




前言
现在人形运控基本都避不开RL了,而对于人形运控本身的部署则是一个完整的工程,而作为经典RL框架rsl_rl,则在本博客里的多篇文章反复被提及,比如
- 比如Humanplus一文中提到
对于humanplus的整个代码框架,总计包含以下五个部分
Humanoid Shadowing Transformer (HST),此所谓low-level,属于机器人小脑
这个部分的代码是基于仿真的强化学习实现,使用了legged_gym和rsl_rl
..
————
顺带,该文『详见此文《斯坦福人形HumanPlus的代码解读与复现关键:从HST(含rsl_rl)到HIT、HardWare》』,曾分析过rsl_rl中对PPO的实现
既然本文专门解读rsl_rl,故可以把那部分中对rsl_rl的介绍 也综合到本文之中了 - 比如Exbody 2一文中提到
“ 对于部署代码
我有找到这个HOMIE——包括PBHC的作者也表示可以参考openhomie和unitree rl gym的真机代码,有提供G1的部署代码(我也和HOMIE作者确认了下,说他们GitHub上包含G1的部署代码)——当然 HOMIE也用的别人的Walk these ways,对应的GitHub为leggedrobotics/rsl_rl
此unitree_rl_gym仓库建立在以下开源项目的支持和贡献之上。特别感谢:
legged_gym:训练和运行代码的基础
rsl_rl:强化学习算法实现——即上面提到的Walk these ways
mujoco:提供强大的模拟功能。
unitree_sdk2_python:用于物理部署的硬件通信接口
- 比如NaVILA一文中提到
第二部分 NaVILA/legged-loco中isaaclab_exts/模块的解析:侧重H1人形机器人配置
整体代码库主要分为以下几个部分:
isaaclab_exts - Isaac Lab的扩展,包含机器人配置和控制逻辑
rsl_rl - 强化学习框架实现
.. - 再比如HOMIE一文中提到
1.2 HOMIE的硬件系统设计与摇操实验
1.2.2.2 遥操作系统:可在现实世界和仿真中遥操机器人(含G1的部署源码Walk these ways)
G1的部署代码源自[52-Walk these ways: Tuning robot control for generalization with multiplicity of behavior],对应的GitHub为:leggedrobotics/rsl_rl
.. - 再比如,KungfuBot一文中提到
第二部分 KungfuBot GitHub仓库的整体分析
其所参考的库包括
ASAP:使用 ASAP 库来构建他们的强化学习代码库
RSL_RL:使用 rsl_rl 库来实现 PPO - 一朋友反馈,通过beyondmimic 试了一小段查尔斯整体还是比较稳的,至于数据用的宇树的数据集,部署框架他则用宇树的unitree_rl_gym改的
当然,beyondmimic本身集成了rsl_rl——homie便用的这个经典RL框架做的部署,也可以试下
正因为rsl_rl的屡屡出现,提高了其重要性和影响力,故本文特地专门汇总梳理下人形运控部署框架,包括rsl_rl、unitree_rl_gym、unitree_sdk2_python
值得一体的是,因为我之前在解读chatgpt原理时,花了大力气阐述过RL中重要的概念,包括PPO,故关于chatgpt/RL的那几篇文章『详见此系列《开启大模型时代的ChatGPT系列:包含原理、RLHF等》,当然,下文我还会再次给出更具体的一篇篇文章的链接的』,对理解本文要介绍的rsl_rl框架 还是很有帮助的,建议大伙读一读
第一部分 rsl_rl/:经典RL框架的封装(含我对PPO实现的解读)
RSL-RL是一个强化学习算法框架,其包含三大主要组件:Runners、Algorithms 和Networks
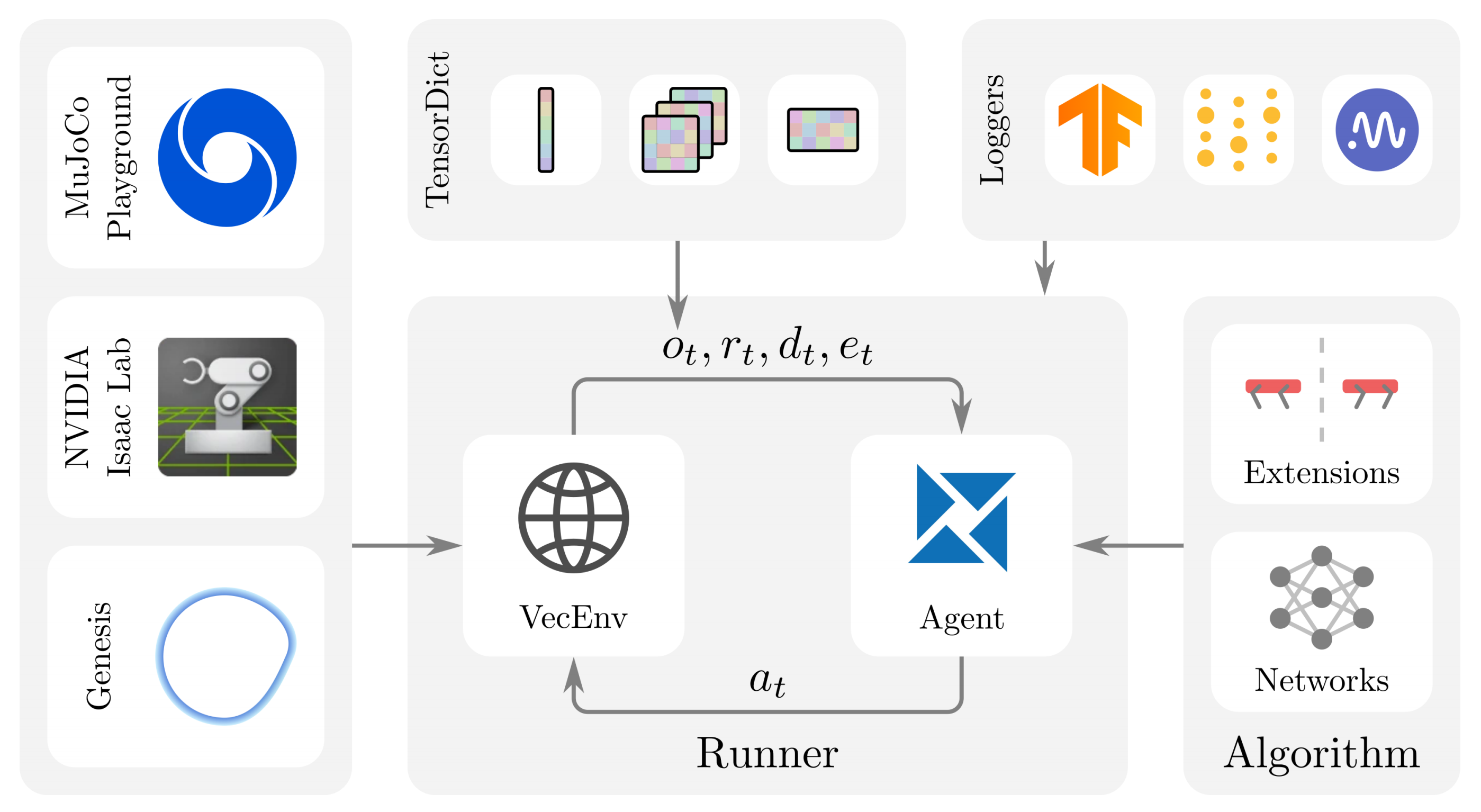
- 管理环境步进和智能体学习的Runner
__init__.py
distillation_runner.py
on_policy_runner.py - 定义学习智能体的Algorithm——包含 ppo.py、distillation.py
即RSL-RL 包含两种算法:
PPO 是一种无模型、基于策略的强化学习方法,它能够从零开始学习复杂任务,无需先验知识
和
BC算法是一种有监督学习方法,用于将专家策略的行为迁移到学生策略中。该方法通过反复执行学生策略以收集数据,使用专家动作对这些数据进行重新标注,并在此基础上训练学生策略
在使用PPO进行强化学习训练后,如果训练环境与硬件部署环境存在差异,该算法尤其有用。在这种情况下,仅依赖仿真中可用信息的RL智能体的(教师)行为可以蒸馏为不再依赖这些信息的(学生策略) - 供算法使用的Network结构
包含
__init__.py
memory.py
mlp.py
normalization.py
此外,还有对环境的封装,以及模型组件
- env
__init__.py
vec_env.py - modules
__init__.py
actor_critic.py
actor_critic_recurrent.py
rnd.py
student_teacher.py
student_teacher_recurrent.py
symmetry.py
具体而言,其代码结构为
rsl_rl/
config/ - 配置文件
rsl_rl/ - 核心代码
algorithms/ - 强化学习算法实现,如PPO
env/ - 环境封装
modules/ - 模型组件
actor_critic.py - 基础Actor-Critic网络
