




1.HCF-Net 之 DASI: 维度感知选择性整合模块小目标
1.1 概述
红外小目标检测是计算机视觉中的一项重要任务,涉及识别和定位红外图像中的微小目标,这些目标通常只有几个像素。然而,由于目标体积小且红外图像背景通常复杂,这项任务面临诸多挑战。本文提出了一种深度学习方法HCF-Net,通过多个实用模块显著提升红外小目标检测性能。具体而言,该方法包括并行化的感知补丁注意力(PPA)模块、维度感知选择性融合(DASI)模块和多膨胀通道优化(MDCR)模块。PPA模块使用多分支特征提取策略来捕捉不同尺度和层次的特征信息。DASI模块实现了自适应的通道选择和融合。MDCR模块通过多层深度可分离卷积捕捉不同感受野范围的空间特征。大量实验结果表明,在SIRST红外单帧图像数据集上,所提出的HCF-Net表现优异,超越了其他传统和深度学习模型。
论文地址:论文地址
代码地址:代码地址
1.2 基本原理
HCF-Net(Hierarchical Context Fusion Network)是一种用于红外小目标检测的深度学习模型,旨在提高对红外图像中微小目标的识别和定位能力。
-
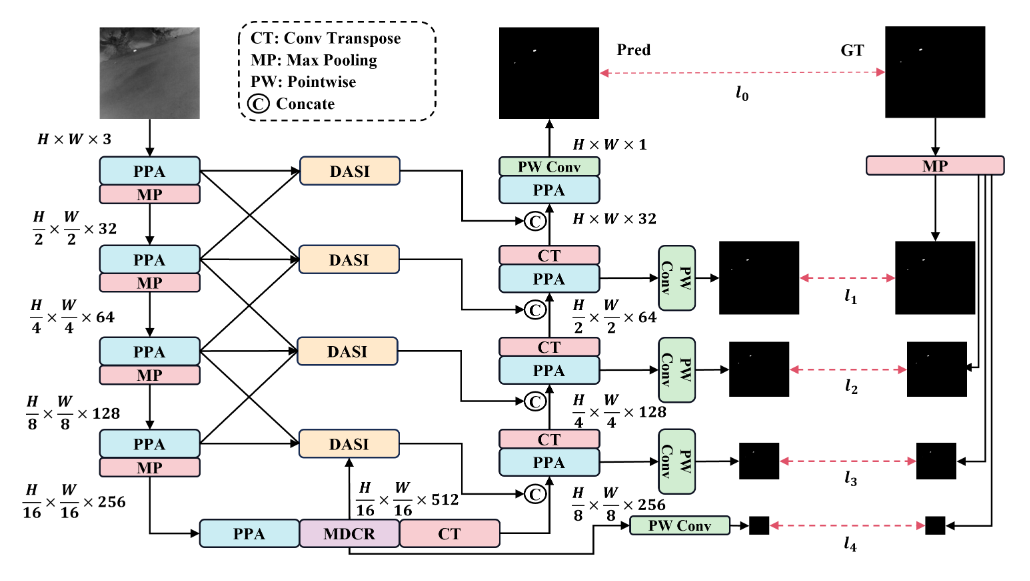
网络架构:HCF-Net采用了一种升级版的U-Net架构,主要由三个关键模块组成:Parallelized Patch-Aware Attention(PPA)模块、Dimension-Aware Selective Integration(DASI)模块和Multi-Dilated Channel Refiner(MDCR)模块。这些模块在不同层级上解决了红外小目标检测中的挑战 。
-
PPA模块:
- Hierarchical Feature Fusion:PPA模块利用分层特征融合和注意力机制,以在多次下采样过程中保持和增强小目标的表示,确保关键信息在整个网络中得以保留[T1]。
- Multi-Branch Feature Extraction:PPA采用多分支特征提取策略,以捕获不同尺度和级别的特征信息,从而提高小目标检测的准确性 。
-
DASI模块:
- Adaptive Feature Fusion:DASI模块增强了U-Net中的跳跃连接,专注于高低维特征的自适应选择和精细融合,以增强小目标的显著性 。
-
MDCR模块:
- Spatial Feature Refinement:MDCR模块通过多个深度可分离卷积层捕获不同感受野范围的空间特征,更细致地建模目标和背景之间的差异,提高了定位小目标的能力 。
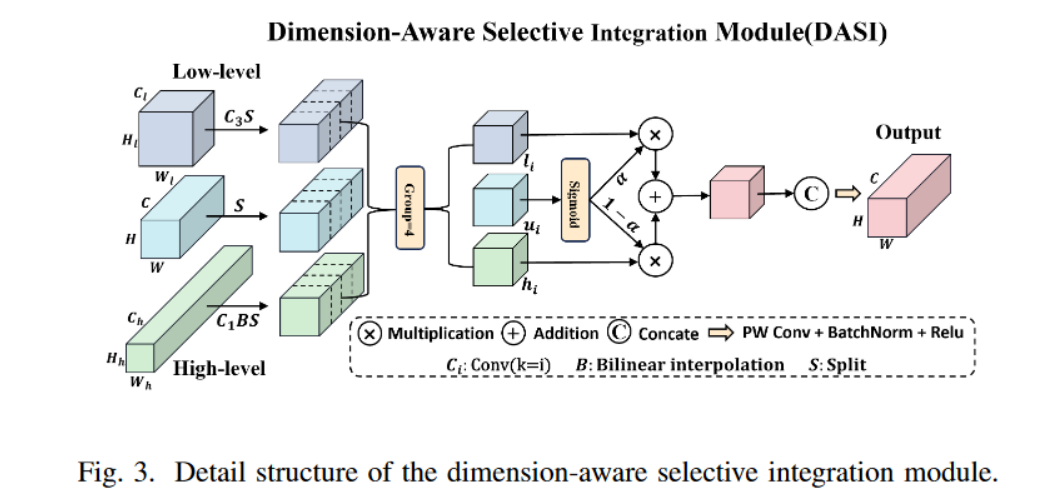
1.3 DASI
在红外小物体检测的多个降采样阶段中,高维特征可能会丢失小物体的信息,而低维特征可能无法提供足够的背景信息。为解决这一问题,提出了一种新颖的信道分区选择机制(如图 3 所示),使 DASI 能够根据物体的大小和特征自适应地选择合适的特征进行融合。
具体来说,DASI 首先通过卷积和插值等操作,将高维特征 (
F
h
∈
R
H
h
×
W
h
×
C
h
\mathbf{F}_h \in \mathbb{R}^{H_h \times W_h \times C_h}
Fh∈RHh×Wh×Ch) 和低维特征 (
F
l
∈
R
H
l
×
W
l
×
C
l
\mathbf{F}_l \in \mathbb{R}^{H_l \times W_l \times C_l}
Fl∈RHl×Wl×Cl),以及当前层的特征 (
F
u
∈
R
H
×
W
×
C
\mathbf{F}_u \in \mathbb{R}^{H \times W \times C}
Fu∈RH×W×C) 对齐。随后,它将这些特征在通道维度上分成四个相等的部分,从而得到
(
(
h
i
)
i
=
1
4
∈
R
H
×
W
×
C
4
,
(
l
i
)
i
=
1
4
∈
R
H
×
W
×
C
4
,
(
u
i
)
i
=
1
4
∈
R
H
×
W
×
C
4
)
((\mathbf{h}_i)_{i=1}^4 \in \mathbb{R}^{H \times W \times \frac{C}{4}}, (\mathbf{l}_i)_{i=1}^4 \in \mathbb{R}^{H \times W \times \frac{C}{4}}, (\mathbf{u}_i)_{i=1}^4 \in \mathbb{R}^{H \times W \times \frac{C}{4}})
((hi)i=14∈RH×W×4C,(li)i=14∈RH×W×4C,(ui)i=14∈RH×W×4C),其中
(
h
i
,
l
i
,
u
i
)
(\mathbf{h}_i, \mathbf{l}_i, \mathbf{u}_i)
(hi,li,ui) 分别表示高维、低维和当前层特征的第
(
i
)
(i)
(i) 个分区特征。
这些分区的计算公式如下:
α
=
sigmoid
(
u
i
)
,
\alpha = \text{sigmoid}(\mathbf{u}_i),
α=sigmoid(ui),
u
i
′
=
α
l
i
+
(
1
−
α
)
h
i
,
\mathbf{u}_i' = \alpha \mathbf{l}_i + (1 - \alpha) \mathbf{h}_i,
ui′=αli+(1−α)hi,
F
u
′
=
[
u
1
′
,
u
2
′
,
u
3
′
,
u
4
′
]
,
\mathbf{F}_u' = [\mathbf{u}_1', \mathbf{u}_2', \mathbf{u}_3', \mathbf{u}_4'],
Fu′=[u1′,u2′,u3′,u4′],
F
^
u
=
δ
(
B
(
Conv
(
F
u
′
)
)
)
,
\hat{\mathbf{F}}_u = \delta \left( \mathcal{B} \left( \text{Conv}(\mathbf{F}_u') \right) \right),
F^u=δ(B(Conv(Fu′))),
其中,
sigmoid
(
⋅
)
\text{sigmoid}(\cdot)
sigmoid(⋅) 表示应用于的 sigmoid 激活函数后得到的值,
(
u
i
′
∈
R
H
×
W
×
C
4
)
(\mathbf{u}_i' \in \mathbb{R}^{H \times W \times \frac{C}{4}})
(ui′∈RH×W×4C) 表示每个分区的选择性汇总结果。在通道维度上合并
(
(
u
i
′
)
i
=
1
4
)
((\mathbf{u}_i')_{i=1}^4)
((ui′)i=14) 后,得到
(
F
u
′
∈
R
H
×
W
×
C
)
(\mathbf{F}_u' \in \mathbb{R}^{H \times W \times C})
(Fu′∈RH×W×C)。操作
(
Conv
(
)
)
(\text{Conv}())
(Conv())、
(
B
