




 本文介绍了马尔可夫决策过程(MDP)的基本概念,包括有限状态空间与动作空间、转移概率等,并详细阐述了价值函数(state-value function与action-value function)的概念与计算方式。此外,还介绍了策略评估(policy evaluation)、策略改进(policy improvement)、策略迭代(policy iteration)及价值迭代(value iteration)等强化学习核心算法。
本文介绍了马尔可夫决策过程(MDP)的基本概念,包括有限状态空间与动作空间、转移概率等,并详细阐述了价值函数(state-value function与action-value function)的概念与计算方式。此外,还介绍了策略评估(policy evaluation)、策略改进(policy improvement)、策略迭代(policy iteration)及价值迭代(value iteration)等强化学习核心算法。
1.MDP(Markov Decision Processes)
finite MDP: finite state space&finite action space
transition probabilities:p(s′ | s, a) = Pr{St+1 = s′ | St = s, At = a}
r(s, a, s′) = E[Rt+1 | St = s, At = a, St+1 = s′]
2.Value Functions
state-value function: vπ(s)=Eπ[Gt|St = s] = Eπ[∑∞k=0γkRt+k+1| St = s]
action-value function: qπ(s, a) = Eπ[Gt|St = s, At = a] = Eπ[∑∞k=0γkRt+k+1| St = s, At = a]
Gt: return (cumulative discounted reward) following t
Rt: reward at t, dependent, like St, on At−1 and St−1
Gt = ∑∞k=0γkRt+k+1

vπ, qπ: vπ(s) = ∑aπ(a|s)qπ(s,a) qπ(s, a) = ∑s′p(s′|s,a)[r(s,a,s′)+γvπ(s’)]
π(a|s): probability of taking action a when in state s
Bellman Equation for vπ: vπ(s) = ∑aπ(a|s)∑s′p(s′|s,a)[r(s,a,s′)+γvπ(s′)]
Bellman function => learn vπ
Bellman Equation for qπ: qπ(s, a) = ∑s′p(s′|s,a)[r(s,a,s′)+γ∑a′π(a′|s′)qπ(s′,a′)]
3.Policy Evaluation
policy evaluation: compute vπ for policy π
Iteration policy evaluation:
1. For state s, the initial v0 is chosen arbitary(terminal state 0)
2.Successive approximation is obtained by using the Bellman Equation:
vk+1(s) = Eπ[Rt+1+γvk(st+1) | St = s]
code:
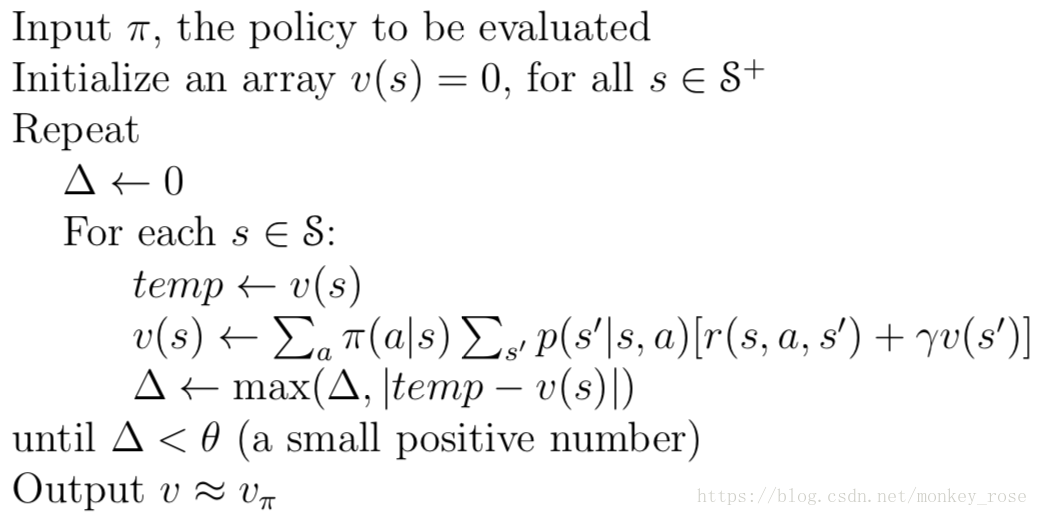
4.Policy Improvement
policy improvement: evaluate policy to find better policies
greedy policy π′: π′(x) = arg amaxqπ(s,a)
The greedy policy takes the action that looks best in the short term—after one step of lookahead—according to vπ.
5.Policy Iteration&Value Iteration
policy iteration
code:

