




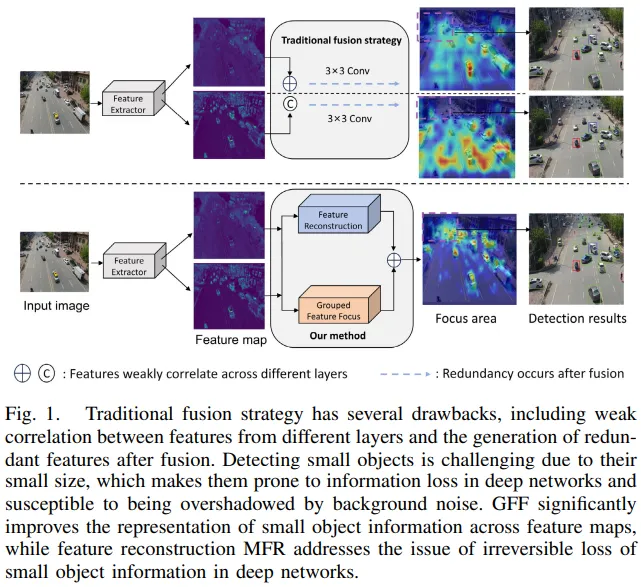
1. EFC: 基于增强层间特征关联的轻量级即插即用融合策略
1.1 概述
由于低分辨率和背景混合,检测无人机图像中的小物体具有挑战性,导致特征信息有限。多尺度特征融合可以通过获取不同尺度上的信息来增强检测能力,但传统的方法存在不足。简单的连接或加法运算不能充分利用多尺度融合的优点,导致特征之间的相关性不足。这一不足阻碍了对小物体的检测,特别是在复杂背景和人口稠密地区。为了解决这一问题并有效地利用有限的计算资源,提出了一种基于增强层间特征相关性(EFC)的轻量级融合策略,以取代传统的特征金字塔网络(FPN)中的特征融合策略。特征金字塔中不同图层的语义表达不一致。在EFC中,分组的特征聚焦单元(GFF)通过聚焦不同特征的上下文信息来增强各层的特征相关性。多级特征重构模块(MFR)对金字塔中各层的强弱信息进行有效的重构和变换,减少冗余特征融合,保留更多的小目标信息。值得注意的是,所提出的方法是即插即用的,并且可以广泛地应用于各种基础网络。
1.2 基本原理
EFC (Enhanced Inter-layer Feature Correlation) 模块是一种轻量级的特征融合策略,旨在提升小物体检测的性能,尤其是在复杂的背景中。以下是对 EFC 模块各组成部分的详细介绍:
- 特征关联增强:
EFC 模块通过引入 Grouped Feature Focusing Unit (GFF) 来强化不同层之间的特征关联性。GFF 通过关注特征的空间上下文信息,聚合邻近层的特征,使得特征之间的语义表示更加一致和丰富。这种对上下文信息的聚焦有助于解决小物体特征的不确定性问题,使模型能够更好地定位小物体。
- 特征重构:
EFC 中的 Multi-Level Feature Reconstruction Module (MFR) 关键在于有效利用各层的特征,而不是仅依赖于简单的卷积操作。MFR 模块能够分离强弱特征信息,通过对特征进行重构,来最大程度地保留对于小物体检测至关重要的细节信息,降低语义偏差。这使得模型在不同层次的特征融合中,能够更精确地理解小物体的空间位置和语义内容。
- 冗余特征的减少:
EFC 特别设计时考虑到了减少冗余特征生成的方法。传统的特征融合常常使用大型卷积核,导致冗余信息的产生,而 EFC 通过采用小型卷积或者轻量级卷积设计,降低了计算复杂度,并在不损失信息的前提下,使得输出特征更加精炼和有用。
- 通用性和适应性:
EFC 模块设计为“插件式”,可以广泛应用于多种特征金字塔网络(FPN)框架,提供了更灵活的检测模型适应能力。这种普遍适用性使得 EFC 可以与不同基础网络结合,进一步提升各种目标检测任务中的表现。
通过上述原理,EFC 模块能够有效应对小物体检测中的挑战,尤其是在多尺度和复杂背景下,增强了特征表达能力,最终实现了更高的检测精度和效率【T2】【T3】【T5】。
1.3 核心代码
import torch.nn as nn
import torch.nn.functional as F
from mmcv.cnn import ConvModule
from mmcv.runner import BaseModule, auto_fp16
from ..builder import NECKS
class EFC(BaseModule):
def __init__(self,
c1, c2
):
super().__init__()
self.conv1 = nn.Conv2d(c1, c2, kernel_size=1, stride=1)
self.conv2 = nn.Conv2d(c2, c2, kernel_size=1, stride=1)
self.conv4 = nn.Conv2d(c2, c2, kernel_size=1, stride=1)
self.bn = nn.BatchNorm2d(c2)
self.sigomid = nn.Sigmoid()
self.group_num = 16
self.eps = 1e-10
self.gamma = nn.Parameter(torch.randn(c2, 1, 1))
self.beta = nn.Parameter(torch.zeros(c2, 1, 1))
self.gate_genator = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(c2, c2, 1, 1),
nn.ReLU(True),
nn.Softmax(dim=1),
)
self.dwconv = nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1, groups=c2)
self.conv3 = nn.Conv2d(c2, c2, kernel_size=1, stride=1)
self.Apt = nn.AdaptiveAvgPool2d(1)
self.one = c2
