



1 数据库的作用和分类
- 数据库是存储和管理数据的系统。
- CURD操作:
- create
- update
- read
- delete
- 分类:
- 关系型数据库(RDBMS)
- SQL数据库:MySQL
- 非关系型数据库
- NoSQL数据库:MongoDB
- 关系型数据库(RDBMS)
2 MySQL数据库
MySQL是目前最流行的关系型数据库管理系统之一。


- 数据库的增、删、改、查
- 数据表的增、删、改、查
- 表记录的增、删、改、查
- SQL语句的功能
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:数据库,表,列等。搭建保存数据的容器。
- 注意:DDL并涉及表中记录(数据)的操作!
- DML (Data Manipulation Language):数据操作语言,用来对数据库中的表记录进行增、删、改。
- DQL (Data Query Language):数据查询语言,用来查询数据库中表的记录。【重点学习】
- DCL (Data Control Language):数据控制语言,用来定义数据库的访问权限和安全级别,及创建用户。
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:数据库,表,列等。搭建保存数据的容器。
3 SQL-DDL 数据定义语言
3.1 创建数据库及创建表
# 查看数据库
show databases;
# 创建数据库
create database db_itpython;
create database if not exists db_itpython;
# 创建数据库建议直接设置编码格式
create database if not exists db_itpython default charset =utf8;
# 删除数据库
drop database db_itpython;# 创建数据库
create database if not exists bigdata_db default charset =utf8
# 查看数据库
show databases
# 指定使用的数据库
use bigdata_db
# 查看当前使用的数据库
select database()
# 删除数据库
drop database bigdata_dbuse db_itpython
# 创建表
create table tb_student(
id int,
name varchar(20),
age int,
gender enum('男','女'),
mobile char(11)
)default charset =utf8
# 查看数据表
show tables# 创建表
# decimal(字段长度,保留几位小数)
create table tb_goods(
id int,
goods_name varchar(20),
goods_price decimal(11,2),
store varchar(20)
)default charset =utf8;
# 查看表有哪些字段
desc tb_goods;
# 重命名表名
rename table tb_goods to tb_product;
# 查看表名
show tables;
# 删除数据表
drop table tb_product# 创建默认编码的数据库(公司1)
create database if not exists company_1;
# 创建编码为gbk的数据库(公司2)
create database if not exists company_2 default charset =gbk;
# 创建编码为utf8的数据库(公司3)
create database if not exists company_3 default charset =utf8;
# a查看有哪些数据库
show databases ;
# b 查看创建数据库(公司2)
show create database company_2;
# c.删除第2个数据库;
drop database company_2;
# d.查看当前使用数据库;
select database();
# e.切换使用数据库(公司3)等操作。
use company_3;3.2 常用数据类型
3.2.1 整数
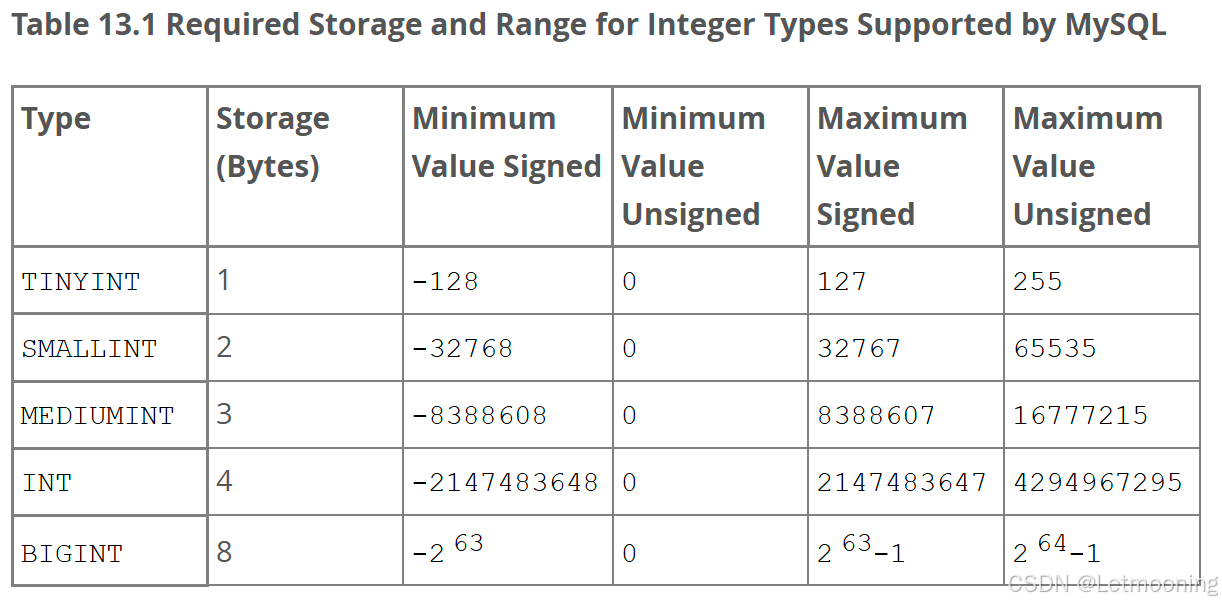
3.2.2 小数
小数:decimal,double,float
decimal(M, N),如decimal(5,2)表示共存5位数,小数占2位,存储小数要求没有误差时使用,比如:金钱
3.2.3 字符串
varchar,char,text
char表示固定长度的字符串,如char(3),如果填充'ab'时会补一个空格为'ab ',3表示字符数;最多保存255个字符。
varchar表示可变长度的字符串,如varchar(3),填充'ab'时就会存储'ab',3表示字符数;最多可保存2万汉字。
text 超过255个字符使用此类型
3.2.4 日期时间
date, time, datetime
3.3 数据约束
在类型限制的基础上给数据增加额外的限制。
- 主键 primary key:唯一标识表中的一行记录。 MySQL 建议所有表的主键字段都叫 id, 类型为 int unsigned。
- 非空 not null:此字段不允许填写空值。NULL表示空
- 惟一 unique:此字段的值不允许重复。
- 默认 default:当不填写字段对应的值会使用默认值,如果填写时以填写为准。
- 外键 foreign key:对关系字段进行约束, 当为关系字段填写值时, 会到关联的表中查询此值是否存在, 如果存在则填写成功, 如果不存在则填写失败并抛出异常。在一个表中是主键,在另一个表是非主键,而且这个字段是两张表的关联字段。
# 字段约束
# 主键约束 primary key 非空且唯一,例如id 可以设置为主键
# unique 字段必须具有唯一性,可以为空
# 非空约束 not null
drop table tb_student;
create table tb_student(
# 主键约束
id int primary key,
# 不能重复
name varchar(20) unique,
age int,
# 默认值约束,插入数据时,如果省略或使用default关键字会自动触发
gender enum('男','女') default '男',
# 非空约束
mobile char(11) not null
)default charset =utf8;
desc tb_student;
3.3.1 主键约束


