




RoadMap: E2E → LLM → VLM → VLA → Word Mode → RL。
1. E2E
- UniAD: Planning-oriented Autonomous Driving (CVPR 2023 Best Paper);
- VAD: Vectorized Scene Representation for Efficient Autonomous Driving (ICCV 2023);
- VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning (arXiv 2024);
- GenAD: Generative End-to-End Autonomous Driving (ECCV 2024);
- DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving (CVPR 2025);
1.1. UniAD
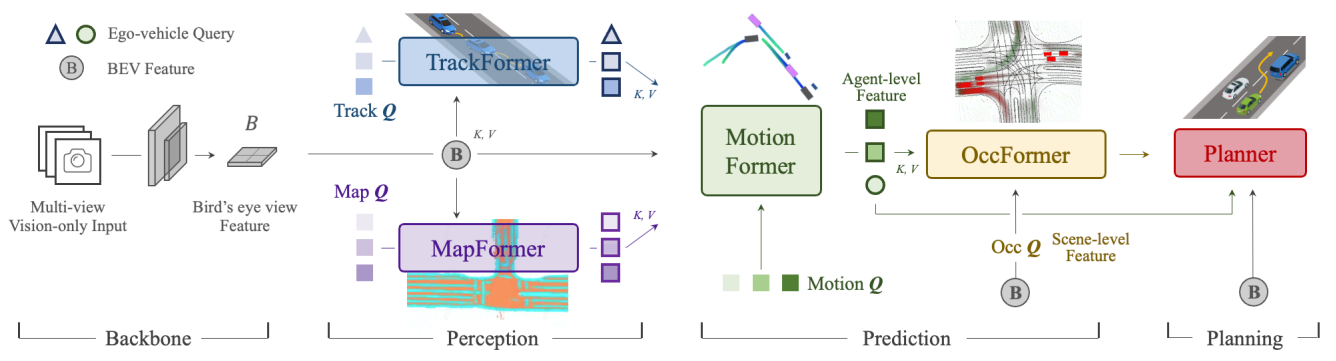
- 纯视觉。文章有说明,可以使用融合感知,只需可以同样生成BEV Feature即可。
- BackBone:CNN/ResNet。
- Encoder:BEVFormer。可替换其他网络结构。
- BEV Feature:栅格化表示(rasterized representation),各任务共享(planner也会使用BEV)。Map和Occ是栅格化表示。
- Decoder:TrackFormer、MapFormer、MotionFormer、OccFormer、Planner。
- Constraints:Planner的输出轨迹会和Occ结果一起做优化,这个是在推理阶段。
- Unified query interfaces:使用queries链接所有的任务,形成E2E。
- Train:pre-train perception parts,各个模块都训练显式监督训练。
- Limits:系统庞大,计算开销大。
1.2. VAD
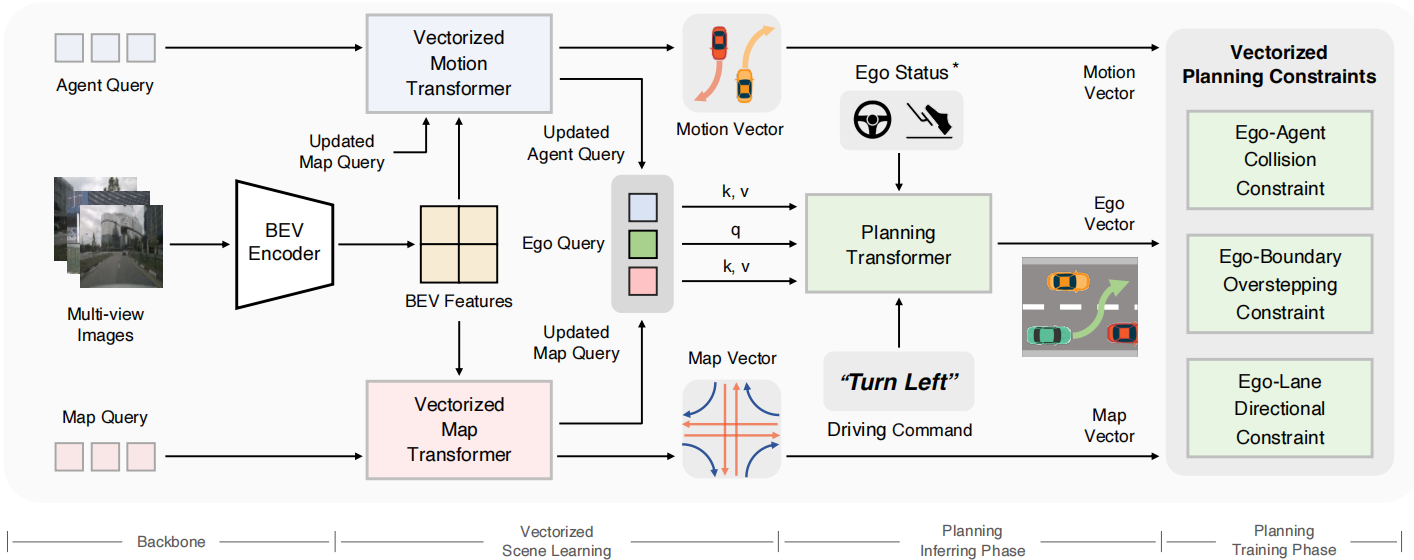
VAD的思想和UniAD有很多的一致性。首先都是纯视觉;其次,都以BEV特征为基础,通过Query链接各个任务。不同的是,VAD采用了矢量化的场景表示方式,即Map和Agents都使用vector表示,提升了计算效率和规划性能。
- 纯视觉。
- BackBone:CNN/ResNet。
- Encoder:BEVFormer。
- BEV Feature:栅格化表示(rasterized representation),Motion和Map任务共享。Planning部分不再直接使用BEV Feature,而是使用Motion和Map的输出。
- Vectoried Scene Representation:矢量化场景表示。Motion、Map和Planning的输出都是矢量。
- Decoder:Motion Transformer、Map Transformer和Planning Transformer。网络结构比UniAD更简单。不需要Tracking和Occ Prediction。
- Constraints:Planner的输出轨迹会进行agent碰撞约束、地图行驶域约束和车道方向约束,这个是在训练阶段。
- Unified query interfaces:使用queries链接所有的任务,形成E2E。
- Train:所有模块一起训练(可以pre train perception),各个模块都训练显式监督训练。
- Limits:没有利用多模态预测结果;没有充分利用交通信息。
1.3. VADv2
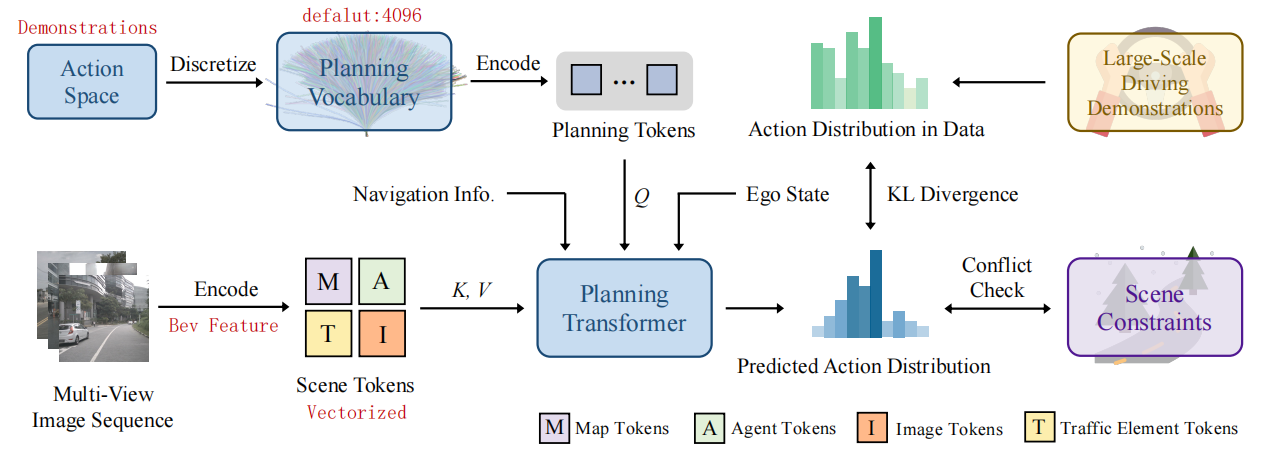
VADv2延续了VAD的矢量化表示,引入了规划动作空间的概率建模,将规划问题建模为概率分布问题,强调了多模态规划能力,推理灵活,可采样多条候选轨迹,易于和传统规则/优化方法结合。
- 纯视觉。
- BackBone:CNN/ResNet。
- Encoder:BEVFormer。
- BEV Feature:栅格化表示(rasterized representation),Motion和Map任务共享。Planning任何不再直接使用BEV Feature,而是使用Motion和Map的输出。
- Vectoried Scene Representation:矢量化场景表示。Motion、Map、Traffic element和Planning的输出都是矢量。