actor_critic_depth_cnn.py - 带深度视觉的Actor-Critic网络
actor_critic_history.py - 带历史信息的Actor-Critic网络
actor_critic_recurrent.py - 循环神经网络版Actor-Critic
depth_backbone.py - 深度视觉处理网络
runners/ - 训练运行器
storage/ - 数据存储
utils/ - 工具函数这个模块定义了强化学习的核心组件,包括actor-critic网络架构(有普通版、CNN版、历史记忆版和RNN版)、PPO算法实现、训练运行器等
从代码中可以看出,它支持不同类型的输入数据(如关节状态、深度图像等)
1.1 rsl_rl/algorithms/ppo.py:近端策略优化PPO的实现
这段代码定义了一个名为 `PPO` 的类,它实现了近端策略优化(Proximal Policy Optimization)算法,其详细介绍详见此文的《强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO》第4.4节
1.1.1 初始化__init__
构造函数接收一个
- `actor_critic` 网络(策略网络和价值网络的组合)
- 学习超参数(如学习周期 `num_learning_epochs`、小批量数量 `num_mini_batches`、裁剪参数 `clip_param`、折扣因子 `gamma`、GAE lambda `lam` 等)
- 以及优化器设置(学习率 `learning_rate`、梯度裁剪范数 `max_grad_norm`)
import torch # 导入 PyTorch 库 import torch.nn as nn # 导入 PyTorch 神经网络模块 import torch.optim as optim # 导入 PyTorch 优化模块 from rsl_rl.modules import ActorCriticTransformer # 从 rsl_rl.modules 导入 ActorCriticTransformer 类 from rsl_rl.storage import RolloutStorage # 从 rsl_rl.storage 导入 RolloutStorage 类 class PPO: # 定义 PPO 类 actor_critic: ActorCriticTransformer # 定义 actor_critic 变量类型为 ActorCriticTransformer def __init__(self, # 定义 PPO 类的初始化函数 actor_critic, # 定义 actor_critic 参数 num_learning_epochs=1, # 定义 num_learning_epochs 参数,默认值为1 num_mini_batches=1, # 定义 num_mini_batches 参数,默认值为1 clip_param=0.2, # 定义 clip_param 参数,默认值为0.2 gamma=0.998, # 定义 gamma 参数,默认值为0.998 lam=0.95, # 定义 lam 参数,默认值为0.95 value_loss_coef=1.0, # 定义 value_loss_coef 参数,默认值为1.0 entropy_coef=0.0, # 定义 entropy_coef 参数,默认值为0.0 learning_rate=1e-3, # 定义 learning_rate 参数,默认值为1e-3 max_grad_norm=1.0, # 定义 max_grad_norm 参数,默认值为1.0 use_clipped_value_loss=True, # 定义 use_clipped_value_loss 参数,默认值为 True schedule="fixed", # 定义 schedule 参数,默认值为 "fixed" desired_kl=0.01, # 定义 desired_kl 参数,默认值为 0.01 device='cpu', # 定义 device 参数,默认值为 'cpu' ):
它初始化 PPO 的核心组件:
- `actor_critic`: 传入的神经网络模型,并将其移动到指定的设备(如 CPU 或 GPU)
- `storage`: 用于存储经验轨迹(transitions)的 `RolloutStorage` 对象,稍后初始化
- `optimizer`: 使用 Adam 优化器来更新 `actor_critic` 网络的参数
- `transition`: 一个临时的 `RolloutStorage.Transition` 对象,用于在每个环境步骤中收集数据
- 及存储 PPO 算法的关键超参数
设置学习率调度策略(`schedule`)和目标 KL 散度(`desired_kl`),用于自适应学习率调整self.device = device # 初始化 self.device 为传入的 device 参数 self.desired_kl = desired_kl # 初始化 self.desired_kl 为传入的 desired_kl 参数 self.schedule = schedule # 初始化 self.schedule 为传入的 schedule 参数 self.learning_rate = learning_rate # 初始化 self.learning_rate 为传入的 learning_rate 参数 # PPO components # 最上面PPO类里一系列参数的self初始化 # PPO parameters # 最上面PPO类里一系列参数的self初始化