(
⋅
)
)
(\mathcal{B}(\cdot))
(B(⋅)) 和
(
δ
(
⋅
)
)
(\delta(\cdot))
(δ(⋅)) 分别表示卷积、批量归一化(BN)和整流线性单元(ReLU),最终得到输出
(
F
^
u
∈
R
H
×
W
×
C
)
(\hat{\mathbf{F}}_u \in \mathbb{R}^{H \times W \times C})
(F^u∈RH×W×C)。
如果
(
α
>
0.5
)
(\alpha > 0.5)
(α>0.5),则模型优先考虑细粒度特征;如果
(
α
<
0.5
)
(\alpha < 0.5)
(α<0.5),则强调上下文特征。
1.4 核心代码
class DASI(nn.Module):
def __init__(self, in_features, out_features) -> None:
super().__init__()
self.bag = Bag()
# 尾部卷积层
self.tail_conv = nn.Sequential(
conv_block(in_features=out_features,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type=None,
activation=False)
)
# 主要卷积操作
self.conv = nn.Sequential(
conv_block(in_features=out_features // 2,
out_features=out_features // 4,
kernel_size=(1, 1),
padding=(0, 0),
norm_type=None,
activation=False)
)
# 批量归一化层
self.bns = nn.BatchNorm2d(out_features)
# 跳跃连接处理
self.skips = conv_block(in_features=in_features,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type=None,
activation=False)
self.skips_2 = conv_block(in_features=in_features * 2,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type=None,
activation=False)
self.skips_3 = nn.Conv2d(in_features // 2, out_features,
kernel_size=3, stride=2, dilation=2, padding=2)
# self.skips_3 = nn.Conv2d(in_features // 2, out_features,
# kernel_size=3, stride=2, dilation=1, padding=1)
# 激活函数
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x, x_low, x_high):
if x_high is not None:
x_high = self.skips_3(x_high)
x_high = torch.chunk(x_high, 4, dim=1)
if x_low is not None:
x_low = self.skips_2(x_low)
x_low = F.interpolate(x_low, size=[x.size(2), x.size(3)], mode='bilinear', align_corners=True)
x_low = torch.chunk(x_low, 4, dim=1)
x_skip = self.skips(x)
x = self.skips(x)
x = torch.chunk(x, 4, dim=1)
if x_high is None:
x0 = self.conv(torch.cat((x[0], x_low[0]), dim=1))
x1 = self.conv(torch.cat((x[1], x_low[1]), dim=1))
x2 = self.conv(torch.cat((x[2], x_low[2]), dim=1))
x3 = self.conv(torch.cat((x[3], x_low[3]), dim=1))
elif x_low is None:
x0 = self.conv(torch.cat((x[0], x_high[0]), dim=1))
x1 = self.conv(torch.cat((x[0], x_high[1]), dim=1))
x2 = self.conv(torch.cat((x[0], x_high[2]), dim=1))
x3 = self.conv(torch.cat((x[0], x_high[3]), dim=1))
else:
x0 = self.bag(x_low[0], x_high[0], x[0])
x1 = self.bag(x_low[1], x_high[1], x[1])
x2 = self.bag(x_low[2], x_high[2], x[2])
x3 = self.bag(x_low[3], x_high[3], x[3])
# 合并处理后的特征
x = torch.cat((x0, x1, x2, x3), dim=1)
# 尾部卷积和跳跃连接
x = self.tail_conv(x)
x += x_skip
# 批量归一化和激活函数
x = self.bns(x)
x = self.relu(x)
return x
1.5 引入代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 DASI为文件名的py文件, 把代码拷贝进去。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class conv_block(nn.Module):
def __init__(self,
in_features,
out_features,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
norm_type='bn',
activation=True,
use_bias=True,
groups=1
):
super().__init__()
self.conv = nn.Conv2d(in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups=groups)
self.norm_type = norm_type
self.act = activation
if self.norm_type == 'gn':
