




引言
在我们的日常生活中,导航和定位已经成为不可或缺的一部分。例如,在商场里寻找某家餐厅,在停车场找到自己的车,或者在医院里快速找到某个科室,这些都依赖于室内定位技术。然而,GPS 在室内通常无法提供高精度的定位,这就需要使用“基于位置指纹(Location Fingerprinting)”的方法来进行室内定位。
本文将从最简单的 NN(最近邻)算法 开始,逐步讲解 KNN、WKNN 及其不同变体
1. NN(最近邻算法,Nearest Neighbor)
1.1 什么是 NN 算法?
NN(Nearest Neighbor,最近邻)是一种最简单的分类与回归算法。它的基本思想是:
-
在定位数据库中,存储每个参考点的 RSSI(接收信号强度指示值),并记录它们的实际位置。
-
当用户想要确定自己位置时,设备会测量当前的 RSSI 值。
-
通过计算当前 RSSI 值与数据库中的指纹数据的相似程度,找到最相似的那个参考点,并把它的坐标作为用户的当前位置。
1.2 在室内定位中的应用
假设你在商场里,你的手机能够接收到来自多个 WiFi 路由器的信号强度(RSSI)。NN 算法的流程如下:
-
你当前的 RSSI 数据:AP1: -50 dBm AP2: -60 dBm AP3: -55 dBm
-
数据库中某个参考点的 RSSI 数据:AP1: -49 dBm AP2: -59 dBm AP3: -56 dBm
-
计算二者的相似性后发现最接近,于是将该参考点的位置作为你的当前位置
2. KNN(K-近邻算法,K-Nearest Neighbors)
2.1 KNN 的基本思想
KNN(K-近邻算法)是一种基于监督学习的分类和回归算法,在室内定位中,KNN 主要用于 基于位置指纹(Fingerprinting)的定位方法。它通过比较实时测量到的信号特征(如 RSSI、CSI 等)与已构建的指纹数据库中的参考点数据,来确定用户当前的位置。
KNN 是 NN 的改进版本。与 NN 只选择最近的 1 个点 不同,KNN 选择 K 个最近的点,然后计算它们的平均位置 作为用户的位置。
2.2 KNN 在室内定位中的应用
-
计算用户当前 RSSI 值与数据库中所有参考点的相似性。
-
选择最接近的 K 个参考点。
-
计算这 K 个点的坐标平均值,作为最终的定位结果。
KNN 在室内定位中的流程如下:
-
构建指纹数据库
在室内环境中,预先采集多个参考点的信号特征(如 RSSI 值),并存储其对应的物理坐标 (x,y)(x, y)(x,y)。 -
实时信号测量
用户的设备(如手机、UWB 设备、WiFi 设备等)采集 当前时刻的信号信息,如 WiFi RSSI、蓝牙 RSSI、UWB 距离、CSI 等。 -
计算信号相似性
- 计算用户当前测量的信号特征与数据库中所有参考点之间的 欧几里得距离 或 余弦相似度。
- 欧几里得距离计算:
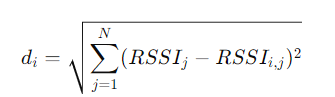 其中,RSSIj为用户当前测得的 RSSI 值,RSSIi,j为参考点 i 在 AP j 处的 RSSI 值。
其中,RSSIj为用户当前测得的 RSSI 值,RSSIi,j为参考点 i 在 AP j 处的 RSSI 值。 -
选择最近的 K 个参考点
按照计算出的距离对所有参考点进行排序,选择 K 个最近的参考点。 -
计算用户位置
取 K 个参考点的坐标平均值。
2.3 KNN 的优势
-
由于考虑了多个参考点,对信号波动的适应性更强。
-
计算简单,适用于大多数室内环境。
2.4 KNN 的缺点
-
计算量大:需要计算所有参考点的距离,然后排序选取 K 个最接近的点。
-
K 值选择困难:K 过小容易受噪声影响,K 过大可能会降低精度。
3. WKNN(加权 K 近邻算法,Weighted KNN)
为什么需要 WKNN?