self.two = c2
self.conv4_gobal = nn.Conv2d(c2, 1, kernel_size=1, stride=1)
for group_id in range(0, 4):
self.interact = nn.Conv2d(c2 // 4, c2 // 4, 1, 1, )
def forward(self, x):
x1, x2 = x
global_conv1 = self.conv1(x1)
bn_x = self.bn(global_conv1)
weight_1 = self.sigomid(bn_x)
global_conv2 = self.conv2(x2)
bn_x2 = self.bn(global_conv2)
weight_2 = self.sigomid(bn_x2)
X_GOBAL = global_conv1 + global_conv2
x_conv4 = self.conv4_gobal(X_GOBAL)
X_4_sigmoid = self.sigomid(x_conv4)
X_ = X_4_sigmoid * X_GOBAL
X_ = X_.chunk(4, dim=1)
out = []
for group_id in range(0, 4):
out_1 = self.interact(X_[group_id])
N, C, H, W = out_1.size()
x_1_map = out_1.reshape(N, 1, -1)
mean_1 = x_1_map.mean(dim=2, keepdim=True)
x_1_av = x_1_map / mean_1
x_2_2 = F.softmax(x_1_av, dim=-1)
x1 = x_2_2.reshape(N, C, H, W)
x1 = X_[group_id] * x1
out.append(x1)
out = torch.cat([out[0], out[1], out[2], out[3]], dim=1)
N, C, H, W = out.size()
x_add_1 = out.reshape(N, self.group_num, -1)
N, C, H, W = X_GOBAL.size()
x_shape_1 = X_GOBAL.reshape(N, self.group_num, -1)
mean_1 = x_shape_1.mean(dim=2, keepdim=True)
std_1 = x_shape_1.std(dim=2, keepdim=True)
x_guiyi = (x_add_1 - mean_1) / (std_1 + self.eps)
x_guiyi_1 = x_guiyi.reshape(N, C, H, W)
x_gui = (x_guiyi_1 * self.gamma + self.beta)
weight_x3 = self.Apt(X_GOBAL)
reweights = self.sigomid(weight_x3)
x_up_1 = reweights >= weight_1
x_low_1 = reweights < weight_1
x_up_2 = reweights >= weight_2
x_low_2 = reweights < weight_2
x_up = x_up_1 * X_GOBAL + x_up_2 * X_GOBAL
x_low = x_low_1 * X_GOBAL + x_low_2 * X_GOBAL
x11_up_dwc = self.dwconv(x_low)
x11_up_dwc = self.conv3(x11_up_dwc)
x_so = self.gate_genator(x_low)
x11_up_dwc = x11_up_dwc * x_so
x22_low_pw = self.conv4(x_up)
xL = x11_up_dwc + x22_low_pw
xL = xL + x_gui
return xL
1.4 引入代码
在根目录下的ultralytics/nn/目录,新建一个 featureFusion目录,然后新建一个以 EFC 为文件名的py文件, 把代码拷贝进去。
import torch
import torch.nn as nn
import torch.nn.functional as F
class EFC(nn.Module):
def __init__(self,
c1, c2
):
super().__init__()
self.conv1 = nn.Conv2d(c1, c2, kernel_size=1, stride=1)
self.conv2 = nn.Conv2d(c2, c2, kernel_size=1, stride=1)
self.conv4 = nn.Conv2d(c2, c2, kernel_size=1, stride=1)
self.bn = nn.BatchNorm2d(c2)
