



目录
2001. 可互换矩形的组数
2003. 每棵子树内缺失的最小基因值
2005. 斐波那契树的移除子树游戏
2007. 从双倍数组中还原原数组
一个整数数组 original 可以转变成一个 双倍 数组 changed ,转变方式为将 original 中每个元素 值乘以 2 加入数组中,然后将所有元素 随机打乱 。
给你一个数组 changed ,如果 change 是 双倍 数组,那么请你返回 original数组,否则请返回空数组。original 的元素可以以 任意 顺序返回。
示例 1:
输入:changed = [1,3,4,2,6,8] 输出:[1,3,4] 解释:一个可能的 original 数组为 [1,3,4] : - 将 1 乘以 2 ,得到 1 * 2 = 2 。 - 将 3 乘以 2 ,得到 3 * 2 = 6 。 - 将 4 乘以 2 ,得到 4 * 2 = 8 。 其他可能的原数组方案为 [4,3,1] 或者 [3,1,4] 。
示例 2:
输入:changed = [6,3,0,1] 输出:[] 解释:changed 不是一个双倍数组。
示例 3:
输入:changed = [1] 输出:[] 解释:changed 不是一个双倍数组。
提示:
1 <= changed.length <= 1050 <= changed[i] <= 105
class Solution {
public:
vector<int> findOriginalArray(vector<int>& changed) {
sort(changed.begin(),changed.end());
queue<int>q;
vector<int>ans;
for(auto x:changed){
if(q.empty())q.push(x);
else{
int t=q.front();
if(x<t*2)q.push(x);
else if(x>t*2)return vector<int>{};
else ans.push_back(x/2),q.pop();
}
}
return q.empty()?ans:vector<int>{};
}
};2008. 出租车的最大盈利
2009. 使数组连续的最少操作数
2013. 检测正方形
2024. 考试的最大困扰度
2028. 找出缺失的观测数据
现有一份 n + m 次投掷单个 六面 骰子的观测数据,骰子的每个面从 1 到 6 编号。观测数据中缺失了 n 份,你手上只拿到剩余 m 次投掷的数据。幸好你有之前计算过的这 n + m 次投掷数据的 平均值 。
给你一个长度为 m 的整数数组 rolls ,其中 rolls[i] 是第 i 次观测的值。同时给你两个整数 mean 和 n 。
返回一个长度为 n 的数组,包含所有缺失的观测数据,且满足这 n + m 次投掷的 平均值 是 mean 。如果存在多组符合要求的答案,只需要返回其中任意一组即可。如果不存在答案,返回一个空数组。
k 个数字的 平均值 为这些数字求和后再除以 k 。
注意 mean 是一个整数,所以 n + m 次投掷的总和需要被 n + m 整除。
示例 1:
输入:rolls = [3,2,4,3], mean = 4, n = 2 输出:[6,6] 解释:所有 n + m 次投掷的平均值是 (3 + 2 + 4 + 3 + 6 + 6) / 6 = 4 。
示例 2:
输入:rolls = [1,5,6], mean = 3, n = 4 输出:[2,3,2,2] 解释:所有 n + m 次投掷的平均值是 (1 + 5 + 6 + 2 + 3 + 2 + 2) / 7 = 3 。
示例 3:
输入:rolls = [1,2,3,4], mean = 6, n = 4 输出:[] 解释:无论丢失的 4 次数据是什么,平均值都不可能是 6 。
示例 4:
输入:rolls = [1], mean = 3, n = 1 输出:[5] 解释:所有 n + m 次投掷的平均值是 (1 + 5) / 2 = 3 。
提示:
m == rolls.length1 <= n, m <= 1051 <= rolls[i], mean <= 6
class Solution {
public:
vector<int> missingRolls(vector<int>& rolls, int mean, int n) {
int s=mean*(n+rolls.size());
for(auto x:rolls)s-=x;
vector<int>v;
if(s<n||s>n*6)return v;
int a=(s-n-1)/5,b=n-1-a,c=s-a*6-b;
while(a--)v.push_back(6);
while(b--)v.push_back(1);
v.push_back(c);
return v;
}
};2029. 石子游戏 IX
2031. 1 比 0 多的子数组个数
2032. 至少在两个数组中出现的值
给你三个整数数组 nums1、nums2 和 nums3 ,请你构造并返回一个 元素各不相同的 数组,且由 至少 在 两个 数组中出现的所有值组成。数组中的元素可以按 任意 顺序排列。
示例 1:
输入:nums1 = [1,1,3,2], nums2 = [2,3], nums3 = [3]
输出:[3,2]
解释:至少在两个数组中出现的所有值为:
- 3 ,在全部三个数组中都出现过。
- 2 ,在数组 nums1 和 nums2 中出现过。
示例 2:
输入:nums1 = [3,1], nums2 = [2,3], nums3 = [1,2]
输出:[2,3,1]
解释:至少在两个数组中出现的所有值为:
- 2 ,在数组 nums2 和 nums3 中出现过。
- 3 ,在数组 nums1 和 nums2 中出现过。
- 1 ,在数组 nums1 和 nums3 中出现过。
示例 3:
输入:nums1 = [1,2,2], nums2 = [4,3,3], nums3 = [5]
输出:[]
解释:不存在至少在两个数组中出现的值。
提示:
1 <= nums1.length, nums2.length, nums3.length <= 100
1 <= nums1[i], nums2[j], nums3[k] <= 100
class Solution {
public:
vector<int> twoOutOfThree(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3) {
auto v1 = GetSameData(nums1, nums2);
auto v2 = GetSameData(nums1, nums3);
auto v3 = GetSameData(nums2, nums3);
v1 = GetInAnyData(v1, v2);
return GetInAnyData(v1, v3);
}
};2037. 使每位学生都有座位的最少移动次数
一个房间里有 n 个座位和 n 名学生,房间用一个数轴表示。给你一个长度为 n 的数组 seats ,其中 seats[i] 是第 i 个座位的位置。同时给你一个长度为 n 的数组 students ,其中 students[j] 是第 j 位学生的位置。
你可以执行以下操作任意次:
增加或者减少第 i 位学生的位置,每次变化量为 1 (也就是将第 i 位学生从位置 x 移动到 x + 1 或者 x - 1)
请你返回使所有学生都有座位坐的 最少移动次数 ,并确保没有两位学生的座位相同。
请注意,初始时有可能有多个座位或者多位学生在 同一 位置。
示例 1:
输入:seats = [3,1,5], students = [2,7,4]
输出:4
解释:学生移动方式如下:
- 第一位学生从位置 2 移动到位置 1 ,移动 1 次。
- 第二位学生从位置 7 移动到位置 5 ,移动 2 次。
- 第三位学生从位置 4 移动到位置 3 ,移动 1 次。
总共 1 + 2 + 1 = 4 次移动。
示例 2:
输入:seats = [4,1,5,9], students = [1,3,2,6]
输出:7
解释:学生移动方式如下:
- 第一位学生不移动。
- 第二位学生从位置 3 移动到位置 4 ,移动 1 次。
- 第三位学生从位置 2 移动到位置 5 ,移动 3 次。
- 第四位学生从位置 6 移动到位置 9 ,移动 3 次。
总共 0 + 1 + 3 + 3 = 7 次移动。
示例 3:
输入:seats = [2,2,6,6], students = [1,3,2,6]
输出:4
解释:学生移动方式如下:
- 第一位学生从位置 1 移动到位置 2 ,移动 1 次。
- 第二位学生从位置 3 移动到位置 6 ,移动 3 次。
- 第三位学生不移动。
- 第四位学生不移动。
总共 1 + 3 + 0 + 0 = 4 次移动。
提示:
n == seats.length == students.length
1 <= n <= 100
1 <= seats[i], students[j] <= 100
class Solution {
public:
int minMovesToSeat(vector<int>& v1, vector<int>& v2) {
sort(v1.begin(),v1.end());
sort(v2.begin(),v2.end());
int ans=0;
for(int i=0;i<v1.size();i++)ans+=abs(v1[i]-v2[i]);
return ans;
}
};2038. 如果相邻两个颜色均相同则删除当前颜色
2042. 检查句子中的数字是否递增
2048. 下一个更大的数值平衡数
如果整数 x 满足:对于每个数位 d ,这个数位 恰好 在 x 中出现 d 次。那么整数 x 就是一个 数值平衡数 。
给你一个整数 n ,请你返回 严格大于 n 的 最小数值平衡数 。
示例 1:
输入:n = 1 输出:22 解释: 22 是一个数值平衡数,因为: - 数字 2 出现 2 次 这也是严格大于 1 的最小数值平衡数。
示例 2:
输入:n = 1000 输出:1333 解释: 1333 是一个数值平衡数,因为: - 数字 1 出现 1 次。 - 数字 3 出现 3 次。 这也是严格大于 1000 的最小数值平衡数。 注意,1022 不能作为本输入的答案,因为数字 0 的出现次数超过了 0 。
示例 3:
输入:n = 3000 输出:3133 解释: 3133 是一个数值平衡数,因为: - 数字 1 出现 1 次。 - 数字 3 出现 3 次。 这也是严格大于 3000 的最小数值平衡数。
提示:
0 <= n <= 106
class Solution {
public:
int nextBeautifulNumber(int n) {
while (++n) {
vector<int>v(10);
int x = n;
while (x) {
v[x % 10]++;
x /= 10;
}
bool flag = true;
for (int i = 0; i < 10; i++)if (v[i]>0 && v[i] != i)flag = false;
if (flag)return n;
}
return 0;
}
};2063. 所有子字符串中的元音
2065. 最大化一张图中的路径价值
2073. 买票需要的时间
2079. 给植物浇水
你打算用一个水罐给花园里的 n 株植物浇水。植物排成一行,从左到右进行标记,编号从 0 到 n - 1 。其中,第 i 株植物的位置是 x = i 。x = -1 处有一条河,你可以在那里重新灌满你的水罐。
每一株植物都需要浇特定量的水。你将会按下面描述的方式完成浇水:
- 按从左到右的顺序给植物浇水。
- 在给当前植物浇完水之后,如果你没有足够的水 完全 浇灌下一株植物,那么你就需要返回河边重新装满水罐。
- 你 不能 提前重新灌满水罐。
最初,你在河边(也就是,x = -1),在 x 轴上每移动 一个单位 都需要 一步 。
给你一个下标从 0 开始的整数数组 plants ,数组由 n 个整数组成。其中,plants[i] 为第 i 株植物需要的水量。另有一个整数 capacity 表示水罐的容量,返回浇灌所有植物需要的 步数 。
示例 1:
输入:plants = [2,2,3,3], capacity = 5 输出:14 解释:从河边开始,此时水罐是装满的: - 走到植物 0 (1 步) ,浇水。水罐中还有 3 单位的水。 - 走到植物 1 (1 步) ,浇水。水罐中还有 1 单位的水。 - 由于不能完全浇灌植物 2 ,回到河边取水 (2 步)。 - 走到植物 2 (3 步) ,浇水。水罐中还有 2 单位的水。 - 由于不能完全浇灌植物 3 ,回到河边取水 (3 步)。 - 走到植物 3 (4 步) ,浇水。 需要的步数是 = 1 + 1 + 2 + 3 + 3 + 4 = 14 。
示例 2:
输入:plants = [1,1,1,4,2,3], capacity = 4 输出:30 解释:从河边开始,此时水罐是装满的: - 走到植物 0,1,2 (3 步) ,浇水。回到河边取水 (3 步)。 - 走到植物 3 (4 步) ,浇水。回到河边取水 (4 步)。 - 走到植物 4 (5 步) ,浇水。回到河边取水 (5 步)。 - 走到植物 5 (6 步) ,浇水。 需要的步数是 = 3 + 3 + 4 + 4 + 5 + 5 + 6 = 30 。
示例 3:
输入:plants = [7,7,7,7,7,7,7], capacity = 8 输出:49 解释:每次浇水都需要重新灌满水罐。 需要的步数是 = 1 + 1 + 2 + 2 + 3 + 3 + 4 + 4 + 5 + 5 + 6 + 6 + 7 = 49 。
提示:
n == plants.length1 <= n <= 10001 <= plants[i] <= 106max(plants[i]) <= capacity <= 109
class Solution {
public:
int wateringPlants(vector<int>& plants, int capacity) {
int ans=plants.size();
int s=capacity;
for(int i=0;i<plants.size();i++){
if(s<plants[i])ans+=i*2,s=capacity;
s-=plants[i];
}
return ans;
}
};2081. k 镜像数字的和
一个 k 镜像数字 指的是一个在十进制和 k 进制下从前往后读和从后往前读都一样的 没有前导 0 的 正 整数。
- 比方说,
9是一个 2 镜像数字。9在十进制下为9,二进制下为1001,两者从前往后读和从后往前读都一样。 - 相反地,
4不是一个 2 镜像数字。4在二进制下为100,从前往后和从后往前读不相同。
给你进制 k 和一个数字 n ,请你返回 k 镜像数字中 最小 的 n 个数 之和 。
示例 1:
输入:k = 2, n = 5
输出:25
解释:
最小的 5 个 2 镜像数字和它们的二进制表示如下:
十进制 二进制
1 1
3 11
5 101
7 111
9 1001
它们的和为 1 + 3 + 5 + 7 + 9 = 25 。
示例 2:
输入:k = 3, n = 7
输出:499
解释:
7 个最小的 3 镜像数字和它们的三进制表示如下:
十进制 三进制
1 1
2 2
4 11
8 22
121 11111
151 12121
212 21212
它们的和为 1 + 2 + 4 + 8 + 121 + 151 + 212 = 499 。
示例 3:
输入:k = 7, n = 17 输出:20379000 解释:17 个最小的 7 镜像数字分别为: 1, 2, 3, 4, 5, 6, 8, 121, 171, 242, 292, 16561, 65656, 2137312, 4602064, 6597956, 6958596
提示:
2 <= k <= 91 <= n <= 30
首先
bool check(long long n, int k)
{
vector<int>v;
while (n) {
v.push_back(n%k);
n /= k;
}
for (int i = 0, j = v.size() - 1; i <= j; i++, j--)if (v[i] != v[j])return false;
return true;
}
//获取k进制下,长为len的所有回文数
vector<long long> getPalindrome(int len, int k)
{
int halfLen = (len + 1) / 2;
int mi = 1;
for (int i = 0; i < halfLen; i++)mi *= k;
vector<long long>ans;
for (int i = mi / k; i < mi; i++) {
long long m = mi, n = i,s = 0;
while (n) {
m /= k;
s += n % k*m;
n /= k;
}
n = i;
if (len & 1)n /= k;
ans.push_back(n*mi + s);
}
return ans;
}
int main()
{
vector<vector<long long>>ans(10);
for (int len = 1; len <= 12; len++)
{
vector<long long>v = getPalindrome(len, 10);
for (auto x : v) {
for (int k = 2; k <= 9; k++) {
if(ans[k].size()<30 && check(x, k))ans[k].push_back(x);