1.1.2 存储初始化init_storage
- 这个方法根据环境的数量、每个环境收集的转换(transitions)数量、观察空间形状和动作空间形状来创建 `RolloutStorage` 实例
- `RolloutStorage` 负责存储智能体与环境交互产生的数据序列
def init_storage(self, num_envs, num_transitions_per_env, actor_obs_shape, critic_obs_shape, action_shape): # 初始化存储 self.storage = RolloutStorage(num_envs, num_transitions_per_env, actor_obs_shape, critic_obs_shape, action_shape, self.device)
1.1.3 模式切换test_mode/train_mode
这些方法用于切换 `actor_critic` 网络到评估(测试)模式或训练模式。这对于包含 Dropout 或 Batch Normalization 层的网络很重要
详细代码如下
def test_mode(self): # 定义测试模式函数
self.actor_critic.test() # 设置 actor_critic 为测试模式
def train_mode(self): # 定义训练模式函数
self.actor_critic.train() # 设置 actor_critic 为训练模式1.1.4 动作选择act
这是智能体与环境交互的核心。给定当前观察 `obs`(用于策略网络)和 `critic_obs`(用于价值网络,可能与 `obs` 相同或包含额外信息),它执行以下操作:
- 如果网络是循环的(RNN/LSTM),获取并存储隐藏状态
def act(self, obs, critic_obs): # 定义 act 函数 if self.actor_critic.is_recurrent: # 如果 actor_critic 是循环的 self.transition.hidden_states = self.actor_critic.get_hidden_states() # 获取隐藏状态 - 使用 `actor_critic` 网络
计算动作 (`actions`)状态价值 (`values`)# 使用 Actor-Critic 网络计算动作,并分离计算图 self.transition.actions = self.actor_critic.act(obs).detach()和动作的对数概率 (`actions_log_prob`)# 使用 Actor-Critic 网络评估状态价值,并分离计算图 self.transition.values = self.actor_critic.evaluate(critic_obs).detach()# 获取动作的对数概率,并分离计算图 self.transition.actions_log_prob = self.actor_critic.get_actions_log_prob(self.transition.actions).detach() - 存储动作分布的均值 (`action_mean`) 和标准差 (`action_sigma`)
self.transition.action_mean = self.actor_critic.action_mean.detach() # 获取动作均值 self.transition.action_sigma = self.actor_critic.action_std.detach() # 获取动作标准差 - 将当前的观察、评论家观察以及计算出的所有信息存储在临时的 `transition` 对象中
# need to record obs and critic_obs before env.step() # 在环境步之前需要记录 obs 和 critic_obs self.transition.observations = obs # 记录观察 self.transition.critic_observations = critic_obs # 记录评论员观察 - 返回计算出的动作,供环境执行
return self.transition.actions # 返回动作
1.1.5 处理环境步骤process_env_step
在环境执行动作后调用此方法
- 接收奖励 (`rewards`)、完成标志 (`dones`) 和额外信息 (`infos`)
def process_env_step(self, rewards, dones, infos): # 定义处理环境步函数 self.transition.rewards = rewards.clone() # 克隆奖励 self.transition.dones = dones # 记录完成状态 - 且将这些信息存储到 `transition` 对象中
重要: 它实现了"超时引导 (Bootstrapping on time outs)"。如果一个 episode 因为达到时间限制而不是因为失败状态而结束(通过 `infos["time_outs"]` 判断),它会将最后一步的估计价值(乘以 `gamma`)加到奖励中
# Bootstrapping on time outs # 对超时进行引导 if 'time_outs' in infos: # 如果信息中有 'time_outs' self.transition.rewards += self.gamma * torch.squeeze(self.transition.values * infos['time_outs'].unsqueeze(1).to(self.device), 1) # 更新奖励
这可以防止智能体因为时间限制而受到不公平的惩罚,并提供更准确的回报估计