self.sigomid = nn.Sigmoid()
self.group_num = 16
self.eps = 1e-10
self.gamma = nn.Parameter(torch.randn(c2, 1, 1))
self.beta = nn.Parameter(torch.zeros(c2, 1, 1))
self.gate_genator = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(c2, c2, 1, 1),
nn.ReLU(True),
nn.Softmax(dim=1),
)
self.dwconv = nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1, groups=c2)
self.conv3 = nn.Conv2d(c2, c2, kernel_size=1, stride=1)
self.Apt = nn.AdaptiveAvgPool2d(1)
self.one = c2
self.two = c2
self.conv4_gobal = nn.Conv2d(c2, 1, kernel_size=1, stride=1)
for group_id in range(0, 4):
self.interact = nn.Conv2d(c2 // 4, c2 // 4, 1, 1, )
def forward(self, x):
x1, x2 = x
global_conv1 = self.conv1(x1)
bn_x = self.bn(global_conv1)
weight_1 = self.sigomid(bn_x)
global_conv2 = self.conv2(x2)
bn_x2 = self.bn(global_conv2)
weight_2 = self.sigomid(bn_x2)
X_GOBAL = global_conv1 + global_conv2
x_conv4 = self.conv4_gobal(X_GOBAL)
X_4_sigmoid = self.sigomid(x_conv4)
X_ = X_4_sigmoid * X_GOBAL
X_ = X_.chunk(4, dim=1)
out = []
for group_id in range(0, 4):
out_1 = self.interact(X_[group_id])
N, C, H, W = out_1.size()
x_1_map = out_1.reshape(N, 1, -1)
mean_1 = x_1_map.mean(dim=2, keepdim=True)
x_1_av = x_1_map / mean_1
x_2_2 = F.softmax(x_1_av, dim=1)
x1 = x_2_2.reshape(N, C, H, W)
x1 = X_[group_id] * x1
out.append(x1)
out = torch.cat([out[0], out[1], out[2], out[3]], dim=1)
N, C, H, W = out.size()
x_add_1 = out.reshape(N, self.group_num, -1)
N, C, H, W = X_GOBAL.size()
x_shape_1 = X_GOBAL.reshape(N, self.group_num, -1)
mean_1 = x_shape_1.mean(dim=2, keepdim=True)
std_1 = x_shape_1.std(dim=2, keepdim=True)
x_guiyi = (x_add_1 - mean_1) / (std_1 + self.eps)
x_guiyi_1 = x_guiyi.reshape(N, C, H, W)
x_gui = (x_guiyi_1 * self.gamma + self.beta)
weight_x3 = self.Apt(X_GOBAL)
reweights = self.sigomid(weight_x3)
x_up_1 = reweights >= weight_1
x_low_1 = reweights < weight_1
x_up_2 = reweights >= weight_2
x_low_2 = reweights < weight_2
x_up = x_up_1 * X_GOBAL + x_up_2 * X_GOBAL
x_low = x_low_1 * X_GOBAL + x_low_2 * X_GOBAL
x11_up_dwc = self.dwconv(x_low)
x11_up_dwc = self.conv3(x11_up_dwc)
x_so = self.gate_genator(x_low)
x11_up_dwc = x11_up_dwc * x_so