}
}
}
for (int k = 2; k <= 9; k++) {
cout << "k=" << k << " num=" << ans[k].size() << endl;
for (auto x : ans[k])cout << x << ",";
cout << endl;
}
return 0;
}二次编码
class Solution {
public:
long long kMirror(int k, int n) {
vector<vector<long long>>v{ {1,3,5,7,9,33,99,313,585,717,7447,9009,15351,32223,39993,53235,53835,73737,585585,1758571,1934391,1979791,3129213,5071705,5259525,5841485,13500531,719848917,910373019,939474939},
{1,2,4,8,121,151,212,242,484,656,757,29092,48884,74647,75457,76267,92929,93739,848848,1521251,2985892,4022204,4219124,4251524,4287824,5737375,7875787,7949497,27711772,83155138},
{1,2,3,5,55,373,393,666,787,939,7997,53235,55255,55655,57675,506605,1801081,2215122,3826283,3866683,5051505,5226225,5259525,5297925,5614165,5679765,53822835,623010326,954656459,51717171715},
{1,2,3,4,6,88,252,282,626,676,1221,15751,18881,10088001,10400401,27711772,30322303,47633674,65977956,808656808,831333138,831868138,836131638,836181638,2512882152,2596886952,2893553982,6761551676,12114741121,12185058121},
{1,2,3,4,5,7,55,111,141,191,343,434,777,868,1441,7667,7777,22022,39893,74647,168861,808808,909909,1867681,3097903,4232324,4265624,4298924,4516154,4565654},
{1,2,3,4,5,6,8,121,171,242,292,16561,65656,2137312,4602064,6597956,6958596,9470749,61255216,230474032,466828664,485494584,638828836,657494756,858474858,25699499652,40130703104,45862226854,61454945416,64454545446},
{1,2,3,4,5,6,7,9,121,292,333,373,414,585,3663,8778,13131,13331,26462,26662,30103,30303,207702,628826,660066,1496941,1935391,1970791,4198914,55366355},
{1,2,3,4,5,6,7,8,191,282,373,464,555,646,656,6886,25752,27472,42324,50605,626626,1540451,1713171,1721271,1828281,1877781,1885881,2401042,2434342,2442442}
};
long long ans = 0;
for (int i = 0; i < n; i++)ans += v[k - 2][i];
return ans;
}
};2085. 统计出现过一次的公共字符串
给你两个字符串数组 words1 和 words2 ,请你返回在两个字符串数组中 都恰好出现一次 的字符串的数目。
示例 1:
输入:words1 = ["leetcode","is","amazing","as","is"], words2 = ["amazing","leetcode","is"] 输出:2 解释: - "leetcode" 在两个数组中都恰好出现一次,计入答案。 - "amazing" 在两个数组中都恰好出现一次,计入答案。 - "is" 在两个数组中都出现过,但在 words1 中出现了 2 次,不计入答案。 - "as" 在 words1 中出现了一次,但是在 words2 中没有出现过,不计入答案。 所以,有 2 个字符串在两个数组中都恰好出现了一次。
示例 2:
输入:words1 = ["b","bb","bbb"], words2 = ["a","aa","aaa"] 输出:0 解释:没有字符串在两个数组中都恰好出现一次。
示例 3:
输入:words1 = ["a","ab"], words2 = ["a","a","a","ab"] 输出:1 解释:唯一在两个数组中都出现一次的字符串是 "ab" 。
提示:
1 <= words1.length, words2.length <= 10001 <= words1[i].length, words2[j].length <= 30words1[i]和words2[j]都只包含小写英文字母。
class Solution {
public:
int countWords(vector<string>& words1, vector<string>& words2) {
map<string,int>m1,m2;
for(auto s:words1)m1[s]++;
for(auto s:words2)m2[s]++;
int ans=0;
for(auto mi:m1){
if(mi.second==1 && m2[mi.first]==1)ans++;
}
return ans;
}
};2097. 合法重新排列数对
2103. 环和杆
2105. 给植物浇水 II
Alice 和 Bob 打算给花园里的 n 株植物浇水。植物排成一行,从左到右进行标记,编号从 0 到 n - 1 。其中,第 i 株植物的位置是 x = i 。
每一株植物都需要浇特定量的水。Alice 和 Bob 每人有一个水罐,最初是满的 。他们按下面描述的方式完成浇水:
- Alice 按 从左到右 的顺序给植物浇水,从植物
0开始。Bob 按 从右到左 的顺序给植物浇水,从植物n - 1开始。他们 同时 给植物浇水。 - 如果没有足够的水 完全 浇灌下一株植物,他 / 她会立即重新灌满浇水罐。
- 不管植物需要多少水,浇水所耗费的时间都是一样的。
- 不能 提前重新灌满水罐。
- 每株植物都可以由 Alice 或者 Bob 来浇水。
- 如果 Alice 和 Bob 到达同一株植物,那么当前水罐中水更多的人会给这株植物浇水。如果他俩水量相同,那么 Alice 会给这株植物浇水。
给你一个下标从 0 开始的整数数组 plants ,数组由 n 个整数组成。其中,plants[i] 为第 i 株植物需要的水量。另有两个整数 capacityA 和 capacityB 分别表示 Alice 和 Bob 水罐的容量。返回两人浇灌所有植物过程中重新灌满水罐的 次数 。
示例 1:
输入:plants = [2,2,3,3], capacityA = 5, capacityB = 5 输出:1 解释: - 最初,Alice 和 Bob 的水罐中各有 5 单元水。 - Alice 给植物 0 浇水,Bob 给植物 3 浇水。 - Alice 和 Bob 现在分别剩下 3 单元和 2 单元水。 - Alice 有足够的水给植物 1 ,所以她直接浇水。Bob 的水不够给植物 2 ,所以他先重新装满水,再浇水。 所以,两人浇灌所有植物过程中重新灌满水罐的次数 = 0 + 0 + 1 + 0 = 1 。
示例 2:
输入:plants = [2,2,3,3], capacityA = 3, capacityB = 4 输出:2 解释: - 最初,Alice 的水罐中有 3 单元水,Bob 的水罐中有 4 单元水。 - Alice 给植物 0 浇水,Bob 给植物 3 浇水。 - Alice 和 Bob 现在都只有 1 单元水,并分别需要给植物 1 和植物 2 浇水。 - 由于他们的水量均不足以浇水,所以他们重新灌满水罐再进行浇水。 所以,两人浇灌所有植物过程中重新灌满水罐的次数 = 0 + 1 + 1 + 0 = 2 。
示例 3:
输入:plants = [5], capacityA = 10, capacityB = 8 输出:0 解释: - 只有一株植物 - Alice 的水罐有 10 单元水,Bob 的水罐有 8 单元水。因此 Alice 的水罐中水更多,她会给这株植物浇水。 所以,两人浇灌所有植物过程中重新灌满水罐的次数 = 0 。
提示:
n == plants.length1 <= n <= 1051 <= plants[i] <= 106max(plants[i]) <= capacityA, capacityB <= 109
class Solution {
public:
int minimumRefill(vector<int>& plants, int capacityA, int capacityB) {
int sa=capacityA,sb=capacityB,ans=0;
for(int i=0,j=plants.size()-1;i<=j;i++,j--){
if(i<j){
if(sa<plants[i])ans++,sa=capacityA;
sa-=plants[i];
if(sb<plants[j])ans++,sb=capacityB;
sb-=plants[j];
}else if(sa>=sb){
if(sa<plants[i])ans++;
}else{
if(sb<plants[j])ans++;
}
}
return ans;
}
};2127. 参加会议的最多员工数
2128. 通过翻转行或列来去除所有的 1
给你一个大小为 m x n 的二进制矩阵 grid。
每次操作,你可以选择 任意 一行 或者 一列,然后将其中的所有值翻转(0 变成 1, 1变成 0)。
如果经过 任意次 操作,你能将矩阵中所有的 1 去除,那么返回 true;否则返回 false。
示例 1:

输入: grid = [[0,1,0],[1,0,1],[0,1,0]] 输出: true 解释: 一种去除所有 1 的可行方法是: - 翻转矩阵的中间的行 - 翻转矩阵的中间的列
示例 2:

输入: grid = [[1,1,0],[0,0,0],[0,0,0]] 输出: false 解释: 不可能去除矩阵中所有的 1。
示例 3:

输入: grid = [[0]] 输出: true 解释: 矩阵中不存在 1,已经符合要求。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]是0或者1.
思路:
和点亮所有的灯差不多,首先理论推导,证明只要有解,那么就一定有一个解不需要把第一行整体翻转。
于是,根据第一行的数字可以求出所有的列操作,最后只需要校验经过这些列操作之后是不是所有的行都是纯0或者纯1即可。
class Solution {
public:
bool removeOnes(vector<vector<int>>& grid) {
for(int i=1;i<grid.size();i++){
int x=grid[i][0]^grid[0][0];
for(int j=0;j<grid[0].size();j++)
if(grid[i][j]^grid[0][j]^x)return false;
}
return true;
}
};2129. 将标题首字母大写
给你一个字符串 title ,它由单个空格连接一个或多个单词组成,每个单词都只包含英文字母。请你按以下规则将每个单词的首字母 大写 :
- 如果单词的长度为
1或者2,所有字母变成小写。 - 否则,将单词首字母大写,剩余字母变成小写。
请你返回 大写后 的 title 。
示例 1:
输入:title = "capiTalIze tHe titLe" 输出:"Capitalize The Title" 解释: 由于所有单词的长度都至少为 3 ,将每个单词首字母大写,剩余字母变为小写。
示例 2:
输入:title = "First leTTeR of EACH Word" 输出:"First Letter of Each Word" 解释: 单词 "of" 长度为 2 ,所以它保持完全小写。 其他单词长度都至少为 3 ,所以其他单词首字母大写,剩余字母小写。
示例 3:
输入:title = "i lOve leetcode" 输出:"i Love Leetcode" 解释: 单词 "i" 长度为 1 ,所以它保留小写。 其他单词长度都至少为 3 ,所以其他单词首字母大写,剩余字母小写。
提示:
1 <= title.length <= 100title由单个空格隔开的单词组成,且不含有任何前导或后缀空格。- 每个单词由大写和小写英文字母组成,且都是 非空 的。
class Solution {
public:
string capitalizeTitle(string title) {
auto v=StringSplit(title);
string ans;
for(auto s:v)ans+=change(s)+" ";
return ans.substr(0,ans.length()-1);
}
string change(string s){
for(auto &c:s){
if(c>='A'&&c<='Z')c=c-'A'+'a';
}
if(s.length()>=3){
s[0]=s[0]-'a'+'A';
}
return s;
}
};2136. 全部开花的最早一天
你有 n 枚花的种子。每枚种子必须先种下,才能开始生长、开花。播种需要时间,种子的生长也是如此。给你两个下标从 0 开始的整数数组 plantTime 和 growTime ,每个数组的长度都是 n :
plantTime[i]是 播种 第i枚种子所需的 完整天数 。每天,你只能为播种某一枚种子而劳作。无须 连续几天都在种同一枚种子,但是种子播种必须在你工作的天数达到plantTime[i]之后才算完成。growTime[i]是第i枚种子完全种下后生长所需的 完整天数 。在它生长的最后一天 之后 ,将会开花并且永远 绽放 。
从第 0 开始,你可以按 任意 顺序播种种子。
返回所有种子都开花的 最早 一天是第几天。
示例 1:

输入:plantTime = [1,4,3], growTime = [2,3,1] 输出:9 解释:灰色的花盆表示播种的日子,彩色的花盆表示生长的日子,花朵表示开花的日子。 一种最优方案是: 第 0 天,播种第 0 枚种子,种子生长 2 整天。并在第 3 天开花。 第 1、2、3、4 天,播种第 1 枚种子。种子生长 3 整天,并在第 8 天开花。 第 5、6、7 天,播种第 2 枚种子。种子生长 1 整天,并在第 9 天开花。 因此,在第 9 天,所有种子都开花。
示例 2:

输入:plantTime = [1,2,3,2], growTime = [2,1,2,1] 输出:9 解释:灰色的花盆表示播种的日子,彩色的花盆表示生长的日子,花朵表示开花的日子。 一种最优方案是: 第 1 天,播种第 0 枚种子,种子生长 2 整天。并在第 4 天开花。 第 0、3 天,播种第 1 枚种子。种子生长 1 整天,并在第 5 天开花。 第 2、4、5 天,播种第 2 枚种子。种子生长 2 整天,并在第 8 天开花。 第 6、7 天,播种第 3 枚种子。种子生长 1 整天,并在第 9 天开花。 因此,在第 9 天,所有种子都开花。
示例 3:
输入:plantTime = [1], growTime = [1] 输出:2 解释:第 0 天,播种第 0 枚种子。种子需要生长 1 整天,然后在第 2 天开花。 因此,在第 2 天,所有种子都开花。
提示:
n == plantTime.length == growTime.length1 <= n <= 1051 <= plantTime[i], growTime[i] <= 104
class Solution {
public:
int earliestFullBloom(vector<int>& plantTime, vector<int>& growTime) {
auto ids = SortId(growTime);
int s = 0, ans = 0;
for (int i = ids.size() - 1; i >= 0; i--) {
int id = ids[i];
s += plantTime[id];
ans = max(ans, s + growTime[id]);
}
return ans;
}
};2140. 解决智力问题
2168. 每个数字的频率都相同的独特子字符串的数量
给你一个由数字组成的字符串 s,返回 s 中独特子字符串数量,其中的每一个数字出现的频率都相同。
示例1:
输入: s = "1212" 输出: 5 解释: 符合要求的子串有 "1", "2", "12", "21", "1212". 要注意,尽管"12"在s中出现了两次,但在计数的时候只计算一次。
示例 2:
输入: s = "12321" 输出: 9 解释: 符合要求的子串有 "1", "2", "3", "12", "23", "32", "21", "123", "321".