3.3.2 主键自增

# 主键约束:非空、唯一、起到唯一标识作用;在一个表中,有且仅有1个主键,可以是1个字段,也可以是多个字段(联合主键)
show tables ;
drop table tb_student;
create table tb_student(
id int auto_increment,
name varchar(28),
age tinyint unsigned,
# 设置联合主键
primary key (id,name)
)default charset =utf8;
insert into tb_student values (null,'Tom',23);
insert into tb_student values (null,'Jack',24);
select * from tb_student# 清空操作与自动增长序列的关系
# delete from 删除表中的所有记录,数据表不重建,自动增长会继续之前的编号
select * from tb_student;
delete from tb_student where id=2;
insert into tb_student values (null,'Jack',23);
delete from tb_student;
insert into tb_student values (null,'Jack',23);
# truncate table 数据表名称,数据表会重建,自动增长会重置编号,再次从1开始编号
truncate table tb_student;
insert into tb_student values (null,'Jack',23);3.3.3 非空约束
# 非空约束
drop table tb_student;
create table tb_student(
id int auto_increment,
name varchar(28) not null,
age tinyint unsigned,
# 设置联合主键
primary key (id,name)
)default charset =utf8;
insert into tb_student values (null,'Tom',23);
select * from tb_student;
insert into tb_student values (null,null,23);3.3.4 唯一约束
# 唯一约束
drop table tb_student;
create table tb_student(
id int auto_increment,
name varchar(28) unique,
age tinyint unsigned,
# 设置联合主键
primary key (id,name)
)default charset =utf8;
insert into tb_student values (null,'Tom',23);
insert into tb_student values (null,'Tom',23);3.3.5 默认值约束
# 默认值约束
drop table tb_student;
create table tb_student(
id int auto_increment,
name varchar(28) unique,
age tinyint unsigned default 18,
# 设置联合主键
primary key (id,name)
)default charset =utf8;
insert into tb_student (id,name) values (null,'Tom');
insert into tb_student values (null,'Rose',default);
insert into tb_student values (null,'Jack',20);
select * from tb_student;3.4 表字段操作
3.4.1 添加表字段

