




自动驾驶系统中,由于交通参与者和感知的不确定性,在密集交通流场景中决策是非常苦难的。POMDP(partially observable Markov decision process)是解决不确定问题的系统性的工具,但是在实际的大规模问题中,其计算非常耗时。论文提出了高效的不确定性下决策框架(EUDM, efficient uncertainty-aware decision-making),在复杂的行驶环境中产生横纵向决策。使用特定领域闭环策略树(DCP-Tree, domain-specific closed-loop policy tree)和条件聚焦剪枝机制(conditional focused branching),利用了特定领域的专家经验对行为空间和意图空间进行剪枝,减少计算量。
论文是在MPDM(multipolicy decision-making)的基础改进的。MPDM使用有限几个语义级策略(例如换道、车道保持)进行闭环的前向仿真,而不是使用车辆所有可能的控制输入。MPDM有两个不足:一是在整个规划时域内只有一个语义决策,二是在初始预测状态不准确的情况下,可能会生成不安全的决策。
1. 架构
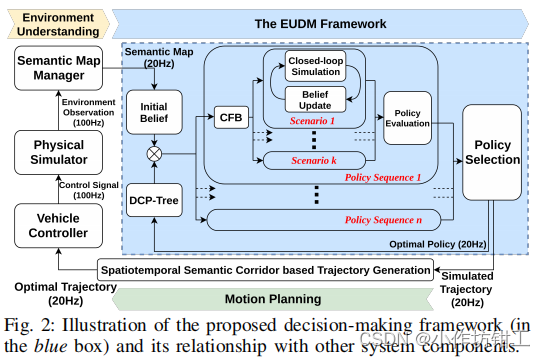
DCP-Tree构造一个语义级的行为空间。决策树上的每个节点都是主车的一个语义级行为,从根节点到叶子节点的每一条轨迹都表示主车的一系列语义级行为,并且语义级行为可以在规划时域内改变一次,每条行为轨迹会在闭环仿真中计算。DCP-Tree决定了主车的行为,但是其他车辆的行为仍然是不知道的。由于和其他车辆的行为意图组合是指数级增长的,CFB机制在主车行为序列的条件下,使用开环安全评估,挑选出可能存在风险的场景。
DCT-Tree将主车的行为空间剪枝,在上一步最优策略的基础上构建决策树。对于主车的每个行为序列(DCP-Tree的每条轨迹),CFB机制通过挑选出主车附近车辆可能具有风险的行为来进行意图空间剪枝。CFB产生一系列场景,其是主车附近车辆的不同的意图的组合。每个场景考虑多智能体之间的交互,使用闭环仿真计算,所有场景进行cost计算,并对有风险的场景进行惩罚。
EUDM输出的最优决策是主车和其他车辆通过闭环前方仿真生成的一系列离散状态,时间分辨率是0.4s0.4s0.4s。下面是EUDM的伪代码,可以发现两个forforfor循环都可是使用多线程并行计算。

2. POMDP
POMDPPOMDPPOMDP由七元组<S,A,T,R,Z,O,γ><\mathcal{S,A,T,R,Z,O,\gamma}><S,A,T,R,Z,O,γ>构成,分别是状态空间,动作空间,状态转移函数,回报函数,观测空间,观测函数和折扣因子。智能体的状态是部分可观测的,使用置信度bbb描述,bbb是在S\mathcal{S}S上的概率分布。在给定的动作aaa和观测zzz下,使用贝叶斯计算btb_tbt,bt=τ(bt−1,at−1,zt)b_t = \tau(b_{t-1},a_{t-1},z_t)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2173
2173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