- Decoder:Motion Transformer、Map Transformer和Planning Transformer。网络结构比UniAD更简单。不需要Tracking和Occ Prediction。
- Planning vocabulary:使用训练数据采样。
- Constraints:通过KL散度提升planning vocabulary中轨迹和训练数据分布概率的一致性,通过约束(和VAD一样)抑制违反约束的轨迹的概率。
- Unified query interfaces:使用queries链接所有的任务,形成E2E。
- Train:所有模块一起训练(可以pre train perception),各个模块都训练显式监督训练。
- Limits:没有体现出交互;vocabulary数量对计算效率的影响。
1.4. GAD
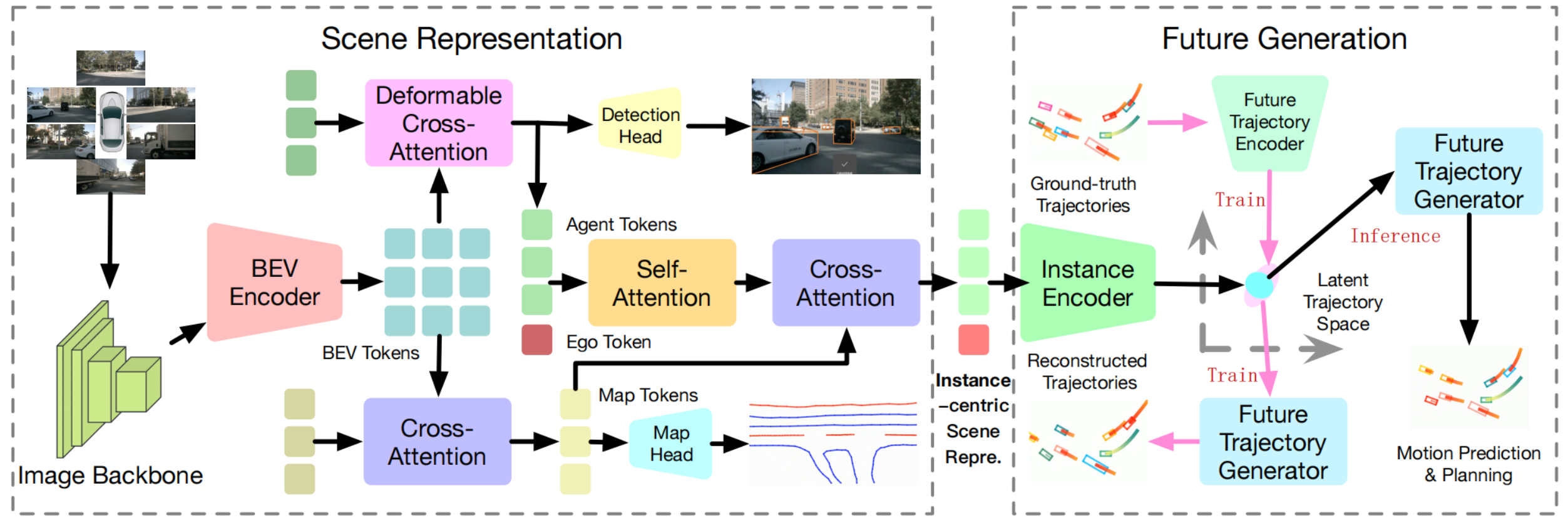
以前的端到端模块化为“perception -> prediction -> planning”的pipeline,忽略了主车和其他交通参与者的交互。GAD在VAD的基础上,使用生成模型VAE(Variational Autoencoder)来同时生成主车轨迹和他车预测轨迹,并处理不确定性和多模态。
VADv2是通过planning vocabulary来处理不确定性和多模态,而GAD是使用VAD生成连续的先验轨迹的潜空间变量的高斯分布。
- 纯视觉。
- BackBone:CNN/ResNet。
- Encoder:BEVFormer。
- BEV Feature:栅格化表示(rasterized representation),Detection和Map任务共享。
- Vectoried Scene Representation:矢量化场景表示。和VAD类似,通过query/token链接不同的任务。
- Decoder:Detection Transformer、Map Transformer和Scene Transformer。感知任务和VAD基本一致。
- VAE:使用VAE生成模型,建模潜在空间变量的概率分布。
- Loss:和VAD(v2)基本类似。
- Unified query interfaces:使用queries/token链接所有的任务,形成E2E。
- Train:所有模块一起训练(可以pre train perception),各个模块都训练显式监督训练。在推理阶段,丢弃掉对真实轨迹的编码和解码。
- Limits:性能着重与VAD-tiny对比;不是真正的交互,是联合建模,planning和prediction共享了latent space。
1.5. DiffusionDrive
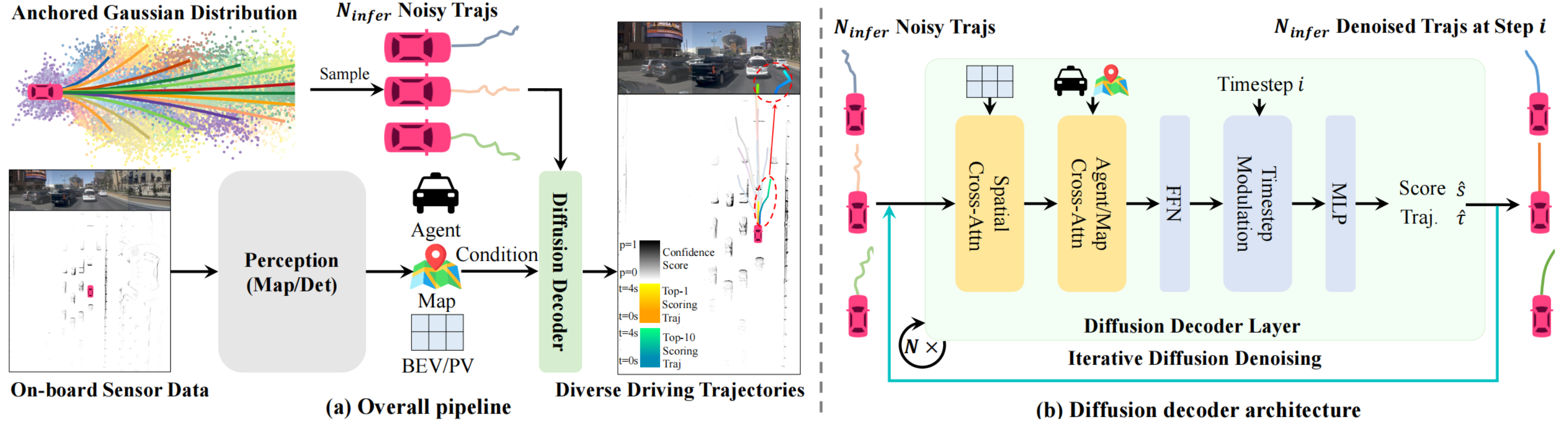
DiffusionDrive使用”perception -> planning“的pipeline,perception遵循的以往的设计范式,在planning模块使用了扩散模型表达驾驶行为的不确定性和多模态特性。由于扩散模型从高斯分布的随机噪声去噪过程计算耗时,且生成轨迹高度近似,DiffusionDrive通过Anchored Gaussian Distribution,使用人类驾驶数据集聚类生成锚点轨迹,只加少量噪声,然后再去噪,步数少,速度快,并且保持了轨迹的多样性。
- 纯视觉,或者多传感器融合,只要生成BEV Feature即可;
- BackBone:ResNet;
- Encoder:BEVFormer;
- Decoder:Diffision decoder,采用了扩散模型;
- Diffusion mode:
-
- Anchored Gaussian Distribution:使用人类驾驶数据集,采用K-means anchors,生成一组锚点,每个锚点就是一条典型的驾驶轨迹;推理时的锚点数量可以少于训练时锚点数量;
- Truncated Diffusion:在anchor上只加少量噪声(truncated schedule),而不是完全扩散到随机高斯;
- Loss:只对主车轨迹做了监督学习,没有对agent预测轨迹;论文没有描述是否对感知任务采用辅助监督学习;
- Limits:没有体现出交互;极端环境需要更多的采样轨迹和去噪过程;
1.6. 总结