解释:
1 <= s.length <= 1000s只包含阿拉伯数字.
class Solution {
public:
int equalDigitFrequency(string s) {
set<string>ss;
for(int i=0;i<s.length();i++){
map<char,int>m;
int maxs=0;
string t;
for(int j=i;j<s.length();j++){
maxs=max(maxs,++m[s[j]]);
t+=s[j];
if(maxs*m.size()==j-i+1)ss.insert(t);
}
}
return ss.size();
}
};2171. 拿出最少数目的魔法豆
给定一个 正整数 数组 beans ,其中每个整数表示一个袋子里装的魔法豆的数目。
请你从每个袋子中 拿出 一些豆子(也可以 不拿出),使得剩下的 非空 袋子中(即 至少还有一颗 魔法豆的袋子)魔法豆的数目 相等。一旦把魔法豆从袋子中取出,你不能再将它放到任何袋子中。
请返回你需要拿出魔法豆的 最少数目。
示例 1:
输入:beans = [4,1,6,5] 输出:4 解释: - 我们从有 1 个魔法豆的袋子中拿出 1 颗魔法豆。 剩下袋子中魔法豆的数目为:[4,0,6,5] - 然后我们从有 6 个魔法豆的袋子中拿出 2 个魔法豆。 剩下袋子中魔法豆的数目为:[4,0,4,5] - 然后我们从有 5 个魔法豆的袋子中拿出 1 个魔法豆。 剩下袋子中魔法豆的数目为:[4,0,4,4] 总共拿出了 1 + 2 + 1 = 4 个魔法豆,剩下非空袋子中魔法豆的数目相等。 没有比取出 4 个魔法豆更少的方案。
示例 2:
输入:beans = [2,10,3,2] 输出:7 解释: - 我们从有 2 个魔法豆的其中一个袋子中拿出 2 个魔法豆。 剩下袋子中魔法豆的数目为:[0,10,3,2] - 然后我们从另一个有 2 个魔法豆的袋子中拿出 2 个魔法豆。 剩下袋子中魔法豆的数目为:[0,10,3,0] - 然后我们从有 3 个魔法豆的袋子中拿出 3 个魔法豆。 剩下袋子中魔法豆的数目为:[0,10,0,0] 总共拿出了 2 + 2 + 3 = 7 个魔法豆,剩下非空袋子中魔法豆的数目相等。 没有比取出 7 个魔法豆更少的方案。
提示:
1 <= beans.length <= 1051 <= beans[i] <= 105
class Solution {
public:
long long minimumRemoval(vector<int>& beans) {
sort(beans.begin(),beans.end());
long long s=0;
for(auto x:beans)s+=x;
long long ans=s;
for(int i=0;i<beans.size();i++){
ans=min(ans,s-beans[i]*(long long)(beans.size()-i));
}
return ans;
}
};2178. 拆分成最多数目的正偶数之和
给你一个整数 finalSum 。请你将它拆分成若干个 互不相同 的正偶数之和,且拆分出来的正偶数数目 最多 。
- 比方说,给你
finalSum = 12,那么这些拆分是 符合要求 的(互不相同的正偶数且和为finalSum):(2 + 10),(2 + 4 + 6)和(4 + 8)。它们中,(2 + 4 + 6)包含最多数目的整数。注意finalSum不能拆分成(2 + 2 + 4 + 4),因为拆分出来的整数必须互不相同。
请你返回一个整数数组,表示将整数拆分成 最多 数目的正偶数数组。如果没有办法将 finalSum 进行拆分,请你返回一个 空 数组。你可以按 任意 顺序返回这些整数。
示例 1:
输入:finalSum = 12 输出:[2,4,6] 解释:以下是一些符合要求的拆分:(2 + 10),(2 + 4 + 6)和(4 + 8) 。(2 + 4 + 6) 为最多数目的整数,数目为 3 ,所以我们返回 [2,4,6] 。 [2,6,4] ,[6,2,4] 等等也都是可行的解。
示例 2:
输入:finalSum = 7 输出:[] 解释:没有办法将 finalSum 进行拆分。 所以返回空数组。
示例 3:
输入:finalSum = 28 输出:[6,8,2,12] 解释:以下是一些符合要求的拆分:(2 + 26),(6 + 8 + 2 + 12)和(4 + 24) 。(6 + 8 + 2 + 12)有最多数目的整数,数目为 4 ,所以我们返回 [6,8,2,12] 。 [10,2,4,12] ,[6,2,4,16] 等等也都是可行的解。
提示:
1 <= finalSum <= 1010
class Solution {
public:
vector<long long> maximumEvenSplit(long long finalSum) {
vector<long long>ans;
if(finalSum&1)return ans;
finalSum>>=1;
for(int i=1;i<123456789;i++){
if(finalSum>=i*2+1)ans.push_back(i<<1),finalSum-=i;
else break;
}
ans.push_back(finalSum<<1);
return ans;
}
};2180. 统计各位数字之和为偶数的整数个数
2182. 构造限制重复的字符串
给你一个字符串 s 和一个整数 repeatLimit ,用 s 中的字符构造一个新字符串 repeatLimitedString ,使任何字母 连续 出现的次数都不超过 repeatLimit 次。你不必使用 s 中的全部字符。
返回 字典序最大的 repeatLimitedString 。
如果在字符串 a 和 b 不同的第一个位置,字符串 a 中的字母在字母表中出现时间比字符串 b 对应的字母晚,则认为字符串 a 比字符串 b 字典序更大 。如果字符串中前 min(a.length, b.length) 个字符都相同,那么较长的字符串字典序更大。
示例 1:
输入:s = "cczazcc", repeatLimit = 3 输出:"zzcccac" 解释:使用 s 中的所有字符来构造 repeatLimitedString "zzcccac"。 字母 'a' 连续出现至多 1 次。 字母 'c' 连续出现至多 3 次。 字母 'z' 连续出现至多 2 次。 因此,没有字母连续出现超过 repeatLimit 次,字符串是一个有效的 repeatLimitedString 。 该字符串是字典序最大的 repeatLimitedString ,所以返回 "zzcccac" 。 注意,尽管 "zzcccca" 字典序更大,但字母 'c' 连续出现超过 3 次,所以它不是一个有效的 repeatLimitedString 。
示例 2:
输入:s = "aababab", repeatLimit = 2 输出:"bbabaa" 解释: 使用 s 中的一些字符来构造 repeatLimitedString "bbabaa"。 字母 'a' 连续出现至多 2 次。 字母 'b' 连续出现至多 2 次。 因此,没有字母连续出现超过 repeatLimit 次,字符串是一个有效的 repeatLimitedString 。 该字符串是字典序最大的 repeatLimitedString ,所以返回 "bbabaa" 。 注意,尽管 "bbabaaa" 字典序更大,但字母 'a' 连续出现超过 2 次,所以它不是一个有效的 repeatLimitedString 。
提示:
1 <= repeatLimit <= s.length <= 105s由小写英文字母组成
class Solution {
public:
string repeatLimitedString(string s, int repeatLimit) {
map<char,int>m;
for(auto c:s)m[c]++;
string ans="";
char c=0;
while(!m.empty()){
auto it = m.rbegin();
if(it->first==c){
if(++it == m.rend())break;
c=it->first;
ans+=c;
if(--it->second == 0)m.erase(it->first);
}else{
c=it->first;
int num = min(m[c],repeatLimit);
m[c]-=num;
if(m[c] == 0)m.erase(c);
while(num--)ans+=c;
}
}
return ans;
}
};2183. 统计可以被 K 整除的下标对数目
2185. 统计包含给定前缀的字符串
2192. 有向无环图中一个节点的所有祖先
2197. 替换数组中的非互质数
2216. 美化数组的最少删除数
给你一个下标从 0 开始的整数数组 nums ,如果满足下述条件,则认为数组 nums 是一个 美丽数组 :
nums.length为偶数- 对所有满足
i % 2 == 0的下标i,nums[i] != nums[i + 1]均成立
注意,空数组同样认为是美丽数组。
你可以从 nums 中删除任意数量的元素。当你删除一个元素时,被删除元素右侧的所有元素将会向左移动一个单位以填补空缺,而左侧的元素将会保持 不变 。
返回使 nums 变为美丽数组所需删除的 最少 元素数目。
示例 1:
输入:nums = [1,1,2,3,5] 输出:1 解释:可以删除nums[0]或nums[1],这样得到的nums= [1,2,3,5] 是一个美丽数组。可以证明,要想使 nums 变为美丽数组,至少需要删除 1 个元素。
示例 2:
输入:nums = [1,1,2,2,3,3] 输出:2 解释:可以删除nums[0]和nums[5],这样得到的 nums = [1,2,2,3] 是一个美丽数组。可以证明,要想使 nums 变为美丽数组,至少需要删除 2 个元素。
提示:
1 <= nums.length <= 1050 <= nums[i] <= 105
class Solution {
public:
int minDeletion(vector<int>& nums) {
int preNum = 0;
for (int i = 0; i < nums.size(); i++) {
if (preNum % 2 == 0 || nums[i] != nums[i - 1])preNum++;
}
return nums.size() - (preNum - preNum % 2);
}
};2218. 从栈中取出 K 个硬币的最大面值和
2221. 数组的三角和
2225. 找出输掉零场或一场比赛的玩家
给你一个整数数组 matches 其中 matches[i] = [winneri, loseri] 表示在一场比赛中 winneri 击败了 loseri 。
返回一个长度为 2 的列表 answer :
answer[0]是所有 没有 输掉任何比赛的玩家列表。answer[1]是所有恰好输掉 一场 比赛的玩家列表。
两个列表中的值都应该按 递增 顺序返回。
注意:
- 只考虑那些参与 至少一场 比赛的玩家。
- 生成的测试用例保证 不存在 两场比赛结果 相同 。
示例 1:
输入:matches = [[1,3],[2,3],[3,6],[5,6],[5,7],[4,5],[4,8],[4,9],[10,4],[10,9]] 输出:[[1,2,10],[4,5,7,8]] 解释: 玩家 1、2 和 10 都没有输掉任何比赛。 玩家 4、5、7 和 8 每个都输掉一场比赛。 玩家 3、6 和 9 每个都输掉两场比赛。 因此,answer[0] = [1,2,10] 和 answer[1] = [4,5,7,8] 。
示例 2:
输入:matches = [[2,3],[1,3],[5,4],[6,4]] 输出:[[1,2,5,6],[]] 解释: 玩家 1、2、5 和 6 都没有输掉任何比赛。 玩家 3 和 4 每个都输掉两场比赛。 因此,answer[0] = [1,2,5,6] 和 answer[1] = [] 。
提示:
1 <= matches.length <= 105matches[i].length == 21 <= winneri, loseri <= 105winneri != loseri- 所有
matches[i]互不相同
class Solution {
public:
vector<vector<int>> findWinners(vector<vector<int>>& matches) {
map<int,int>m;
for(auto v:matches)m[v[0]],m[v[1]]++;
vector<vector<int>>ans(2);
for(auto mi:m){
if(mi.second<2)ans[mi.second].push_back(mi.first);
}
return ans;
}
};2235. 两整数相加
2236. 判断根结点是否等于子结点之和
给你一个 二叉树 的根结点 root,该二叉树由恰好 3 个结点组成:根结点、左子结点和右子结点。
如果根结点值等于两个子结点值之和,返回 true ,否则返回 false 。
示例 1:

输入:root = [10,4,6] 输出:true 解释:根结点、左子结点和右子结点的值分别是 10 、4 和 6 。 由于 10 等于 4 + 6 ,因此返回 true 。
示例 2:

输入:root = [5,3,1] 输出:false 解释:根结点、左子结点和右子结点的值分别是 5 、3 和 1 。 由于 5 不等于 3 + 1 ,因此返回 false 。
提示:
- 树只包含根结点、左子结点和右子结点
-100 <= Node.val <= 100
class Solution {
public:
bool checkTree(TreeNode* root) {
return root->val==root->left->val+root->right->val;
}
};2239. 找到最接近 0 的数字
给你一个长度为 n 的整数数组 nums ,请你返回 nums 中最 接近 0 的数字。如果有多个答案,请你返回它们中的 最大值 。
示例 1:
输入:nums = [-4,-2,1,4,8] 输出:1 解释: -4 到 0 的距离为 |-4| = 4 。 -2 到 0 的距离为 |-2| = 2 。 1 到 0 的距离为 |1| = 1 。 4 到 0 的距离为 |4| = 4 。 8 到 0 的距离为 |8| = 8 。 所以,数组中距离 0 最近的数字为 1 。
示例 2:
输入:nums = [2,-1,1] 输出:1 解释:1 和 -1 都是距离 0 最近的数字,所以返回较大值 1 。
提示:
1 <= n <= 1000-105 <= nums[i] <= 105
class Solution {
public:
int findClosestNumber(vector<int>& nums) {
int ans =123456;
for(auto x:nums){
if(abs(ans)>abs(x))ans=x;
if(abs(ans)==abs(x) && x>0)ans=x;
}
return ans;
}
};2244. 完成所有任务需要的最少轮数
2250. 统计包含每个点的矩形数目
2264. 字符串中最大的 3 位相同数字
给你一个字符串 num ,表示一个大整数。如果一个整数满足下述所有条件,则认为该整数是一个 优质整数 :
- 该整数是
num的一个长度为3的 子字符串 。 - 该整数由唯一一个数字重复
3次组成。
以字符串形式返回 最大的优质整数 。如果不存在满足要求的整数,则返回一个空字符串 "" 。
注意:
- 子字符串 是字符串中的一个连续字符序列。
num或优质整数中可能存在 前导零 。
