









 本文介绍三种处理数据集中类别不平衡的方法:使用pandas进行过采样、使用imblearn模块进行下采样和上采样,以及结合裁剪数据与生成新数据。通过实际代码示例展示了如何实现这些方法。
本文介绍三种处理数据集中类别不平衡的方法:使用pandas进行过采样、使用imblearn模块进行下采样和上采样,以及结合裁剪数据与生成新数据。通过实际代码示例展示了如何实现这些方法。
方法一: 直接使用pandas.sample(frac=2.0)(过采样)
oversample = train_df.sample(frac=2.2, resample=True)
downsample = train_df.sample(frac=0.2)
方法二: 使用python的imblearn模块
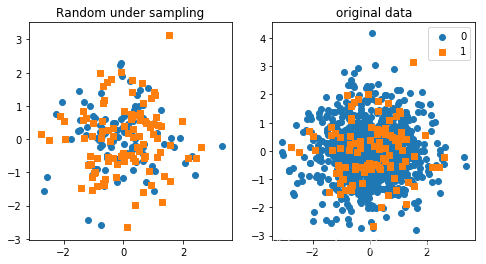
下采样:
from imblearn.under_sampling import RandomUnderSampler
ran = RandomUnderSampler(return_indices=True)
x_rs, y_rs, dropped = ran.fit_sample(X, y)
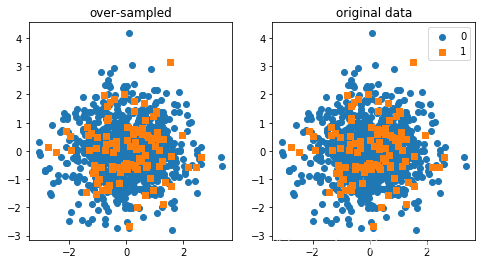
上采样;
from imblearn.over_sampling import RandomOverSampler
ran=RandomOverSampler()
X_ran,y_ran= ran.fit_resample(X,y)
 方法三:使用imblearn自动裁剪数据和生成新的数据
方法三:使用imblearn自动裁剪数据和生成新的数据
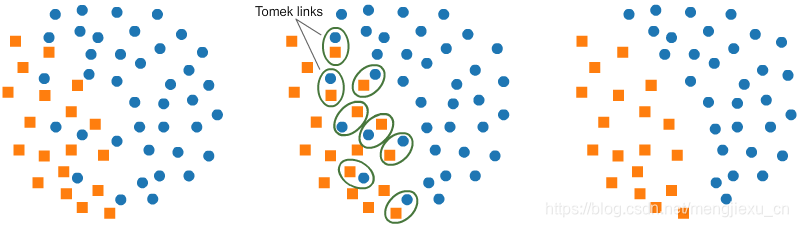
删除临界值来下采样:
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(return_indices=True, ratio='majority')
X_tl, y_tl, id_tl = tl.fit_sample(X, y)
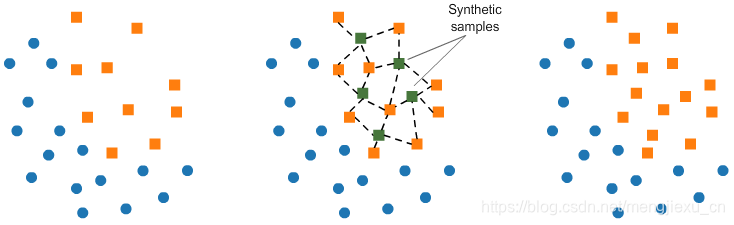
 生成新数据来上采样:
生成新数据来上采样:
from imblearn.over_sampling import SMOTE
smote = SMOTE(ratio='minority')
X_sm, y_sm = smote.fit_sample(X, y)
Reference:
https://www.kaggle.com/shahules/tackling-class-imbalance

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