3.4.2 修改、删除表字段
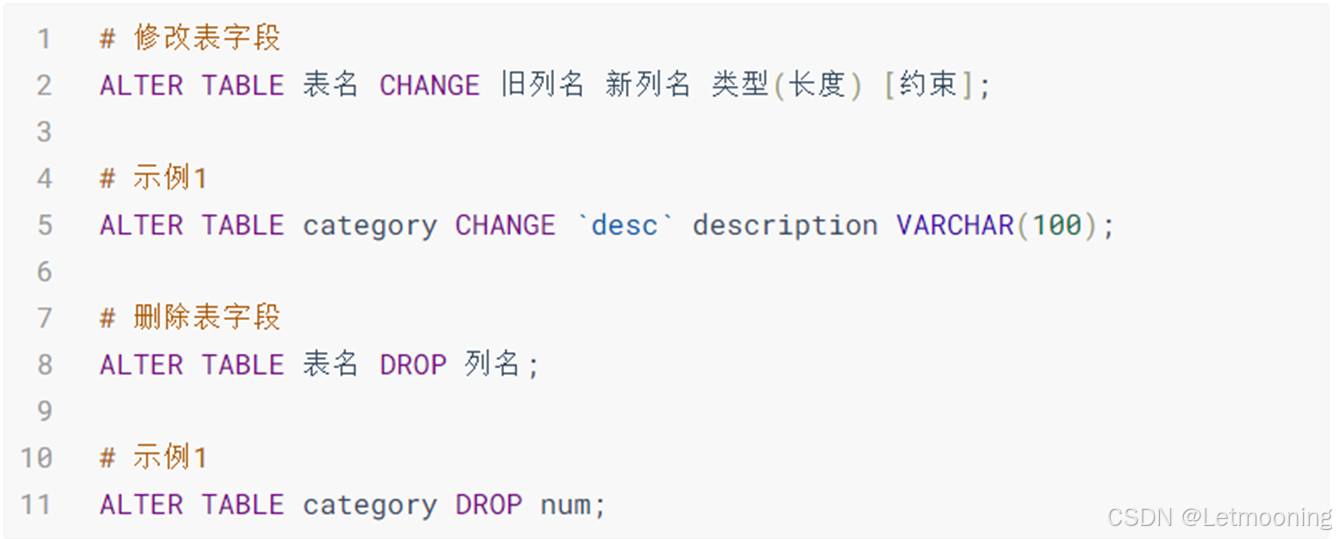
# 创建表
create table tb_category(
id int primary key
)default charset =utf8;
# 字段管理
# 添加字段
alter table tb_category add name varchar(20) after id;
desc tb_category;
# 修改字段
alter table tb_category add `desc` varchar(255) after name;
desc tb_category;
# 重命名字段
alter table tb_category change `desc` description varchar(255);
desc tb_category;
# 删除字段
alter table tb_category drop description;
desc tb_category;4 SQL-DML数据操作语言
4.1 增加表记录
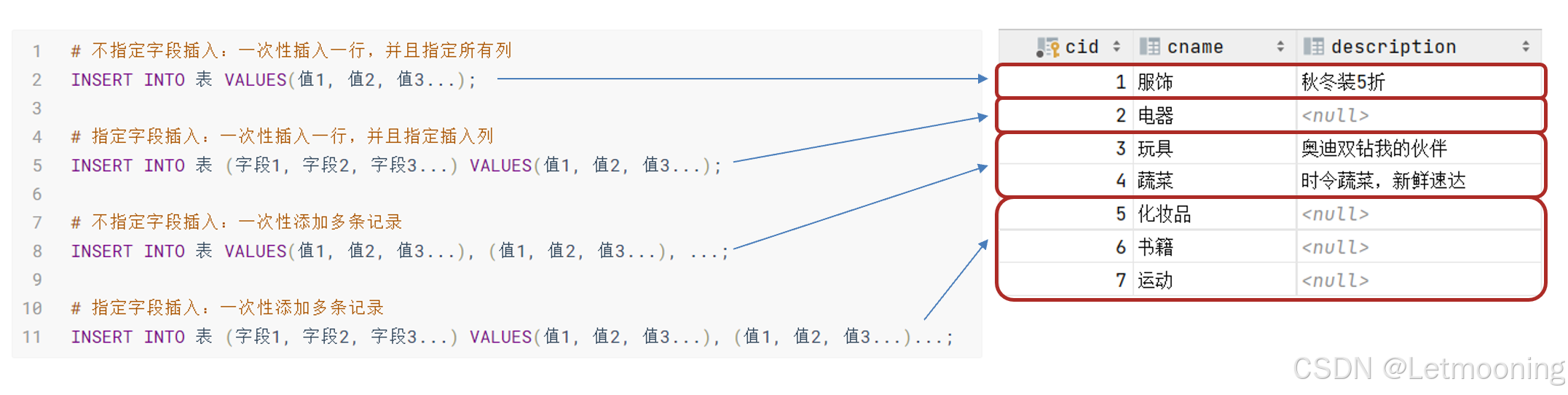
create table tb_category(
cid int primary key ,
cname varchar(20),
description varchar(255)
)default charset =utf8;
# 插入数据
insert into tb_category values(1,'服饰','秋冬5折');
insert into tb_category(cid,cname) values (2,'电器');
insert into tb_category values
(3,'玩具','奥迪双钻'),(4,'蔬菜','时令蔬菜');
insert into tb_category(cid,cname) values (5,'化妆品'),(6,'书籍'),(7,'运动');
select * from tb_category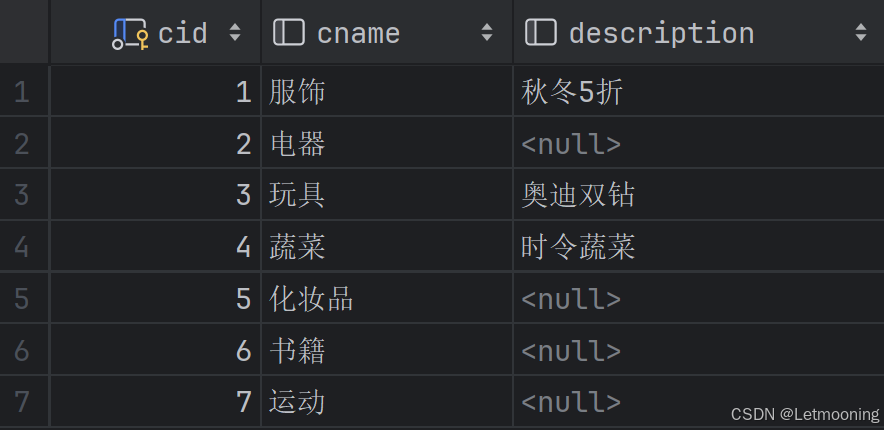
4.2 更新表记录