KNN 算法在计算目标位置时,只是简单地取了 K 个参考点的平均值,没有考虑它们之间的距离差异。在实际场景中,离目标点更近的参考点应该起更大的作用,这就是 WKNN 提出的原因。
3.1 WKNN 的基本思想
在 KNN 算法中,K 个最近参考点的坐标是 等权平均 计算的:
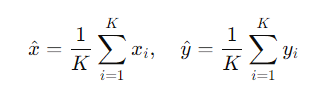
其中,wi 是第 i 个参考点的 权重,满足:
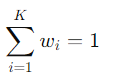
3.2 计算权重
反比权重(Inverse Distance Weight, IDW):
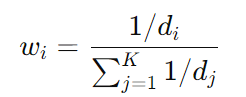
这种方法可以确保离用户较近的参考点 权重更大,远的点影响较小。
指数权重(Exponential Weight):
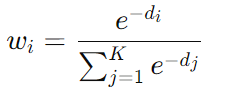
该方法可以进一步降低远距离点的影响,使得计算更加稳定。
3.3 WKNN 的优势
-
定位精度更高
相较于 KNN,WKNN 通过加权计算,使得更接近用户的参考点贡献更大,有效减少远距离参考点的影响,提高定位准确性。 -
鲁棒性更强
对 RSSI 波动、环境变化、噪声干扰 更加稳定。 -
适用于多种室内环境
可用于 WiFi、蓝牙、UWB、5G、CSI 等多种信号源的定位。
3.4 WKNN 的缺点
-
计算量比 KNN 略大
- 需要计算 权重,相较于 KNN 需要更多计算量。
- 但可以使用 KD-Tree 或 Ball-Tree 进行优化,提高查询速度。
-
权重函数选择复杂
- 线性加权、指数加权、距离倒数加权 等方式在不同环境下表现不同,需 实验调整。
4. WKNN 的变体
在 WKNN(加权 K 近邻算法)的基础上,不同研究者针对 不同的室内环境、信号特性、计算效率 进行了改进,提出了多种变体。这些变体主要在 距离计算方法、加权策略、环境适应性 等方面进行了优化,以提高定位精度。
4.1.1 SE-WKNN(标准欧几里得加权 KNN)
SE-WKNN 采用 欧几里得距离(Euclidean Distance) 计算用户与指纹数据库参考点的距离:
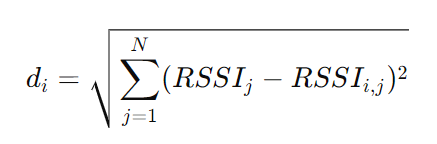
其中:
- RSSIj 是用户当前测得的 RSSI 值;
- RSSIi,j 是参考点 i 在第 j 个信号源的 RSSI 值。
K 近邻参考点的权重计算方式:

计算用户位置:
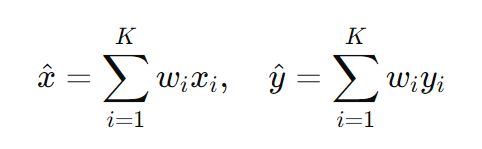
4.1.2 适用场景
- 信号传播均匀的环境,如 开放办公室、大型大厅、展览中心。
- 适用于 WiFi、蓝牙、UWB 等多种室内定位技术。
4.1.3 优势
✅ 计算简单,适用于大规模数据集。
✅ 适用于 信号传播较均匀的环境,定位误差较小。
✅ 在 无明显障碍物的开放环境 下表现较好。
4.1.4 缺点
❌ 对障碍物敏感,在有障碍物遮挡的环境下,误差可能较大。
❌ 欧几里得距离假设信号传播均匀,但在非均匀环境中,效果可能下降。
4.2.1 ED-WKNN(欧几里得距离加权 KNN)
ED-WKNN 采用欧几里得距离计算,但对距离进行 归一化处理,以适应不同信号衰减特性:
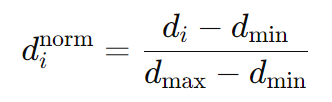
权重计算:
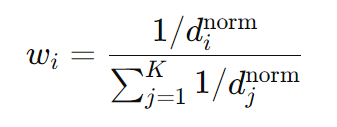
4.2.2 适用场景
- 较规则的环境,如 商场、超市、会议厅,信号传播相对均匀,但受 物品摆放、墙壁反射影响。
- 适用于 WiFi、蓝牙、UWB 定位,尤其是 RSSI 波动较大的环境。
4.2.3 优势
✅ 归一化处理可以 降低不同环境信号衰减对计算的影响。
✅ 在 复杂但规则的环境(如商场) 中,比 SE-WKNN 表现更稳定。
✅ 适用于信号衰减不同的多种场景。
4.2.4 缺点
❌ 计算比 SE-WKNN 略复杂,需要额外的归一化步骤。
❌ 在 非均匀信号环境(如障碍物较多的场景)下,可能需要调整参数。
4.3 MD-WKNN(曼哈顿距离加权 KNN)
MD-WKNN 采用 曼哈顿距离(Manhattan Distance) 计算用户与指纹数据库参考点的距离:
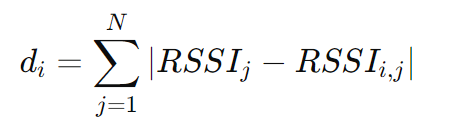
与欧几里得距离不同,曼哈顿距离 仅计算维度方向的绝对差值之和,不考虑对角方向的变化。
权重计算:
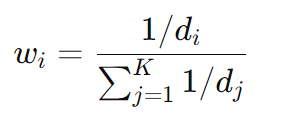
4.3.2 适用场景
- 走廊、网格化建筑、地铁站,即 路径主要沿 X/Y 轴方向延伸的场景。
- 适用于 BLE(蓝牙)、WiFi、RFID 定位,尤其适用于 狭长的通道环境。
4.3.3 优势
✅ 适用于网格化环境,如 医院、仓库、地铁站。
✅ 在 走廊类环境 下,误差比欧几里得距离更小。
✅ 计算更快,不需要平方和开方计算。
4.3.4 缺点
❌ 不适用于开放空间,因为曼哈顿距离无法很好地模拟斜向移动。
❌ 对障碍物仍然敏感,若信号传播路径复杂,误差可能较大。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