x22_low_pw = self.conv4(x_up)
xL = x11_up_dwc + x22_low_pw
xL = xL + x_gui
return xL
1.5 注册模块
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.featureFusion.EFC import EFC
步骤2
修改def parse_model(d, ch, verbose=True):
elif m is EFC:
c1, c2 = ch[f[0]], args[0]
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2]
1.6 配置yolov8-EFC.yaml
ultralytics/cfg/models/v8/yolov8-EFC.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, EFC, [512]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, EFC, [256]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, EFC, [512]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, EFC, [1024]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
1.7 训练
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/yolov8-EFC.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='coco128.yaml',
name='EFC',
epochs=10,
workers=8,
batch=1)

2. FCM:特征互补映射模块 ,通过融合丰富语义信息与精确空间位置信息,增强深度网络中小目标特征匹配能力
2.1 摘要
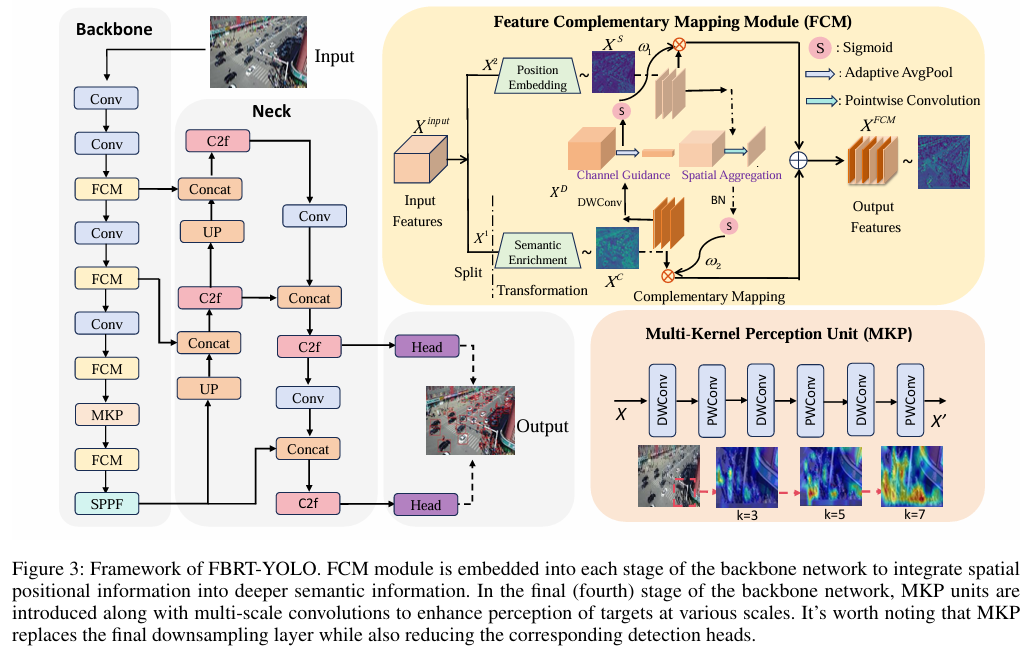
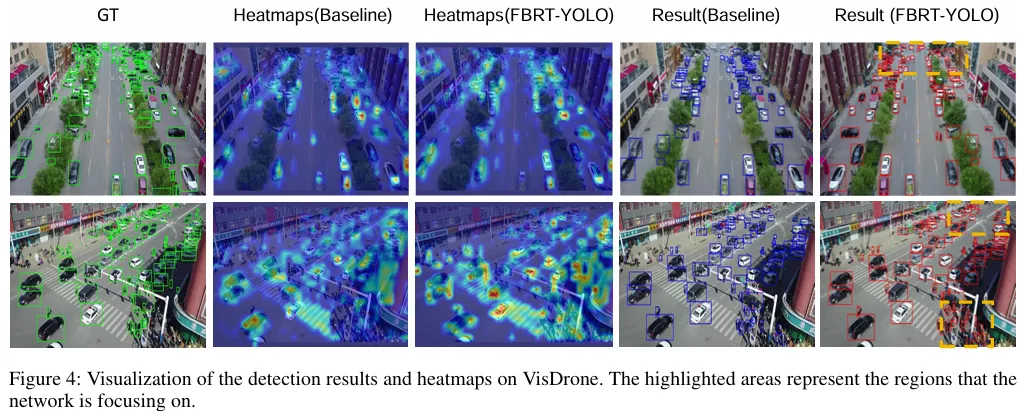
具备视觉能力的嵌入式飞行设备已在众多应用场景中成为关键组件。在航拍图像检测领域,尽管现有方法已部分解决小目标检测问题,但在优化小目标检测性能与平衡检测精度和效率方面仍存在挑战,这些问题是实时航拍图像检测技术发展的主要障碍。本文提出新型实时检测器FBRT-YOLO,通过两个轻量级模块——特征互补映射模块(FCM)与多核感知单元(MKP)——来提升航拍图像中小目标的感知能力。FCM模块致力于缓解深层网络中因小目标信息丢失导致的信息失衡问题,通过将目标空间位置信息更深度地整合至网络深层,使其与深层语义信息更好对齐,从而优化小目标定位。MKP单元采用多尺度卷积核强化不同尺度目标间的关联性,提升网络对多尺度目标的感知能力。在Visdrone、UAVDT和AI-TOD三大航拍数据集上的实验表明,FBRT-YOLO在检测性能与速度方面均优于现有实时检测器。
论文地址:https://arxiv.org/pdf/2504.20670
代码地址:https://github.com/galaxy-oss/FCM
2.2 基本原理
FCM(Feature Complementary Mapping Module,特征互补映射模块)是FBRT-YOLO模型中核心的轻量级模块之一,专门用于解决航拍图像检测中浅层空间位置信息与深层语义信息融合不足的问题,通过优化特征传递与互补机制,提升小目标检测的精度和效率。
在传统深度学习网络中,浅层网络保留了丰富的空间位置信息(如小目标的边缘、位置细节),但语义信息较弱;深层网络则侧重提取语义信息(如目标类别、整体特征),但空间细节易丢失。这种信息割裂会导致“特征不匹配”,尤其对航拍图像中的小目标检测影响显著。
FCM的核心目标是:将浅层空间位置信息有效传递到深层网络,与深层语义信息进行互补融合,增强网络对小目标的定位能力和特征一致性。
FCM通过“拆分-变换-互补映射-聚合”四步流程实现信息融合,具体结构和操作如下:
- 通道拆分(Channel Split)
首先将输入特征(形状为 C × H × W C \times H \times W C×H×W,( C )为通道数, H H H、 W W W为空间尺寸)按比例拆分为两部分:
- 一部分占 α C \alpha C αC通道 ( 0 ≤ α ≤ 1 ( 0 \leq \alpha \leq 1 (0≤α≤1,拆分比例),用于后续提取语义信息;
- 另一部分占
(
1
−
α
)
C
(1 - \alpha)C
(1−α)C通道,用于保留浅层空间位置信息。
公式表示为:
( X 1 , X 2 ) = Split ( X input ) (X^1, X^2) = \text{Split}(X^{\text{input}}) (X1,X2)=Split(Xinput)