self.norm = nn.GroupNorm(32 if out_features >= 32 else out_features, out_features)
if self.norm_type == 'bn':
self.norm = nn.BatchNorm2d(out_features)
if self.act:
# self.relu = nn.GELU()
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class Bag(nn.Module):
def __init__(self):
super(Bag, self).__init__()
def forward(self, p, i, d):
edge_att = torch.sigmoid(d)
return edge_att * p + (1 - edge_att) * i
class DASI(nn.Module):
def __init__(self, in_features, out_features) -> None:
super().__init__()
self.bag = Bag()
self.tail_conv = nn.Sequential(
conv_block(in_features=out_features,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
)
self.conv = nn.Sequential(
conv_block(in_features = out_features // 2,
out_features = out_features // 4,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
)
self.bns = nn.BatchNorm2d(out_features)
self.skips = conv_block(in_features=in_features,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.skips_2 = conv_block(in_features=in_features * 2,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.skips_3 = nn.Conv2d(in_features//2, out_features,
kernel_size=3, stride=2, dilation=2, padding=2)
# self.skips_3 = nn.Conv2d(in_features//2, out_features,
# kernel_size=3, stride=2, dilation=1, padding=1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skips(x)
x = self.skips(x)
# x = torch.chunk(x, 4, dim=1)
x = self.tail_conv(x)
x += x_skip
x = self.bns(x)
x = self.relu(x)
return x
class C2f_DASI(nn.Module):
def __init__(self, c1, c2, n=1, k=7, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(DASI(self.c, self.c) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
1.6 注册卷积
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.DASI import C2f_DASI
步骤2
修改def parse_model(d, ch, verbose=True):
if m in (
Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d,DWConvTranspose2d, C3x, RepC3, EVCBlock,
CAFMAttention, CloFormerAttnConv, C2f_iAFF, CSPStage, nn.Conv2d, GSConv, VoVGSCSP, C2f_CBAM, C2f_RefConv,C2f_SimAM,
C2f_NAM, MSFE, C2f_MDCR,C2f_MHSA, PPA, C2f_DASI
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3, C2f_deformable_LKA,Sea_AttentionBlock, C2f_iAFF,CSPStage, VoVGSCSP,C2f_SimAM,
C2f_NAM, C2f_MDCR, C2f_DASI
):
args.insert(2, n) # number of repeats
n = 1

1.7配置文件
文件位置:ultralytics/cfg/models/v8/yolov8_DASI.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f_DASI, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_DASI, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_DASI, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_DASI, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
1.8 训练
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/yolov8_DASI.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='ultralytics/datasets/original-license-plates.yaml',
name='yolov8_DASI',
epochs=10,
workers=8,
batch=1)
2.HCF-Net 之 PPA:小目标并行化注意力设计
2.1 概述
红外小目标检测是计算机视觉中的一项重要任务,涉及识别和定位红外图像中的微小目标,这些目标通常只有几个像素。然而,由于目标体积小且红外图像背景通常复杂,这项任务面临诸多挑战。本文提出了一种深度学习方法HCF-Net,通过多个实用模块显著提升红外小目标检测性能。具体而言,该方法包括并行化的感知补丁注意力(PPA)模块、维度感知选择性融合(DASI)模块和多膨胀通道优化(MDCR)模块。PPA模块使用多分支特征提取策略来捕捉不同尺度和层次的特征信息。DASI模块实现了自适应的通道选择和融合。MDCR模块通过多层深度可分离卷积捕捉不同感受野范围的空间特征。大量实验结果表明,在SIRST红外单帧图像数据集上,所提出的HCF-Net表现优异,超越了其他传统和深度学习模型。