UniAD使用统一的query将各个任务链接起来,VAD采用了矢量化建模提高了计算效率,VADv2进一步引入规划动作空间的概率建模,将规划问题建模为概率分布问题,GAD采用VAE生成连续的规划动作空间,而DiffusionDrive又引入了先验驾驶行为。端到端的pipeline从"perception -> prediction -> planning"到"perception -> planning",planning集成预测和规划任务。perception任务的核心是BEV feature,以纯视觉为主。plannning任务从简单的MLP解码结构,发展到生成模型,以充分表达驾驶行为的不确定性和多模态特性。
2. LLM
- Drive Like a Human: Rethinking Autonomous Driving with Large Language Models(IEEE/CVF 2024)
- DiLu: A Knowledge-Driven Approach to Autonomous Driving with LLM(ICLR 2024)
两篇论文都是上海AI Lab的工作,DiLu是第一篇论文的后续工作。
2.1. Drive Like a Human
类人驾驶需要三种核心能力:
- Reasoning(推理能力):模型面对具体的驾驶场景,能够通过常识和经验做出决策。
- Interpretation(可解释能力):模型做出的决策能够被解释。
- Memorization(记忆能力):在推理和解释场景后,需要记住过往的经验,以便在遇到类似情境时做出类似决策。
LLMs,例如GPT,具有以上三种能力,文章在HighwayEnv中使用GPT-3.5构建了闭环仿真,探索LLM能否像人一样理解交通场景,并处理长尾问题。
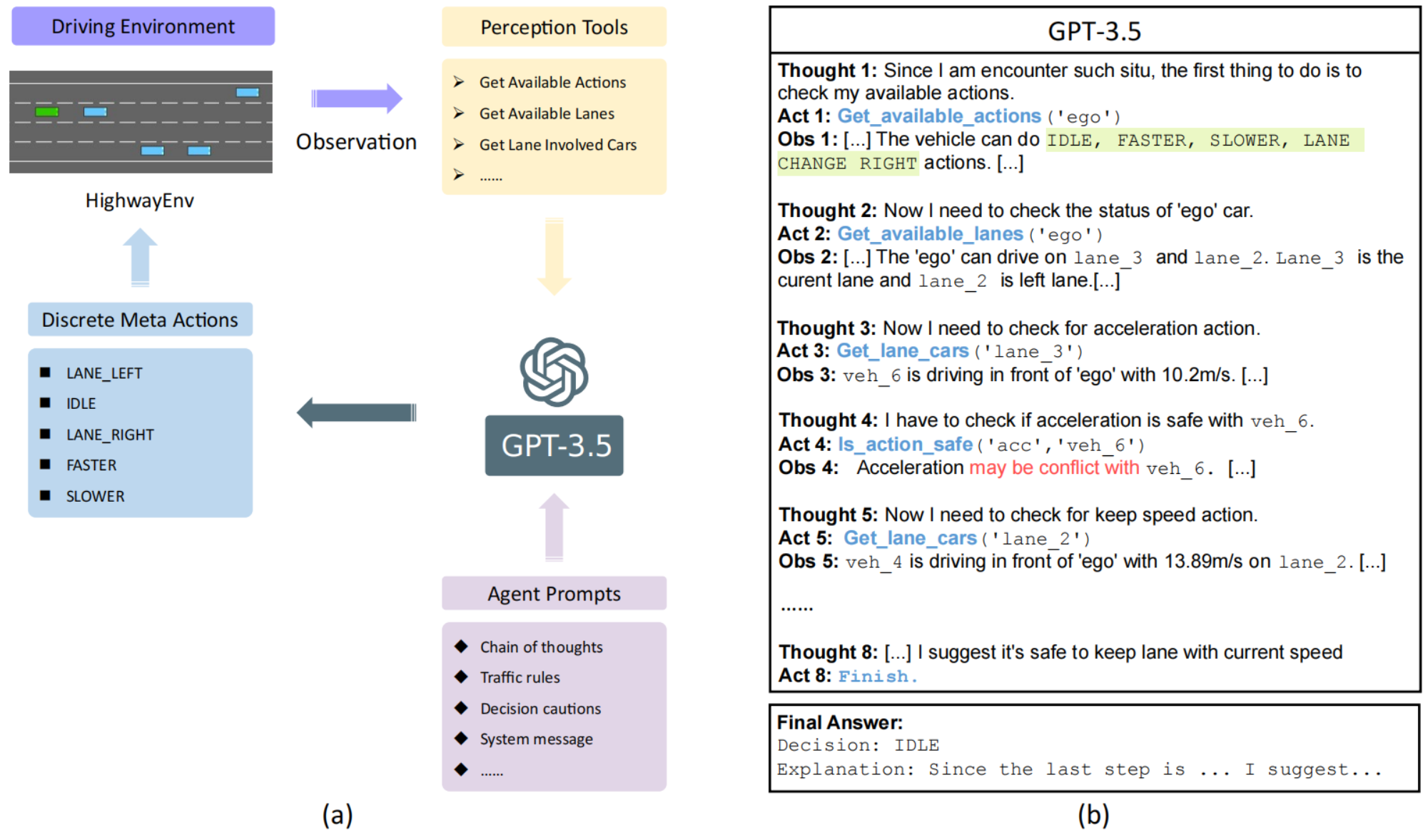
GPT-3.5是文本模型,无法直接操作仿真环境,因此使用LangChain(大语言模型应用开发框架),调用Percaption Tools,根据Agent Prompts使用ReAct(Reasoning+Acting)策略,在”思考(Thouhgt) →行动(Action)→观察(Observation)“循环中分析周围环境,进行决策,生成预定义的决策(Discrete Meta Actions)。
- Agent Prompts:
-
- 明确自动驾驶决策时的规则与约束(如保持车距、不频繁变道);
- 规定”工具使用“的交互方式(Thought→Action→Observation→Final Answer);
- 避免模型输出模糊或者矛盾的答案,必须使用
Final Answer明确标注唯一答案; - 通过
SYSTEM_MESSAGE_PREFIX/SUFFIX/HUMAN_MESSAGE组织成一套完整的 system prompt + human prompt 模板,用于 ChatGPT 风格的链式推理(CoT, Chain-of-Thought)+ Tool-Use。
- Perception Tools:
-
- LLM可以使用的工具,并告诉LLM如何使用;
- 可用工具有:
-
-
- 获取可用动作(换道/加速/减速/保持车速等);
- 获取某车辆可用车道;
- 获取某车道上和ego相关车辆;
- 判断换道、加速、减速、保持车速是否会和其他车辆冲突;
-
文章直接使用GPT-3.5,没有进行微调,利用Prompts进行驾驶决策。由于LLM只能输入文本,需要使用语言对环境信息进行详细描述,并借助工具进行驾驶行为决策,工具的规则条件是人工手写的。显然LLM并没有针对驾驶场景进行微调,并容易受到”工程师“手写规则的影响。
2.2. DiLu
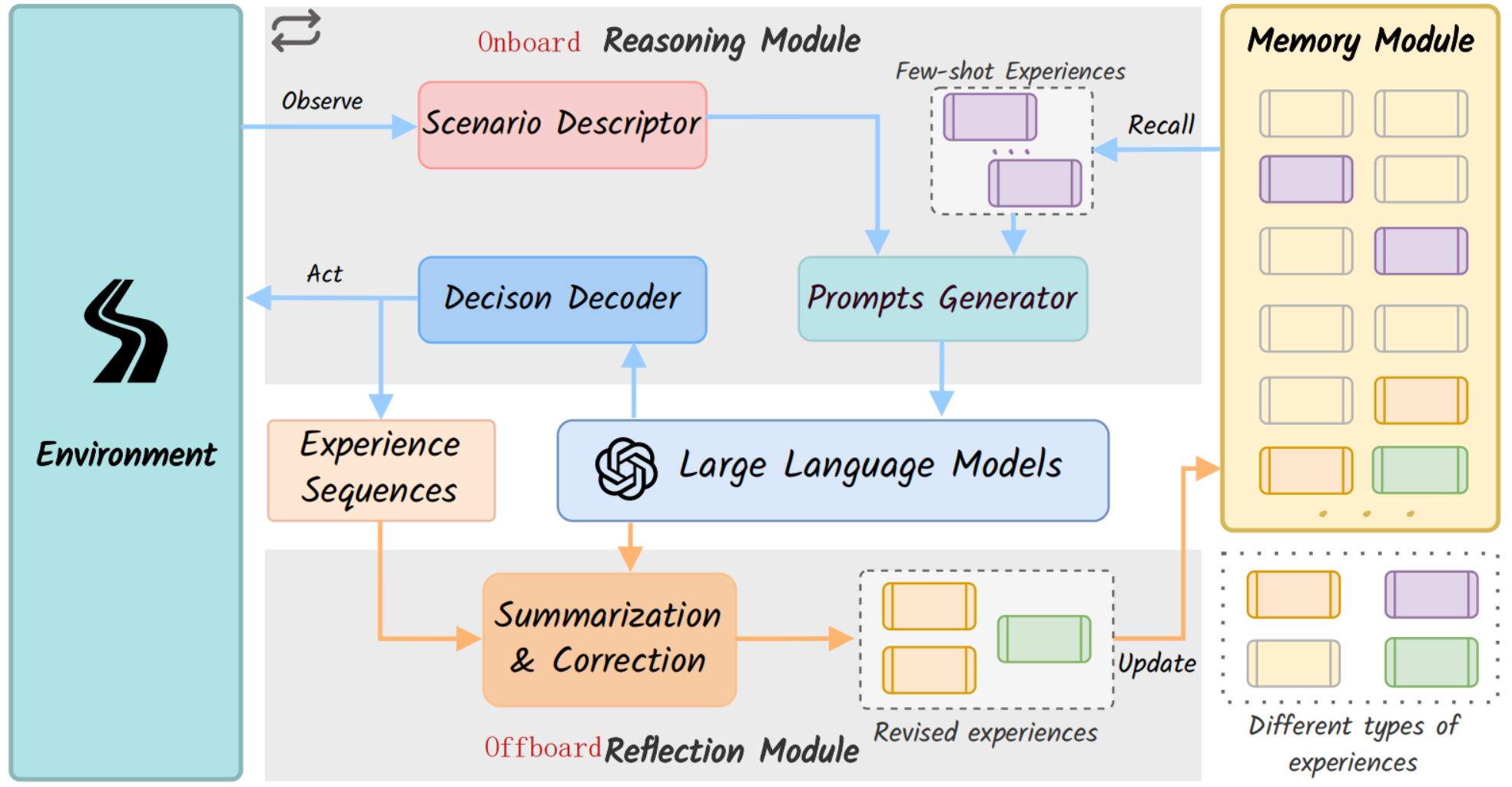
DiLu架构有4个模块:
- Environment(环境)
-
- 提供驾驶场景信息;
- Driver Agent从中观察并获得当前场景描述;
- Reasoning(推理)
-
- 输入:环境描述+从Memory模块检索到的few-shot(少样本学习)类似经验;
- 处理:
-
-
- Prompt Generator将场景描述与经验结合生成prompt;
- 将prompt输入LLM,利用LLM的常识与推理能力生成初步决策;
- Decision Decoder将LLM的输出解码为具体动作;
-
-
- 输出:时间序列的决策序列。
- Reflection(反思)
-
- 对Reasoning模块产生的决策序列进行安全性评估;
- 将unsafe决策修正为安全可执行的动作;
- Memory(记忆)
-