其中KaTeX parse error: Can't use function '\)' in math mode at position 49: …es H \times W} \̲)̲,\( X^2 \in \ma…
- 方向变换(Orientation Transformation)
对拆分后的两部分特征分别进行处理,获取语义和空间信息的映射:
- X 1 X^1 X1通过 3 × 3 3 \times 3 3×3标准卷积提取丰富的通道语义信息,输出为 X C X^C XC(语义特征);
-
X
2
X^2
X2通过点卷积
(
1
×
1
( 1 \times 1
(1×1卷积)保留原始空间位置信息,输出为
X
S
X^S
XS(空间特征)。
这一步的目的是让两部分特征分别专注于语义和空间信息的提取,为后续互补做准备。
- 互补映射(Complementary Mapping)
为解决 X C X^C XC(语义特征)和 X S X^S XS(空间特征)的信息割裂问题,FCM通过“通道交互”和“空间交互”实现互补:
- 通道交互:对 X C X^C XC使用深度卷积(Depthwise Conv)切断通道间干扰,再通过全局平均池化和激活函数生成通道权重 ω 1 \omega_1 ω1,用于增强关键语义通道的影响;
- 空间交互:对
X
S
X^S
XS使用
1
×
1
1 \times 1
1×1卷积和激活函数生成空间权重
ω
2
\omega_2
ω2,突出重要空间位置的信息。
最终通过权重映射让两部分特征互补:语义特征指导空间特征的关键区域,空间特征补充语义特征的细节位置。
- 特征聚合(Feature Aggregation)
将经过权重调整的 X C X^C XC和 X S X^S XS进行元素级相乘后拼接,输出融合了空间位置和语义信息的特征 X FCM X^{\text{FCM}} XFCM,公式为:
X FCM = ( X C ⊗ ω 2 ) ⊕ ( X S ⊗ ω 1 ) X^{\text{FCM}} = (X^C \otimes \omega_2) \oplus (X^S \otimes \omega_1) XFCM=(XC⊗ω2)⊕(XS⊗ω1)
其中 ⊗ \otimes ⊗为元素相乘, ⊕ \oplus ⊕为拼接操作。
2.3 核心代码
class FCM(nn.Module):
def __init__(self, dim,dim_out):
super().__init__()
self.one = dim // 4
self.two = dim - dim // 4
self.conv1 = Conv(dim // 4, dim // 4, 3, 1, 1)
self.conv12 = Conv(dim // 4, dim // 4, 3, 1, 1)
self.conv123 = Conv(dim // 4, dim, 1, 1)
self.conv2 = Conv(dim - dim // 4, dim, 1, 1)
self.conv3 = Conv(dim, dim, 1, 1)
self.spatial = Spatial(dim)
self.channel = Channel(dim)
def forward(self, x):
x1, x2 = torch.split(x, [self.one, self.two], dim=1)
x3 = self.conv1(x1)
x3 = self.conv12(x3)
x3 = self.conv123(x3)
x4 = self.conv2(x2)
x33 = self.spatial(x4) * x3
x44 = self.channel(x3) * x4
x5 = x33 + x44
x5 = self.conv3(x5)
return x5
2.4 引入代码
在根目录下的ultralytics/nn/目录,新建一个 目录,然后新建一个以 为文件名的py文件, 把代码拷贝进去。
import math
import torch.nn.functional as F
import numpy as np
import torch
import torch.nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class Channel(nn.Module):
def __init__(self, dim):
super().__init__()
self.dwconv = self.dconv = nn.Conv2d(
dim, dim, 3,
1, 1, groups=dim
)
self.Apt = nn.AdaptiveAvgPool2d(1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x2 = self.dwconv(x)
x5 = self.Apt(x2)
x6 = self.sigmoid(x5)