论文地址:论文地址
代码地址:代码地址
2.2 基本原理
HCF-Net(Hierarchical Context Fusion Network)是一种用于红外小目标检测的深度学习模型,旨在提高对红外图像中微小目标的识别和定位能力。
-
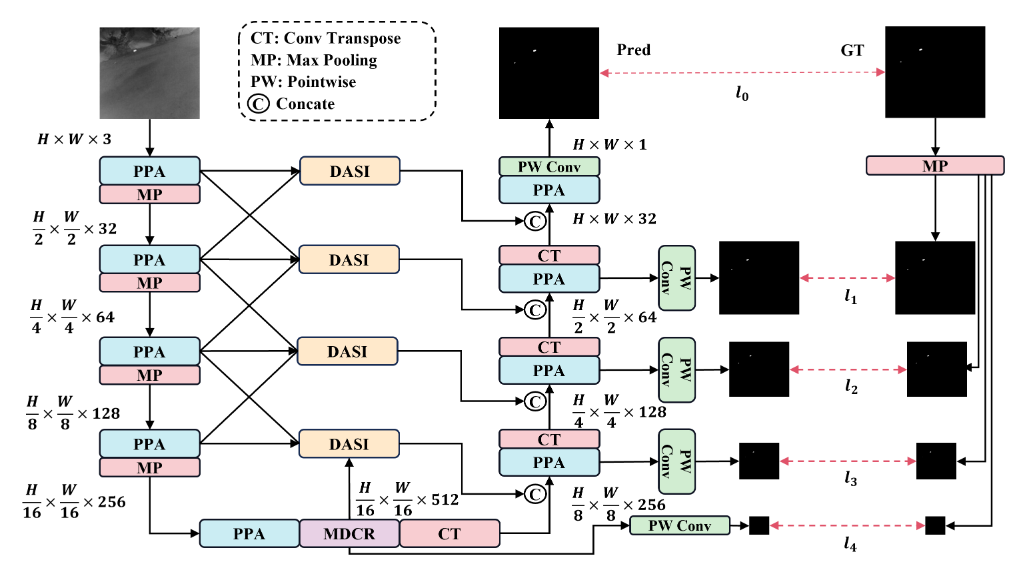
网络架构:HCF-Net采用了一种升级版的U-Net架构,主要由三个关键模块组成:Parallelized Patch-Aware Attention(PPA)模块、Dimension-Aware Selective Integration(DASI)模块和Multi-Dilated Channel Refiner(MDCR)模块。这些模块在不同层级上解决了红外小目标检测中的挑战 。
-
PPA模块:
- Hierarchical Feature Fusion:PPA模块利用分层特征融合和注意力机制,以在多次下采样过程中保持和增强小目标的表示,确保关键信息在整个网络中得以保留[T1]。
- Multi-Branch Feature Extraction:PPA采用多分支特征提取策略,以捕获不同尺度和级别的特征信息,从而提高小目标检测的准确性 。
-
DASI模块:
- Adaptive Feature Fusion:DASI模块增强了U-Net中的跳跃连接,专注于高低维特征的自适应选择和精细融合,以增强小目标的显著性 。
-
MDCR模块:
- Spatial Feature Refinement:MDCR模块通过多个深度可分离卷积层捕获不同感受野范围的空间特征,更细致地建模目标和背景之间的差异,提高了定位小目标的能力 。
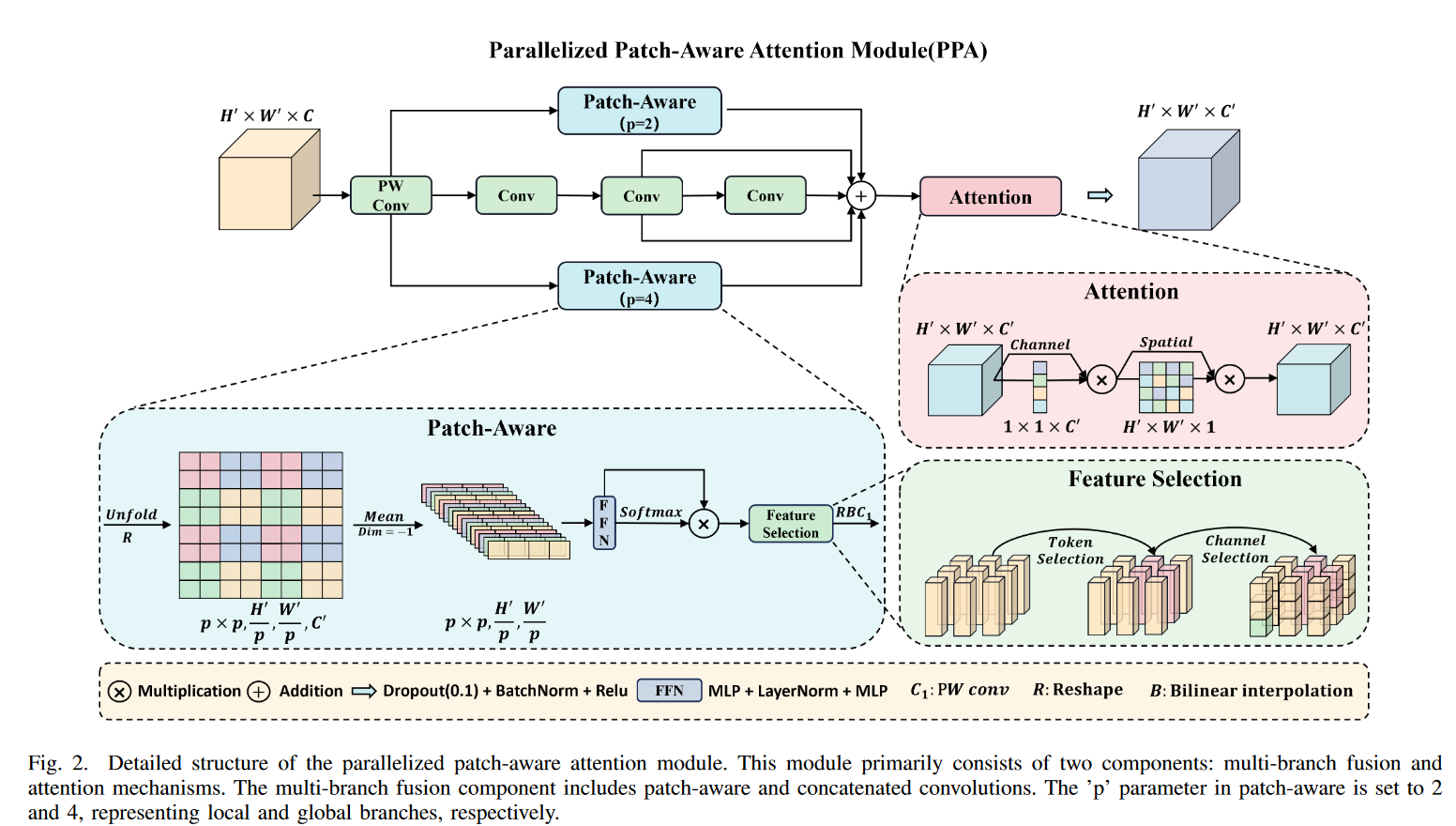
2.3 PPA
在红外小物体检测任务中,小物体很容易在多次降采样操作中丢失关键信息。 ,PPA 在编码器和解码器的基本组件中取代了传统的卷积运算,从而更好地应对了这一挑战。PPA 主要有两大优势:多分支特征提取和特征融合注意力。
多分支特征提取
PPA 的多分支特征提取策略如下图 所示,采用并行多分支方法,每个分支负责提取不同规模和级别的特征。这种策略有利于捕捉物体的多尺度特征,提高小物体检测的准确性。具体而言,这包括三个并行分支:局部分支、全局分支和串行卷积分支。
-
局部分支:通过调整逐点卷积后的特征张量 F ′ F’ F′,分割成一组空间上连续的斑块,进行信道平均和线性计算,再应用激活函数得到空间维度上的概率分布。
-
全局分支:使用高效操作,在斑块中选择与任务相关的特征,通过余弦相似度衡量加权,最终产生局部和全局特征。
-
串行卷积分支:采用三个 3x3 卷积层替代传统的大卷积核,得到多个输出结果,最后相加得到串行卷积输出。
这些分支计算得到的特征分别是 F l o c a l F_{local} Flocal、 F g l o b a l F_{global} Fglobal 和 F c o n v F_{conv} Fconv,它们在尺寸和通道数上保持一致。
通过这种策略,PPA 不仅能有效捕获不同尺度下的特征,还能提升特征的表达能力和模型的整体性能。
2.4 核心代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class conv_block(nn.Module):
def __init__(self,
in_features, # 输入特征数量
out_features, # 输出特征数量
kernel_size=(3, 3), # 卷积核大小
stride=(1, 1), # 步长
padding=(1, 1), # 填充
dilation=(1, 1), # 空洞卷积率
norm_type='bn', # 归一化类型
activation=True, # 是否使用激活函数
use_bias=True, # 是否使用偏置
groups=1 # 分组卷积数量
):
super().__init__()
# 定义卷积层
self.conv = nn.Conv2d(in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups=groups)
self.norm_type = norm_type
self.act = activation
# 定义归一化层
if self.norm_type == 'gn':
self.norm = nn.GroupNorm(32 if out_features >= 32 else out_features, out_features)
if self.norm_type == 'bn':
self.norm = nn.BatchNorm2d(out_features)
# 定义激活函数
if self.act:
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class LocalGlobalAttention(nn.Module):
def __init__(self, output_dim, patch_size):
super().__init__()
self.output_dim = output_dim
self.patch_size = patch_size
self.mlp1 = nn.Linear(patch_size*patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1) # 重新排列张量维度 (B, H, W, C)
B, H, W, C = x.shape
P = self.patch_size
# 局部分支
local_patches = x.unfold(1, P, P).unfold(2, P, P) # 将特征分块 (B, H/P, W/P, P, P, C)
local_patches = local_patches.reshape(B, -1, P*P, C) # 重新调整形状 (B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # 对最后一维取均值 (B, H/P*W/P, P*P)
local_patches = self.mlp1(local_patches) # 全连接层 (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # 层归一化 (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # 全连接层 (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # 计算注意力 (B, H/P*W/P, output_dim)