示例 1:
输入:num = "6777133339" 输出:"777" 解释:num 中存在两个优质整数:"777" 和 "333" 。 "777" 是最大的那个,所以返回 "777" 。
示例 2:
输入:num = "2300019" 输出:"000" 解释:"000" 是唯一一个优质整数。
示例 3:
输入:num = "42352338" 输出:"" 解释:不存在长度为 3 且仅由一个唯一数字组成的整数。因此,不存在优质整数。
提示:
3 <= num.length <= 1000num仅由数字(0-9)组成
class Solution {
public:
string largestGoodInteger(string num) {
for (char c = '9'; c >= '0'; c--) {
string s;
s += c;
s += c;
s += c;
if (num.find(s.c_str()) != std::string::npos)return s;
}
return "";
}
};2270. 分割数组的方案数
给你一个下标从 0 开始长度为 n 的整数数组 nums 。
如果以下描述为真,那么 nums 在下标 i 处有一个 合法的分割 :
- 前
i + 1个元素的和 大于等于 剩下的n - i - 1个元素的和。 - 下标
i的右边 至少有一个 元素,也就是说下标i满足0 <= i < n - 1。
请你返回 nums 中的 合法分割 方案数。
示例 1:
输入:nums = [10,4,-8,7] 输出:2 解释: 总共有 3 种不同的方案可以将 nums 分割成两个非空的部分: - 在下标 0 处分割 nums 。那么第一部分为 [10] ,和为 10 。第二部分为 [4,-8,7] ,和为 3 。因为 10 >= 3 ,所以 i = 0 是一个合法的分割。 - 在下标 1 处分割 nums 。那么第一部分为 [10,4] ,和为 14 。第二部分为 [-8,7] ,和为 -1 。因为 14 >= -1 ,所以 i = 1 是一个合法的分割。 - 在下标 2 处分割 nums 。那么第一部分为 [10,4,-8] ,和为 6 。第二部分为 [7] ,和为 7 。因为 6 < 7 ,所以 i = 2 不是一个合法的分割。 所以 nums 中总共合法分割方案受为 2 。
示例 2:
输入:nums = [2,3,1,0] 输出:2 解释: 总共有 2 种 nums 的合法分割: - 在下标 1 处分割 nums 。那么第一部分为 [2,3] ,和为 5 。第二部分为 [1,0] ,和为 1 。因为 5 >= 1 ,所以 i = 1 是一个合法的分割。 - 在下标 2 处分割 nums 。那么第一部分为 [2,3,1] ,和为 6 。第二部分为 [0] ,和为 0 。因为 6 >= 0 ,所以 i = 2 是一个合法的分割。
提示:
2 <= nums.length <= 105-105 <= nums[i] <= 105
class Solution {
public:
int waysToSplitArray(vector<int>& nums) {
int ans = 0;
long long s = 0;
for (auto x : nums)s += x;
s = -(s + (s > 0)) / 2;
for (auto x : nums) {
s += x;
if (s >= 0)ans++;
}
if (s >= 0)ans--;
return ans;
}
};2274. 不含特殊楼层的最大连续楼层数
Alice 管理着一家公司,并租用大楼的部分楼层作为办公空间。Alice 决定将一些楼层作为 特殊楼层 ,仅用于放松。
给你两个整数 bottom 和 top ,表示 Alice 租用了从 bottom 到 top(含 bottom 和 top 在内)的所有楼层。另给你一个整数数组 special ,其中 special[i] 表示 Alice 指定用于放松的特殊楼层。
返回不含特殊楼层的 最大 连续楼层数。
示例 1:
输入:bottom = 2, top = 9, special = [4,6] 输出:3 解释:下面列出的是不含特殊楼层的连续楼层范围: - (2, 3) ,楼层数为 2 。 - (5, 5) ,楼层数为 1 。 - (7, 9) ,楼层数为 3 。 因此,返回最大连续楼层数 3 。
示例 2:
输入:bottom = 6, top = 8, special = [7,6,8] 输出:0 解释:每层楼都被规划为特殊楼层,所以返回 0 。
提示
1 <= special.length <= 1051 <= bottom <= special[i] <= top <= 109special中的所有值 互不相同
class Solution {
public:
int maxConsecutive(int bottom, int top, vector<int>& special) {
special.push_back(bottom-1);
special.push_back(top+1);
sort(special.begin(),special.end());
int ans=0;
for(int i=1;i<special.size();i++)ans=max(ans,special[i]-special[i-1]);
return ans-1;
}
};2276. 统计区间中的整数数目
给你区间的 空 集,请你设计并实现满足要求的数据结构:
- 新增:添加一个区间到这个区间集合中。
- 统计:计算出现在 至少一个 区间中的整数个数。
实现 CountIntervals 类:
CountIntervals()使用区间的空集初始化对象void add(int left, int right)添加区间[left, right]到区间集合之中。int count()返回出现在 至少一个 区间中的整数个数。
注意:区间 [left, right] 表示满足 left <= x <= right 的所有整数 x 。
示例 1:
输入
["CountIntervals", "add", "add", "count", "add", "count"]
[[], [2, 3], [7, 10], [], [5, 8], []]
输出
[null, null, null, 6, null, 8]
解释
CountIntervals countIntervals = new CountIntervals(); // 用一个区间空集初始化对象
countIntervals.add(2, 3); // 将 [2, 3] 添加到区间集合中
countIntervals.add(7, 10); // 将 [7, 10] 添加到区间集合中
countIntervals.count(); // 返回 6
// 整数 2 和 3 出现在区间 [2, 3] 中
// 整数 7、8、9、10 出现在区间 [7, 10] 中
countIntervals.add(5, 8); // 将 [5, 8] 添加到区间集合中
countIntervals.count(); // 返回 8
// 整数 2 和 3 出现在区间 [2, 3] 中
// 整数 5 和 6 出现在区间 [5, 8] 中
// 整数 7 和 8 出现在区间 [5, 8] 和区间 [7, 10] 中
// 整数 9 和 10 出现在区间 [7, 10] 中
提示:
1 <= left <= right <= 109- 最多调用
add和count方法 总计105次 - 调用
count方法至少一次
思路:
利用缓存的方式,先排序再插入,提高性能。
bool cmp(const vector<int>&v1, const vector<int>&v2)
{
return v1[0] < v2[0];
}
class CountIntervals {
public:
CountIntervals() {
}
void add(int left, int right) {
pushs.push_back(vector<int>{left, right});
}
int count() {
sort(pushs.begin(), pushs.end(), cmp);
for (auto v : pushs) {
opt.push(CloseIval<0>(v[0], v[1]));
}
pushs.clear();
int s = 0;
for (auto x : opt.allCi) {
s += x.high - x.low + 1;
}
return s;
}
CloseInterval<0> opt;
vector<vector<int>>pushs;
};2279. 装满石头的背包的最大数量
现有编号从 0 到 n - 1 的 n 个背包。给你两个下标从 0 开始的整数数组 capacity 和 rocks 。第 i 个背包最大可以装 capacity[i] 块石头,当前已经装了 rocks[i] 块石头。另给你一个整数 additionalRocks ,表示你可以放置的额外石头数量,石头可以往 任意 背包中放置。
请你将额外的石头放入一些背包中,并返回放置后装满石头的背包的 最大 数量。
示例 1:
输入:capacity = [2,3,4,5], rocks = [1,2,4,4], additionalRocks = 2 输出:3 解释: 1 块石头放入背包 0 ,1 块石头放入背包 1 。 每个背包中的石头总数是 [2,3,4,4] 。 背包 0 、背包 1 和 背包 2 都装满石头。 总计 3 个背包装满石头,所以返回 3 。 可以证明不存在超过 3 个背包装满石头的情况。 注意,可能存在其他放置石头的方案同样能够得到 3 这个结果。
示例 2:
输入:capacity = [10,2,2], rocks = [2,2,0], additionalRocks = 100 输出:3 解释: 8 块石头放入背包 0 ,2 块石头放入背包 2 。 每个背包中的石头总数是 [10,2,2] 。 背包 0 、背包 1 和背包 2 都装满石头。 总计 3 个背包装满石头,所以返回 3 。 可以证明不存在超过 3 个背包装满石头的情况。 注意,不必用完所有的额外石头。
提示:
n == capacity.length == rocks.length1 <= n <= 5 * 1041 <= capacity[i] <= 1090 <= rocks[i] <= capacity[i]1 <= additionalRocks <= 109
class Solution {
public:
int maximumBags(vector<int>& capacity, vector<int>& rocks, int additionalRocks) {
for (int i = 0; i < capacity.size(); i++)capacity[i] -= rocks[i];
sort(capacity.begin(), capacity.end());
int ans = 0;
for (auto x : capacity) {
ans += (x <= additionalRocks), additionalRocks -= x;
if (additionalRocks < 0)break;
}
return ans;
}
};2280. 表示一个折线图的最少线段数
2283. 判断一个数的数字计数是否等于数位的值
2287. 重排字符形成目标字符串
2288. 价格减免
句子 是由若干个单词组成的字符串,单词之间用单个空格分隔,其中每个单词可以包含数字、小写字母、和美元符号 '$' 。如果单词的形式为美元符号后跟着一个非负实数,那么这个单词就表示一个 价格 。
- 例如
"$100"、"$23"和"$6"表示价格,而"100"、"$"和"$1e5不是。
给你一个字符串 sentence 表示一个句子和一个整数 discount 。对于每个表示价格的单词,都在价格的基础上减免 discount% ,并 更新 该单词到句子中。所有更新后的价格应该表示为一个 恰好保留小数点后两位 的数字。
返回表示修改后句子的字符串。
注意:所有价格 最多 为 10 位数字。
示例 1:
输入:sentence = "there are $1 $2 and 5$ candies in the shop", discount = 50 输出:"there are $0.50 $1.00 and 5$ candies in the shop" 解释: 表示价格的单词是 "$1" 和 "$2" 。 - "$1" 减免 50% 为 "$0.50" ,所以 "$1" 替换为 "$0.50" 。 - "$2" 减免 50% 为 "$1" ,所以 "$2" 替换为 "$1.00" 。
示例 2:
输入:sentence = "1 2 $3 4 $5 $6 7 8$ $9 $10$", discount = 100 输出:"1 2 $0.00 4 $0.00 $0.00 7 8$ $0.00 $10$" 解释: 任何价格减免 100% 都会得到 0 。 表示价格的单词分别是 "$3"、"$5"、"$6" 和 "$9"。 每个单词都替换为 "$0.00"。
提示:
1 <= sentence.length <= 105sentence由小写英文字母、数字、' '和'$'组成sentence不含前导和尾随空格sentence的所有单词都用单个空格分隔- 所有价格都是 正 整数且不含前导零
- 所有价格 最多 为
10位数字 0 <= discount <= 100
class Solution {
public:
string change(string sentence, int r) {
string s = sentence.substr(1, sentence.length() - 1);
istringstream iss(s);
long long x;
iss >> x;
x *= r;
ostringstream oss;
oss << x/100 << '.' <<(x%100<10?"0":"")<< x%100;
return sentence[0] + oss.str();
}
bool needChange(string s) {
if (s.length() <= 1 || s[0] != '$')return false;
if (s[1] == '-')return false;
for (int i = 1; i < s.length(); i++)if (s[i] == '$' || (s[i] >= 'a'&&s[i] <= 'z'))return false;
return true;
}
string discountPrices(string sentence, int discount) {
auto v = StringSplit(sentence);
string ans;
int r = 100 - discount;
for (int i = 0; i < v.size(); i++) {
if (i)ans += ' ';
ans += needChange(v[i]) ? change(v[i], r) : v[i];
}
return ans;
}
};2293. 极大极小游戏
给你一个下标从 0 开始的整数数组 nums ,其长度是 2 的幂。
对 nums 执行下述算法:
设 n 等于 nums 的长度,如果 n == 1 ,终止 算法过程。否则,创建 一个新的整数数组 newNums ,新数组长度为 n / 2 ,下标从 0 开始。
对于满足 0 <= i < n / 2 的每个 偶数 下标 i ,将 newNums[i] 赋值 为 min(nums[2 * i], nums[2 * i + 1]) 。
对于满足 0 <= i < n / 2 的每个 奇数 下标 i ,将 newNums[i] 赋值 为 max(nums[2 * i], nums[2 * i + 1]) 。
