




材料准备
一块ESP32(本文所用为ESP32-S3-N16R8)
一块max98357A(功放模块)+一个喇叭
一块INMP441麦克风模块
一块5V锂电池
一块面包板
项目流程
细致分为十个步骤,如图
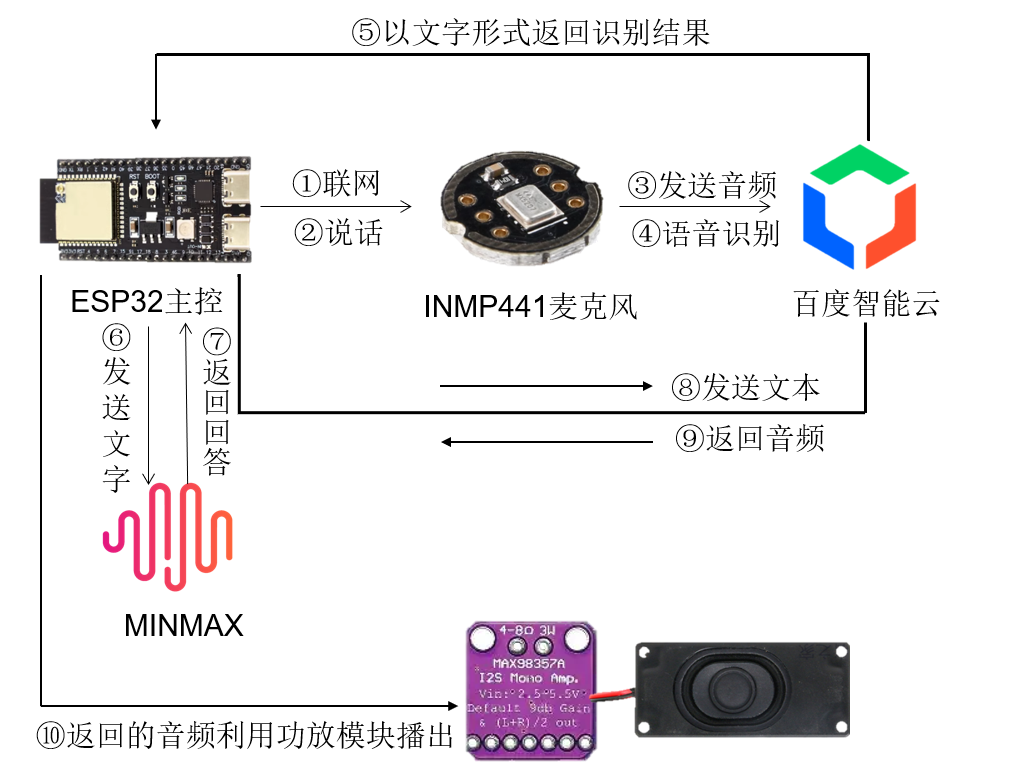
主要步骤为:
① 将麦克风录音的音频发送到百度语音智能云平台,调用百度语音识别技术,将音频转换为文字,识别的文字返回给ESP32
②ESP32将文字发送到minmax平台,调用minmax模型获取回答,并将回答以文字形式返回给ESP32
③ESP32将获取的回复内容发送到百度语音智能云平台,调用百度语音合成技术,将文字内容转换为音频,音频返回给ESP32,ESP32将合成的音频通过功放模块放出来
代码连线:
模块引脚说明:

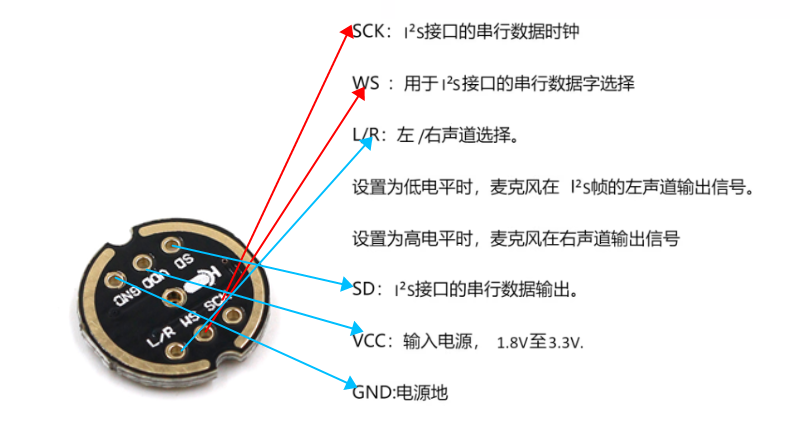
| ESP32 | MAX98357A |
| 16 | LRC |
| 15 | BCLK |
| 7 | DIN |
| GND | GND |
| 3.3/5V | VIN |
| ESP32 | INP441 |
| 4 | SCK |
| 5 | WS |
| 6 | SD |
| 3.3V | VDD |
| GND | GND |
INP441与MAX98357A未提及部分不需要接线,MAX98357A还需接喇叭,注意正负极,红色为正,黑色为负
开发环境:Arduino IDE
开发板选取:ESP32S3 Dev Module
流程如下(默认已经有了ESP32环境)
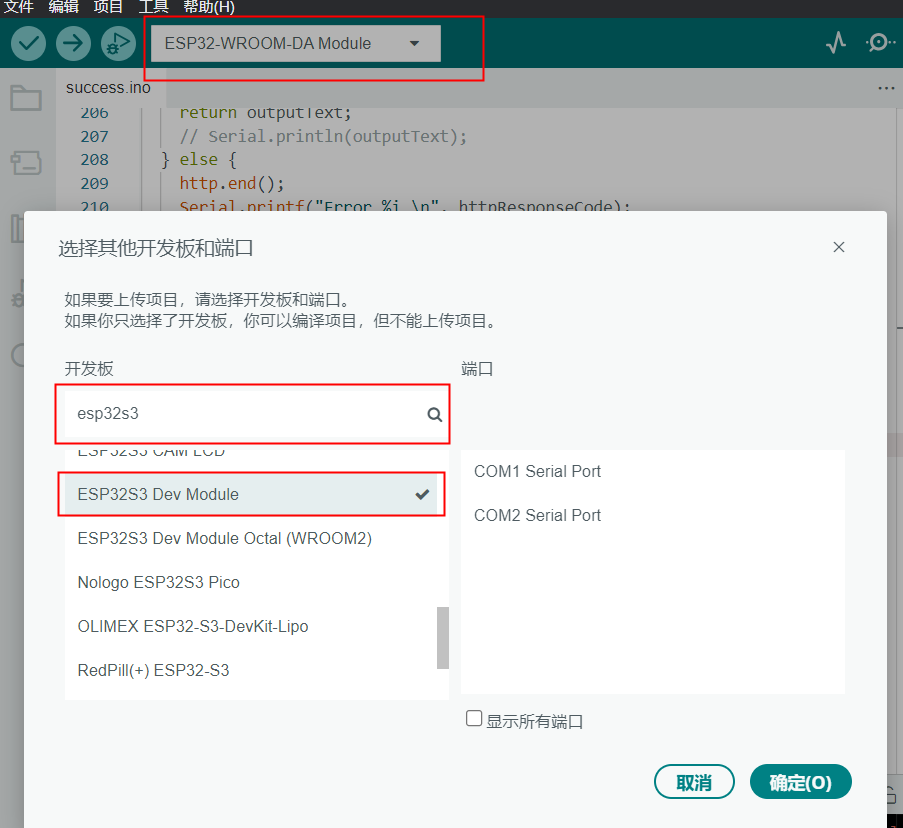
如果说这个方法找不到开发板,还有一种方法,具体流程如下
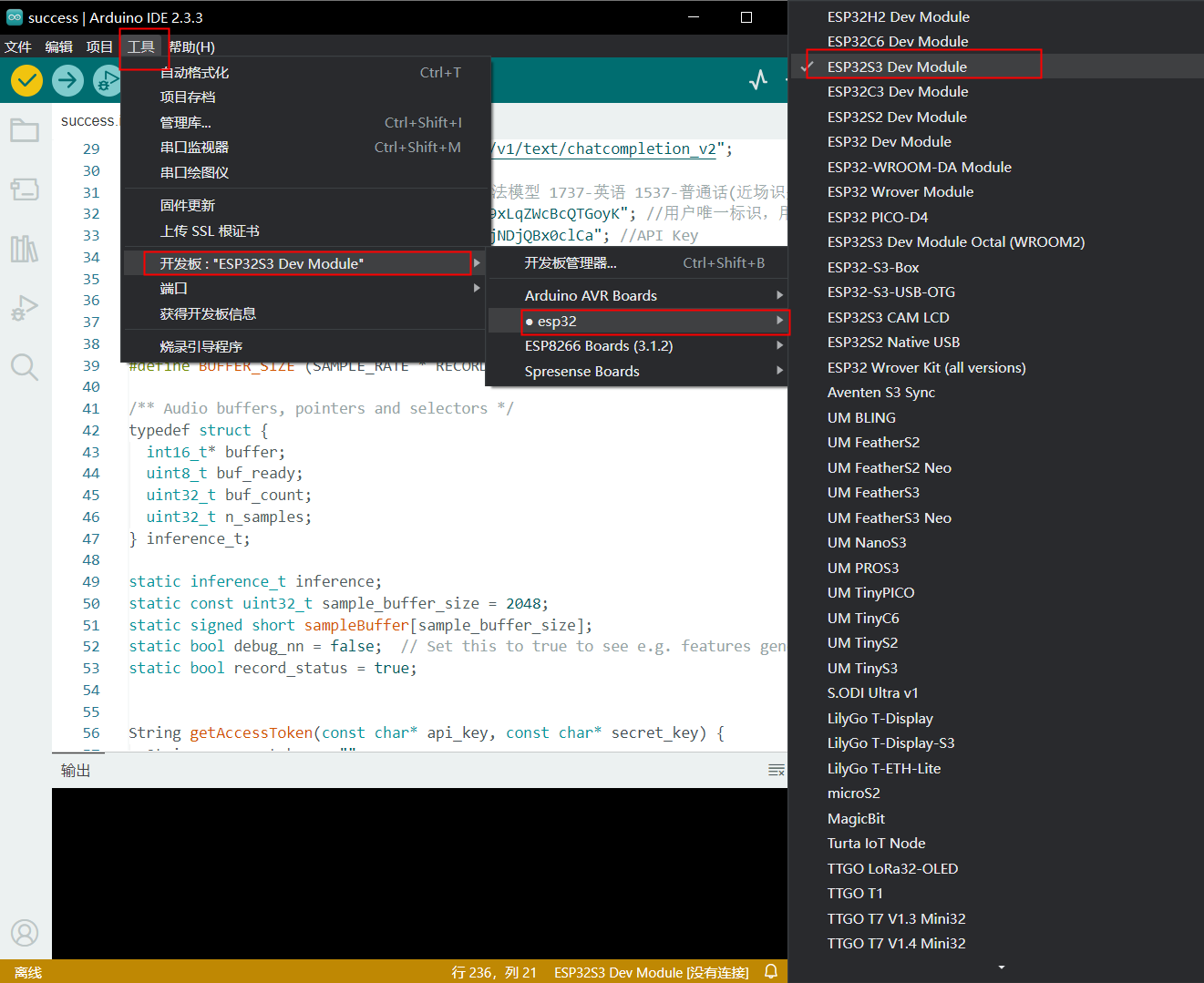
实现代码:(代码有bug)
#include <WiFi.h>
#include <HTTPClient.h>
#include <ArduinoJson.h>
#include <driver/i2s.h>
#include <UrlEncode.h>
#include <base64.hpp>
#include <string.h>
#include "cJSON.h"
// I2S config for MAX98357A
#define I2S_OUT_PORT I2S_NUM_1
#define I2S_OUT_BCLK 15