# 更新表记录
update tb_category set cname='家电';
select * from tb_category;
# 给更新表记录添加条件
update tb_category set cname='服装' where cid=1;
select * from tb_category;4.3 删除表记录

删除表满足条件的记录
delete from tb_category where cid=5;
select * from tb_category;
# 删除所有记录(只是把数据删除,表不会重建,自增序列删除)
delete from tb_category;
select * from tb_category;
# 清空所有记录(不仅会删除所有内容,还会重建数据表)
truncate table tb_category;
select * from tb_category;5 SQL-DQL数据查询语言
5.1 简单查询

查询5子句:
where=>条件查询
group by=>分组查询
having=>分组查询的过滤条件
order by =>排序查询
limit=>限制查询,分页查询
5.2 条件查询
![]()
条件运算符:
1.
比较运算符:
=
、
>
、
<
、
>=
、
<=
、
!=
、
<>
2.
逻辑运算符:
AND
(
并且
)
、
OR
(
或者
)
、
NOT
(
非、取反
)
3.
LIKE
模糊查询
%
:表示任意多个任意字符
_
:表示任意一个字符
4.
范围查询
BETWEEN ... AND ...
表示在一个连续的范围内查询
IN
表示在一个非连续的范围内查询
5.
空值判断:
IS NULL
和
IS NOT NULL
# %代表任意多个字符
# 中间包含note
select * from goods where name like '%note%';
# 以note开头
select * from goods where name like 'note%';
# 以note结尾
select * from goods where name like '%note';
# _代表任意的某一个字符
# 查询商品名称为5个字符的所有商品
select * from goods where name like '_____';# 范围查询
select * from goods where price between 2000 and 3000;
select * from goods where price>=2000 and price<=3000;
select * from goods where score in (9.50,9.70);
select * from goods where score=9.50 or score=9.70# 空值与非空值判断
select * from goods where score is null;
select * from goods where score is not null;5.3 聚合函数
又叫组函数、统计函数,用来对表中的指定列数据进行统计计算。
count() 求总数
sum() 求和
avg() 求平均值
max() 求最大值
min() 求最小值
聚合函数计算会忽略null 值。
select count(*) from goods;
select count(id) from goods;
select count(score) from goods;