- 存储安全或者修正后的决策,用于future retrieval;
- 支持推理模块生成基于历史经验的few-shot prompts,形成闭环学习。
2.2.1. Memory
- Memory Initialization(初始化)
-
- 类似于人类学车前培训,手动挑选一些典型场景,标注正确的决策和推理过程,这些初始化记忆构成Memory模块的“种子”,为LLM提供初步的驾驶逻辑。
- Memory Recall(记忆检索)
-
- 在每个决策时刻,将当前场景描述为文本,然后将文本嵌入成向量,作为memory key,在Memory中搜索,找到最相似的场景及其对应的推理过程。
- 检索出的历史经验(few-shot examples)作为LLM参考示例,指导复杂场景下做出合理决策。
- few-shot作用:让LLM不必从零推理,提供类似场景的决策模板,提升闭环驾驶任务精度。
- Memory Storage(记忆存储)
-
- 当LLM做出正确决策或者通过Reflection模块修正决策后,将当前场景文本描述嵌入向量作为key,与推理过程配对存储到Memory模块;
- 系统不断累积经验,形成持续学习能力。
2.2.2. Reasoning
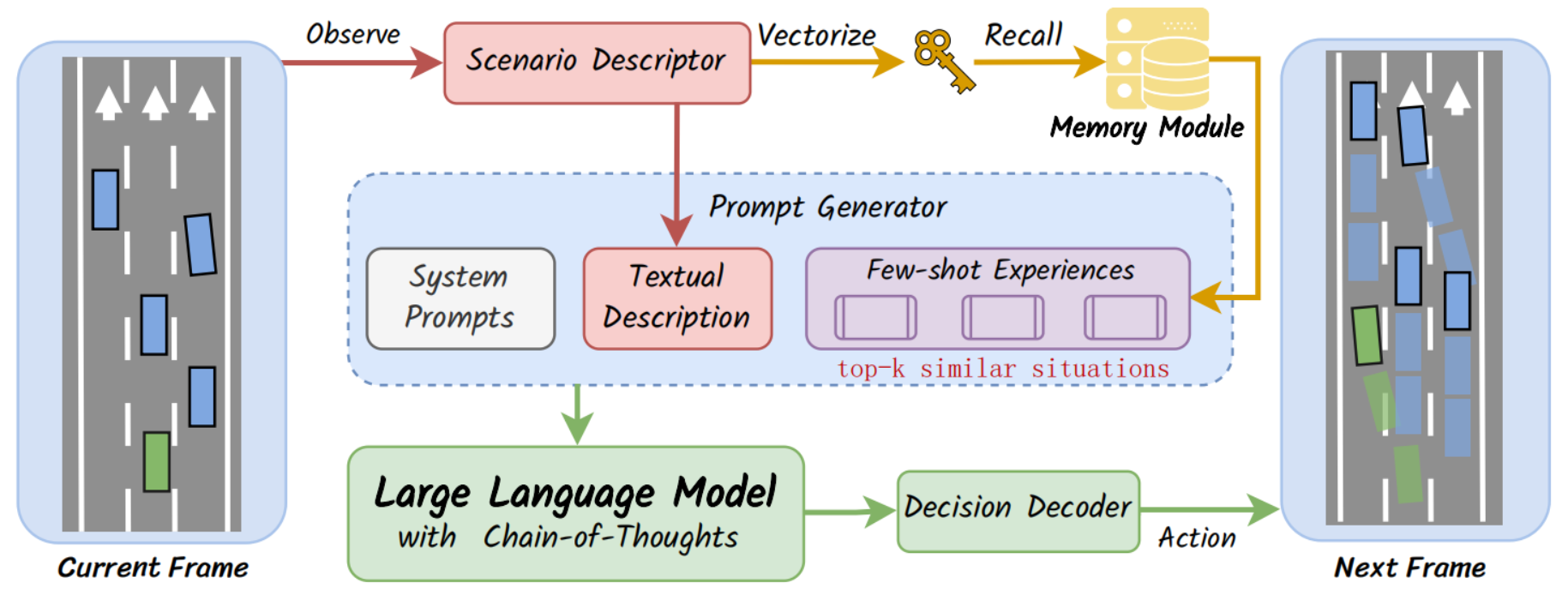
Reasoning模块有5步操作:
- 场景编码:将当前驾驶环境转成自然语言描述,即作为prompt输入,又作为Memory模块的检索key;
- 检索经验:将场景描述文本嵌入向量,在Memory中搜索Top-k最相似场景,拿到他们的场景描述和推理过程,作为few-shot experiences,帮助LLM参考过去经验;
- 生成提示词:System prompt(驾驶规则,输入输出格式等)、当前场景描述和few-shot经验。每个决策帧都会生成定制化prompt,保证场景相关性;
- 输入LLM推理:使用CoT推理,输出一段逐步的逻辑推理文本,最后得到决策;
- 解码行动:把LLM输出文本转化可执行的驾驶动作。
2.2.3. Reflection
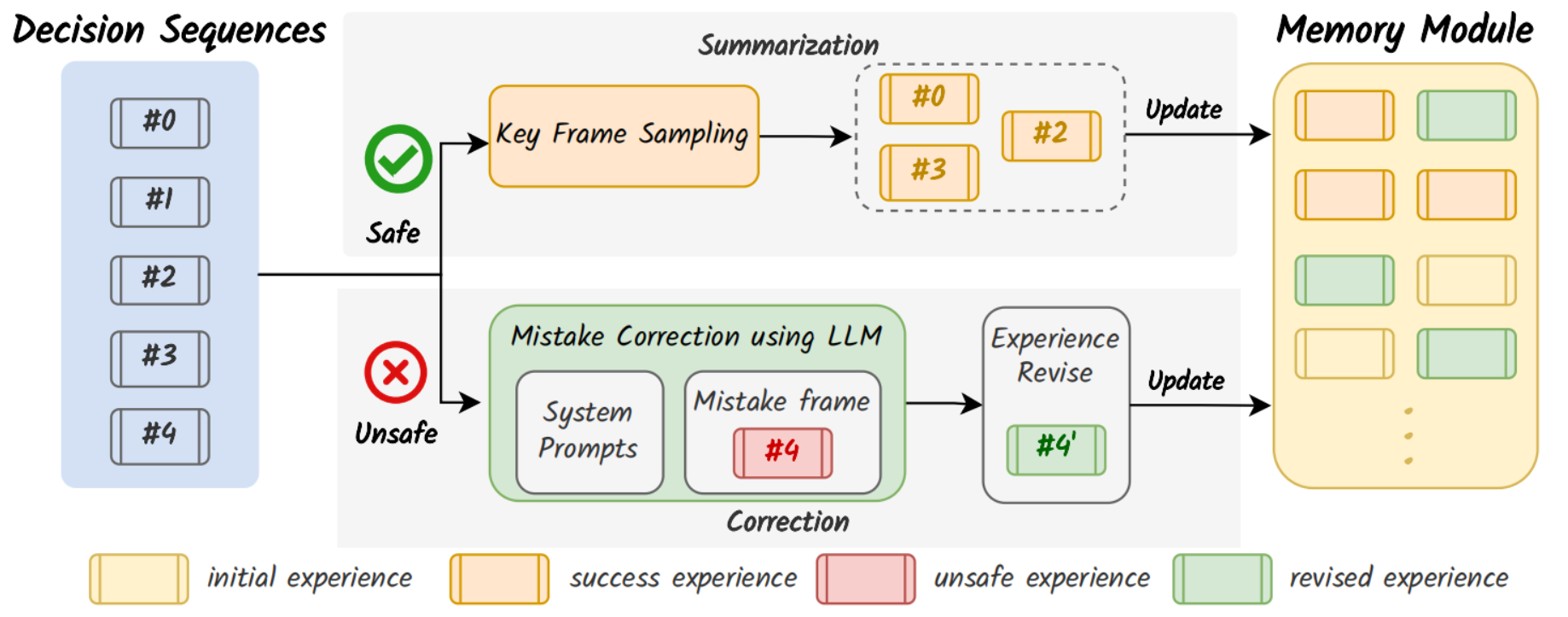
驾驶任务结束后,Reflection记录推理过程和决策序列,成功的驾驶行为会直接存储为经验,失败的驾驶经验需要进行修正后存储。这部分可以人工标注,或者自动化。
2.2.4. Limits
- 决策延迟:每次决策约5~10s(LLM推理和API调用);
- 幻觉问题。
2.3. 总结
LLM利用常识和推理能力提升驾驶能力,但是并未对LLM进行微调,需要详细设计的prompt。此外,由于LLM是文本模型,需要将驾驶场景转化为描述文本,在推理过程中需要使用API理解环境,输出同样是决策序列文本描述,需要转化为驾驶行为指令。所以,LLM即可以与传统的模块化的系统结合,也可以和E2E系统结合作为参考,但是不能参与到训练过程中,不能针对驾驶场景训练学习。此外,存在推理速度慢和幻觉问题。
3. VLM
- Learning Transferable Visual Models From Natural Language Supervision (ICML 2021)
- DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models(CoRL 2024)
- DriveGPT4: Interpretable end-to-end autonomous driving via large language model(RAL 2024)
- Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving(arXiv 2024)
- VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision(CoRL 2025)
3.1. CLIP
博客:https://openai.com/index/clip/
CLIP, a milestone image-text matching work in VLMs, captures image feature representations associated with language and achieves zero-shot transfer ability by training on a vast number of image-text pairs through contrastive learning.