用 newNums 替换 nums 。
从步骤 1 开始 重复 整个过程。
执行算法后,返回 nums 中剩下的那个数字。
示例 1:
输入:nums = [1,3,5,2,4,8,2,2]
输出:1
解释:重复执行算法会得到下述数组。
第一轮:nums = [1,5,4,2]
第二轮:nums = [1,4]
第三轮:nums = [1]
1 是最后剩下的那个数字,返回 1 。
示例 2:
输入:nums = [3]
输出:3
解释:3 就是最后剩下的数字,返回 3 。
提示:
1 <= nums.length <= 1024
1 <= nums[i] <= 109
nums.length 是 2 的幂
class Solution {
public:
int minMaxGame(vector<int>& nums) {
if (nums.size() == 1)return nums[0];
for (int i = 0; i < nums.size() / 2; i++) {
nums[i] = (i % 2) ? max(nums[i * 2], nums[i * 2 + 1]) : min(nums[i * 2], nums[i * 2 + 1]);
}
nums.resize(nums.size() / 2);
return minMaxGame(nums);
}
};2299. 强密码检验器 II
2300. 咒语和药水的成功对数
2303. 计算应缴税款总额
2307. 检查方程中的矛盾之处
2309. 兼具大小写的最好英文字母
2312. 卖木头块
2313. 二叉树中得到结果所需的最少翻转次数
2315. 统计星号
给你一个字符串 s ,每 两个 连续竖线 '|' 为 一对 。换言之,第一个和第二个 '|' 为一对,第三个和第四个 '|' 为一对,以此类推。
请你返回 不在 竖线对之间,s 中 '*' 的数目。
注意,每个竖线 '|' 都会 恰好 属于一个对。
示例 1:
输入:s = "l|*e*et|c**o|*de|"
输出:2
解释:不在竖线对之间的字符加粗加斜体后,得到字符串:"l|*e*et|c**o|*de|" 。
第一和第二条竖线 '|' 之间的字符不计入答案。
同时,第三条和第四条竖线 '|' 之间的字符也不计入答案。
不在竖线对之间总共有 2 个星号,所以我们返回 2 。
示例 2:
输入:s = "iamprogrammer"
输出:0
解释:在这个例子中,s 中没有星号。所以返回 0 。
示例 3:
输入:s = "yo|uar|e**|b|e***au|tifu|l"
输出:5
解释:需要考虑的字符加粗加斜体后:"yo|uar|e**|b|e***au|tifu|l" 。不在竖线对之间总共有 5 个星号。所以我们返回 5 。
提示:
1 <= s.length <= 1000
s 只包含小写英文字母,竖线 '|' 和星号 '*' 。
s 包含 偶数 个竖线 '|' 。
class Solution {
public:
int countAsterisks(string s) {
int ans = 0;
map<char, char>m;
m['|'] = '|';
vector<string>v = StringMatchSplit(s, m)[0];
for (auto str : v)
ans += count(str);
return ans;
}
int count(string s)
{
int ans = 0;
for (auto c : s)if (c == '*')ans++;
return ans;
}
};2316. 统计无向图中无法互相到达点对数
2317. 操作后的最大异或和
2319. 判断矩阵是否是一个 X 矩阵
2325. 解密消息
给你字符串 key 和 message ,分别表示一个加密密钥和一段加密消息。解密 message 的步骤如下:
- 使用
key中 26 个英文小写字母第一次出现的顺序作为替换表中的字母 顺序 。 - 将替换表与普通英文字母表对齐,形成对照表。
- 按照对照表 替换
message中的每个字母。 - 空格
' '保持不变。
- 例如,
key = "happy boy"(实际的加密密钥会包含字母表中每个字母 至少一次),据此,可以得到部分对照表('h' -> 'a'、'a' -> 'b'、'p' -> 'c'、'y' -> 'd'、'b' -> 'e'、'o' -> 'f')。
返回解密后的消息。
示例 1:
输入:key = "the quick brown fox jumps over the lazy dog", message = "vkbs bs t suepuv" 输出:"this is a secret" 解释:对照表如上图所示。 提取 "the quick brown fox jumps over the lazy dog" 中每个字母的首次出现可以得到替换表。
示例 2:

输入:key = "eljuxhpwnyrdgtqkviszcfmabo", message = "zwx hnfx lqantp mnoeius ycgk vcnjrdb" 输出:"the five boxing wizards jump quickly" 解释:对照表如上图所示。 提取 "eljuxhpwnyrdgtqkviszcfmabo" 中每个字母的首次出现可以得到替换表。
提示:
26 <= key.length <= 2000key由小写英文字母及' '组成key包含英文字母表中每个字符('a'到'z')至少一次1 <= message.length <= 2000message由小写英文字母和' '组成
class Solution {
public:
string decodeMessage(string key, string s) {
map<char, char>m;
char x = 'a';
char e = ' ';
m[e] = ' ';
for (auto c : key)if (c!=' ' && !m[c])m[c] = x++;
for (int i = 0; i < s.length(); i++)s[i] = m[s[i]];
return s;
}
};2326. 螺旋矩阵 IV
给你两个整数:m 和 n ,表示矩阵的维数。
另给你一个整数链表的头节点 head 。
请你生成一个大小为 m x n 的螺旋矩阵,矩阵包含链表中的所有整数。链表中的整数从矩阵 左上角 开始、顺时针 按 螺旋 顺序填充。如果还存在剩余的空格,则用 -1 填充。
返回生成的矩阵。
示例 1:

输入:m = 3, n = 5, head = [3,0,2,6,8,1,7,9,4,2,5,5,0] 输出:[[3,0,2,6,8],[5,0,-1,-1,1],[5,2,4,9,7]] 解释:上图展示了链表中的整数在矩阵中是如何排布的。 注意,矩阵中剩下的空格用 -1 填充。
示例 2:

输入:m = 1, n = 4, head = [0,1,2] 输出:[[0,1,2,-1]] 解释:上图展示了链表中的整数在矩阵中是如何从左到右排布的。 注意,矩阵中剩下的空格用 -1 填充。
提示:
1 <= m, n <= 1051 <= m * n <= 105- 链表中节点数目在范围
[1, m * n]内 0 <= Node.val <= 1000
int dx[] = { 0,1,0,-1 };
int dy[] = { 1,0,-1,0 };
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>> matrix) {
vector<int>ans;
if (matrix.empty())return ans;
int k = 0, len = matrix.size() * matrix[0].size();
int x = 0, y = 0;
while (len--)
{
if (x < 0 || x >= matrix.size() || y < 0 || y >= matrix[0].size() || matrix[x][y] == -1234567)
{
x -= dx[k], y -= dy[k];
k++, k %= 4;
x += dx[k], y += dy[k];
}
ans.push_back(matrix[x][y]);
matrix[x][y] = -1234567;
x += dx[k], y += dy[k];
}
return ans;
}
vector<vector<int>> spiralMatrix(int m, int n, ListNode* head) {
vector<vector<int>> matrix(m);
for (int i = 0; i < m; i++)for (int j = 0; j < n; j++)matrix[i].push_back(i * n + j);
vector<int> v = spiralOrder(matrix);
for (int i = 0; i < m * n; i++) {
if (head)matrix[v[i] / n][v[i] % n] = head->val, head = head->next;
else matrix[v[i] / n][v[i] % n] = -1;
}
return matrix;
}
};2327. 知道秘密的人数
2335. 装满杯子需要的最短总时长
现有一台饮水机,可以制备冷水、温水和热水。每秒钟,可以装满 2 杯 不同 类型的水或者 1 杯任意类型的水。
给你一个下标从 0 开始、长度为 3 的整数数组 amount ,其中 amount[0]、amount[1] 和 amount[2] 分别表示需要装满冷水、温水和热水的杯子数量。返回装满所有杯子所需的 最少 秒数。
示例 1:
输入:amount = [1,4,2]
输出:4
解释:下面给出一种方案:
第 1 秒:装满一杯冷水和一杯温水。
第 2 秒:装满一杯温水和一杯热水。
第 3 秒:装满一杯温水和一杯热水。
第 4 秒:装满一杯温水。
可以证明最少需要 4 秒才能装满所有杯子。
示例 2:
输入:amount = [5,4,4]
输出:7
解释:下面给出一种方案:
第 1 秒:装满一杯冷水和一杯热水。
第 2 秒:装满一杯冷水和一杯温水。
第 3 秒:装满一杯冷水和一杯温水。
第 4 秒:装满一杯温水和一杯热水。
第 5 秒:装满一杯冷水和一杯热水。
第 6 秒:装满一杯冷水和一杯温水。
第 7 秒:装满一杯热水。
示例 3:
输入:amount = [5,0,0]
输出:5
解释:每秒装满一杯冷水。
提示:
amount.length == 3
0 <= amount[i] <= 100
class Solution {
public:
int fillCups(vector<int>& amount) {
int s=1,m=0;
for(auto x:amount)s+=x,m=max(m,x);
return max(m,s/2);
}
};2336. 无限集中的最小数字
2338. 统计理想数组的数目
2341. 数组能形成多少数对
给你一个下标从 0 开始的整数数组 nums 。在一步操作中,你可以执行以下步骤:
从 nums 选出 两个 相等的 整数
从 nums 中移除这两个整数,形成一个 数对
请你在 nums 上多次执行此操作直到无法继续执行。
返回一个下标从 0 开始、长度为 2 的整数数组 answer 作为答案,其中 answer[0] 是形成的数对数目,answer[1] 是对 nums 尽可能执行上述操作后剩下的整数数目。
示例 1:
输入:nums = [1,3,2,1,3,2,2]
输出:[3,1]
解释:
nums[0] 和 nums[3] 形成一个数对,并从 nums 中移除,nums = [3,2,3,2,2] 。
nums[0] 和 nums[2] 形成一个数对,并从 nums 中移除,nums = [2,2,2] 。
nums[0] 和 nums[1] 形成一个数对,并从 nums 中移除,nums = [2] 。
无法形成更多数对。总共形成 3 个数对,nums 中剩下 1 个数字。
示例 2:
输入:nums = [1,1]
输出:[1,0]
解释:nums[0] 和 nums[1] 形成一个数对,并从 nums 中移除,nums = [] 。
无法形成更多数对。总共形成 1 个数对,nums 中剩下 0 个数字。
示例 3:
输入:nums = [0]
输出:[0,1]
解释:无法形成数对,nums 中剩下 1 个数字。
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 100
class Solution {
public:
vector<int> numberOfPairs(vector<int>& nums) {
map<int,int>m;
int s=0;
for(auto x:nums)m[x]++,s+=(m[x]%2==0);
return vector<int>{s,int(nums.size()-s*2)};
}
};2342. 数位和相等数对的最大和
给你一个下标从 0 开始的数组 nums ,数组中的元素都是 正 整数。请你选出两个下标 i 和 j(i != j),且 nums[i] 的数位和 与 nums[j] 的数位和相等。
请你找出所有满足条件的下标 i 和 j ,找出并返回 nums[i] + nums[j] 可以得到的 最大值 。
示例 1:
输入:nums = [18,43,36,13,7] 输出:54 解释:满足条件的数对 (i, j) 为: - (0, 2) ,两个数字的数位和都是 9 ,相加得到 18 + 36 = 54 。 - (1, 4) ,两个数字的数位和都是 7 ,相加得到 43 + 7 = 50 。 所以可以获得的最大和是 54 。
示例 2:
输入:nums = [10,12,19,14] 输出:-1 解释:不存在满足条件的数对,返回 -1 。
提示:
1 <= nums.length <= 1051 <= nums[i] <= 109
class Solution {
public:
int maximumSum(vector<int>& nums) {
map<int,vector<int>>m;
for(auto x: nums){
int s=0,a=x;
while(a)s+=a%10,a/=10;
m[s].push_back(x);
}
int ans=-1;
for(auto mi: m){
if(mi.second.size()<2)continue;
int a=0,b=0,c=0;
for(auto x : mi.second){
c=x;
if(b<c)b^=c^=b^=c;
if(a<b)a^=b^=a^=b;
}
ans=max(ans,a+b);
}
return ans;
}
};2344. 使数组可以被整除的最少删除次数
2348. 全 0 子数组的数目
给你一个整数数组 nums ,返回全部为 0 的 子数组 数目。
子数组 是一个数组中一段连续非空元素组成的序列。
示例 1:
输入:nums = [1,3,0,0,2,0,0,4] 输出:6 解释: 子数组 [0] 出现了 4 次。 子数组 [0,0] 出现了 2 次。 不存在长度大于 2 的全 0 子数组,所以我们返回 6 。
示例 2:
输入:nums = [0,0,0,2,0,0] 输出:9 解释: 子数组 [0] 出现了 5 次。 子数组 [0,0] 出现了 3 次。 子数组 [0,0,0] 出现了 1 次。 不存在长度大于 3 的全 0 子数组,所以我们返回 9 。
示例 3:
输入:nums = [2,10,2019] 输出:0 解释:没有全 0 子数组,所以我们返回 0 。
提示:
1 <= nums.length <= 105-109 <= nums[i] <= 109