select sum(price) 总价格 from goods;
select avg(price) 平均价格 from goods;
select max(price) from goods;
select min(price) from goods;5.4 分组函数
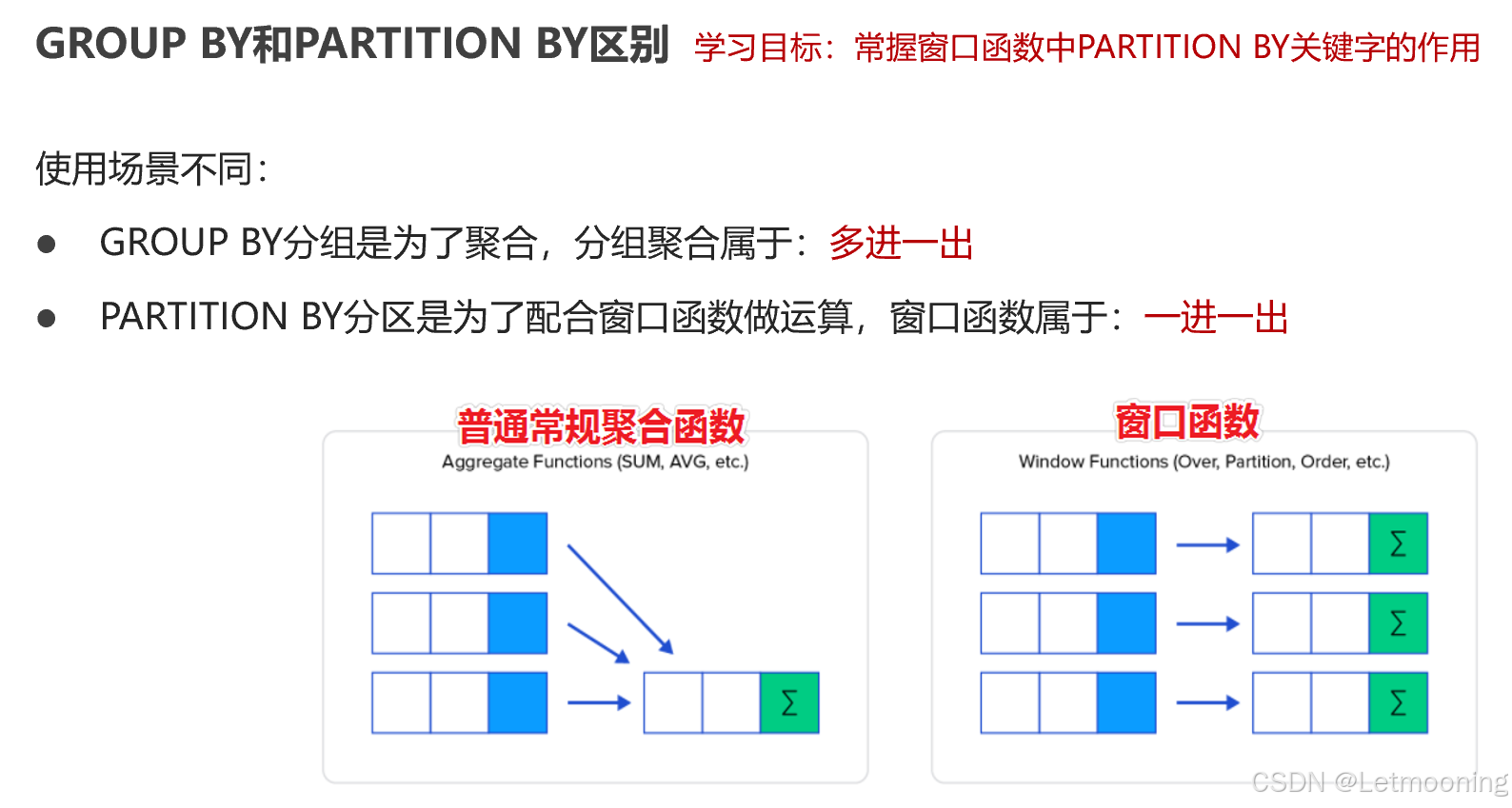
group by 分组聚合分两步:先分组、再聚合。

select category_id,count(category_id) cnt from goods group by category_id;
# 聚合字段需要出现在select后面
select category_id,is_self,count(category_id) from goods
group by category_id,is_self;
5.5 过滤函数
having 发生在分组之后
where 发生在分组之前


# 分组字段、聚合字段需要出现在select后面
select category_id,is_self,count(category_id) from goods
group by category_id,is_self;
# having在无聚合的情况下可以替代where
select * from goods where price>3000;
select * from goods having price>3000;
select category_id,avg(price) from goods
group by category_id having avg(price)<1000;
select category_id,avg(price) avg_price from goods
group by category_id having avg_price<1000;
# 重点
select category_id,avg(price) from goods
where is_self='自营'
group by category_id
having avg(price)>2000;5.6 去重查询
select distinct name from goods;
select name from goods group by name;
# (name,price 作为整体)
select distinct name,price from goods;5.7 排序查询

select name,price from goods order by price;
select * from goods order by score desc;
# 多字段排序,通excel的排序逻辑
select * from goods order by score desc,price;5.8 Limit查询(分页查询)

# 获取id 2/3/4
select * from goods limit 1,3;
# 获取一条记录
select * from goods order by price limit 1;
select * from goods order by price limit 0,1;
# 12条,每页3条,分4页
select * from goods order by price limit 3,3;
# 分页公式 (当前页-1)*每页条数,每页条数
# 每页5条,第三页
# limit (3-1)*5,55.9 SQL执行顺序

