



最近,DeepSeek凭借其先进的算法和卓越的能力迅速崛起,成为国内AI大模型领域的佼佼者,推动了国内AI技术的跨越式发展。作为一款现象级的AI产品,DeepSeek的用户量增长迅猛,其日活跃用户数已突破3000万。然而,随着用户量的激增,DeepSeek的服务器也面临着巨大的压力,甚至在近期遭受了大规模的网络攻击,导致服务频繁出现“服务器繁忙”的提示。
在这种情况下,将DeepSeek部署到本地电脑成为了一个理想的解决方案。本地部署不仅可以避免网络依赖,还能确保数据的安全性和隐私性。此外,本地部署的DeepSeek无需联网即可直接运行,能够提供更稳定、更高效的AI体验。
将DeepSeek部署在本地电脑
一、下载安装 Ollama
部署DeepSeek要用到 Ollama,它支持多种大模型。进入Ollama官网
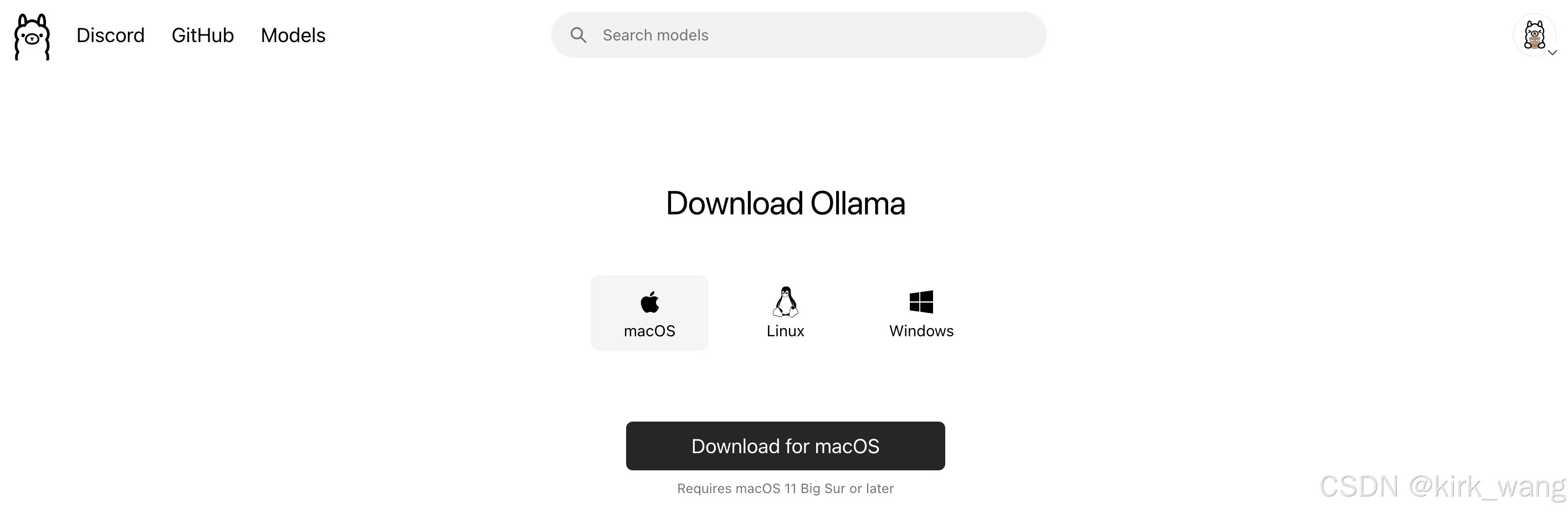
根据当前要部署的电脑类型选择对应的下载,当然有些小伙伴可能不方便下载,我也为大家准备好了安装包:Windows安装包、MAC安装包 我这里选择的是MAC版本,下载并安装好。
二、下载 DeepSeek-R1
1、进入Ollama官网,找到并选择Models。

2、进入就可以看到deepseek-r1模型,如果没有,在搜索栏搜索即可。
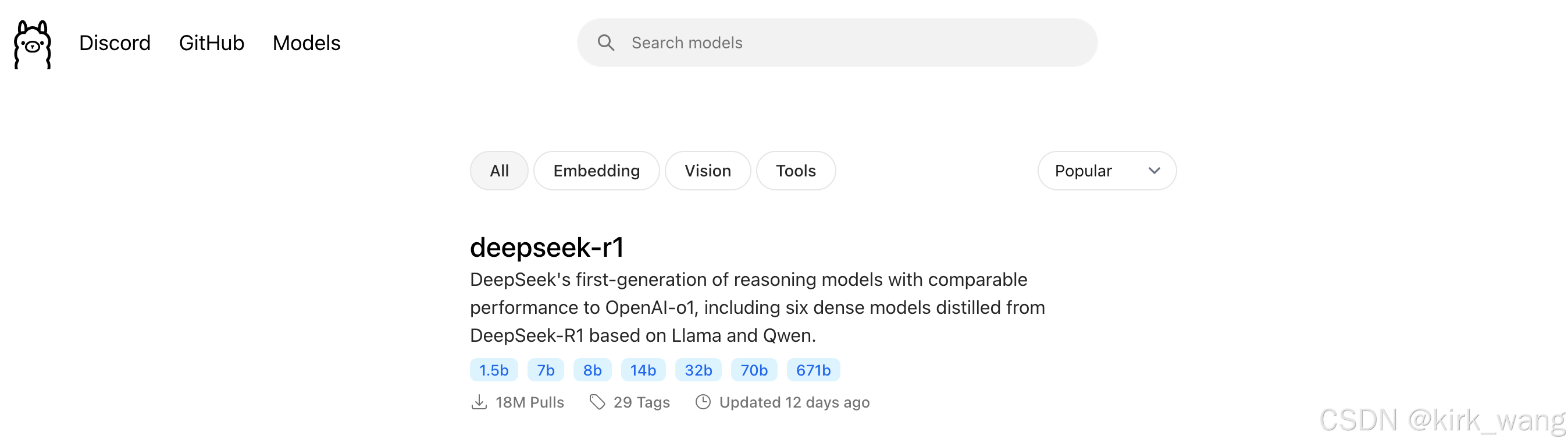