class Solution {
public:
long long zeroFilledSubarray(vector<int>& nums) {
long long n=0,ans=0;
for(auto x:nums){
if(x)ans+=(n+1)*n/2,n=0;
else n++;
}
return ans+(n+1)*n/2;
}
};2351. 第一个出现两次的字母
给你一个由小写英文字母组成的字符串 s ,请你找出并返回第一个出现 两次 的字母。
注意:
如果 a 的 第二次 出现比 b 的 第二次 出现在字符串中的位置更靠前,则认为字母 a 在字母 b 之前出现两次。
s 包含至少一个出现两次的字母。
示例 1:
输入:s = "abccbaacz"
输出:"c"
解释:
字母 'a' 在下标 0 、5 和 6 处出现。
字母 'b' 在下标 1 和 4 处出现。
字母 'c' 在下标 2 、3 和 7 处出现。
字母 'z' 在下标 8 处出现。
字母 'c' 是第一个出现两次的字母,因为在所有字母中,'c' 第二次出现的下标是最小的。
示例 2:
输入:s = "abcdd"
输出:"d"
解释:
只有字母 'd' 出现两次,所以返回 'd' 。
提示:
2 <= s.length <= 100
s 由小写英文字母组成
s 包含至少一个重复字母
class Solution {
public:
char repeatedCharacter(string s) {
map<char,int>m;
for(auto c:s){
if(m[c]++)return c;
}
return '0';
}
};2368. 受限条件下可到达节点的数目
2369. 检查数组是否存在有效划分
2385. 感染二叉树需要的总时间
2386. 找出数组的第 K 大和
给你一个整数数组 nums 和一个 正 整数 k 。你可以选择数组的任一 子序列 并且对其全部元素求和。
数组的 第 k 大和 定义为:可以获得的第 k 个 最大 子序列和(子序列和允许出现重复)
返回数组的 第 k 大和 。
子序列是一个可以由其他数组删除某些或不删除元素排生而来的数组,且派生过程不改变剩余元素的顺序。
注意:空子序列的和视作 0 。
示例 1:
输入:nums = [2,4,-2], k = 5 输出:2 解释:所有可能获得的子序列和列出如下,按递减顺序排列: - 6、4、4、2、2、0、0、-2 数组的第 5 大和是 2 。
示例 2:
输入:nums = [1,-2,3,4,-10,12], k = 16 输出:10 解释:数组的第 16 大和是 10 。
提示:
n == nums.length1 <= n <= 105-109 <= nums[i] <= 1091 <= k <= min(2000, 2n)
思路:
贪心。
只有最后一个用例是超时的,作弊加了一行才AC
class Solution {
public:
long long kSum(vector<int>& nums, int k) {
if (nums.size() > 99999 && k==1731)return 24946959360753;
sort(nums.begin(), nums.end());
int id = upper_bound(nums.begin(), nums.end(), 0) - nums.begin();
long long s = 0;
for (int i = id; i < nums.size(); i++)s += nums[i];
multiset<long long>ss;
ss.insert(s);
vector<int>num2;
int i = id, j = id + 1;
while (i >= 0 && j < nums.size()) {
if (nums[i] + nums[j] > 0)num2.push_back(nums[i--]);
else num2.push_back(nums[j++]);
}
if (i == nums.size())i--;
while (i >= 0)num2.push_back(nums[i--]);
while(j < nums.size())num2.push_back(nums[j++]);
for (auto x:num2) {
long long t = *ss.begin();
int dif = -abs(x);
int num = 0;
vector<long long>v;
for (auto it = ss.rbegin(); it != ss.rend(); it++) {
if (ss.size() + v.size() < k || *it + dif >= t)v.push_back(*it + dif);
if (++num > k / 2)break;
}
for (auto x : v)ss.insert(x);
while (ss.size() > k)ss.erase(ss.begin());
}
return *ss.begin();
}
};2387. 行排序矩阵的中位数
2391. 收集垃圾的最少总时间
给你一个下标从 0 开始的字符串数组 garbage ,其中 garbage[i] 表示第 i 个房子的垃圾集合。garbage[i] 只包含字符 'M' ,'P' 和 'G' ,但可能包含多个相同字符,每个字符分别表示一单位的金属、纸和玻璃。垃圾车收拾 一 单位的任何一种垃圾都需要花费 1 分钟。
同时给你一个下标从 0 开始的整数数组 travel ,其中 travel[i] 是垃圾车从房子 i 行驶到房子 i + 1 需要的分钟数。
城市里总共有三辆垃圾车,分别收拾三种垃圾。每辆垃圾车都从房子 0 出发,按顺序 到达每一栋房子。但它们 不是必须 到达所有的房子。
任何时刻只有 一辆 垃圾车处在使用状态。当一辆垃圾车在行驶或者收拾垃圾的时候,另外两辆车 不能 做任何事情。
请你返回收拾完所有垃圾需要花费的 最少 总分钟数。
示例 1:
输入:garbage = ["G","P","GP","GG"], travel = [2,4,3] 输出:21 解释: 收拾纸的垃圾车: 1. 从房子 0 行驶到房子 1 2. 收拾房子 1 的纸垃圾 3. 从房子 1 行驶到房子 2 4. 收拾房子 2 的纸垃圾 收拾纸的垃圾车总共花费 8 分钟收拾完所有的纸垃圾。 收拾玻璃的垃圾车: 1. 收拾房子 0 的玻璃垃圾 2. 从房子 0 行驶到房子 1 3. 从房子 1 行驶到房子 2 4. 收拾房子 2 的玻璃垃圾 5. 从房子 2 行驶到房子 3 6. 收拾房子 3 的玻璃垃圾 收拾玻璃的垃圾车总共花费 13 分钟收拾完所有的玻璃垃圾。 由于没有金属垃圾,收拾金属的垃圾车不需要花费任何时间。 所以总共花费 8 + 13 = 21 分钟收拾完所有垃圾。
示例 2:
输入:garbage = ["MMM","PGM","GP"], travel = [3,10] 输出:37 解释: 收拾金属的垃圾车花费 7 分钟收拾完所有的金属垃圾。 收拾纸的垃圾车花费 15 分钟收拾完所有的纸垃圾。 收拾玻璃的垃圾车花费 15 分钟收拾完所有的玻璃垃圾。 总共花费 7 + 15 + 15 = 37 分钟收拾完所有的垃圾。
提示:
2 <= garbage.length <= 105garbage[i]只包含字母'M','P'和'G'。1 <= garbage[i].length <= 10travel.length == garbage.length - 11 <= travel[i] <= 100
class Solution {
public:
int garbageCollection(vector<string>& garbage, vector<int>& travel) {
int ans = 0, m = 0, p = 0, g = 0;
for (int i = 0; i < garbage.size();i++) {
ans += garbage[i].length();
if (garbage[i].find('M') != garbage[i].npos)m = i;
if (garbage[i].find('P') != garbage[i].npos)p = i;
if (garbage[i].find('G') != garbage[i].npos)g = i;
}
for (int i = 0; i < m; i++)ans += travel[i];
for (int i = 0; i < p; i++)ans += travel[i];
for (int i = 0; i < g; i++)ans += travel[i];
return ans;
}
};2396. 严格回文的数字
如果一个整数 n 在 b 进制下(b 为 2 到 n - 2 之间的所有整数)对应的字符串 全部 都是 回文的 ,那么我们称这个数 n 是 严格回文 的。
给你一个整数 n ,如果 n 是 严格回文 的,请返回 true ,否则返回 false 。
如果一个字符串从前往后读和从后往前读完全相同,那么这个字符串是 回文的 。
示例 1:
输入:n = 9 输出:false 解释:在 2 进制下:9 = 1001 ,是回文的。 在 3 进制下:9 = 100 ,不是回文的。 所以,9 不是严格回文数字,我们返回 false 。 注意在 4, 5, 6 和 7 进制下,n = 9 都不是回文的。
示例 2:
输入:n = 4 输出:false 解释:我们只考虑 2 进制:4 = 100 ,不是回文的。 所以我们返回 false 。
提示:
4 <= n <= 105
class Solution {
public:
bool isStrictlyPalindromic(int n) {
return false;
}
};2397. 被列覆盖的最多行数
2400. 恰好移动 k 步到达某一位置的方法数目
2406. 将区间分为最少组数
2413. 最小偶倍数
给你一个正整数 n ,返回 2 和 n 的最小公倍数(正整数)。
示例 1:
输入:n = 5 输出:10 解释:5 和 2 的最小公倍数是 10 。
示例 2:
输入:n = 6 输出:6 解释:6 和 2 的最小公倍数是 6 。注意数字会是它自身的倍数。
提示:
1 <= n <= 150
class Solution {
public:
int smallestEvenMultiple(int n) {
return n%2?n*2:n;
}
};2414. 最长的字母序连续子字符串的长度
字母序连续字符串 是由字母表中连续字母组成的字符串。换句话说,字符串 "abcdefghijklmnopqrstuvwxyz" 的任意子字符串都是 字母序连续字符串 。
- 例如,
"abc"是一个字母序连续字符串,而"acb"和"za"不是。
给你一个仅由小写英文字母组成的字符串 s ,返回其 最长 的 字母序连续子字符串 的长度。
示例 1:
输入:s = "abacaba" 输出:2 解释:共有 4 个不同的字母序连续子字符串 "a"、"b"、"c" 和 "ab" 。 "ab" 是最长的字母序连续子字符串。
示例 2:
输入:s = "abcde" 输出:5 解释:"abcde" 是最长的字母序连续子字符串。
提示:
1 <= s.length <= 105s由小写英文字母组成
class Solution {
public:
int longestContinuousSubstring(string s) {
int ans = 1, x = 1;
for (int i = 1; i < s.length(); i++) {
if (s[i] - s[i - 1] == 1)ans = max(ans, ++x);
else x = 1;
}
return ans;
}
};2417. 最近的公平整数
给定一个 正整数 n。
如果一个整数 k 中的 偶数 位数与 奇数 位数相等,那么我们称 k 为公平整数。
返回 大于或等于 n 的 最小 的公平整数。
示例 1:
输入: n = 2 输出: 10 解释: 大于等于 2 的最小的公平整数是 10。 10是公平整数,因为它的偶数和奇数个数相等 (一个奇数和一个偶数)。
示例 2:
输入: n = 403 输出: 1001 解释: 大于或等于 403 的最小的公平整数是 1001。 1001 是公平整数,因为它有相等数量的偶数和奇数 (两个奇数和两个偶数)。
提示:
1 <= n <= 109
class Solution {
public:
int closestFair(int n) {
long long len=0,mi=1,m=n;
while(m)m/=10,len++,mi*=10;
n=len%2?mi:n;
while(!check(n)){
if(++n==mi)return closestFair(n);
}
return n;
}
bool check(int n){
int s=0;
while(n){
if(n%2)s++;
else s--;
n/=10;
}
return s==0;
}
};2419. 按位与最大的最长子数组
给你一个长度为 n 的整数数组 nums 。
考虑 nums 中进行 按位与(bitwise AND)运算得到的值 最大 的 非空 子数组。
- 换句话说,令
k是nums任意 子数组执行按位与运算所能得到的最大值。那么,只需要考虑那些执行一次按位与运算后等于k的子数组。
返回满足要求的 最长 子数组的长度。
数组的按位与就是对数组中的所有数字进行按位与运算。
子数组 是数组中的一个连续元素序列。
示例 1:
输入:nums = [1,2,3,3,2,2] 输出:2 解释: 子数组按位与运算的最大值是 3 。 能得到此结果的最长子数组是 [3,3],所以返回 2 。
示例 2:
输入:nums = [1,2,3,4] 输出:1 解释: 子数组按位与运算的最大值是 4 。 能得到此结果的最长子数组是 [4],所以返回 1 。
提示:
1 <= nums.length <= 1051 <= nums[i] <= 106
class Solution {
public:
int longestSubarray(vector<int>& nums) {
int m=0,a=0,ans=0;
for(auto x:nums)m=max(m,x);
for(auto x:nums){
if(x==m)a++;
else ans=max(ans,a),a=0;
}
return max(ans,a);
}
};2425. 所有数对的异或和
2427. 公因子的数目
2436. 使子数组最大公约数大于一的最小分割数
2441. 与对应负数同时存在的最大正整数
给你一个 不包含 任何零的整数数组 nums ,找出自身与对应的负数都在数组中存在的最大正整数 k 。
返回正整数 k ,如果不存在这样的整数,返回 -1 。
示例 1:
输入:nums = [-1,2,-3,3]
输出:3
解释:3 是数组中唯一一个满足题目要求的 k 。
示例 2:
输入:nums = [-1,10,6,7,-7,1]
输出:7
解释:数组中存在 1 和 7 对应的负数,7 的值更大。
示例 3:
输入:nums = [-10,8,6,7,-2,-3]
输出:-1
解释:不存在满足题目要求的 k ,返回 -1 。
提示:
1 <= nums.length <= 1000
-1000 <= nums[i] <= 1000
nums[i] != 0
class Solution {
public:
int findMaxK(vector<int>& nums) {
map<int,int>m;
for(auto x:nums)m[x]++;
sort(nums.begin(),nums.end());
for(int i=nums.size()-1;i>=0;i--)if(nums[i]>0&&m[-nums[i]])return nums[i];