————
将完整的 `transition` 添加到 `storage` 中# Record the transition # 记录过渡 self.storage.add_transitions(self.transition) # 添加过渡到存储中 - 清空 `transition` 对象,为下一步做准备
如果网络是循环的,根据 `dones` 信号重置其隐藏状态
self.transition.clear() # 清除过渡数据self.actor_critic.reset(dones) # 重置 actor_critic
1.1.6 计算回报compute_returns
- 在收集了足够多的 transitions 后调用
- 首先,使用 `actor_critic` 网络评估最后一个状态的价值 (`last_values`)
# 计算回报和优势的方法 def compute_returns(self, last_critic_obs): # 评估最后一个状态的价值 last_values = self.actor_critic.evaluate(last_critic_obs).detach() - 然后,调用 `storage.compute_returns` 方法
这个方法通常使用广义优势估计 (Generalized Advantage Estimation, GAE)来计算每个时间步的回报 (`returns`) 和优势 (`advantages`)
# 调用存储器的 compute_returns 方法计算回报和 GAE 优势 self.storage.compute_returns(last_values, self.gamma, self.lam)
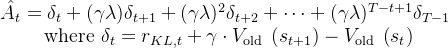
GAE 结合了不同时间步长的价值估计,以减少估计的方差
至于什么是GAE,请参见此文《从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat的源码》的第3.6节
1次PPO训练由train_rlhf()方法进行管理,其内部主要实现了『注,以下的内容如果有不太理解的,可以结合《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》一文中的3.2节增进理解』:
- KL散度惩罚奖励old_rewards的计算,为了防止对phase2学习到的环境奖励过度自信,所以加入了KL散度惩罚项:
- 优势advantages和回报returns的计算
其中包括本框架在内多数框架的advantages实现并非纯粹使用TD-error,而是在TD-error的基础上结合了MC方法,也即GAE(广义优势估计);
——————
对于全长为的轨迹来说,其某个时间步的优势为(时,advantage完全使用MC方法;时,advantage完全使用TD-error方法):
- 至于回报returns就是奖励reward的累计,对于全长为的轨迹来说,其到达某个时间步 时的回报为
1.1.7 update:策略和价值网络参数更新
这是执行策略和价值网络参数更新的核心循环
# 更新策略和价值网络参数的方法
def update(self):
# 初始化平均价值损失
mean_value_loss = 0
# 初始化平均代理损失
mean_surrogate_loss = 0- 第一阶段,它首先根据网络是否是循环的,选择合适的小批量生成器(`mini_batch_generator` 或 `reccurent_mini_batch_generator`) 从 `storage` 中采样数据
# 检查 Actor-Critic 网络是否是循环网络 if self.actor_critic.is_recurrent: # 如果是循环网络,使用循环小批量生成器 generator = self.storage.reccurent_mini_batch_generator(self.num_mini_batches, self.num_learning_epochs) # 如果不是循环网络 else: # 使用标准小批量生成器 generator = self.storage.mini_batch_generator(self.num_mini_batches, self.num_learning_epochs) -
第二阶段,它遍历生成器产生的每个mini-batch,对每个batch进行一系列的操作
注意,以下是整个FOR大循环开始# 遍历小批量生成器产生的数据 for ( obs_batch, # 观察值小批量 critic_obs_batch, # 评论家观察值小批量 actions_batch, # 动作小批量 target_values_batch, # 目标价值小批量 (用于价值损失计算,通常是回报) advantages_batch, # 优势小批量 returns_batch, # 回报小批量 (用于价值损失计算) old_actions_log_prob_batch, # 旧策略下的动作对数概率小批量 old_mu_batch, # 旧策略下的动作均值小批量 old_sigma_batch, # 旧策略下的动作标准差小批量 hid_states_batch, # 隐藏状态小批量 (仅用于循环网络) masks_batch, # 掩码小批量 (仅用于循环网络) ) in generator:
接下来,分析下整个FOR循环