3、选择对应的模型来下载
1.5b、7b、8b、14b、32b、70b或671b,这里有很多版本可选,模型越大,要求电脑内存、显卡等的配置越高。
根据您的硬件配置(四核Intel Core i7 + 16GB内存),建议选择 DeepSeek-R1-7B,以下是具体分析:
4、硬件适配性对比
| 模型 | 最低内存需求(未量化) | 最低内存需求(4/8-bit量化) | CPU推理速度(参考) | 兼容性风险 |
|---|---|---|---|---|
| 7B | ~14-16GB | ~6-8GB | 较流畅(3-5词/秒) | 低 |
| 8B | ~18-20GB | ~9-12GB | 卡顿(1-3词/秒) | 高 |
-
内存瓶颈:
16GB物理内存中,系统占用约2-4GB,实际可用约12-14GB。-
7B模型:若使用量化(如
llama.cpp的4-bit量化),内存占用可压缩到8GB以内,剩余内存可支持轻量级应用。 -
8B模型:即使量化后仍需9-12GB,易触发内存交换(Swap),导致卡顿或崩溃。
-
-
CPU压力:
四核i7(无独立GPU)处理7B模型时,推理速度尚可接受(短文本生成约5-10秒),但8B模型负载更高,响应延迟可能翻倍。
5、性能实测参考
| 任务类型 | 7B模型(量化后) | 8B模型(量化后) |
|---|---|---|
| 短文本生成(<100字) | 3-5秒 | 6-10秒 |
