




什么是RAG
RAG(检索增强生成)是一种将语言模型与可搜索知识库结合的方法,主要包含以下关键步骤:
-
数据预处理
- 加载:从不同格式(PDF、Markdown等)中提取文本
- 分块:将长文本分割成短序列(通常100-500个标记),作为检索单元
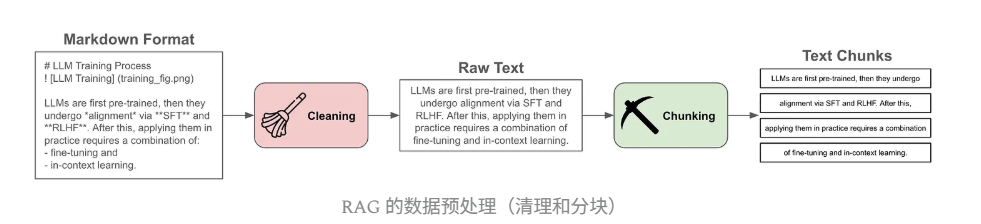
-
检索系统构建
- embedding:使用embedding模型为每个文本块生成向量表示
- 存储:将这些向量索引到向量数据库中
- 可选-重排:结合关键词搜索构建混合搜索系统,并添加重排序步骤
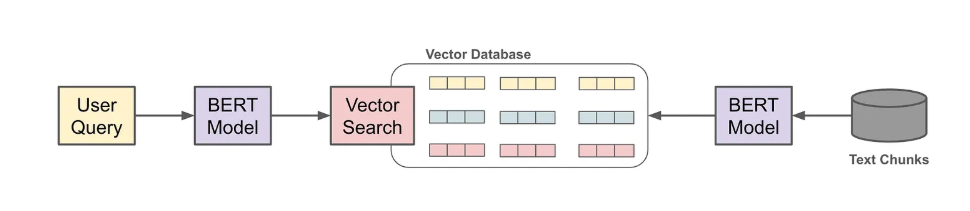
-
查询处理流程
- 接收用户查询并评估其相关性
- 对查询进行嵌入,在向量库中查找相关块
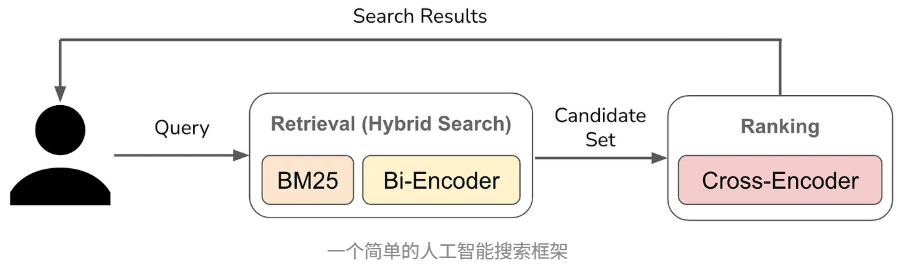
-
生成输出
- 将检索到的相关内容与原始查询一起传递给LLM
- LLM根据这些上下文信息生成更准确、更符合事实的回答
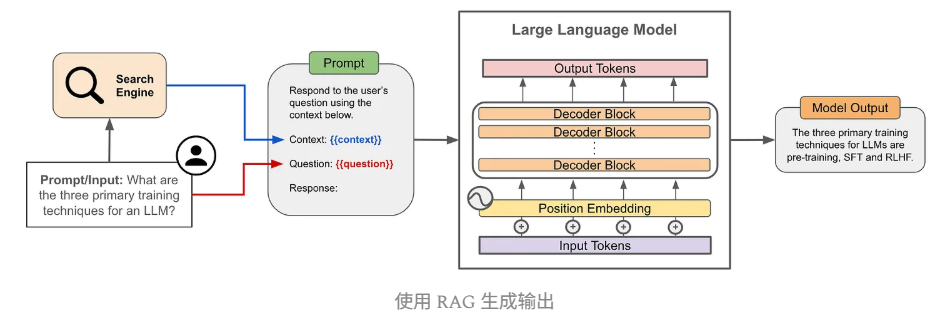



















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