--- Vision Language Models in Autonomous Driving: A Survery and Outlook
计算机视觉系统通过预定义的对象类别进行训练,需要新的标注数据才能鉴别新的对象。CLIP从互联网收集4亿个图像-文本对,从零学习图像和文本的内容的匹配关系,预训练完成后,可以实现零样本迁移。
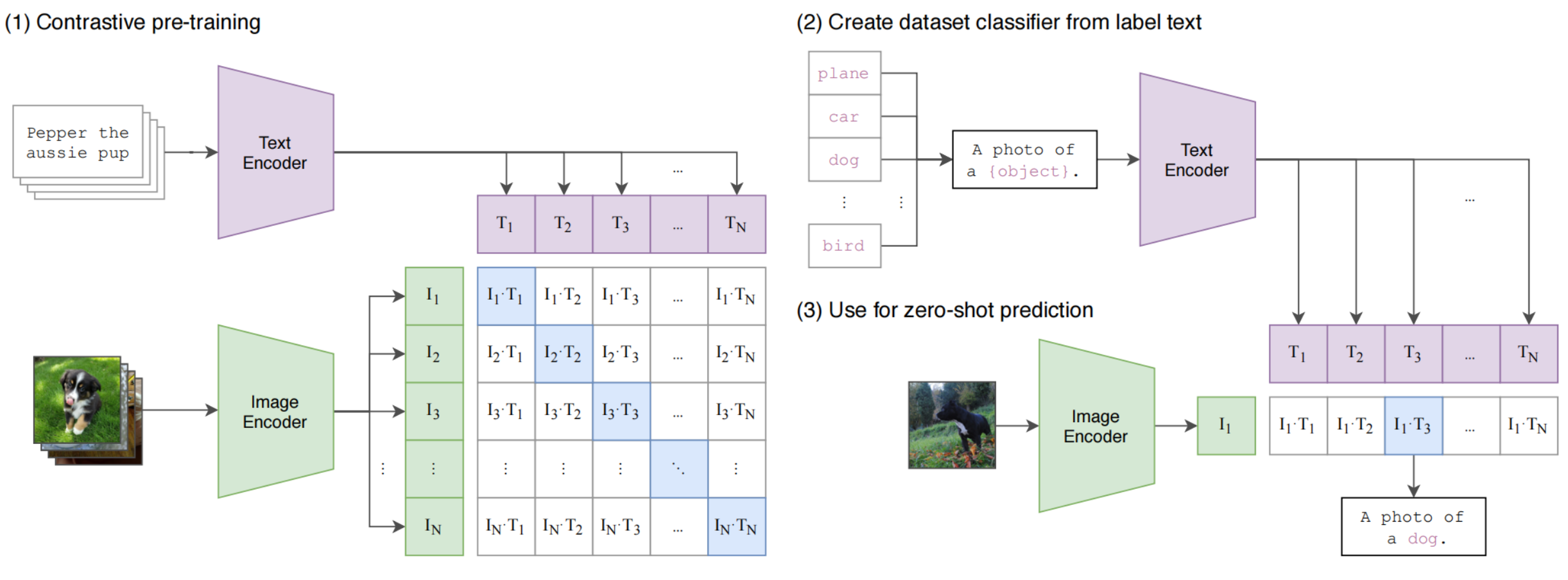
3.1.1. 对比预训练阶段(Contrastive Pre-training)
- 正样本采样:同一批次内图文匹配采样作为正样本;
- 负样本采样:同一批次内图文不匹配采样作为负样本;
- Image Encoder:将图像转换为特征向量,ResNet/ViT;
- Text Encoder:将文本转换为特征向量,Transformer;
- 对比学习:最大化矩阵中对角元素的余弦相似度,最小化其他元素的余弦相似度;
3.1.2. 零样本分类器生成(Create Dataset Classifier)
- 标签文本模板化:将目标数据集的类别通过prompt转换为自然语言描述;
- 文本编码器嵌入:通过预训练好的本文编码器,将这些模板化描述转换为类别特征向量;
3.1.3. 零样本预测(Zero-shot Prediction)
将图像编码后,与所有的文本向量计算余弦相似度,选择相似度最高的文本原型对应的类别作为预测结果。
多数VLM或者VLA模型采用Qwen-VL作为基座模型,Qwen-VL采用OpenCLIP作为视觉编码器,而OpenCLIP则是LAION团队开发的CLIP的开源版本。
3.2. DriveVLM
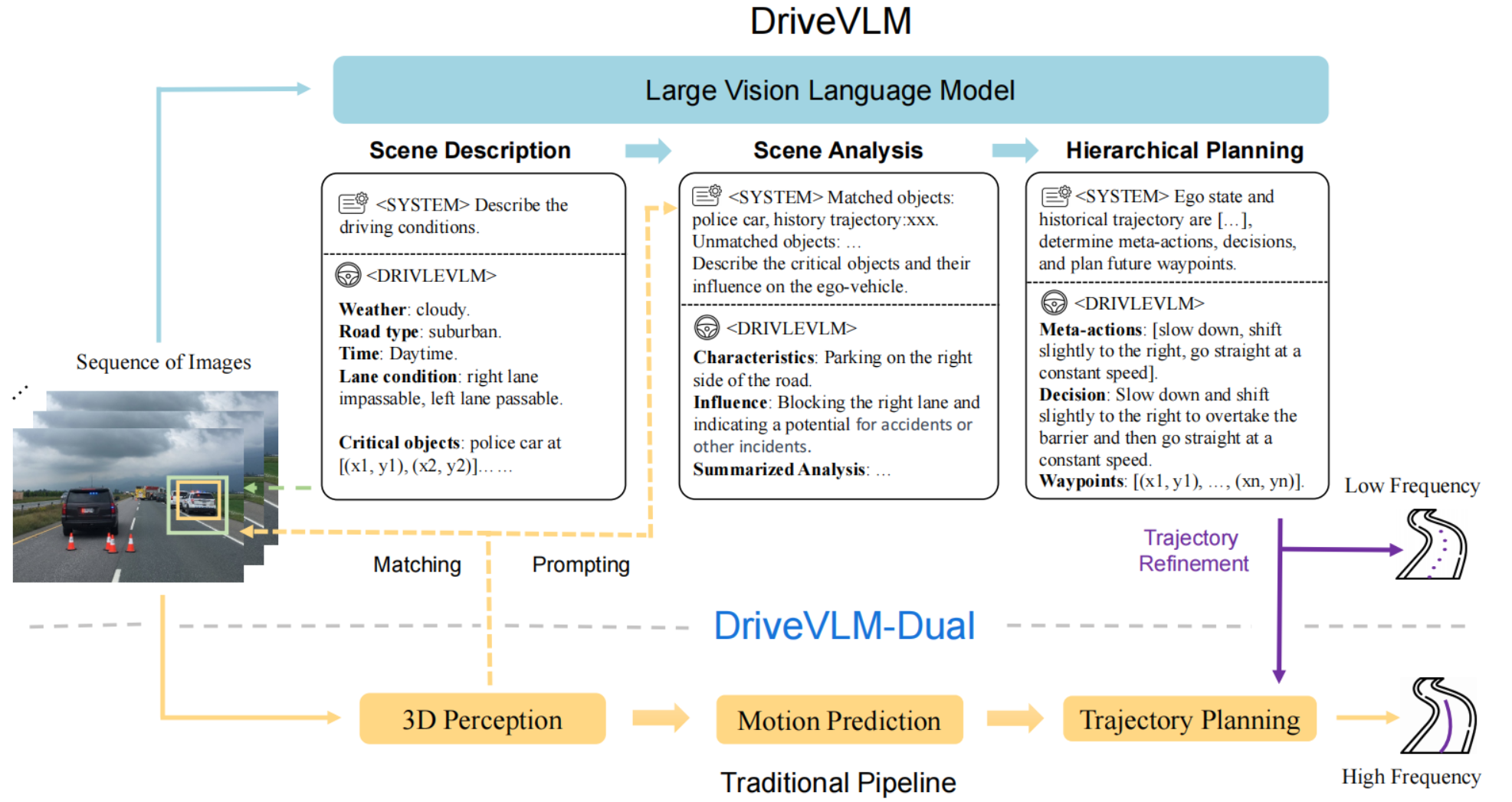
DriveVLM使用Qwen-VL作为基座模型,通过使用驾驶数据集微调和prompt设计,使LLM更好的理解驾驶场景并做出决策。和传统(规则+优化)/E2E结合,使用感知结果提升LLM的空间推理能力和提升计算性能。
- 快慢双系统设计,如果是规则+优化方法,DriveVLM输出参考轨迹给轨迹优化器。如果是和E2E方法结合,则输出参考轨迹的token。
- 使用传统方案的感知模块的输出提升VLM的空间理解能力。
- 设计了驾驶场景的数据挖掘、标注和VLM对驾驶场景描述和分析的评估方法。
