -m torch.utils.collect_env # 查看pytorch相关依赖
SORT: Simple, Online, Realtime, Tracker在新环境下的适配
from sklearn.utils.linear_assignment_ import linear_assignment
DeprecationWarning: The linear_assignment function is deprecated in 0.21 and will be removed from 0.23. Use scipy.optimize.linear_sum_assignment instead.
替换为
from scipy.optimize import linear_sum_assignment
#compute your cost matrix
indices = linear_sum_assignment(cost_matrix)
indices = np.asarray(indices)
indices = np.transpose(indices)
参考:https://stackoverflow.com/questions/57369848/how-do-i-resolve-use-scipy-optimize-linear-sum-assignment-instead
You need to replace the
sklearn.utils.linear_assignment_.linear_assignmentfunction by thescipy.optimize.linear_sum_assignmentfunction.
The difference is in the return format:linear_assignment()is returning a numpy array andlinear_sum_assignment()a tuple of numpy arrays. You obtain the same output by converting the output oflinear_sum_assignment()in array and transpose it.

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