return x6
class Spatial(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv1 = nn.Conv2d(dim, 1, 1, 1)
self.bn = nn.BatchNorm2d(1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x1 = self.conv1(x)
x5 = self.bn(x1)
x6 = self.sigmoid(x5)
return x6
class FCM_3(nn.Module):
def __init__(self, dim):
super().__init__()
self.one = dim - dim // 4
self.two = dim // 4
self.conv1 = Conv(dim - dim // 4, dim - dim // 4, 3, 1, 1)
self.conv12 = Conv(dim - dim // 4, dim - dim // 4, 3, 1, 1)
self.conv123 = Conv(dim - dim // 4, dim, 1, 1)
self.conv2 = Conv(dim // 4, dim, 1, 1)
self.spatial = Spatial(dim)
self.channel = Channel(dim)
def forward(self, x):
x1, x2 = torch.split(x, [self.one, self.two], dim=1)
x3 = self.conv1(x1)
x3 = self.conv12(x3)
x3 = self.conv123(x3)
x4 = self.conv2(x2)
x33 = self.spatial(x4) * x3
x44 = self.channel(x3) * x4
x5 = x33 + x44
return x5
class FCM_2(nn.Module):
def __init__(self, dim):
super().__init__()
self.one = dim - dim // 4
self.two = dim // 4
self.conv1 = Conv(dim - dim // 4, dim - dim // 4, 3, 1, 1)
self.conv12 = Conv(dim - dim // 4, dim - dim // 4, 3, 1, 1)
self.conv123 = Conv(dim - dim // 4, dim, 1, 1)
self.conv2 = Conv(dim // 4, dim, 1, 1)
self.spatial = Spatial(dim)
self.channel = Channel(dim)
def forward(self, x):
x1, x2 = torch.split(x, [self.one, self.two], dim=1)
x3 = self.conv1(x1)
x3 = self.conv12(x3)
x3 = self.conv123(x3)
x4 = self.conv2(x2)
x33 = self.spatial(x4) * x3
x44 = self.channel(x3) * x4
x5 = x33 + x44
return x5
class FCM_1(nn.Module):
def __init__(self, dim):
super().__init__()
self.one = dim // 4
self.two = dim - dim // 4
self.conv1 = Conv(dim // 4, dim // 4, 3, 1, 1)
self.conv12 = Conv(dim // 4, dim // 4, 3, 1, 1)
self.conv123 = Conv(dim // 4, dim, 1, 1)
self.conv2 = Conv(dim - dim // 4, dim, 1, 1)
self.spatial = Spatial(dim)
self.channel = Channel(dim)
def forward(self, x):
x1, x2 = torch.split(x, [self.one, self.two], dim=1)
x3 = self.conv1(x1)
x3 = self.conv12(x3)
x3 = self.conv123(x3)
x4 = self.conv2(x2)
x33 = self.spatial(x4) * x3
x44 = self.channel(x3) * x4
x5 = x33 + x44
return x5
class FCM(nn.Module):
def __init__(self, dim):
super().__init__()
self.one = dim // 4