local_out = local_patches * local_attention # 应用注意力权重 (B, H/P*W/P, output_dim)
# 计算与提示向量的余弦相似度
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # (B, N, 1)
mask = cos_sim.clamp(0, 1) # 计算掩码
local_out = local_out * mask # 应用掩码
local_out = local_out @ self.top_down_transform # 变换
# 恢复形状
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2)
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False) # 插值恢复原始尺寸
output = self.conv(local_out) # 卷积层
return output
class ECA(nn.Module):
def __init__(self,in_channel,gamma=2,b=1):
super(ECA, self).__init__()
k = int(abs((math.log(in_channel,2)+b)/gamma)) # 计算卷积核大小
kernel_size = k if k % 2 else k+1 # 保证卷积核大小为奇数
padding = kernel_size // 2 # 填充
self.pool = nn.AdaptiveAvgPool2d(output_size=1) # 自适应平均池化
self.conv = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=1, kernel_size=kernel_size, padding=padding, bias=False), # 1D卷积层
nn.Sigmoid() # Sigmoid激活函数
)
def forward(self, x):
out = self.pool(x) # 平均池化
out = out.view(x.size(0), 1, x.size(1)) # 调整形状
out = self.conv(out) # 1D卷积
out = out.view(x.size(0), x.size(1), 1, 1) # 调整形状
return out * x # 注意力加权
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3) # 2D卷积层
self.sigmoid = nn.Sigmoid() # Sigmoid激活函数
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True) # 平均池化
maxout, _ = torch.max(x, dim=1, keepdim=True) # 最大池化
out = torch.cat([avgout, maxout], dim=1) # 连接
out = self.sigmoid(self.conv2d(out)) # 卷积和激活
return out * x # 注意力加权
class PPA(nn.Module):
def __init__(self, in_features, filters) -> None:
super().__init__()
# 定义跳跃连接卷积块
self.skip = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
# 定义连续卷积块
self.c1 = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c2 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c3 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
# 定义空间注意力模块
self.sa = SpatialAttentionModule()
# 定义ECA模块
self.cn = ECA(filters)
# 定义局部和全局注意力模块
self.lga2 = LocalGlobalAttention(filters, 2)
self.lga4 = LocalGlobalAttention(filters, 4)
# 定义批归一化层、dropout层和激活函数
self.bn1 = nn.BatchNorm2d(filters)
self.drop = nn.Dropout2d(0.1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skip(x) # 跳跃连接输出
x_lga2 = self.lga2(x_skip) # 局部和全局注意力输出(大小为2的patch)
x_lga4 = self.lga4(x_skip) # 局部和全局注意力输出(大小为4的patch)
x1 = self.c1(x) # 第一个卷积块输出
x2 = self.c2(x1) # 第二个卷积块输出
x3 = self.c3(x2) # 第三个卷积块输出
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4 # 合并所有输出
x = self.cn(x) # ECA模块
x = self.sa(x) # 空间注意力模块
x = self.drop(x) # Dropout层
x = self.bn1(x) # 批归一化层
x = self.relu(x) # 激活函数
return x
2.5 引入代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 PPA为文件名的py文件, 把代码拷贝进去。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class conv_block(nn.Module):
def __init__(self,
in_features,
out_features,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
norm_type='bn',
activation=True,
use_bias=True,
groups=1
):
super().__init__()
self.conv = nn.Conv2d(in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups=groups)
self.norm_type = norm_type