return -1;
}
};2446. 判断两个事件是否存在冲突
给你两个字符串数组 event1 和 event2 ,表示发生在同一天的两个闭区间时间段事件,其中:
event1 = [startTime1, endTime1]且event2 = [startTime2, endTime2]
事件的时间为有效的 24 小时制且按 HH:MM 格式给出。
当两个事件存在某个非空的交集时(即,某些时刻是两个事件都包含的),则认为出现 冲突 。
如果两个事件之间存在冲突,返回 true ;否则,返回 false 。
示例 1:
输入:event1 = ["01:15","02:00"], event2 = ["02:00","03:00"] 输出:true 解释:两个事件在 2:00 出现交集。
示例 2:
输入:event1 = ["01:00","02:00"], event2 = ["01:20","03:00"] 输出:true 解释:两个事件的交集从 01:20 开始,到 02:00 结束。
示例 3:
输入:event1 = ["10:00","11:00"], event2 = ["14:00","15:00"] 输出:false 解释:两个事件不存在交集。
提示:
evnet1.length == event2.length == 2.event1[i].length == event2[i].length == 5startTime1 <= endTime1startTime2 <= endTime2- 所有事件的时间都按照
HH:MM格式给出
class Solution {
public:
bool haveConflict(vector<string>& event1, vector<string>& event2) {
int s1=f(event1[0]),e1=f(event1[1]);
int s2=f(event2[0]),e2=f(event2[1]);
return min(e1,e2)>=max(s1,s2);
}
int f(string s)
{
return f(s[0],s[1])*60+f(s[3],s[4]);
}
int f(char a,char b)
{
return (a-'0')*10+b-'0';
}
};2447. 最大公因数等于 K 的子数组数目
2454. 下一个更大元素 IV
2455. 可被三整除的偶数的平均值
给你一个由正整数组成的整数数组 nums ,返回其中可被 3 整除的所有偶数的平均值。
注意:n 个元素的平均值等于 n 个元素 求和 再除以 n ,结果 向下取整 到最接近的整数。
示例 1:
输入:nums = [1,3,6,10,12,15] 输出:9 解释:6 和 12 是可以被 3 整除的偶数。(6 + 12) / 2 = 9 。
示例 2:
输入:nums = [1,2,4,7,10] 输出:0 解释:不存在满足题目要求的整数,所以返回 0 。
提示:
1 <= nums.length <= 10001 <= nums[i] <= 1000
class Solution {
public:
int averageValue(vector<int>& nums) {
int ans=0,num=0;
for(auto x:nums)if(x%6==0)ans+=x,num++;
return num?ans/num:ans;
}
};2458. 移除子树后的二叉树高度
2462. 雇佣 K 位工人的总代价
2465. 不同的平均值数目
给你一个下标从 0 开始长度为 偶数 的整数数组 nums 。
只要 nums 不是 空数组,你就重复执行以下步骤:
- 找到
nums中的最小值,并删除它。 - 找到
nums中的最大值,并删除它。 - 计算删除两数的平均值。
两数 a 和 b 的 平均值 为 (a + b) / 2 。
- 比方说,
2和3的平均值是(2 + 3) / 2 = 2.5。
返回上述过程能得到的 不同 平均值的数目。
注意 ,如果最小值或者最大值有重复元素,可以删除任意一个。
示例 1:
输入:nums = [4,1,4,0,3,5] 输出:2 解释: 1. 删除 0 和 5 ,平均值是 (0 + 5) / 2 = 2.5 ,现在 nums = [4,1,4,3] 。 2. 删除 1 和 4 ,平均值是 (1 + 4) / 2 = 2.5 ,现在 nums = [4,3] 。 3. 删除 3 和 4 ,平均值是 (3 + 4) / 2 = 3.5 。 2.5 ,2.5 和 3.5 之中总共有 2 个不同的数,我们返回 2 。
示例 2:
输入:nums = [1,100] 输出:1 解释: 删除 1 和 100 后只有一个平均值,所以我们返回 1 。
提示:
2 <= nums.length <= 100nums.length是偶数。0 <= nums[i] <= 100
class Solution {
public:
int distinctAverages(vector<int>& nums) {
sort(nums.begin(),nums.end());
map<int,int>m;
for(int i=0;i<nums.size()/2;i++)m[nums[i]+nums[nums.size()-1-i]];
return m.size();
}
};2470. 最小公倍数为 K 的子数组数目
2476. 二叉搜索树最近节点查询
2481. 分割圆的最少切割次数
2485. 找出中枢整数
2487. 从链表中移除节点
2495. 乘积为偶数的子数组数
2496. 数组中字符串的最大值
2500. 删除每行中的最大值
给你一个 m x n 大小的矩阵 grid ,由若干正整数组成。
执行下述操作,直到 grid 变为空矩阵:
- 从每一行删除值最大的元素。如果存在多个这样的值,删除其中任何一个。
- 将删除元素中的最大值与答案相加。
注意 每执行一次操作,矩阵中列的数据就会减 1 。
返回执行上述操作后的答案。
示例 1:

输入:grid = [[1,2,4],[3,3,1]] 输出:8 解释:上图展示在每一步中需要移除的值。 - 在第一步操作中,从第一行删除 4 ,从第二行删除 3(注意,有两个单元格中的值为 3 ,我们可以删除任一)。在答案上加 4 。 - 在第二步操作中,从第一行删除 2 ,从第二行删除 3 。在答案上加 3 。 - 在第三步操作中,从第一行删除 1 ,从第二行删除 1 。在答案上加 1 。 最终,答案 = 4 + 3 + 1 = 8 。
示例 2:

输入:grid = [[10]] 输出:10 解释:上图展示在每一步中需要移除的值。 - 在第一步操作中,从第一行删除 10 。在答案上加 10 。 最终,答案 = 10 。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 501 <= grid[i][j] <= 100
class Solution {
public:
int deleteGreatestValue(vector<vector<int>>& grid) {
for(auto &gi:grid)sort(gi.begin(),gi.end());
auto ans=grid[0];
for(auto gi:grid){
for(int i=0;i<ans.size();i++)ans[i]=max(ans[i],gi[i]);
}
int s=0;
for(auto x:ans)s+=x;
return s;
}
};2506. 统计相似字符串对的数目
给你一个下标从 0 开始的字符串数组 words 。
如果两个字符串由相同的字符组成,则认为这两个字符串 相似 。
- 例如,
"abca"和"cba"相似,因为它们都由字符'a'、'b'、'c'组成。 - 然而,
"abacba"和"bcfd"不相似,因为它们不是相同字符组成的。
请你找出满足字符串 words[i] 和 words[j] 相似的下标对 (i, j) ,并返回下标对的数目,其中 0 <= i < j <= words.length - 1 。
示例 1:
输入:words = ["aba","aabb","abcd","bac","aabc"] 输出:2 解释:共有 2 对满足条件: - i = 0 且 j = 1 :words[0] 和 words[1] 只由字符 'a' 和 'b' 组成。 - i = 3 且 j = 4 :words[3] 和 words[4] 只由字符 'a'、'b' 和 'c' 。
示例 2:
输入:words = ["aabb","ab","ba"] 输出:3 解释:共有 3 对满足条件: - i = 0 且 j = 1 :words[0] 和 words[1] 只由字符 'a' 和 'b' 组成。 - i = 0 且 j = 2 :words[0] 和 words[2] 只由字符 'a' 和 'b' 组成。 - i = 1 且 j = 2 :words[1] 和 words[2] 只由字符 'a' 和 'b' 组成。
示例 3:
输入:words = ["nba","cba","dba"] 输出:0 解释:不存在满足条件的下标对,返回 0 。
提示:
1 <= words.length <= 1001 <= words[i].length <= 100words[i]仅由小写英文字母组成
class Solution {
public:
int hash(string s)
{
int x = 0;
char a = 'a';
for (auto c : s)x |= 1 << (c - a);
return x;
}
int similarPairs(vector<string>& words) {
map<int, int>m;
for (auto str : words)m[hash(str)]++;
int ans = 0;
for (auto mi : m) {
ans += mi.second*(mi.second - 1) / 2;
}
return ans;
}
};2507. 使用质因数之和替换后可以取到的最小值
2509. 查询树中环的长度
2512. 奖励最顶尖的 K 名学生
2513. 最小化两个数组中的最大值
2514. 统计同位异构字符串数目
2520. 统计能整除数字的位数
给你一个整数 num ,返回 num 中能整除 num 的数位的数目。
如果满足 nums % val == 0 ,则认为整数 val 可以整除 nums 。
示例 1:
输入:num = 7 输出:1 解释:7 被自己整除,因此答案是 1 。
示例 2:
输入:num = 121 输出:2 解释:121 可以被 1 整除,但无法被 2 整除。由于 1 出现两次,所以返回 2 。
示例 3:
输入:num = 1248 输出:4 解释:1248 可以被它每一位上的数字整除,因此答案是 4 。
提示:
1 <= num <= 109num的数位中不含0
class Solution {
public:
int countDigits(int num) {
int ans = 0, d = num;
while (d) {
if (num % (d % 10) == 0)ans++;
d /= 10;
}
return ans;
}
};2521. 数组乘积中的不同质因数数目
2523. 范围内最接近的两个质数
2525. 根据规则将箱子分类
2526. 找到数据流中的连续整数
2527. 查询数组 Xor 美丽值
2529. 正整数和负整数的最大计数
2530. 执行 K 次操作后的最大分数
给你一个下标从 0 开始的整数数组 nums 和一个整数 k 。你的 起始分数 为 0 。
在一步 操作 中:
- 选出一个满足
0 <= i < nums.length的下标i, - 将你的 分数 增加
nums[i],并且 - 将
nums[i]替换为ceil(nums[i] / 3)。
返回在 恰好 执行 k 次操作后,你可能获得的最大分数。
向上取整函数 ceil(val) 的结果是大于或等于 val 的最小整数。
示例 1:
输入:nums = [10,10,10,10,10], k = 5 输出:50 解释:对数组中每个元素执行一次操作。最后分数是 10 + 10 + 10 + 10 + 10 = 50 。
示例 2:
输入:nums = [1,10,3,3,3], k = 3 输出:17 解释:可以执行下述操作: 第 1 步操作:选中 i = 1 ,nums 变为 [1,4,3,3,3] 。分数增加 10 。 第 2 步操作:选中 i = 1 ,nums 变为 [1,2,3,3,3] 。分数增加 4 。 第 3 步操作:选中 i = 2 ,nums 变为 [1,1,1,3,3] 。分数增加 3 。 最后分数是 10 + 4 + 3 = 17 。
提示:
1 <= nums.length, k <= 1051 <= nums[i] <= 109
class Solution {
public:
long long maxKelements(vector<int>& nums, int k) {
priority_queue<int>q;
for (auto x : nums)q.push(x);
long long ans = 0;
while (k--) {
int x = q.top();
ans += x;
q.pop();
q.push((x + 2) / 3);
}
return ans;
}
};2536. 子矩阵元素加 1
2543. 判断一个点是否可以到达
2544. 交替数字和
2545. 根据第 K 场考试的分数排序
班里有 m 位学生,共计划组织 n 场考试。给你一个下标从 0 开始、大小为 m x n 的整数矩阵 score ,其中每一行对应一位学生,而 score[i][j] 表示第 i 位学生在第 j 场考试取得的分数。矩阵 score 包含的整数 互不相同 。
另给你一个整数 k 。请你按第 k 场考试分数从高到低完成对这些学生(矩阵中的行)的排序。
返回排序后的矩阵。
示例 1:
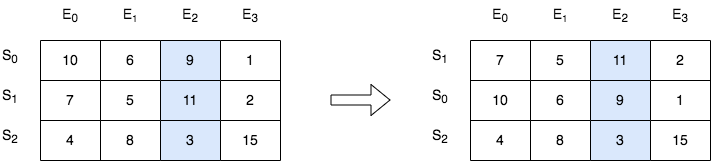
输入:score = [[10,6,9,1],[7,5,11,2],[4,8,3,15]], k = 2 输出:[[7,5,11,2],[10,6,9,1],[4,8,3,15]] 解释:在上图中,S 表示学生,E 表示考试。 - 下标为 1 的学生在第 2 场考试取得的分数为 11 ,这是考试的最高分,所以 TA 需要排在第一。 - 下标为 0 的学生在第 2 场考试取得的分数为 9 ,这是考试的第二高分,所以 TA 需要排在第二。 - 下标为 2 的学生在第 2 场考试取得的分数为 3 ,这是考试的最低分,所以 TA 需要排在第三。
示例 2:
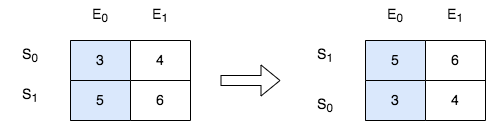
输入:score = [[3,4],[5,6]], k = 0 输出:[[5,6],[3,4]] 解释:在上图中,S 表示学生,E 表示考试。 - 下标为 1 的学生在第 0 场考试取得的分数为 5 ,这是考试的最高分,所以 TA 需要排在第一。 - 下标为 0 的学生在第 0 场考试取得的分数为 3 ,这是考试的最低分,所以 TA 需要排在第二。
提示:
m == score.lengthn == score[i].length1 <= m, n <= 2501 <= score[i][j] <= 105score由 不同 的整数组成0 <= k < n
#define Frev SingleVectorOpt::frev//翻转vector、翻转二维vector的每一行
#define SortId VectorOpt::sortId//排序后数组中的每个数的原ID,输入8 5 6 7,输出1 2 3 0
class Solution {
public:
