




硬件
服务器配置:鲲鹏2 * 920(32c)+ 4 * Atlas300I duo卡
参考文章
https://www.hiascend.com/developer/ascendhub/detail/07a016975cc341f3a5ae131f2b52399d
鲲鹏+昇腾Atlas300Iduo部署Embedding模型和Rerank模型并连接Dify(自用详细版)
下载准备
1.bge-m3模型:https://www.modelscope.cn/models/BAAI/bge-m3
2.封装好的docker容器:mis-tei:6.0.RC3-300I-Duo-aarch64(自己去昇腾社区申请)
3.安装好docker
部署bge-m3
(1)创建容器运行
docker run -u root -e ASCEND_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 -itd --name=tei-m3 --net=host \
-e HOME=/home/HwHiAiUser \
--privileged=true \
-v /home/BAAI/:/home/HwHiAiUser/model \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
--entrypoint /home/HwHiAiUser/start.sh \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mis-tei:6.0.RC3-300I-Duo-aarch64 \
BAAI/bge-m3 127.0.0.1 8068
(2)查看是否启动成功
docker logs tei-m3
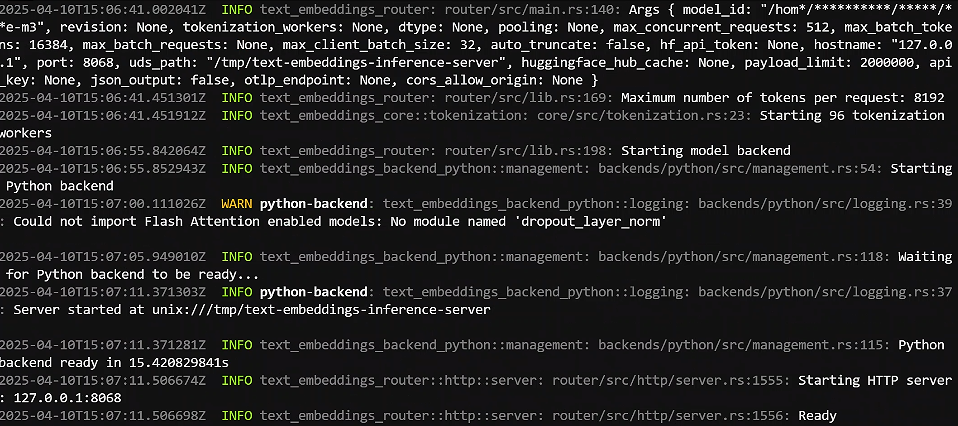
最后出现Ready成功
测试bge-m3
curl 127.0.0.1:8068/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json'
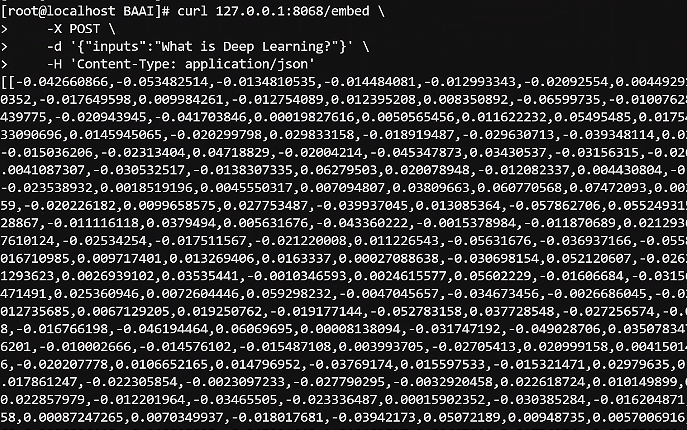
这样就成功了
API
http://127.0.0.1:8068/embed #这个就是创建的bge-m3的API,TEI格式
水一篇文章哈


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