self.act = activation
if self.norm_type == 'gn':
self.norm = nn.GroupNorm(32 if out_features >= 32 else out_features, out_features)
if self.norm_type == 'bn':
self.norm = nn.BatchNorm2d(out_features)
if self.act:
# self.relu = nn.GELU()
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class LocalGlobalAttention(nn.Module):
def __init__(self, output_dim, patch_size):
super().__init__()
self.output_dim = output_dim
self.patch_size = patch_size
self.mlp1 = nn.Linear(patch_size*patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
P = self.patch_size
# Local branch
local_patches = x.unfold(1, P, P).unfold(2, P, P) # (B, H/P, W/P, P, P, C)
local_patches = local_patches.reshape(B, -1, P*P, C) # (B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # (B, H/P*W/P, P*P)
local_patches = self.mlp1(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # (B, H/P*W/P, output_dim)
local_out = local_patches * local_attention # (B, H/P*W/P, output_dim)
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # B, N, 1
mask = cos_sim.clamp(0, 1)
local_out = local_out * mask
local_out = local_out @ self.top_down_transform
# Restore shapes
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2)
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False)
output = self.conv(local_out)
return output
class ECA(nn.Module):
def __init__(self,in_channel,gamma=2,b=1):
super(ECA, self).__init__()
k=int(abs((math.log(in_channel,2)+b)/gamma))
kernel_size=k if k % 2 else k+1
padding=kernel_size//2
self.pool=nn.AdaptiveAvgPool2d(output_size=1)
self.conv=nn.Sequential(
nn.Conv1d(in_channels=1,out_channels=1,kernel_size=kernel_size,padding=padding,bias=False),
nn.Sigmoid()
)
def forward(self,x):
out=self.pool(x)
out=out.view(x.size(0),1,x.size(1))
out=self.conv(out)
out=out.view(x.size(0),x.size(1),1,1)
return out*x
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out * x
class PPA(nn.Module):
def __init__(self, in_features, filters) -> None:
super().__init__()
self.skip = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.c1 = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c2 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c3 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.sa = SpatialAttentionModule()
self.cn = ECA(filters)
self.lga2 = LocalGlobalAttention(filters, 2)
self.lga4 = LocalGlobalAttention(filters, 4)
self.bn1 = nn.BatchNorm2d(filters)
self.drop = nn.Dropout2d(0.1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skip(x)
x_lga2 = self.lga2(x_skip)
x_lga4 = self.lga4(x_skip)
x1 = self.c1(x)
x2 = self.c2(x1)
x3 = self.c3(x2)
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.cn(x)
x = self.sa(x)
x = self.drop(x)
x = self.bn1(x)
x = self.relu(x)
return x
2.6 注册卷积
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.PPA import PPA
步骤2
修改def parse_model(d, ch, verbose=True):
if m in (
Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d,DWConvTranspose2d, C3x, RepC3, EVCBlock,
CloFormerAttnConv, C2f_iAFF, CSPStage, nn.Conv2d, GSConv, VoVGSCSP, C2f_CBAM, C2f_RefConv,C2f_SimAM,