vector<vector<int>> sortTheStudents(vector<vector<int>>& score, int k) {
vector<int>v;
for (auto &vi : score)v.push_back(vi[k]);
auto ids = SortId(v);
vector<vector<int>>ans;
for(auto id:ids)ans.push_back(score[id]);
return Frev<vector<int>>(ans);
}
};2549. 统计桌面上的不同数字
给你一个正整数 n ,开始时,它放在桌面上。在 109 天内,每天都要执行下述步骤:
- 对于出现在桌面上的每个数字
x,找出符合1 <= i <= n且满足x % i == 1的所有数字i。 - 然后,将这些数字放在桌面上。
返回在 109 天之后,出现在桌面上的 不同 整数的数目。
注意:
- 一旦数字放在桌面上,则会一直保留直到结束。
%表示取余运算。例如,14 % 3等于2。
示例 1:
输入:n = 5 输出:4 解释:最开始,5 在桌面上。 第二天,2 和 4 也出现在桌面上,因为 5 % 2 == 1 且 5 % 4 == 1 。 再过一天 3 也出现在桌面上,因为 4 % 3 == 1 。 在十亿天结束时,桌面上的不同数字有 2 、3 、4 、5 。
示例 2:
输入:n = 3 输出:2 解释: 因为 3 % 2 == 1 ,2 也出现在桌面上。 在十亿天结束时,桌面上的不同数字只有两个:2 和 3 。
提示:
1 <= n <= 100
class Solution {
public:
int distinctIntegers(int n) {
if(n==1)return 1;
return n-1;
}
};2551. 将珠子放入背包中
你有 k 个背包。给你一个下标从 0 开始的整数数组 weights ,其中 weights[i] 是第 i 个珠子的重量。同时给你整数 k 。
请你按照如下规则将所有的珠子放进 k 个背包。
- 没有背包是空的。
- 如果第
i个珠子和第j个珠子在同一个背包里,那么下标在i到j之间的所有珠子都必须在这同一个背包中。 - 如果一个背包有下标从
i到j的所有珠子,那么这个背包的价格是weights[i] + weights[j]。
一个珠子分配方案的 分数 是所有 k 个背包的价格之和。
请你返回所有分配方案中,最大分数 与 最小分数 的 差值 为多少。
示例 1:
输入:weights = [1,3,5,1], k = 2 输出:4 解释: 分配方案 [1],[3,5,1] 得到最小得分 (1+1) + (3+1) = 6 。 分配方案 [1,3],[5,1] 得到最大得分 (1+3) + (5+1) = 10 。 所以差值为 10 - 6 = 4 。
示例 2:
输入:weights = [1, 3], k = 2 输出:0 解释:唯一的分配方案为 [1],[3] 。 最大最小得分相等,所以返回 0 。
提示:
1 <= k <= weights.length <= 1051 <= weights[i] <= 109
class Solution {
public:
long long putMarbles(vector<int>& weights, int k) {
for (int i = weights.size() - 1; i; i--)weights[i] += weights[i - 1];
sort(weights.begin() + 1, weights.end());
long long ans = 0;
for (int i = 1; i <= k - 1; i++)ans -= weights[i];
for (int i = weights.size() - k + 1; i < weights.size(); i++)ans += weights[i];
return ans;
}
};2554. 从一个范围内选择最多整数 I
给你一个整数数组 banned 和两个整数 n 和 maxSum 。你需要按照以下规则选择一些整数:
- 被选择整数的范围是
[1, n]。 - 每个整数 至多 选择 一次 。
- 被选择整数不能在数组
banned中。 - 被选择整数的和不超过
maxSum。
请你返回按照上述规则 最多 可以选择的整数数目。
示例 1:
输入:banned = [1,6,5], n = 5, maxSum = 6 输出:2 解释:你可以选择整数 2 和 4 。 2 和 4 在范围 [1, 5] 内,且它们都不在 banned 中,它们的和是 6 ,没有超过 maxSum 。
示例 2:
输入:banned = [1,2,3,4,5,6,7], n = 8, maxSum = 1 输出:0 解释:按照上述规则无法选择任何整数。
示例 3:
输入:banned = [11], n = 7, maxSum = 50 输出:7 解释:你可以选择整数 1, 2, 3, 4, 5, 6 和 7 。 它们都在范围 [1, 7] 中,且都没出现在 banned 中,它们的和是 28 ,没有超过 maxSum 。
提示:
1 <= banned.length <= 1041 <= banned[i], n <= 1041 <= maxSum <= 109
class Solution {
public:
int maxCount(vector<int>& banned, int n, int maxSum) {
map<int,int>m;
for(auto x:banned)m[x]=1;
int ans=0;
for(int i=1;i<=n;i++){
if(m[i])continue;
maxSum-=i;
if(maxSum>=0)ans++;
else break;
}
return ans;
}
};2557. 从一个范围内选择最多整数 II
2558. 从数量最多的堆取走礼物
给你一个整数数组 gifts ,表示各堆礼物的数量。每一秒,你需要执行以下操作:
- 选择礼物数量最多的那一堆。
- 如果不止一堆都符合礼物数量最多,从中选择任一堆即可。
- 选中的那一堆留下平方根数量的礼物(向下取整),取走其他的礼物。
返回在 k 秒后剩下的礼物数量。
示例 1:
输入:gifts = [25,64,9,4,100], k = 4 输出:29 解释: 按下述方式取走礼物: - 在第一秒,选中最后一堆,剩下 10 个礼物。 - 接着第二秒选中第二堆礼物,剩下 8 个礼物。 - 然后选中第一堆礼物,剩下 5 个礼物。 - 最后,再次选中最后一堆礼物,剩下 3 个礼物。 最后剩下的礼物数量分别是 [5,8,9,4,3] ,所以,剩下礼物的总数量是 29 。
示例 2:
输入:gifts = [1,1,1,1], k = 4 输出:4 解释: 在本例中,不管选中哪一堆礼物,都必须剩下 1 个礼物。 也就是说,你无法获取任一堆中的礼物。 所以,剩下礼物的总数量是 4 。
提示:
1 <= gifts.length <= 1031 <= gifts[i] <= 1091 <= k <= 103
class Solution {
public:
long long pickGifts(vector<int>& gifts, int k) {
priority_queue<int>q;
long long ans=0;
for(auto x:gifts)q.push(x),ans+=x;
while(k--){
int x=q.top();
int y=int(sqrt(x*1.0));
ans-=x-y;
q.pop();
q.push(y);
}
return ans;
}
};2561. 重排水果
2568. 最小无法得到的或值
2575. 找出字符串的可整除数组
给你一个下标从 0 开始的字符串 word ,长度为 n ,由从 0 到 9 的数字组成。另给你一个正整数 m 。
word 的 可整除数组 div 是一个长度为 n 的整数数组,并满足:
- 如果
word[0,...,i]所表示的 数值 能被m整除,div[i] = 1 - 否则,
div[i] = 0
返回 word 的可整除数组。
示例 1:
输入:word = "998244353", m = 3 输出:[1,1,0,0,0,1,1,0,0] 解释:仅有 4 个前缀可以被 3 整除:"9"、"99"、"998244" 和 "9982443" 。
示例 2:
输入:word = "1010", m = 10 输出:[0,1,0,1] 解释:仅有 2 个前缀可以被 10 整除:"10" 和 "1010" 。
提示:
1 <= n <= 105word.length == nword由数字0到9组成1 <= m <= 109
class Solution {
public:
vector<int> divisibilityArray(string word, int m) {
vector<int>ans;
long long s=0;
for(auto c:word){
s=(s*10+c-'0')%m;
ans.push_back(s==0);
}
return ans;
}
};2576. 求出最多标记下标
给你一个下标从 0 开始的整数数组 nums 。
一开始,所有下标都没有被标记。你可以执行以下操作任意次:
- 选择两个 互不相同且未标记 的下标
i和j,满足2 * nums[i] <= nums[j],标记下标i和j。
请你执行上述操作任意次,返回 nums 中最多可以标记的下标数目。
示例 1:
输入:nums = [3,5,2,4] 输出:2 解释:第一次操作中,选择 i = 2 和 j = 1 ,操作可以执行的原因是 2 * nums[2] <= nums[1] ,标记下标 2 和 1 。 没有其他更多可执行的操作,所以答案为 2 。
示例 2:
输入:nums = [9,2,5,4] 输出:4 解释:第一次操作中,选择 i = 3 和 j = 0 ,操作可以执行的原因是 2 * nums[3] <= nums[0] ,标记下标 3 和 0 。 第二次操作中,选择 i = 1 和 j = 2 ,操作可以执行的原因是 2 * nums[1] <= nums[2] ,标记下标 1 和 2 。 没有其他更多可执行的操作,所以答案为 4 。
示例 3:
输入:nums = [7,6,8] 输出:0 解释:没有任何可以执行的操作,所以答案为 0 。
提示:
1 <= nums.length <= 1051 <= nums[i] <= 109
class Solution {
public:
int maxNumOfMarkedIndices(vector<int>& nums) {
sort(nums.begin(), nums.end());
int ans = 0;
for (int i = 0, j = nums.size() / 2; i < nums.size() / 2;i++,j++) {
while (j < nums.size() && nums[j] < nums[i] * 2)j++;
if (j == nums.size())return ans;
ans += 2;
}
return ans;
}
};2580. 统计将重叠区间合并成组的方案数
2581. 统计可能的树根数目
2582. 递枕头
2583. 二叉树中的第 K 大层和
2584. 分割数组使乘积互质
2586. 统计范围内的元音字符串数
2589. 完成所有任务的最少时间
2591. 将钱分给最多的儿童
给你一个整数 money ,表示你总共有的钱数(单位为美元)和另一个整数 children ,表示你要将钱分配给多少个儿童。
你需要按照如下规则分配:
- 所有的钱都必须被分配。
- 每个儿童至少获得
1美元。 - 没有人获得
4美元。
请你按照上述规则分配金钱,并返回 最多 有多少个儿童获得 恰好 8 美元。如果没有任何分配方案,返回 -1 。
示例 1:
输入:money = 20, children = 3 输出:1 解释: 最多获得 8 美元的儿童数为 1 。一种分配方案为: - 给第一个儿童分配 8 美元。 - 给第二个儿童分配 9 美元。 - 给第三个儿童分配 3 美元。 没有分配方案能让获得 8 美元的儿童数超过 1 。
示例 2:
输入:money = 16, children = 2 输出:2 解释:每个儿童都可以获得 8 美元。
提示:
1 <= money <= 2002 <= children <= 30
class Solution {
public:
int distMoney(int money, int children) {
if(money<children)return -1;
if(money>children*8)return children-1;
int ans=(money-children)/7;
if(children*8-4==money && ans>0)ans--;
return ans;
}
};2595. 奇偶位数
给你一个 正 整数 n 。
用 even 表示在 n 的二进制形式(下标从 0 开始)中值为 1 的偶数下标的个数。
用 odd 表示在 n 的二进制形式(下标从 0 开始)中值为 1 的奇数下标的个数。
请注意,在数字的二进制表示中,位下标的顺序 从右到左。
返回整数数组 answer ,其中 answer = [even, odd] 。
示例 1:
输入:n = 50
输出:[1,2]
解释:
50 的二进制表示是 110010。
在下标 1,4,5 对应的值为 1。
示例 2:
输入:n = 2
输出:[0,1]
解释:
2 的二进制表示是 10。
只有下标 1 对应的值为 1。
提示:
1 <= n <= 1000
class Solution {
public:
vector<int> evenOddBit(int n) {
int even=0,odd=0;
while(n){
if(n&1)even++;
n>>=1;
if(n&1)odd++;
n>>=1;
}
return vector<int>{even,odd};
}
};2597. 美丽子集的数目
2598. 执行操作后的最大 MEX
2599. 使前缀和数组非负
给定一个 下标从0开始 的整数数组 nums 。你可以任意多次执行以下操作:
- 从
nums中选择任意一个元素,并将其放到nums的末尾。
nums 的前缀和数组是一个与 nums 长度相同的数组 prefix ,其中 prefix[i] 是所有整数 nums[j](其中 j 在包括区间 [0,i] 内)的总和。
返回使前缀和数组不包含负整数的最小操作次数。测试用例的生成方式保证始终可以使前缀和数组非负。
示例 1 :
输入:nums = [2,3,-5,4] 输出:0 解释:我们不需要执行任何操作。 给定数组为 [2, 3, -5, 4],它的前缀和数组是 [2, 5, 0, 4]。
示例 2 :
输入:nums = [3,-5,-2,6] 输出:1 解释:我们可以对索引为1的元素执行一次操作。 操作后的数组为 [3, -2, 6, -5],它的前缀和数组是 [3, 1, 7, 2]。
提示:
1 <= nums.length <= 105-109 <= nums[i] <= 109
class Solution {
public:
int makePrefSumNonNegative(vector<int>& v) {
priority_queue<int,vector<int>, greater<int>>q;
long long ans = 0, s = 0;
for (auto x:v) {
s += x;
q.push(x);
if (s<0) {
ans++;
s -= q.top();
q.pop();
}
}
return ans;
}
};
















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