#define I2S_OUT_LRC 16
#define I2S_OUT_DOUT 7
// INMP441 config
#define I2S_IN_PORT I2S_NUM_0
#define I2S_IN_BCLK 4
#define I2S_IN_LRC 5
#define I2S_IN_DIN 6
// WiFi credentials
const char* ssid = "name";
const char* password = "password";
// 2. Replace with your OpenAI API key
const char* apiKey = "*******************";
// Send request to OpenAI API
String apiUrl = "https://api.minimax.chat/v1/text/chatcompletion_v2";
const int STT_DEV_PID = 1537; //选填,输入法模型 1737-英语 1537-普通话(近场识别模型) 1936-普通话远程识别 1837-四川话
const char *STT_CUID = "*****************8"; //用户唯一标识,用来区分用户,计算UV值。建议填写能区分用户的机器 MAC 地址或 IMEI 码,长度为60字符以内。
const char *STT_CLIENT_ID = "*****************8"; //API Key
const char *STT_CLIENT_SECRET = "*******************"; //Secret Key
// Audio recording settings
#define SAMPLE_RATE 16000
#define RECORD_TIME_SECONDS 15
#define BUFFER_SIZE (SAMPLE_RATE * RECORD_TIME_SECONDS)
/** Audio buffers, pointers and selectors */
typedef struct {
int16_t* buffer;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
static inference_t inference;
static const uint32_t sample_buffer_size = 2048;
