







 本文介绍如何在数据库中去除重复记录,包括统计重复数据、使用DISTINCT关键字和GROUP BY进行过滤等方法,并提供了一种通过创建临时表来清除重复数据的具体步骤。
本文介绍如何在数据库中去除重复记录,包括统计重复数据、使用DISTINCT关键字和GROUP BY进行过滤等方法,并提供了一种通过创建临时表来清除重复数据的具体步骤。
数据去重
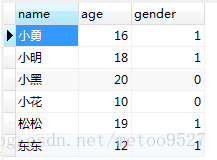
现有两个表 test_01 test_02 其中test_01有重复数据
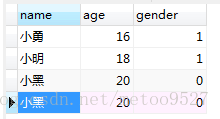
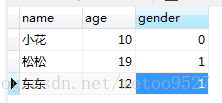
统计重复数据
select count(*) as repeat_count,name from test_01 group by name having repeat_count > 1;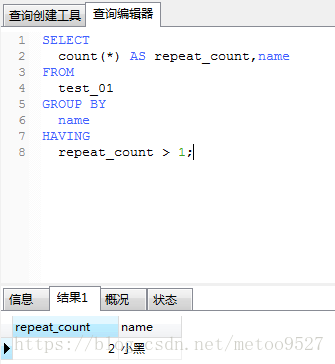
使用DISTINCT关键字过滤重复数据
select distinct name,age from test_01;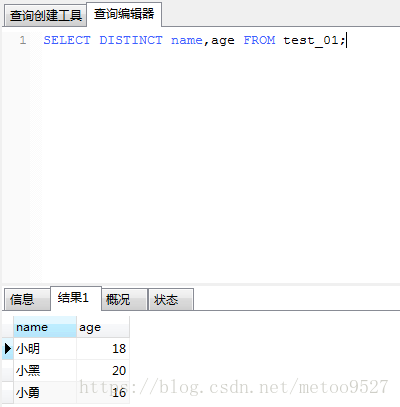
也可以使用GROUP BY过滤重复数据
select name,age,gender from test_01 group by name;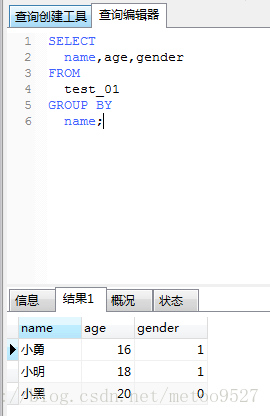
删除重复的数据,采用create table select方式从以上过滤完数据的查询结果中创建新表,作为临时表,然后把原来的表drop删除,再把临时表重命名为原来的表名
create table test_temp select name,age,gender from test_01 group by name;
drop table test_01;
alter table test_temp rename to test_01;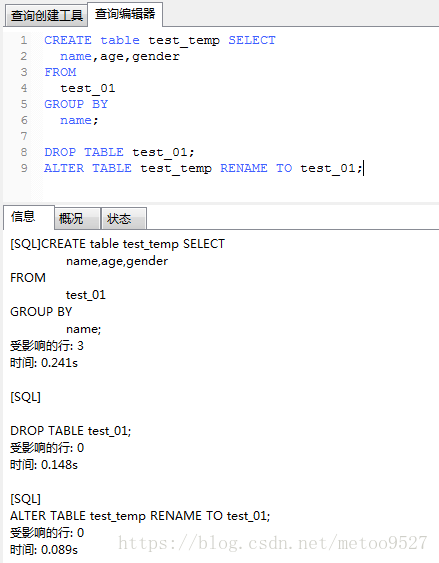
这样便得到了无重复数据的 test_01
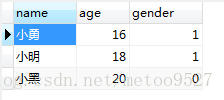
合并test_01 test_02(两表结构相同)采用暴力添加数据的方法,这里把test_02 表的数据合并到test_01表
insert into test_01(name,age,gender) select name,age,gender from test_02;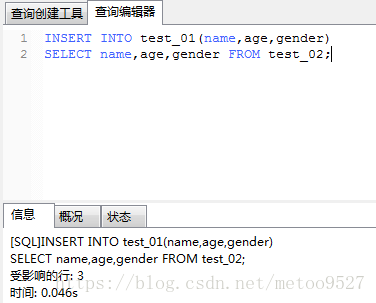
得到合并后的test_01

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