对于每个小批量 (mini-batch)
- 重新计算当前策略下的小批量数据的动作对数概率、价值和熵
# 使用当前策略重新评估动作 (主要为了获取内部状态如均值、标准差) self.actor_critic.act(obs_batch, masks=masks_batch, hidden_states=hid_states_batch[0]) # 获取当前策略下动作的对数概率 actions_log_prob_batch = self.actor_critic.get_actions_log_prob(actions_batch) # 使用当前策略评估状态价值 value_batch = self.actor_critic.evaluate( # 传入评论家观察、掩码和隐藏状态 critic_obs_batch, masks=masks_batch, hidden_states=hid_states_batch[1] ) # 获取当前策略的动作均值 mu_batch = self.actor_critic.action_mean # 获取当前策略的动作标准差 sigma_batch = self.actor_critic.action_std # 获取当前策略的熵 entropy_batch = self.actor_critic.entropy- KL 散度与自适应学习率:如果启用了自适应学习率 (`schedule == "adaptive"`)
首先,计算当前策略和旧策略(生成数据时的策略)之间的 KL 散度上面这个KL公式稍微有点小复杂,但为方便大家更好的理解 更为大家看着舒服、省心,我还是把上面这段代码对应的公式 写一下,且把代码的每一行 与公式当中的各个项,逐一对应说明下# KL 散度计算 (用于自适应学习率) # 如果设置了期望 KL 且调度策略是自适应的 if self.desired_kl is not None and self.schedule == "adaptive": # 在无梯度计算模式下进行 with torch.inference_mode(): # 计算当前策略和旧策略之间的 KL 散度 kl = torch.sum( # 对数标准差比项 (+1e-5 防止除零) torch.log(sigma_batch / old_sigma_batch + 1.0e-5) # 旧标准差平方 + 均值差平方项 + (torch.square(old_sigma_batch) + torch.square(old_mu_batch - mu_batch)) # 除以 2 倍当前标准差平方 / (2.0 * torch.square(sigma_batch)) # 减去 0.5 - 0.5, # 沿着最后一个维度求和 axis=-1, )
假设当前策略的均值和标准差分别为 μ 和 σ,旧策略的均值和标准差分别为和
,则 KL 散度的公式为
首先,其中这行代码对应为# 对数标准差比项 (+1e-5 防止除零) torch.log(sigma_batch / old_sigma_batch + 1.0e-5)
其次,接下来的这行代码对应于# 旧标准差平方 + 均值差平方项 + (torch.square(old_sigma_batch) + torch.square(old_mu_batch - mu_batch))
然后其中的「除以 2 倍当前标准差平方」的代码:对应于# 除以 2 倍当前标准差平方 / (2.0 * torch.square(sigma_batch))
接下来,减去0.5的代码 对应为
最后,沿着最后一个维度求和的代码 对应为
![\sum_{i=1}^{d}\left[\log \left(\frac{\sigma_{i}}{\sigma_{\text {old }, i}}+10^{-5}\right)+\frac{\sigma_{\text {old }, i}^{2}+\left(\mu_{\text {old }, i}-\mu_{i}\right)^{2}}{2 \sigma_{i}^{2}}-\frac{1}{2}\right]](https://latex.youkuaiyun.com/eq?%5Csum_%7Bi%3D1%7D%5E%7Bd%7D%5Cleft%5B%5Clog%20%5Cleft%28%5Cfrac%7B%5Csigma_%7Bi%7D%7D%7B%5Csigma_%7B%5Ctext%20%7Bold%20%7D%2C%20i%7D%7D+10%5E%7B-5%7D%5Cright%29+%5Cfrac%7B%5Csigma_%7B%5Ctext%20%7Bold%20%7D%2C%20i%7D%5E%7B2%7D+%5Cleft%28%5Cmu_%7B%5Ctext%20%7Bold%20%7D%2C%20i%7D-%5Cmu_%7Bi%7D%5Cright%29%5E%7B2%7D%7D%7B2%20%5Csigma_%7Bi%7D%5E%7B2%7D%7D-%5Cfrac%7B1%7D%7B2%7D%5Cright%5D)
哦了,上面这个公式解释好了
那接下来,根据 KL 散度与 `desired_kl` 的比较,动态调整优化器的学习率上面这个过程,也是有说法滴,根据此文的《强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO》第4.4节,可知:上述的5行代码是典型的自适应KL惩罚的过程# 计算 KL 散度的平均值 kl_mean = torch.mean(kl) # 如果 KL 散度远大于期望值 if kl_mean > self.desired_kl * 2.0: # 降低学习率 (最小为 1e-5) self.learning_rate = max(1e-5, self.learning_rate / 1.5) # 如果 KL 散度远小于期望值 (且大于 0) elif kl_mean < self.desired_kl / 2.0 and kl_mean > 0.0: # 提高学习率 (最大为 1e-2) self.learning_rate = min(1e-2, self.learning_rate * 1.5)