| 长文本生成(500字) | 20-30秒 | 可能卡顿/崩溃 |
| 多轮对话 | 流畅 | 内存压力大 |
我这边电脑是四核intel Core i7 内存16G,所以选的7b的模型。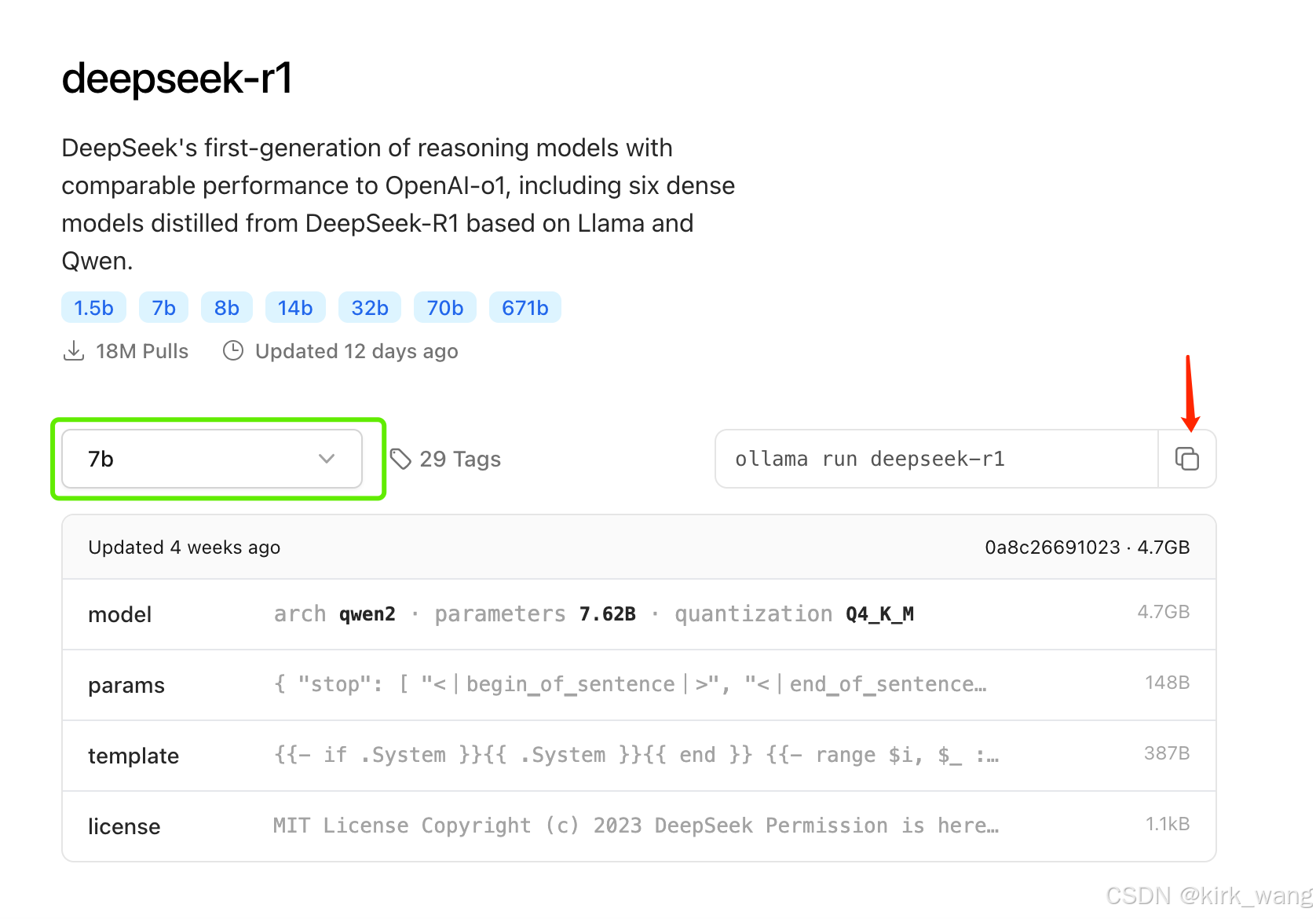
复制上边7b的代码,打开终端输入:ollama run deepseek-r1:7b
如果你的电脑提示下图,代表你没有安装好或者环境变量没配置,MAC电脑如果安装好环境变量是默认配置好的

出现下载等待窗口,等待下载完成,如下载完成后稍微等待,看到success,即部署完成。:
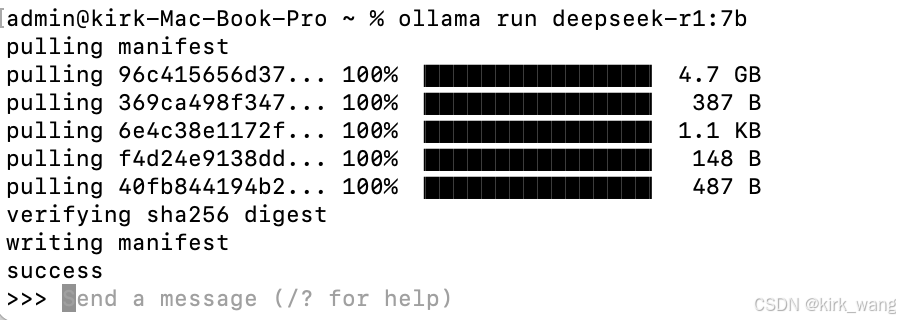