C2f_NAM, MSFE, C2f_MDCR,C2f_MHSA, PPA
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3, C2f_deformable_LKA,Sea_AttentionBlock, C2f_iAFF,CSPStage, VoVGSCSP,C2f_SimAM,
C2f_NAM, C2f_MDCR
):
args.insert(2, n) # number of repeats
n = 1
2.7 配置文件
文件目录:ultralytics/cfg/models/v8/yolov8_PPA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PPA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.8 模型训练
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/yolov8_PPA.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='ultralytics/datasets/original-license-plates.yaml',
name='yolov8_PPA',
epochs=10,
workers=8,
batch=1)
3.SPD-Conv空间深度转换卷积,处理低分辨率图像和小目标问题
3.1 概述
卷积神经网络(CNNs)在许多计算机视觉任务中取得了巨大成功,例如图像分类和目标检测。然而,当面对图像分辨率低或对象较小的更加困难的任务时,它们的性能迅速下降。在本文中,我们指出这一问题根源于现有CNN架构中一个有缺陷但常见的设计,即使用了步长卷积和/或池化层,这导致了细粒度信息的丢失和较不有效的特征表示的学习。为此,我们提出了一种新的CNN构建块,名为SPD-Conv,用以替代每个步长卷积层和每个池化层(从而完全消除它们)。SPD-Conv由一个空间到深度(SPD)层和一个非步长卷积(Conv)层组成,并且可以应用于大多数(如果不是全部的话)CNN架构中。我们在两个最具代表性的计算机视觉任务下解释这一新设计:目标检测和图像分类。然后,我们通过将SPD-Conv应用于YOLOv5和ResNet来创建新的CNN架构,并通过实验证明我们的方法特别是在图像分辨率低和小对象的困难任务上显著优于最先进的深度学习模型。我们已经在开放源代码。
3.2 创新点
SPD-Conv的创新点在于其独特的设计理念和结构,它旨在解决当处理低分辨率图像或小物体时,传统卷积神经网络(CNN)性能下降的问题。以下是SPD-Conv的主要创新点:
-
完全消除卷积步长和池化层:传统CNN中,卷积步长和池化层被广泛用于减小特征图的空间尺寸,以减少计算量和增加感受野。然而,这种设计会导致细粒度信息的损失,特别是在处理低分辨率图像和小物体时。SPD-Conv通过完全摒弃这些操作,避免了信息损失,有助于保持更多的细节和特征信息。
-
空间到深度(SPD)层:SPD-Conv包含一个SPD层,该层通过重排特征图的元素,将空间信息转换到深度(通道)维度,从而实现下采样而不损失信息。这种方法保留了通道维度中的所有信息,避免了传统下采样方法中的信息丢失。
-
非步长卷积层:在SPD层之后,SPD-Conv使用非步长(即步长为1)的卷积层进一步处理特征图。这种设计允许网络在不丢失空间信息的前提下,通过可学习的参数精细调整特征表示,有助于提高模型对小物体和低分辨率图像的处理能力。
-
通用性和统一性:SPD-Conv不仅可以替代CNN中的卷积步长和池化层,还能广泛应用于各种CNN架构中,提供一种统一的改进策略。这增加了SPD-Conv的适用范围和灵活性,使其能够在不同的深度学习任务和模型中发挥作用。
-
性能提升:通过在目标检测和图像分类任务中的应用和验证,SPD-Conv展现了其在处理低分辨率图像和小物体时相比传统CNN模型的显著性能提升。这证明了其设计理念在实际应用中的有效性和优势。
3.3 基本原理
SPD-Con是一种创新的模块,旨在现有卷积神经网络(CNN)架构中替代传统的步进卷积及池化层。该结构包括一个空间到深度(SPD)层及一个非步进卷积(Conv)层。
空间到深度(SPD)层的功能在于,将输入特征图中的空间维度降维至通道维度,同时确保通道信息的完整性。具体通过将输入特征图的每一像素或特征映射至独立通道来实现,此过程中空间维度缩减,而通道维度相应扩增。
非步进卷积(Conv)层执行标准的卷积操作,紧随SPD层之后进行。不同于步进卷积,非步进卷积不在特征图上进行滑动,而是对每个像素或特征映射执行卷积操作。这有助于缓解SPD层可能导致的过度下采样问题,保留更丰富的细节信息。
SPD-Conv通过串联SPD层与Conv层的方式进行组合。具体而言,输入特征图首先经SPD层转换,其输出随后通过Conv层进行卷积处理。该组合策略在不丧失信息的前提下,有效减少空间维度尺寸,保持通道信息,从而提升CNN在低分辨率图像及小型物体检测上的性能。
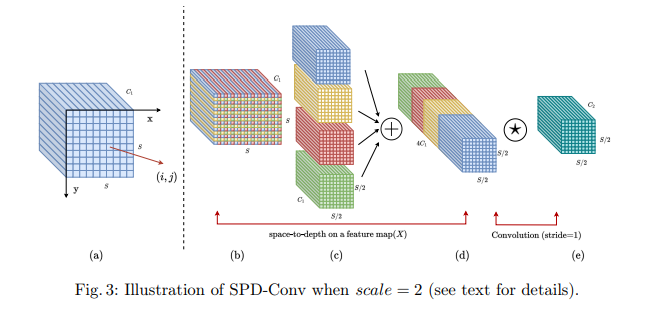
通常,对于任意给定的原始特征映射(X),子映射(f_{x,y})由特征图(X(i, j))中,(i + x)和(j + y)可被比例因子整除的所有特征映射组成。因而,每个子图实现了对(X)的比例因子下采样。例如,当比例因子为2时,可以得到四个子映射(f_{0,0}, f_{1,0}, f_{0,1}, f_{1,1}),它们的尺寸为((S/2, S/2, C_1)),对(X)实现2倍下采样。
随后,这些子特征映射沿通道维度进行连接,形成一个新的特征映射(X’),其空间维度按比例因子减少,而通道维度按比例因子2增加。
SPD借鉴了一种原始图像转换技术,用于在CNN内部及其整体中对特征映射进行下采样,如此操作。
考虑任意尺寸为(S \times S \times C_1)的中间特征映射(X),其子特征映射序列按上述方式进行切割。
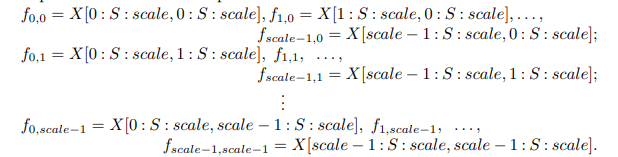
3.4 核心代码
class space_to_depth(nn.Module):
"""
space_to_depth类继承自nn.Module,用于实现空间到深度的转换,这种转换通过重排输入张量的元素来降低其空间维度,
同时增加深度维度,常用于深度学习中对图像进行下采样。
参数:
dimension: 用于指定转换的维度,默认为1。此参数设置转换操作的深度维度增加的倍数。
"""
def __init__(self, dimension=1):
"""
初始化space_to_depth模块。
参数:
dimension: 转换的维度,决定了深度增加的倍数,默认值为1。
"""
super().__init__() # 调用父类的构造函数来进行初始化
self.d = dimension # 保存维度参数
def forward(self, x):