3.3. DriveGPT4
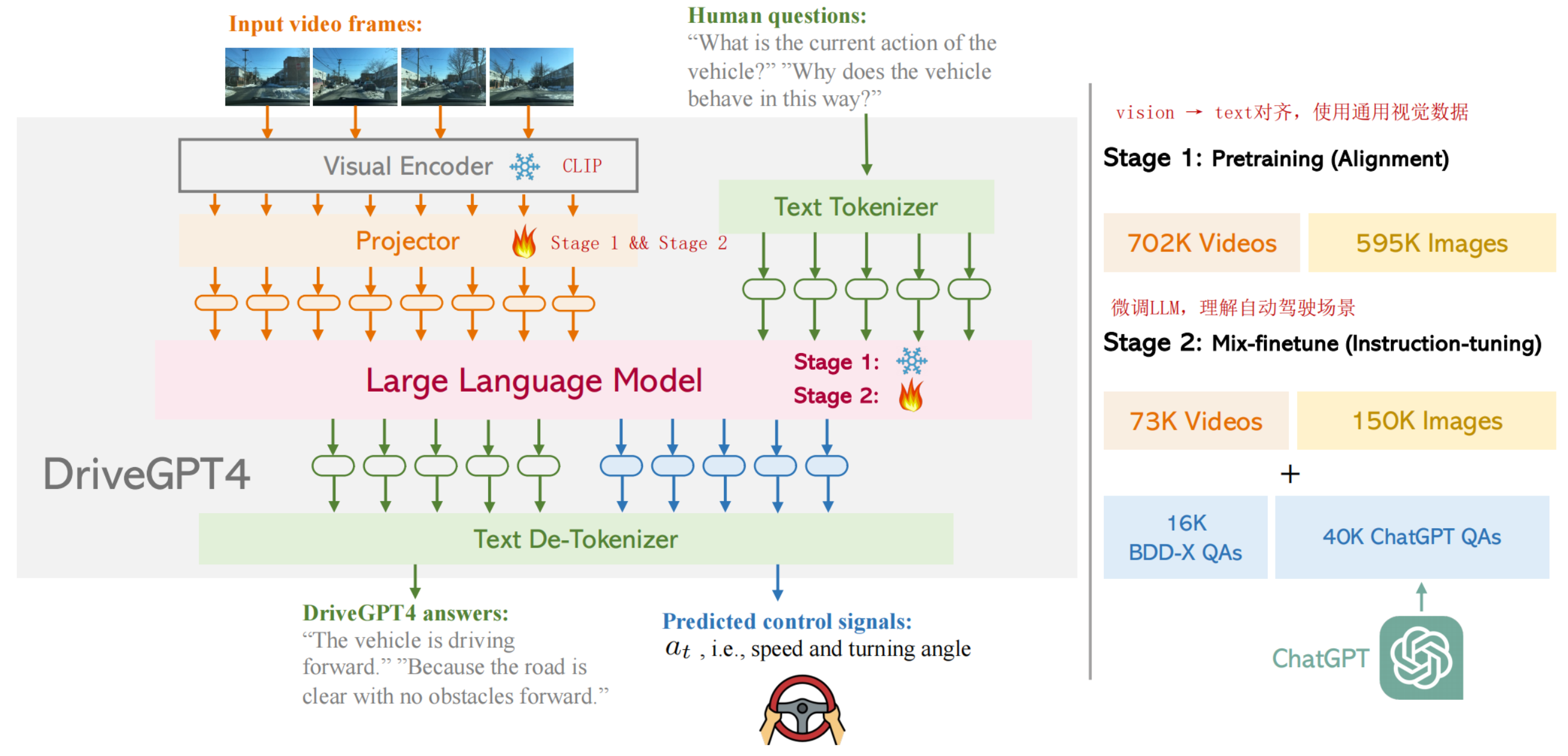
DriveGPT使用LLaMa2作为基座模型,视频、文本、车辆信号等作为输入,统一转换到text domain tokens输入给LLM,LLM输出的关于回答和控制指令的预测tokens解码成文本。
从架构中可以看到,video会抽帧image,使用预训练的CLIP编码,N帧图像再映射到文本空间,这个Projector在训练的第一个阶段使用通用视觉数据对齐到文本。在第二个训练阶段和LLM一起微调,使用自动驾驶数据,使LLM理解自动驾驶场景。
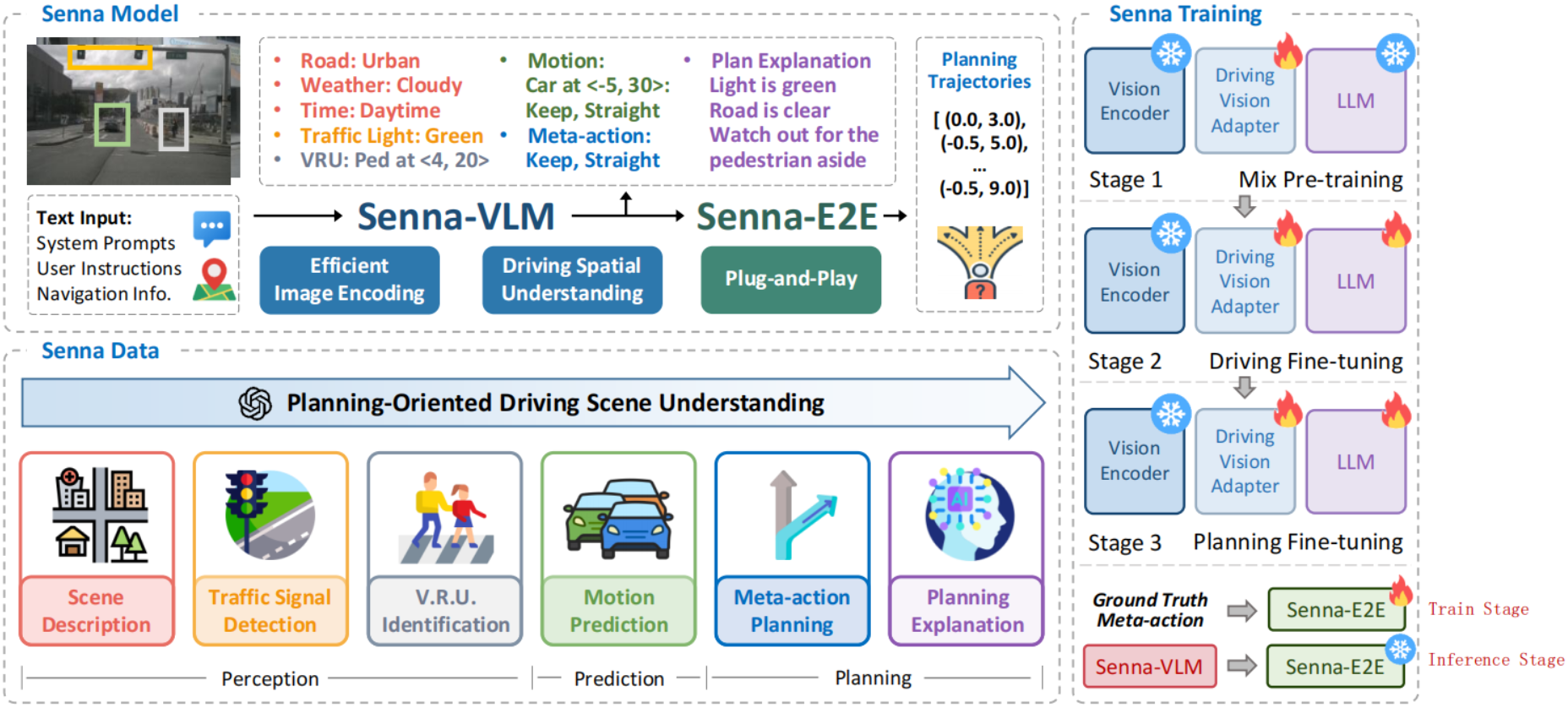
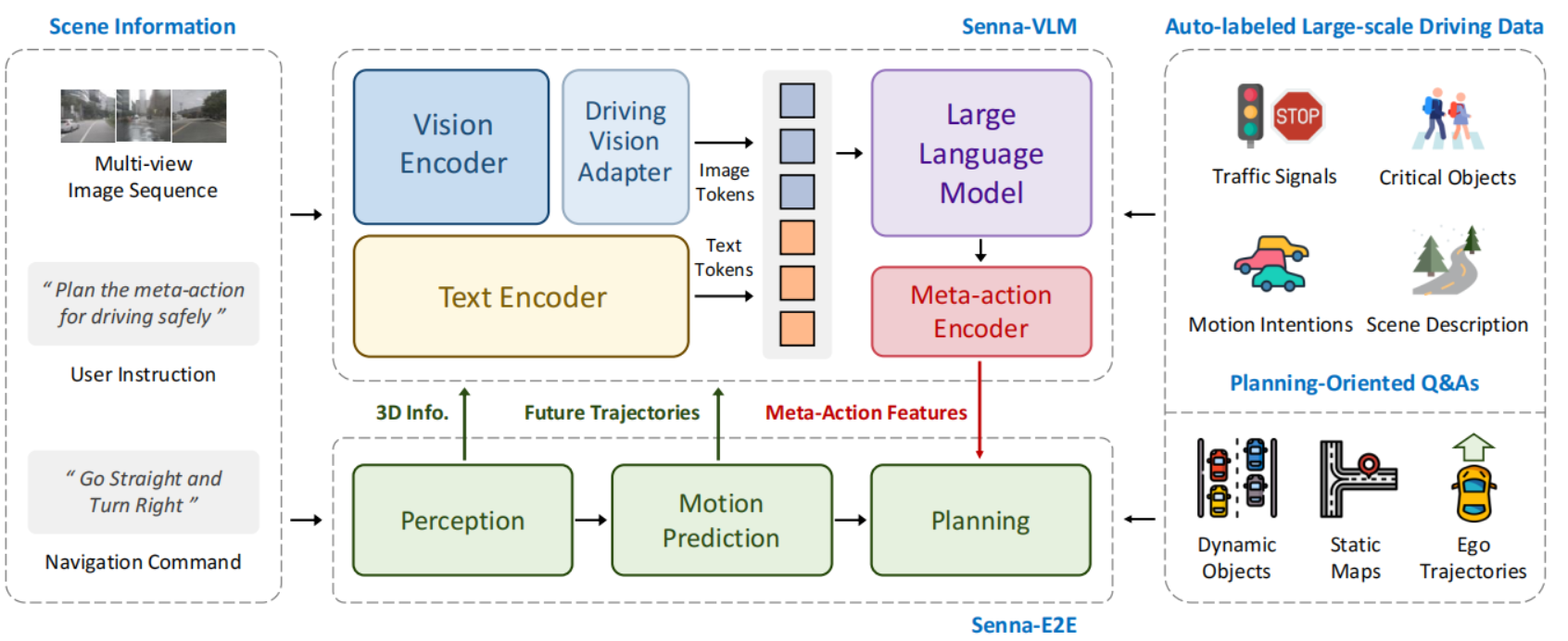
3.4. Senna
Senna论述VLMs模型的三个问题:
- VLMs在精确的数值计算方面存在局限,不适合直接输出轨迹;
- VLMs缺乏多帧图像理解能力,尤其是自动驾驶场景的环视图像理解;
- VLMs的自动驾驶训练数据主要针对环境理解,而不是以规划为导向,并且常用两阶段微调策略并非最优策略;
因此,Senna做出三点改进:
- Senna-VLM输出高层规划决策,而不是规划轨迹;
- Senna-VLM针对多帧环视图像,设计Driving Vision Adapter,对图像token压缩,并设计了环视专用prompt,提升自动驾驶场景理解能力;
- Senna-VLM提出三阶段训练,并对数据集设计了一系列规划导向问答。
-
- Mix Pre-training:其他模块参数保持冻结,使用单张图像数据训练 Driving Vision Adapter, 将图像特征映射到 LLM 的特征空间。
- Driving Fine-tuning:基于规划导向的 QAs(除去 meta-action QAs)微调 Senna-VLM,输入改为多视角图像序列(surround-view)而不是单张图像,在此阶段,Senna-VLM 除 Vision Encoder 外,所有参数都参与微调。
- Planning Fine-tuning: Vision Encoder 保持冻结,使用仅 meta-action QAs 对 Senna-VLM 进一步微调,提升高层规划能力。