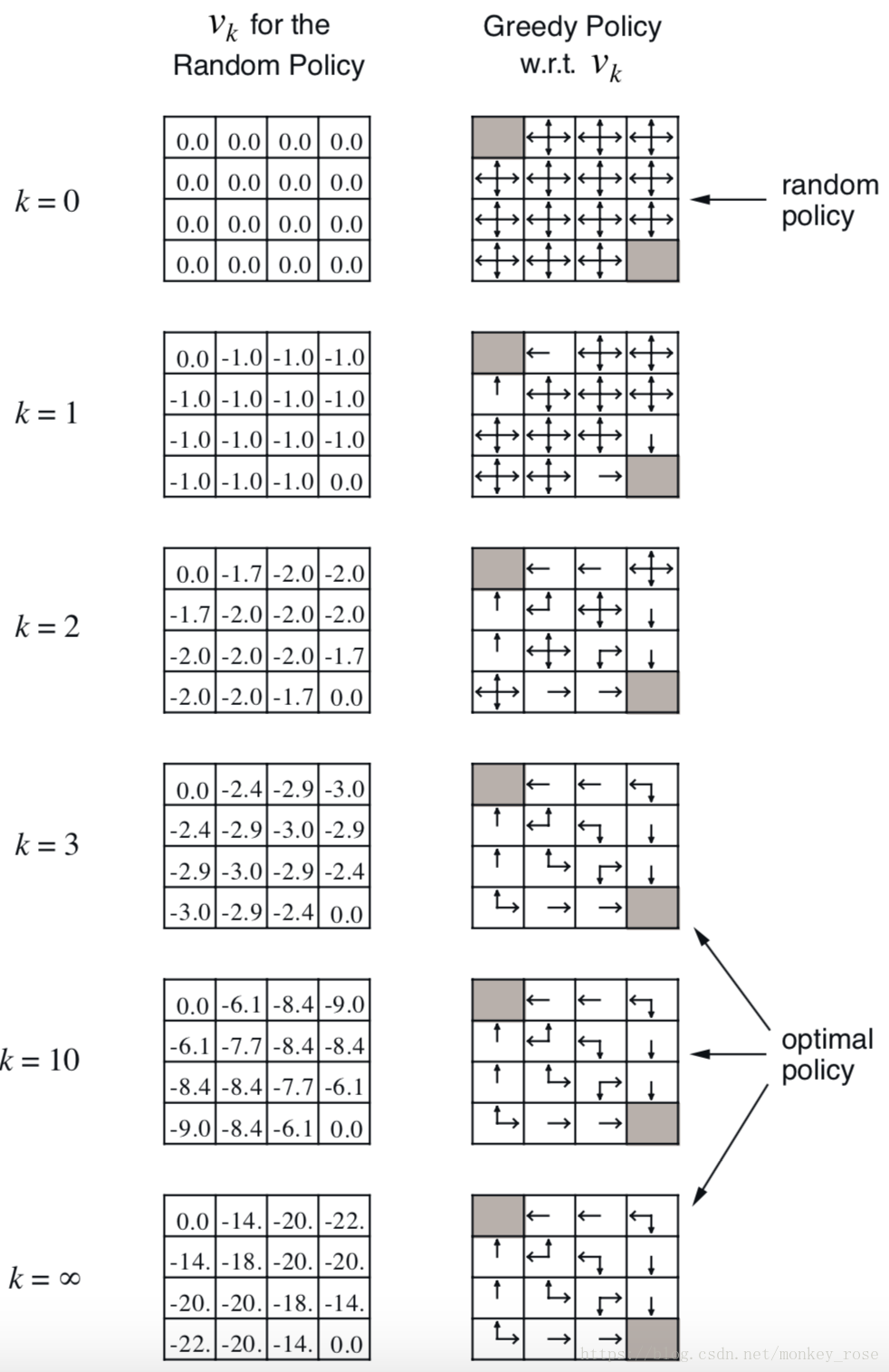
an example:
value iteration
It can be written as a particularly simple backup operation that combines the policy improvement and truncated policy evaluation steps, more efficient.
vk+1(s) = amax E[Rt+1+γvk(St+1) | St = s, At = a]
code:

Q-Learning
Initialize Q(s,a) arbitrarily
Repeat (for each episode):
Initialize s
Repeat (for each episode):
Choose a from s using policy derived from Q(e.g.,ε-greedy)
Take action a, observe r, s'
Q(s, a)←Q(s, a) + α[r + γmaxQ(s', a')-Q(s, a)]
s←s'
util s is terminalEvaluation:
update Q-table, in every episode, Q(s, a) is the value in the table, maxa’Q(s’, a’) is the max approximation for Q(s’)
decision policy:
ε-greedy: ε = 0.9, choose the best action for 90%, choose others randomly for 10%

















 66
66

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