上述公式中的是怎么取值的呢,事实上,
假设优化完以后,KL 散度值太大导致
,意味着
与
差距过大(即学习率/步长过大),也就代表后面惩罚的项
惩罚效果太弱而没有发挥作用,故增大惩罚把
如果优化完,意味着
————
至于详细了解请查看本博客内此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》的4.4.1 什么是近端策略优化PPO与PPO-penalty- 接下来,计算 PPO 的核心损失项:actor损失 (Surrogate Loss)
它首先计算新旧策略的比率——即重要性采样比率 (`ratio`) ,和优势 (`advantages_batch`),然后计算未裁剪和裁剪的代理损失,并取两者的最大值作为最终的actor损失# 代理损失计算 (PPO 核心目标) # 计算重要性采样比率 (当前概率 / 旧概率) ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch)) # 计算未裁剪的代理损失项 surrogate = -torch.squeeze(advantages_batch) * ratio # 计算裁剪后的代理损失项 surrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp( # 且将比率裁剪到 [1-clip, 1+clip] 范围内 ratio, 1.0 - self.clip_param, 1.0 + self.clip_param ) # 取未裁剪和裁剪后损失中的较大者,并计算平均值 surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()其实上面的代码就是对近端策略优化裁剪PPO-clip的直接实现,其对应的公式如下『详细了解请查看本博客内此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》的第4.4.2节PPO算法的另一个变种:近端策略优化裁剪PPO-clip)』
- 价值函数损失 (Value Function Loss):计算价值网络的损失
如果设置了使用裁剪价值损失,那么会计算裁剪的价值损失和未裁剪的价值损失,并取两者的最大值作为最终的价值损失否则,直接计算未裁剪的价值损失# 价值函数损失计算 # 如果使用裁剪的价值损失 if self.use_clipped_value_loss: # 计算裁剪后的价值预测 value_clipped = target_values_batch + (value_batch - target_values_batch).clamp( # 将价值预测与目标价值的差值裁剪到 [-clip, clip] -self.clip_param, self.clip_param ) # 计算未裁剪的价值损失 (均方误差) value_losses = (value_batch - returns_batch).pow(2) # 计算裁剪后的价值损失 (均方误差) value_losses_clipped = (value_clipped - returns_batch).pow(2) # 取未裁剪和裁剪后损失中的较大者,并计算平均值 value_loss = torch.max(value_losses, value_losses_clipped).mean()————# 如果不使用裁剪的价值损失 else: # 直接计算价值损失 (均方误差) value_loss = (returns_batch - value_batch).pow(2).mean()
其实就是之前这篇文章《从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat的源码》中3.6中AC架构下的PPO训练:在加了β惩罚且截断后的RM之下,通过经验数据不断迭代策略且估计value讲过
在1个ppo_batch中,critic的损失计算公式为:
裁剪新价值估计,使其不至于太偏离采集经验时的旧价值估计,使得经验回放仍能有效:
critic将拟合回报R:
可能有同学疑问上面的代码和我说的这个公式并没有一一对齐呀,为了方便大家一目了然,我们把代码逐行再分析下
对于这行代码
value_clipped = target_values_batch + (value_batch - target_values_batch).clamp(-self.clip_param,self.clip_param)
转换成公式便是
V_clipped = V_old + clip(V_new - V_old, -ε, ε)
它和我上面贴的公式表达的其实是一样的
因为我上面贴的公式要表达的是:,那该不等式两边都减去个
,不就意味着
而接下来这三行代码
value_losses = (value_batch - returns_batch).pow(2)
value_losses_clipped = (value_clipped - returns_batch).pow(2)
value_loss = torch.max(value_losses, value_losses_clipped).mean()
则表达的就是如下公式
是不一目了然了..