- Senna-E2E 的训练与推理:
-
-
- 训练阶段:使用真实的 ground truth meta-actions 作为输入
- 推理阶段:使用 Senna-VLM 预测的 meta-actions 作为输入
-
3.5. VLM-AD
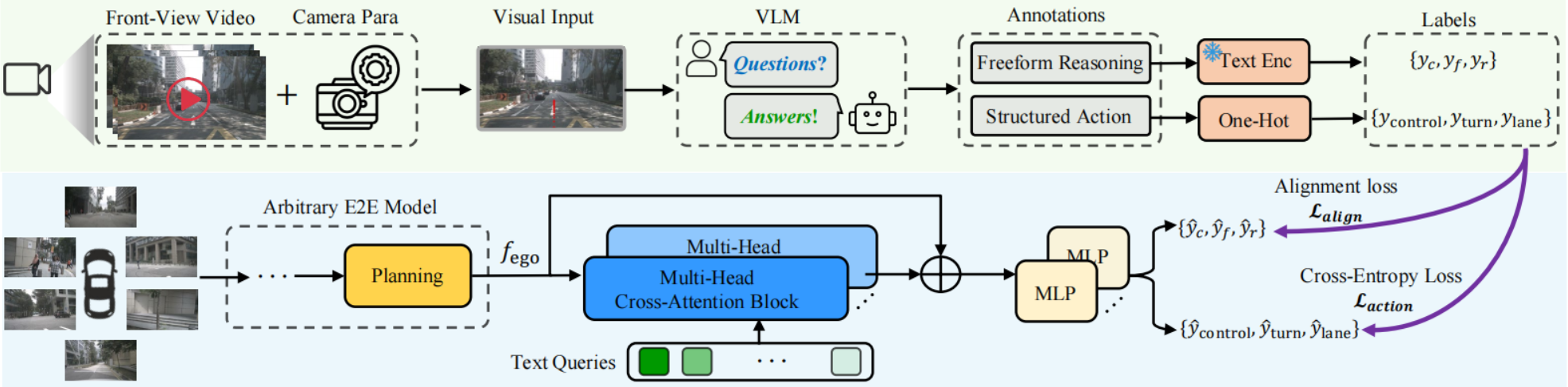
VLMs在线推理耗时,因此VLM-AD将VLMs作为teacher,先离线生成推理标注,再通过辅助任务对E2E模型进行辅助监督训练,可以使E2E学习到推理过程。并且是一种通用插件,不会修改原E2E模型,并且在推理过程中无需VLMs。
3.6. 总结
VLMs可以直接对齐图像和文本,识别自动驾驶环境,但是需要进行数据挖掘、标注和prompt设计。此外,VLMs的推理耗时太大,VLMs结果只是作为一种参考。
4. VLA
- OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model(arXiv 2025)
- LMDrive: Closed-Loop End-to-End Driving with Large Language Models(CVPR 2024)
- SimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment(CVPR 2025)
- CarLLaVA: Vision language models for camera-only closed-loop driving(CVPR 2025)
- ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation(arXiv 2025)
- Discrete Diffusion for Reflective Vision-Language-Action Models in Autonomous Driving(arXiv 2025)
4.1. OpenDriveVLA
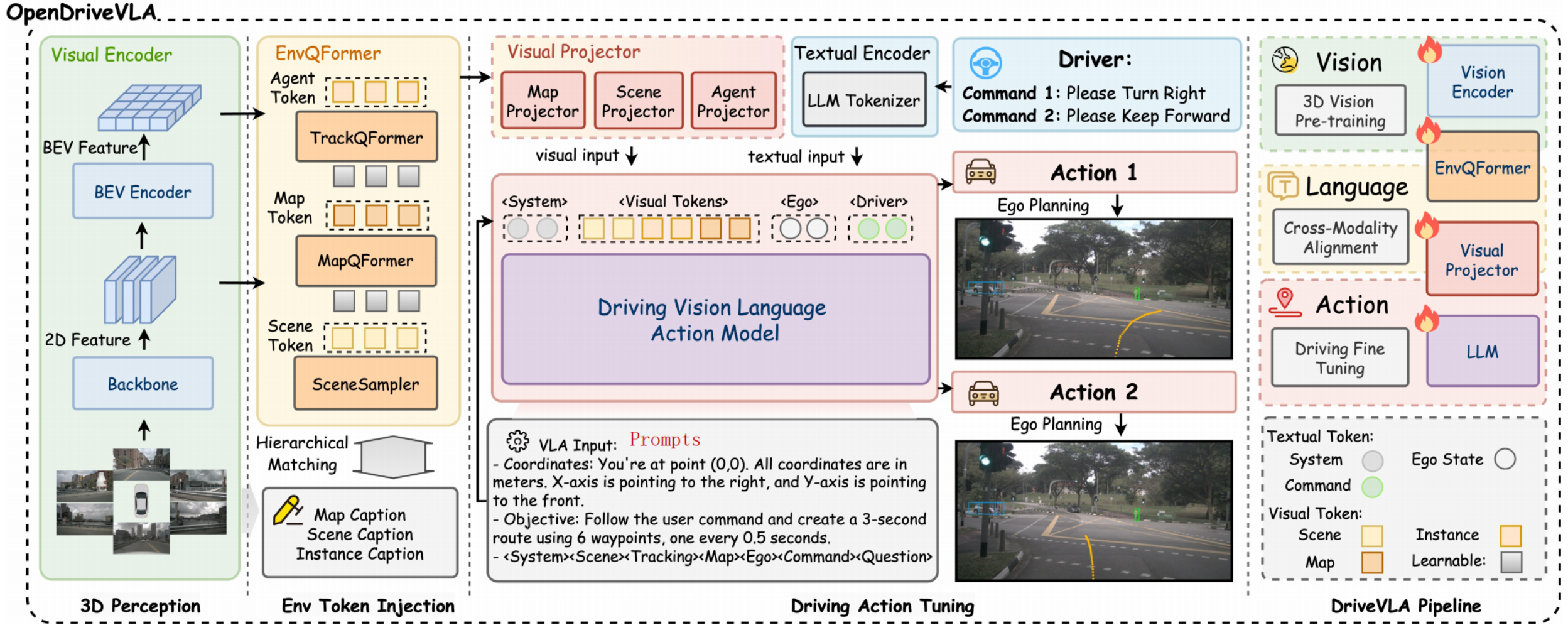
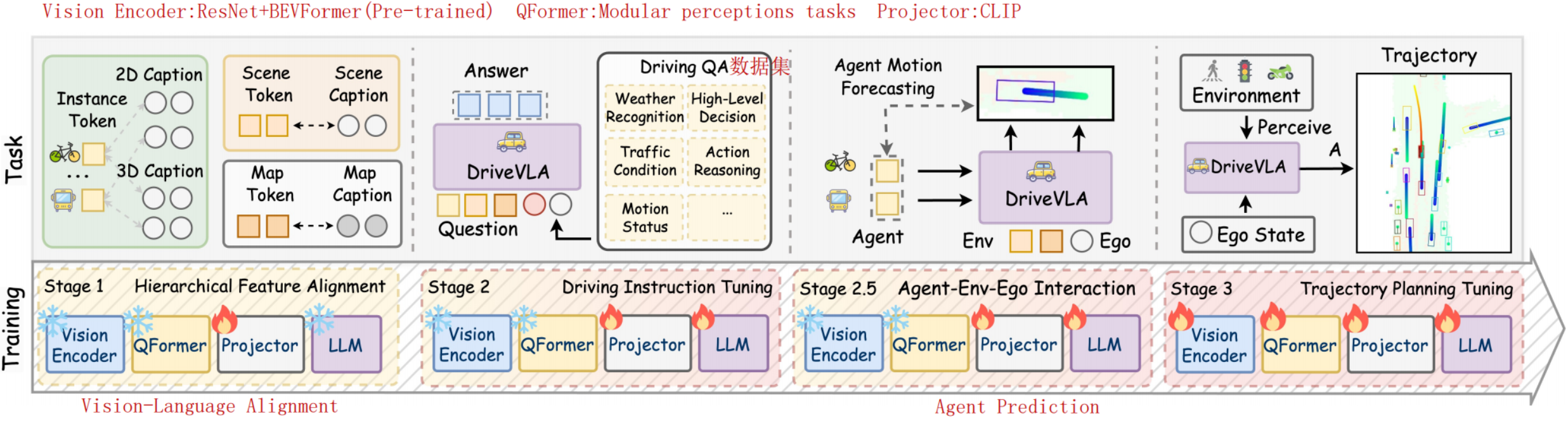
OpenSource or OpenLoop?