部署完成,send a message,输入内容即可开始对话。
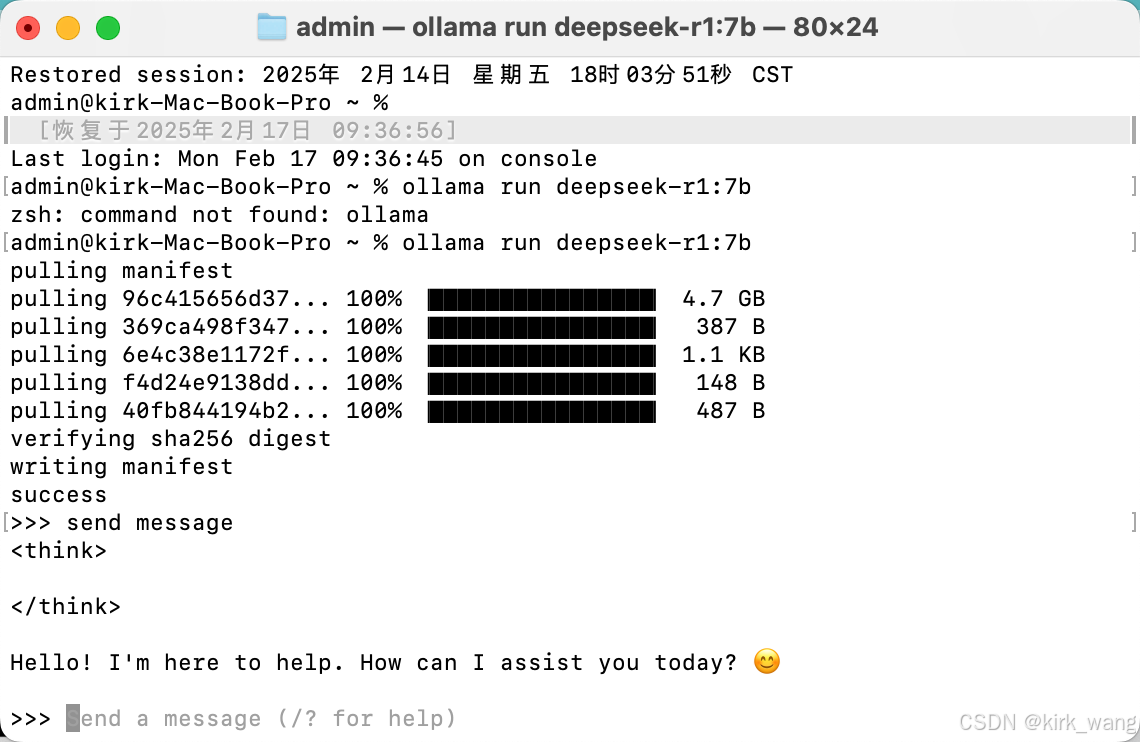
三、Chatbox前端搭建
通过第二步的操作,已经部署好DeepSeek,但每次使用都要在终端管理员里操作,相当繁琐。这里可以借助Chatbox,实现网页或客户端操作。
1、下载安装Chatbox
Chatbox官网:chatboxai.app/zh
进入官网下载安装Chatbox客户端,Chatbox安装包
2、点击设置,选择Ollama API
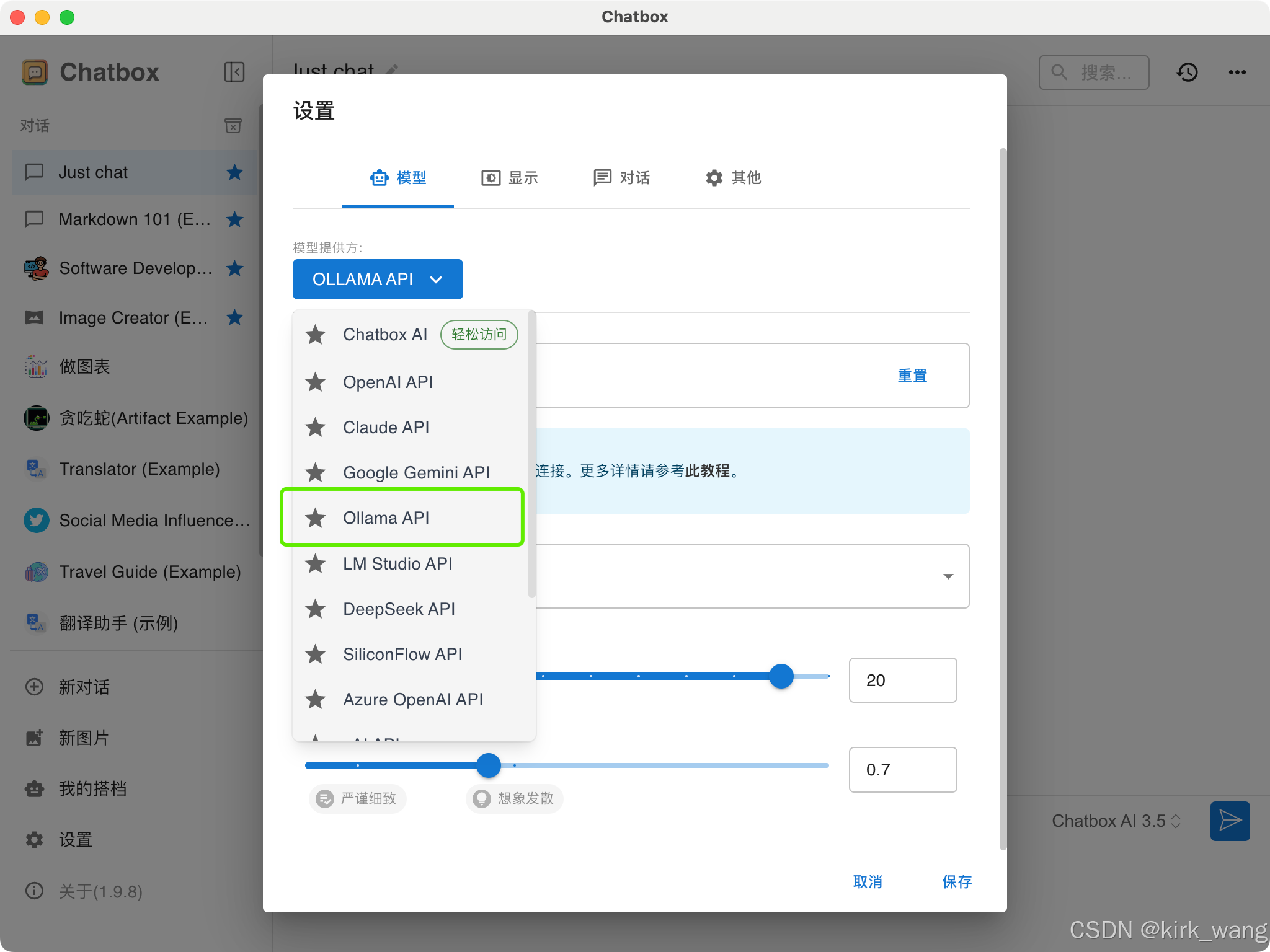
3、选择安装好的deepseek r1模型,保存即可