- 最后,计算总损失:将代理损失、价值损失(乘以系数 `value_loss_coef`)和熵奖励(乘以系数 `entropy_coef`,鼓励探索)结合起来
且进行梯度更新: 计算总损失的梯度,执行梯度裁剪 (`clip_grad_norm_`) 防止梯度爆炸,然后让优化器执行一步更新# 计算总损失 = 代理损失 + 价值损失 - 熵奖励 loss = surrogate_loss + self.value_loss_coef * value_loss - self.entropy_coef * entropy_batch.mean()# 梯度更新步骤 # 清空优化器的梯度 self.optimizer.zero_grad() # 反向传播计算梯度 loss.backward() # 对梯度进行裁剪,防止梯度爆炸 nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm) # 执行一步优化器更新 self.optimizer.step() # 累加当前小批量的价值损失 (转换为 Python float) mean_value_loss += value_loss.item() # 累加当前小批量的代理损失 (转换为 Python float) mean_surrogate_loss += surrogate_loss.item()
至此,便结束了上述的整个FOR循环
- 第三阶段,在所有mini-batch更新完成后,累积并计算平均的价值损失和代理损失,用于监控训练过程
清空 `storage`,为下一轮数据收集做准备
# 计算总的更新次数 num_updates = self.num_learning_epochs * self.num_mini_batches # 计算整个 update 过程中的平均价值损失 mean_value_loss /= num_updates # 计算整个 update 过程中的平均代理损失 mean_surrogate_loss /= num_updates# 清空经验存储器,为下一轮数据收集做准备 self.storage.clear()返回平均损失值# 返回平均价值损失和平均代理损失 return mean_value_loss, mean_surrogate_loss
1.2 rsl_rl/env
1.3 rsl_rl/modules
1.3.0 modules/actor_critic_transformer.py
actor_critic_transformer.py这段代码定义了一个基于BERT风格的Transformer模型,用于强化学习中的Actor-Critic方法
它由三个主要的类组成:Transformer_Block, Transformer、ActorCriticTransformer
- Transformer_Block 类
Transformer_Block 类是构建Transformer模型的基础块(下图来自此文中对ViT的架构的介绍:Embedding层 + Transformer Encoder + MLP Head)
它包含了多头注意力机制 (Muitihead Attention) 和前馈神经网络 (FeedForward Neural Network)
这个类首先通过层归一代 (Layer Normalization),然后应用多头注意力机制,再次进行层归一化,并最后通过一个前馈神经网络# a BERT-style transformer block class Transformer_Block(nn.Module): def __init__(self, latent_dim, num_head, dropout_rate) -> None: super().__init__() self.num_head = num_head self.latent_dim = latent_dim self.ln_1 = nn.LayerNorm(latent_dim) self.attn = nn.MultiheadAttention(latent_dim, num_head, dropout=dropout_rate, batch_first=True) self.ln_2 = nn.LayerNorm(latent_dim) self.mlp = nn.Sequential( nn.Linear(latent_dim, 4 * latent_dim), nn.GELU(), nn.Linear(4 * latent_dim, latent_dim), nn.Dropout(dropout_rate), ) def forward(self, x): x = self.ln_1(x) x = x + self.attn(x, x, x, need_weights=False)[0] x = self.ln_2(x) x = x + self.mlp(x) return x - Transformer 类
Transformer 类构建了一个完整的 Transformer模型,它接收输入数据并通过一系列的Transformer_Block 进行处理
首先,输入数据通过一个线性层和位置嵌入 (Position Embedding) 进行处理,以增加位置信息
然后,数据通过多个 Transformer_Block 进行处理class Transformer(nn.Module): def __init__(self, input_dim, output_dim, context_len, latent_dim=128, num_head=4, num_layer=4, dropout_rate=0.1) -> None: super().__init__() self.input_dim = input_dim self.output_dim = output_dim self.context_len = context_len self.latent_dim = latent_dim self.num_head = num_head self.num_layer = num_layer self.input_layer = nn.Sequential( nn.Linear(input_dim, latent_dim), nn.Dropout(dropout_rate), ) self.weight_pos_embed = nn.Embedding(context_len, latent_dim)