![]()
6 多表关联查询
表之间的关系:一对一、一对多、多对多
6.1 笛卡尔积(cross join)
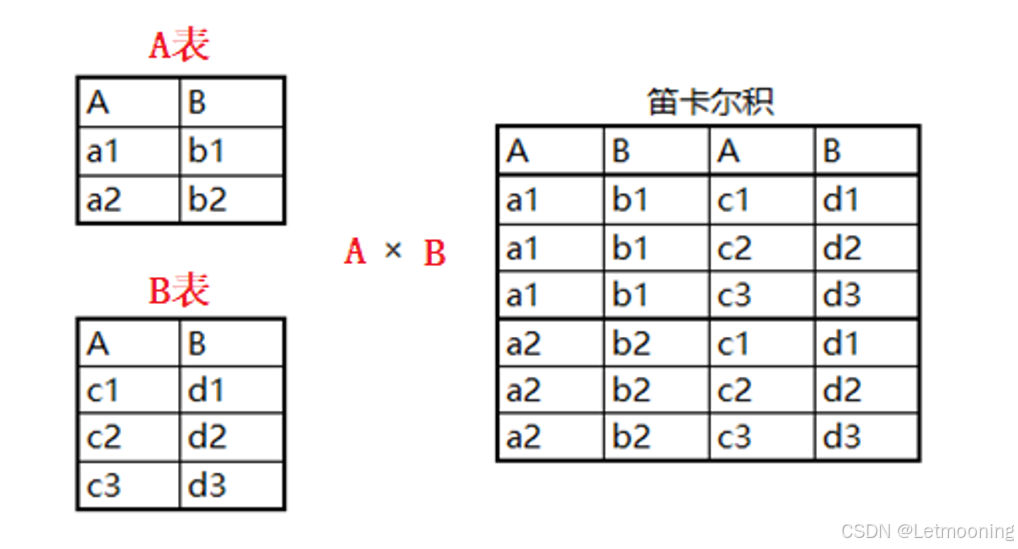
# 交叉连接,字段数等于字段之和,记录数等于两者记录的乘积
select * from category join goods;
# 重点
select * from category,goods;6.2 有条件连接查询