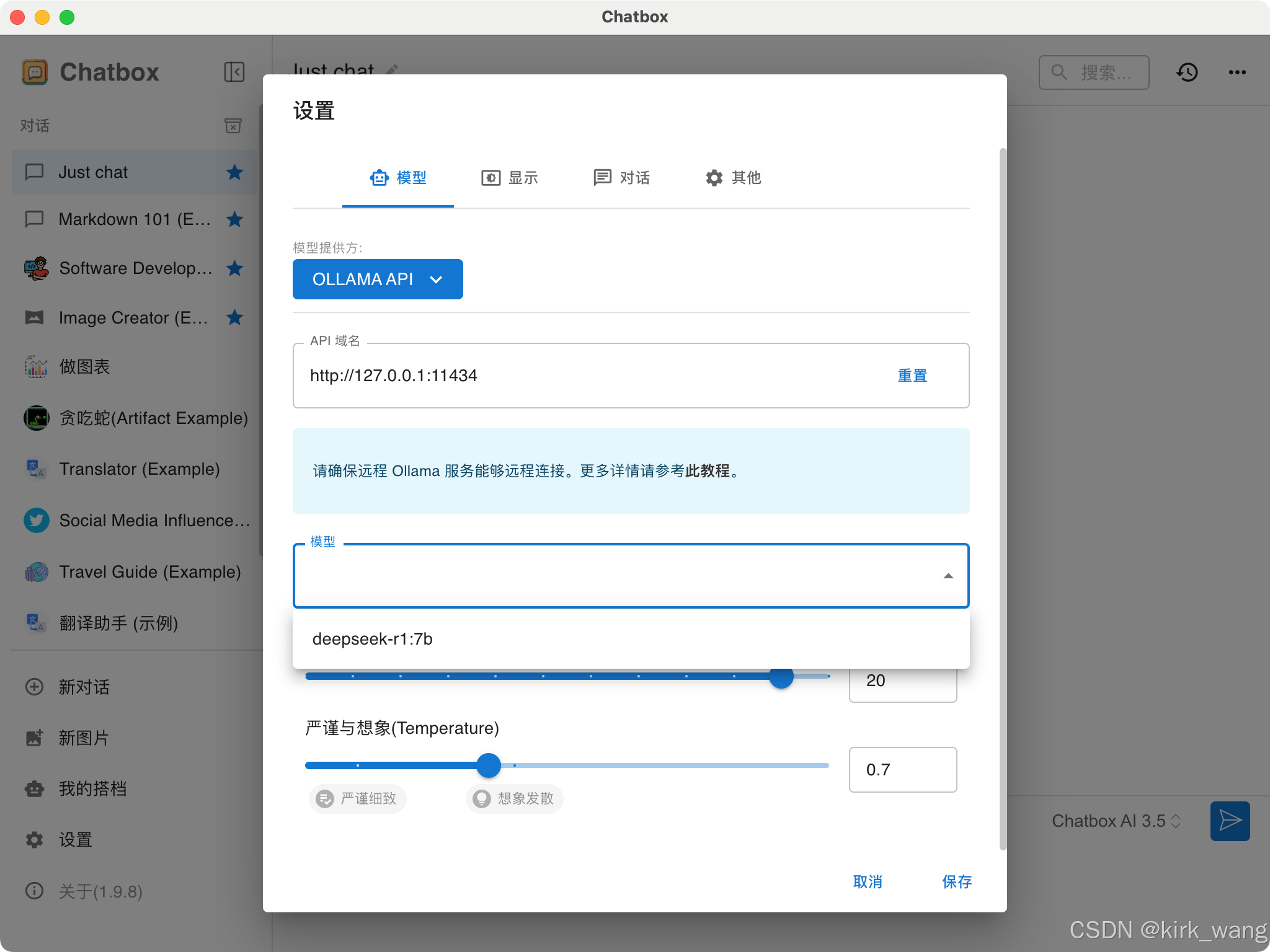
4、部署完成,就可以正常使用了。
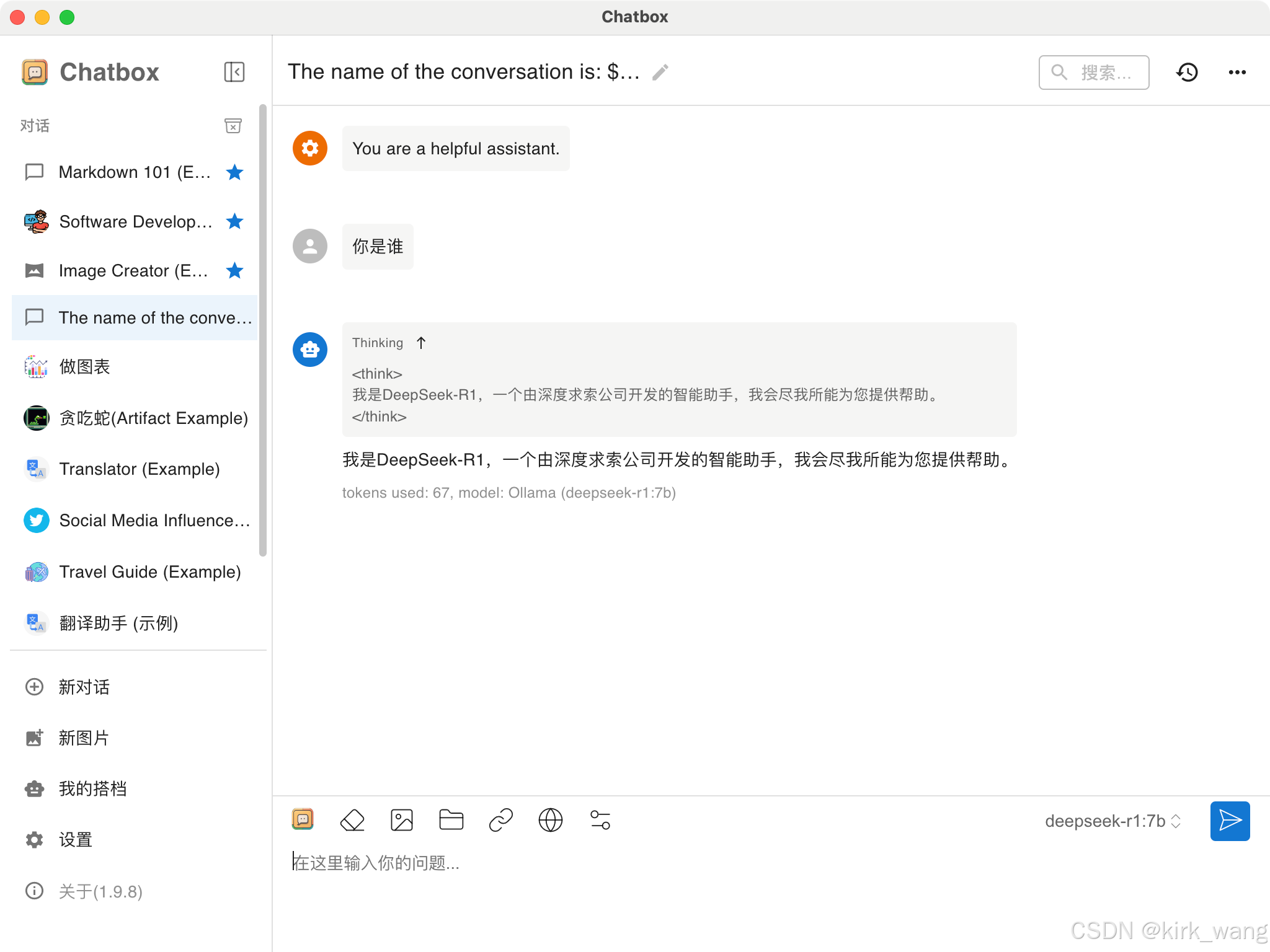
通过以上步骤,DeepSeek就部署在本地电脑上了,有些不方便公开的数据,比如实验数据,可以通过部署大模型到本地的方式进行处理,不用担心数据泄露。
总的来说,DeepSeek的本地部署为用户提供了更灵活、更安全的AI使用方式,尤其是在网络环境不稳定或数据隐私要求较高的场景下。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