最后,模型通过另一个线性层输出最終结果self.attention_blocks = nn.Sequential( *[Transformer_Block(latent_dim, num_head, dropout_rate) for _ in range(num_layer)], )self.output_layer = nn.Sequential( nn.LayerNorm(latent_dim), nn.Linear(latent_dim, output_dim), ) def forward(self, x): x = self.input_layer(x) x = x + self.weight_pos_embed(torch.arange(x.shape[1], device=x.device)) x = self.attention_blocks(x) # take the last token x = x[:, -1, :] x = self.output_layer(x) return x - ActorCriticTransformer 类
ActorcriticTransformer 类实现了Actor-Critic方法,其中Actor和Critic都使用了上述的Transformer模型
Actor负责生成动作,而Critic负责评估当前策略的价值。这个类还包括了动作噪声的处理,以及一些用于强化学习的特定方法,如 act、evaluate 和update-distribution 等
1.3.1 modules/actor_critic_depth_cnn.py
1.3.2 modules/actor_critic_history.py
1.3.3 modules/actor_critic_recurrent.py
1.3.4 modules/actor_critic.py
这段代码定义了一个名为 ActorCritic的类,它继承自nn.Module,是一个用于强化学习的演员-评论家模型的实现
这个模型包含两个主要部分:一个用于决策的策略网络(演员)和一个用于评估动作价值的价值网络(评论家)
- 构造函数_-init--- 接收多个参数,包括观察空问的维度(分别为演员和评论家)、动作空问的维度、隐藏层的维度、激活函数类型以及初始噪声标淮差
class ActorCritic(nn.Module): is_recurrent = False def __init__(self, num_actor_obs, num_critic_obs, num_actions, actor_hidden_dims=[256, 256, 256], critic_hidden_dims=[256, 256, 256], activation='elu', init_noise_std=1.0, **kwargs): - 构造函数首先检查是否有末预期的参数传入,并打印警告信息。然后,它调用get_activation 函数来获取指定的激活函数
if kwargs: print("ActorCritic.__init__ got unexpected arguments, which will be ignored: " + str([key for key in kwargs.keys()])) super(ActorCritic, self).__init__() activation = get_activation(activation) - 接下来,构造函数初始化演员和评论家网络
这两个网络都是使用多层感知机MLP构建的,其中每一层都是通过 nn.Linear 创建的,并且在每个线性层之后应用了激活函数mlp_input_dim_a = num_actor_obs mlp_input_dim_c = num_critic_obs
比如这是对policy的构建
再比如这是对value的构建# Policy actor_layers = [] actor_layers.append(nn.Linear(mlp_input_dim_a, actor_hidden_dims[0])) actor_layers.append(activation) for l in range(len(actor_hidden_dims)): if l == len(actor_hidden_dims) - 1: actor_layers.append(nn.Linear(actor_hidden_dims[l], num_actions)) else: actor_layers.append(nn.Linear(actor_hidden_dims[l], actor_hidden_dims[l + 1])) actor_layers.append(activation) self.actor = nn.Sequential(*actor_layers)
演员网络的输出维度等于动作空间的维度,而评论家网络的输出维度固定为1,表示对当前状态的价值评估# Value function critic_layers = [] critic_layers.append(nn.Linear(mlp_input_dim_c, critic_hidden_dims[0])) critic_layers.append(activation) for l in range(len(critic_hidden_dims)): if l == len(critic_hidden_dims) - 1: critic_layers.append(nn.Linear(critic_hidden_dims[l], 1)) else: critic_layers.append(nn.Linear(critic_hidden_dims[l], critic_hidden_dims[l + 1])) critic_layers.append(activation) self.critic = nn.Sequential(*critic_layers) print(f"Actor MLP: {self.actor}") print(f"Critic MLP: {self.critic}") - 此外,构造函数还初始化了一个用于动作输出的噪声参数 self.std,并设置了一个分布self.distribution,该分布稍后将用于生成带有噪声的动作
类中还定义了几个方法,包括reset(重置状态,当前为空实现)、forward(抽象方法,未实现)、update_distribution(根据当前观察更新动作分布)、act (根据当前观察采取动作)、get_actions_1og-prob(计算动作的对数概率)、 act-inference(推断模式下的动作选择,不包含噪声)和evaluate(评估给定观察的价值)
最后,get_activation 函数根据传入的激活函数名称返回对应的PyTorch激活函数对象,如果传入的名称无效,则打印错误信息井返回None
1.3.5 modules/depth_backbone.py
1.3.6 modules/normalizer.py
1.4 rsl_rl/runners
// 待更


















 1737
1737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