self.two = dim - dim // 4
self.conv1 = Conv(dim // 4, dim // 4, 3, 1, 1)
self.conv12 = Conv(dim // 4, dim // 4, 3, 1, 1)
self.conv123 = Conv(dim // 4, dim, 1, 1)
self.conv2 = Conv(dim - dim // 4, dim, 1, 1)
self.conv3 = Conv(dim, dim, 1, 1)
self.spatial = Spatial(dim)
self.channel = Channel(dim)
def forward(self, x):
x1, x2 = torch.split(x, [self.one, self.two], dim=1)
x3 = self.conv1(x1)
x3 = self.conv12(x3)
x3 = self.conv123(x3)
x4 = self.conv2(x2)
x33 = self.spatial(x4) * x3
x44 = self.channel(x3) * x4
x5 = x33 + x44
x5 = self.conv3(x5)
return x5
class Pzconv(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv1 = nn.Conv2d(
dim, dim, 3,
1, 1, groups=dim
)
self.conv2 = Conv(dim, dim, k=1, s=1, )
self.conv3 = nn.Conv2d(
dim, dim, 5,
1, 2, groups=dim
)
self.conv4 = Conv(dim, dim, 1, 1)
self.conv5 = nn.Conv2d(
dim, dim, 7,
1, 3, groups=dim
)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = self.conv3(x2)
x4 = self.conv4(x3)
x5 = self.conv5(x4)
x6 = x5 + x
return x6
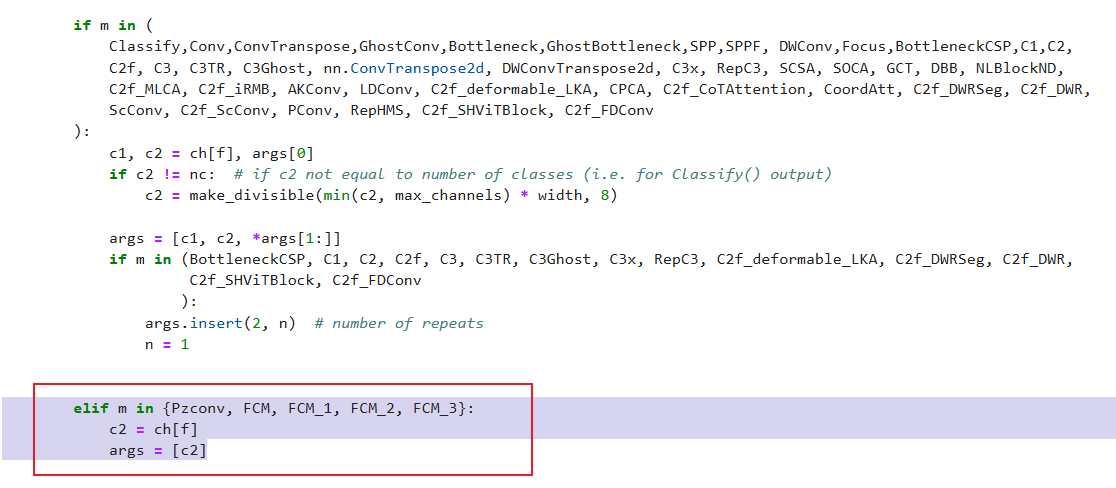
2.5 注册模块
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.featureFusion.FCM import Pzconv, FCM, FCM_1, FCM_2, FCM_3
步骤2
修改def parse_model(d, ch, verbose=True):
elif m in {Pzconv, FCM, FCM_1, FCM_2, FCM_3}:
c2 = ch[f]
args = [c2]
2.6 配置文件
ultralytics/cfg/models/v8/yolov8-FCM.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 1, FCM_3, []]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 1, FCM_2, []]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 1, FCM_1, []]
- [-1, 1, Pzconv, []] # 7-P4/16
- [-1, 1, FCM, []]
- [-1, 1, SPPF, [512, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P2
- [-1, 3, C2f, [128]] # 15 (P2/4)
- [-1, 1, Conv, [128, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P3
- [-1, 3, C2f, [256]] # 18 (P3/8)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [512]] # 21 (P4/16)
- [[18, 21], 1, Detect, [nc]] # Detect(P3, P4)
2.7 训练
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/yolov8-FCM.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='coco128.yaml',
name='FCM',
epochs=10,
workers=8,
batch=1,
)



















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