VLMs的空间理解能力不足,因此OpenDriveVLA构建BEV Feature,然后进行perception、map和prediction任务增加空间感知能力。
4.2. LMDrive
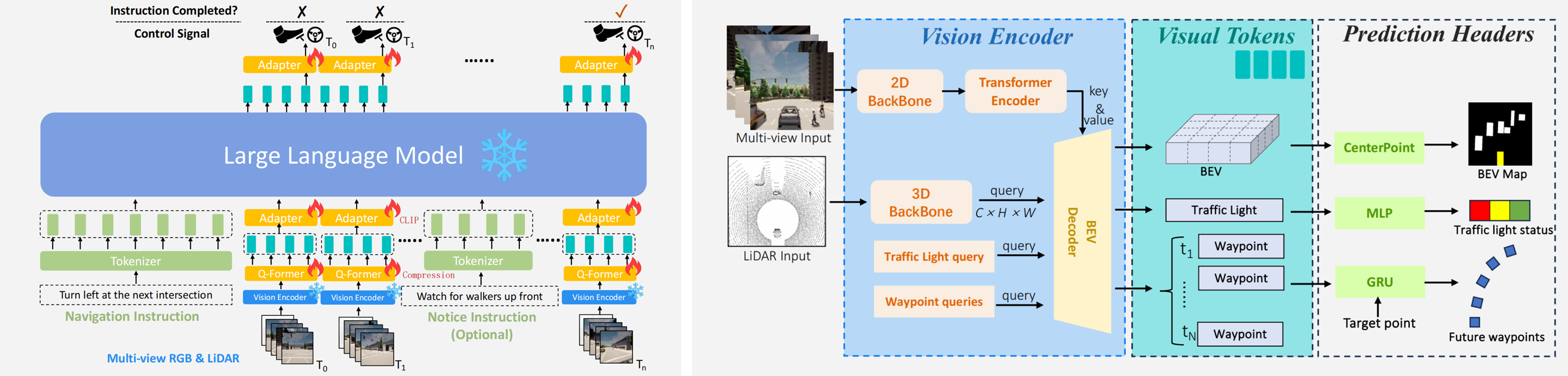
Two-Stage Trainning:
- Vision encoder pre-training stage:BEV感知,通过监督学习训练;
- Instruction-finetuning stage:冻结Vision encoder,并去掉Prediction Heads,通过监督学习训练Q-Former和Adapter。
同样的通过BEV感知增加3D空间理解能力,使用CLIP对齐的文本空间,然后对LLM预测轨迹解码。
4.3. SimLingo/CarLLaVA
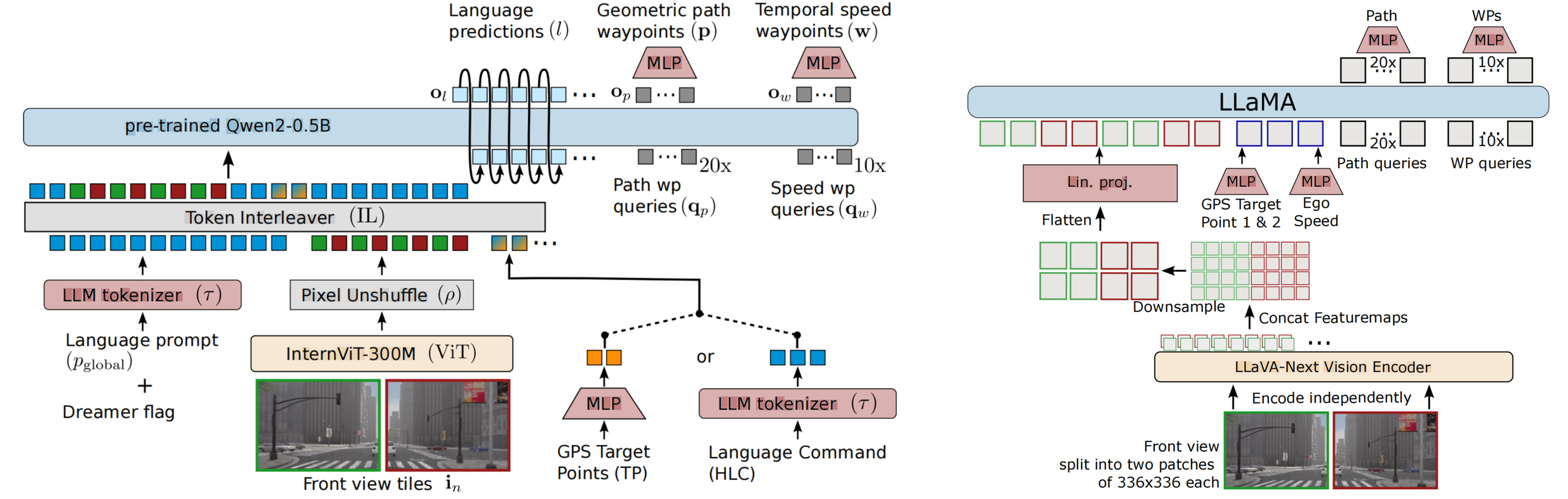
两个工作都是Wayve和图宾根大学合作的,显然采用了一样的思路和架构。将前视图像编码后降采样,对齐到文本空间,然后根据Prompt排序不同模态的输入给LLM,增加MLP解码path和speed。更加像在VLMs的工作上增加了Instruction-Action训练和Action Decoder。
4.4. ORION
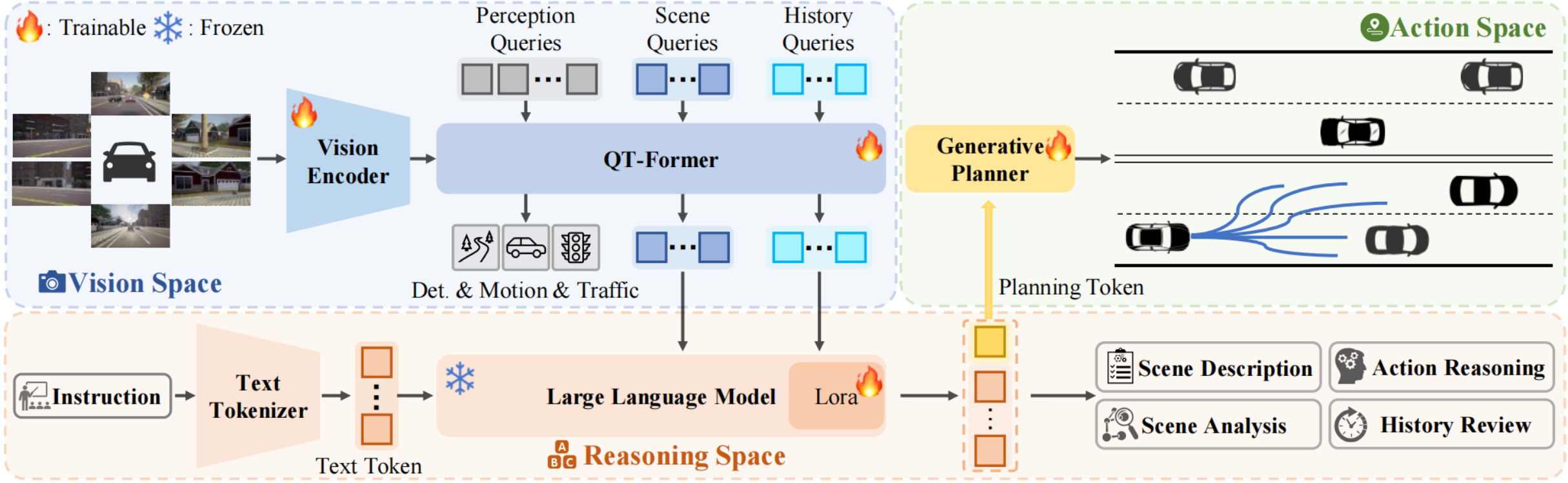
ORIN在使用视觉感知监督训练检测、地图和预测任务同时,增加了场景的历史信息储存和查询,增加对自动驾驶场景的空间理解能力。通过VAE对齐规划的文本空间和行动空间,增加轨迹的生成能力。
4.5. ReflectDrive
4.6. 总结
VLAs在VLMs的基础上,通过显式增加感知任务提升LLMs的自动驾驶环境的空间理解能力,通过MLP或者其他Decoder增加轨迹生成能力。VLAs/VLMs增加了数据集需求,如visual-question-answering(VQA)和instruction-action pairs。VLAs仍然面临推理的实时性和幻觉问题。
5. World Model
- A Survey of World Models for Autonomous Driving(TPAMI 2025)
- GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving(arXiv 2025)
- DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving(ECCV 2024)
- Drivedreamer-2: Llm-enhanced world models for diverse driving video generation(AAAI 2025)

















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