6.2.1 内连接
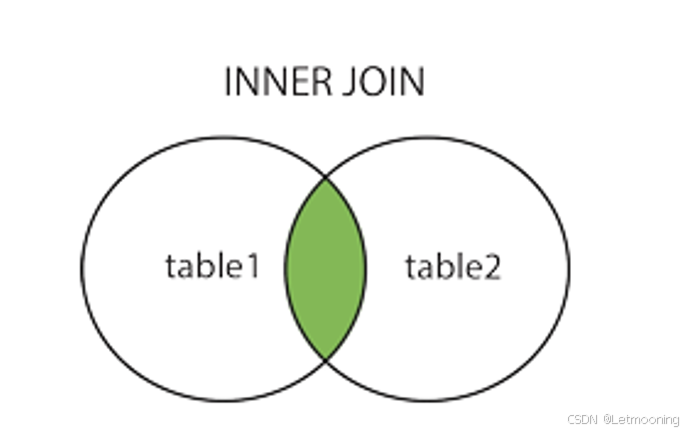
select category.id,category.name,goods.id,goods.name from category join goods
on category.id = goods.category_id;
select
c.id,c.name cname,
g.id,g.name gname
from category c
join goods g
on c.id=g.category_id;6.2.2 左连接(左外连接)
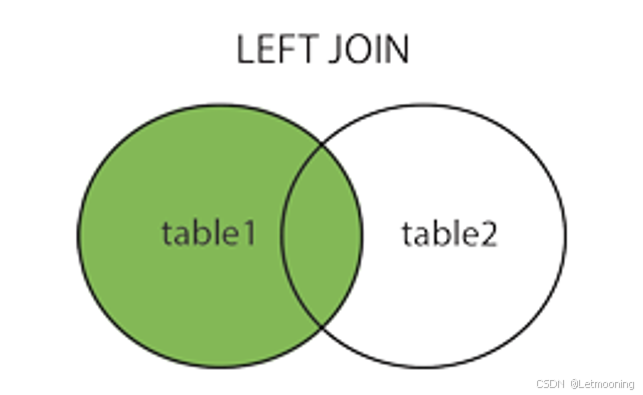
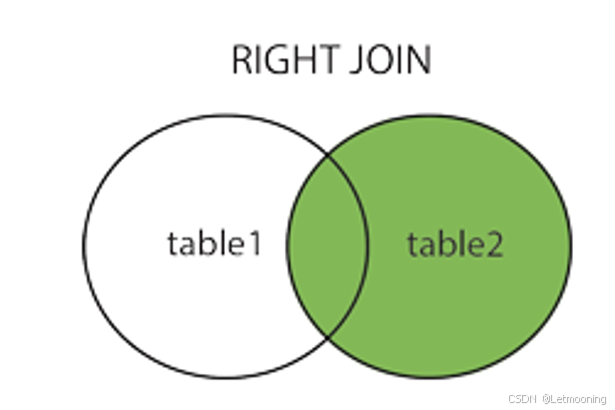
6.2.3 右连接(右外连接)
# 左外连接
select
c.id,c.name cname,
g.id,g.name gname
from category c left join goods g
on c.id = g.category_id;
# 右外连接
select
c.id,c.name cname,
g.id,g.name gname
from category c right join goods g
on c.id = g.category_id;6.2.4 全外连接(mysql不支持)
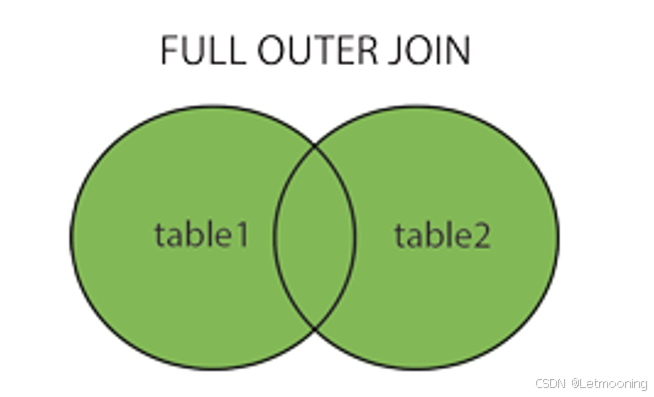
可用union模拟全外连接
# union把两张表进行纵向合并:字段个数和类型必须相同;字段顺序必须相同
# union all 不去重;union去重
select
c.id,c.name cname,
g.id,g.name gname
from category c left join goods g
on c.id = g.category_id
union
select
c.id,c.name cname,
g.id,g.name gname
from category c right join goods g
on c.id = g.category_id;7 外键约束
级联删除;级联更新
-- 创建一个大哥表
create table dage(
id int not null auto_increment,
name varchar(20),
primary key(id)
) engine=innodb default charset=utf8;
-- 添加测试数据
insert into dage values (null, '陈浩南');
insert into dage values (null, '乌鸦');
-- 创建一个小弟表
create table xiaodi(
id int not null auto_increment,
name varchar(20),
dage_id int,
primary key(id)
) engine=innodb default charset=utf8;
-- 添加一个外键约束(重点)
alter table xiaodi add foreign key(dage_id)
references dage(id) on delete cascade;
desc xiaodi;
show create table xiaodi;
-- 插入测试数据
insert into xiaodi values (null, '山鸡', 1);
insert into xiaodi values (null, '大天二', 1);
insert into xiaodi values (null, '乌鸦的小弟', 2);
-- 测试外键约束的级联删除功能
delete from dage where id = 2;
select * from dage;
select * from xiaodi;8 子查询
select * from goods
where price>(
select avg(price) from goods
); 
# 查询所有类别的平均价格,然后显示对应的分类名称
select category_id,avg(price) `avg` from goods group by category_id;
select t2.id,t2.name,t1.`avg` from (
select category_id,avg(price) `avg` from goods group by category_id
)t1 join category t2 on t1.id=t2.iddrop table students;
create table `students` (
`id` int(11) not null auto_increment,
`name` varchar(24) not null,
`gender` varchar(8) not null,
`score` decimal(5,2) not null,
primary key (`id`)
) engine=innodb default charset=utf8;
insert into `students` values
(1,'smart','male',90.00),(2,'linda','female',81.00),
(3,'lucy','female',83.00),(4,'david','male',94.00),
(5,'tom','male',92.00),(6,'jack','male',88.00);
-- ①编写子查询
select avg(score) from students;
-- ②把子查询结果填充到主查询中
select id,name,gender,score,
(平均成绩) as avg_sore,
score-(平均成绩) as difference
from students;
-- ③替换伪代码
select id,name,gender,score,
(select avg(score) from students) as avg_sore,
score-(select avg(score) from students) as difference
from students;9 窗口函数
聚合函数+over()