static signed short sampleBuffer[sample_buffer_size];
static bool debug_nn = false; // Set this to true to see e.g. features generated from the raw signal
static bool record_status = true;
String getAccessToken(const char* api_key, const char* secret_key) {
String access_token = "";
HTTPClient http;
// 创建http请求
http.begin("https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + String(api_key) + "&client_secret=" + String(secret_key));
int httpCode = http.POST("");
if (httpCode == HTTP_CODE_OK) {
String response = http.getString();
DynamicJsonDocument doc(1024);
deserializeJson(doc, response);
access_token = doc["access_token"].as<String>();
Serial.printf("[HTTP] GET access_token: %s\n", access_token);
} else {
Serial.printf("[HTTP] GET... failed, error: %s\n", http.errorToString(httpCode).c_str());
}
http.end();
return access_token;
}
void wifi_setup() {
WiFi.mode(WIFI_STA);
WiFi.begin(ssid, password);
Serial.print("Connecting to WiFi ..");
while (WiFi.status() != WL_CONNECTED) {
Serial.print('.');
delay(1000);
}
Serial.println(WiFi.localIP());
Serial.println("Enter a prompt:");
}
void baiduTTS_Send(String access_token, String text) {
if (access_token == "") {
Serial.println("access_token is null");
return;
}
if (text.length() == 0) {
Serial.println("text is null");
return;
}
const int per = 1;
const int spd = 6;
const int pit = 5;
const int vol = 15;
const int aue = 6;
// 进行 URL 编码
String encodedText = urlEncode(urlEncode(text));
// URL http请求数据封装
String url = "https://tsn.baidu.com/text2audio";
const char* header[] = { "Content-Type", "Content-Length" };
url += "?tok=" + access_token;
url += "&tex=" + encodedText;
url += "&per=" + String(per);
url += "&spd=" + String(spd);
url += "&pit=" + String(pit);
url += "&vol=" + String(vol);
url += "&aue=" + String(aue);
url += "&cuid=esp32s3";
url += "&lan=zh";
url += "&ctp=1";
// http请求创建
HTTPClient http;
http.begin(url);
http.collectHeaders(header, 2);
int httpResponseCode = http.GET();
if (httpResponseCode > 0) {
if (httpResponseCode == HTTP_CODE_OK) {
String c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9238
9238


 到【灌水乐园】发言
到【灌水乐园】发言








