







一、前言
RLHF中的PPO算法存在以下问题:
- 流程复杂: 需要构建一个反映人类偏好的奖励模型
- 训练不稳定:引入多个模型包括:
reward model、critic model、actor model、ref_actor model
而 DPO 本身是一种不需要强化学习的算法,简化了整个 RLHF 流程,训练起来会更简单。
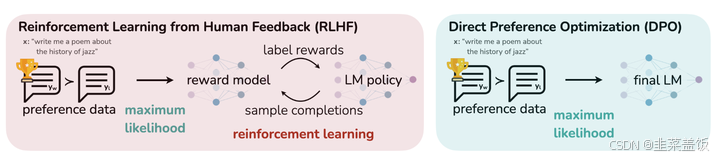
DPO 省略了reward model、critic model两个模块,直接优化目标模型(Actor)的参数,使其生成更符合人类偏好的输出。简而言之,DPO 不依赖强化学习中的“奖励”机制和“批评”机制,而是通过人类反馈直接指导优化过程。
二、DPO公式解释
这里先放一下DPO最终的公式
L DPO ( π θ ; π ref ) = − E ( x , y w , y l ) ∼ D [ ln σ ( β ln π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β ln π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \ln \sigma \left( \beta \ln \frac{\pi_\theta(y_w \mid x)}{\pi_{\text{ref}}(y_w \mid x)} - \beta \ln \frac{\pi_\theta(y_l \mid x)}{\pi_{\text{ref}}(y_l \mid x)} \right) \right] LDPO(πθ;πref)=−E(x,yw,yl)∼D[lnσ(βlnπref(yw∣x)πθ(yw∣x)−βlnπref(yl∣x)πθ(yl∣x))]
L DPO ( π θ ; π ref ) 是 DPO 算法的损失函数,表示用于优化模型参数 θ 的目标函数。 \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) \text{是 DPO 算法的损失函数,表示用于优化模型参数} \theta \text{的目标函数。} LDPO(πθ;πref)是 DPO 算法的损失函数,表示用于优化模型参数θ的目标函数。
π θ 是当前要训练的模型,其参数为 θ ,用于生成文本。 \pi_\theta \text{是当前要训练的模型,其参数为} \theta \text{,用于生成文本。} πθ是当前要训练的模型,其参数为θ,用于生成文本。
π ref 是参考模型,即 π θ 的备份(不再更新),用于训练稳定 \pi_{\text{ref}} \text{是参考模型,即} \pi_\theta \text{的备份(不再更新),用于训练稳定} πref是参考模型,即πθ的备份(不再更新),用于训练稳定
D 是数据集,包含了输入 x 和对应的合理文本 y w 和不合理文本 y l 。 \mathcal{D} \text{是数据集,包含了输入} x \text{和对应的合理文本} y_w \text{和不合理文本}y_l\text{。} D是数据集,包含了输入x和对应的合理文本yw和不合理文本yl。
( x , y w , y l ) 是数据集中的一个样本,其中 x 是输入文本, y w 是生成的合理文本, y l 是生成的不合理文本。 (x, y_w, y_l) \text{是数据集中的一个样本,其中} x \text{是输入文本,} y_w \text{是生成的合理文本,} y_l \text{是生成的不合理文本。} (x,yw,yl)是数据集中的一个样本,其中x是输入文本,yw是生成的合理文本,yl是生成的不合理文本。
σ 是 sigmoid 函数,将输入值映射到 [ 0 , 1 ] 。 \sigma \text{是 sigmoid 函数,将输入值映射到} [0, 1]\text{。} σ是 sigmoid 函数,将输入值映射到[0,1]。
β 是一个超参数,用于控制损失函数中不合理文本相对于合理文本的权重。 \beta \text{是一个超参数,用于控制损失函数中不合理文本相对于合理文本的权重。} β是一个超参数,用于控制损失函数中不合理文本相对于合理文本的权重。
π θ ( y w ∣ x ) π ref ( y w ∣ x ) 确保生成的文本在一定程度上与参考模型保持一致,防止训练偏了。 \frac{\pi_\theta(y_w \mid x)}{\pi_{\text{ref}}(y_w \mid x)} \text{确保生成的文本在一定程度上与参考模型保持一致,防止训练偏了。} πref(yw∣x)πθ(yw∣x)确保生成的文本在一定程度上与参考模型保持一致,防止训练偏了。
对公式进一步推导:
L DPO ( π θ ; π ref ) = − E ∼ D [ log σ ( β log π θ ( y w ) π ref ( y w ) − β log π θ ( y l ) π ref ( y l ) ) ] = − E ∼ D [ log σ ( β ( log π θ ( y w ) π ref ( y w ) − log π θ ( y l ) π ref ( y l ) ) ) ] = − E ∼ D [ log σ ( β ( ( log π θ ( y w ) − log π ref ( y w ) ) − ( log π θ ( y l ) − log π ref ( y l ) ) ) ) ] = − E ∼ D [ log σ ( β ( ( log π θ ( y w ) − log π θ ( y l ) ) − ( log π ref ( y w ) − log π ref ( y l ) ) ) ) ] 其中 π ( y ) = π ( y ∣ x ) L_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{\sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w)}{\pi_{\text{ref}}(y_w)} - \beta \log \frac{\pi_\theta(y_l)}{\pi_{\text{ref}}(y_l)} \right) \right] \\ = -\mathbb{E}_{\sim \mathcal{D}} \left[ \log \sigma \left( \beta \left( \log \frac{\pi_\theta(y_w)}{\pi_{\text{ref}}(y_w)} - \log \frac{\pi_\theta(y_l)}{\pi_{\text{ref}}(y_l)} \right) \right) \right] \\ = -\mathbb{E}_{\sim \mathcal{D}} \left[ \log \sigma \left( \beta \left( (\log \pi_\theta(y_w) - \log \pi_{\text{ref}}(y_w)) - (\log \pi_\theta(y_l) - \log \pi_{\text{ref}}(y_l)) \right) \right) \right] \\ = -\mathbb{E}_{\sim \mathcal{D}} \left[ \log \sigma \left( \beta \left( (\log \pi_\theta(y_w) - \log \pi_\theta(y_l)) - (\log \pi_{\text{ref}}(y_w) - \log \pi_{\text{ref}}(y_l)) \right) \right) \right] \\ \text{其中 } \pi(y) = \pi(y \mid x) LDPO(πθ;πref)=−E∼D[logσ(βlogπref(yw)πθ(yw)−βlogπref(yl)πθ(yl))]=−E∼D[logσ(β(logπref(yw)πθ(yw)−logπref(yl)πθ(yl)))]=−E∼D[logσ(β((logπθ(yw)−logπref(yw))−(logπθ(yl)−logπref(yl))))]=−E∼D[logσ(β((logπθ(yw)−logπθ(yl))−(logπref(yw)−logπref(yl))))]其中 π(y)=π(y∣x)
其中
p i _ l o g r a t i o s = log ( π θ ( y w ) ) − log ( π θ ( y l ) ) r e f _ l o g r a t i o s = log ( π ref ( y w ) ) − log ( π ref ( y l ) ) pi\_logratios = \log(\pi_\theta(y_w)) - \log(\pi_\theta(y_l)) \\ ref\_logratios = \log(\pi_{\text{ref}}(y_w)) - \log(\pi_{\text{ref}}(y_l)) pi_logratios=log(πθ(yw))−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