9.1 特点
1)简单
窗口函数更易于使用。
窗口函数是
MySQL8.0
以后加入的功能,之前需要通过定义临时变量和大量的子查询或关联才能完成的工作,使用窗口函数实现起来更加简洁高效。
窗口函数也是面试及实际工作的高频点
。
2)快速
使用窗口函数比使用替代方法要快得多。当你处理成百上千个千兆字节的数据时,这非常有用。
3)多功能性
最重要的是,窗口函数具有多种功能,比如:
求差值、求占比、求排名、累计值计算
等等。
9.2 语法
# 子查询充当临时表
# 查询不同类型商品的平均价格,结果中包含分类的名称
select category_id,avg(price) `avg` from goods group by category_id;
select t2.id,t2.name,t1.avg
from category t2 join
(select category_id,avg(price) `avg` from goods group by category_id) t1
on t1.category_id=t2.id;# 基本语法 聚合函数()+over()/排名函数+over()
select *,avg(score) over() avg_score,
score- avg(score) over() as differernce
from students;
# 求每个学生的成绩占总成绩的占比
select *,sum(score) over() as 'sum',
score/sum(score) over()*100 as ratio
from students;
-- partition by不仅会分组,而且会保存之前全部的字段
select *,avg(score) over(partition by gender) as avg_score,
score-avg(score) over(partition by gender) as difference
from students;# 排名函数
# rank 有并列,排名不连续
# dense_rank 有并列,且排名连续
# row_number 无并列,但连续
-- 准备数据集
create table `tb_score` (
`name` varchar(24) not null,
`course` varchar(24) not null,
`score` decimal(5,2) not null
) engine=innodb default charset=utf8;
insert into `tb_score` values ('张三','语文',81.00),('张三','数学',75.00),('李四','语文',76.00),('李四','数学',90.00),('王五','语文',81.00),('王五','数学',100.00);
-- rank()、dense_rank()、row_number()
select
*,
rank() over(order by score desc) as `rank`,
dense_rank() over(order by score desc) as `dense_rank`,
row_number() over(order by score desc) as `row_number`
from tb_score; 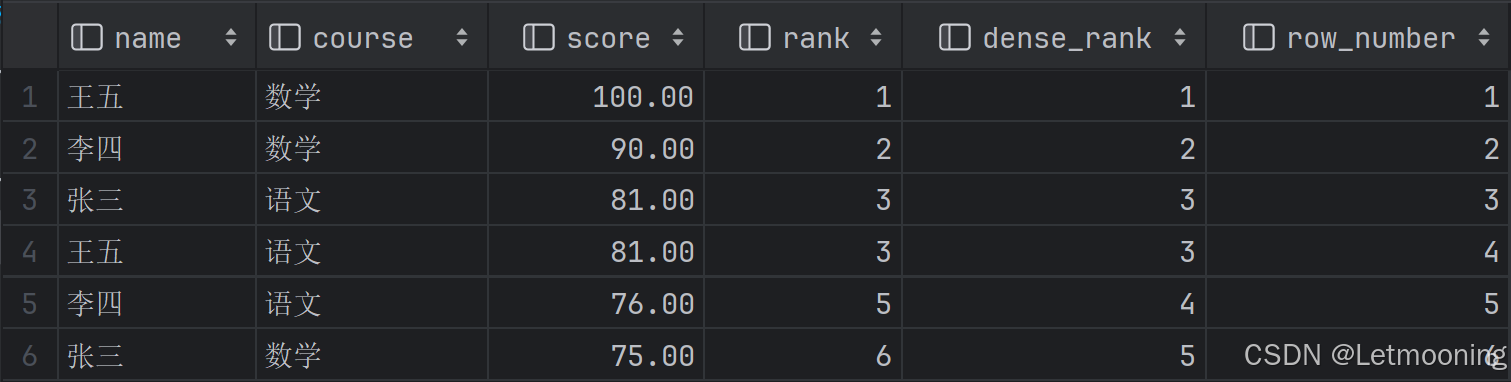
-- TopN问题--
select *,
dense_rank() over(partition by course order by score) as rn
from tb_score;
# 如果把子查询作为一张表,则需要起一个名字
select * from
(
select *,
dense_rank() over(partition by course order by score) as rn
from tb_score
)tmp
where rn=2;10 CASE WHEN

select name,course,score,
case
when score>=90 then '优秀'
when score>=80 then '良好'
when score>=70 then '中等'
when score>=60 then '及格'
else '不及格'
end as grade
from tb_score;小测试:
主键primary key和unique的区别?
时间查询
-- 需求9: 另一种常见的报表需求是查询某段时间内的业务指标, 我们统计2016年7月的订单数量,
# select * from orders;
select count(order_id) 订单数量 from orders
where order_date >= '2016-07-01' and order_date<'2016-08-01';
-- 模糊查询
select count(order_id) 订单数量 from orders where order_date like '2016-07%';
-- 等值查询
select count(order_id) 订单数量 from orders
where year(order_date)=2016 and month(order_date)=7;
-- 范围查询(between and 是前闭后闭的)
select count(order_id) 订单数量 from orders
where order_date between '2016-07-01' and '2016-07-31';IF 语句
-- 需求24: 在引入北美地区免运费的促销策略时,我们也想知道运送到北美地区和其它国家地区的订单数量
-- 促销策略, 参见需求21的代码.
# select ship_country, count(order_id) 订单数量
# from orders
# group by ship_country;
select
count(if(ship_country in ('USA', 'Canada'), 1, null)) as 北美地区订单总数,
count(if(ship_country not in ('USA', 'Canada'), 1, null)) as 其它地区订单总数
from orders;
select
count(case when ship_country in ('USA','Canada') then 1 end)
as 北美地区订单总数,
count(case when ship_country not in ('USA','Canada') then 1 end)
as 其它地区订单总数
from orders;

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