"""
前向传播函数,实现输入x的空间到深度的转换。
通过将输入张量x的空间维度重新排列到深度维度来实现转换,具体操作是将x的高和宽每隔一个像素取一个,形成四个部分,
然后将这四个部分在深度(通道)维度上进行拼接。
参数:
x: 输入张量,需要进行空间到深度转换的数据。
返回:
转换后的张量,其空间维度减小,深度维度增加。
"""
# 对输入x进行空间到深度的转换操作,并在指定维度上进行拼接
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
3.5 引入代码
在根目录下的ultralytics/nn/目录,新建一个 conv目录,然后新建一个以 SPDConv为文件名的py文件, 把代码拷贝进去。
import torch.nn as nn
import torch
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
3.6 注册卷积
在 ultralytics/nn/tasks.py中加入以下代码:
步骤1:导包
from ultralytics.nn.conv.SPDConv import space_to_depth
步骤2
修改def parse_model(d, ch, verbose=True):
只需要添加截图中标明的,其他没有的模块不需要添加
elif m is space_to_depth:
c2 = 4 * ch[f]
3.7 配置 文件
配置文件目录:ultralytics/cfg/models/v8/ yolov8_SPDConv.yaml
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 1]] # 1
- [-1, 1, space_to_depth,[1]] # 2-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 1]] # 4
- [-1, 1, space_to_depth,[1]] # 5-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 1]] # 7
- [-1, 1, space_to_depth,[1]] # 8-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 1]] # 10
- [-1, 1, space_to_depth,[1]] # 11-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 13
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 9], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 16
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 19 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 16], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 22 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 25 (P5/32-large)
- [[19, 22, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.8 训练
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/ yolov8_SPDConv.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='ultralytics/datasets/original-license-plates.yaml',
name=' yolov8_SPDConv',
epochs=10,
workers=8,
batch=1)
4. MSCA: 多尺度卷积注意力小目标检测
4.1 摘要
我们提出了SegNeXt,一种用于语义分割的简单[卷积网络架构。最近基于变换器的模型由于自注意力在编码空间信息方面的效率而在语义分割领域占据主导地位。在本文中,我们展示了卷积注意力是一种比变换器中的自注意力机制更高效和有效的编码上下文信息的方式。通过重新审视成功的分割模型所拥有的特征,我们发现了几个关键组件,这些组件导致了分割模型性能的提升。这激励我们设计了一种新颖的卷积注意力网络,该网络使用廉价的卷积操作。没有任何花哨的技巧,我们的SegNeXt在包括ADE20K、Cityscapes、COCO-Stuff、Pascal VOC、Pascal Context和iSAID在内的流行基准测试上,显著提高了先前最先进方法的性能。值得注意的是,SegNeXt超越了EfficientNet-L2 w/ NAS-FPN,在Pascal VOC 2012测试排行榜上仅使用1/10的参数就达到了90.6%的mIoU。平均而言,与最先进的方法相比,SegNeXt在ADE20K数据集上的mIoU提高了约2.0%,同时计算量相同或更少。
论文地址:论文地址
中文论文:论文地址
代码地址:代码地址
参考代码地址:参考代码地址
4.2 基本原理
MSCA 主要由三个部分组成:(1)一个深度卷积用于聚 合局部信息;(2)多分支深度卷积用于捕获多尺度上下文信息;(3)一个 1 × 1 逐点卷积用于模拟特征中不同通道之间的关系。1 × 1 逐点卷积的输出被直接用 作卷积注意力的权重,以重新权衡 MSCA 的输入。

MSCA 可以写成 如下形式:其中 F 代表输入特征,Att 和 Out 分别为注意力权重和输出,⊗ 表示逐元素的矩 阵乘法运算,DWConv 表示深度卷积,Scalei (i ∈ {0, 1, 2, 3}) 表示上图右边侧图中的第 i 个分支,Scale0 为残差连接。遵循[130],在 MSCA 的每个分支中,SegNeXt 使用两个深度条带卷积来近似模拟大卷积核的深度卷积。每个分支的卷积核大 小分别被设定为 7、11 和 21。 选择深度条带卷积主要考虑到以下两方面原 因:一方面,相较于普通卷积,条带卷积更加轻量化。为了模拟核大小为 7 × 7 的标准二维卷积,只需使用一对 7 × 1 和 1 × 7 的条带卷积。另一方面,在实际 的分割场景中存在一些条状物体,例如人和电线杆。因此,条状卷积可以作为 标准网格状的卷积的补充,有助于提取条状特征。
Att
=
Conv
1
×
1
(
∑
i
=
0
3
Scale
i
(
DW-Conv
(
F
)
)
)
,
\text{Att} = \text{Conv}_{1\times1}\!\left(\sum_{i=0}^{3} \text{Scale}_i\!\left(\text{DW-Conv}(F)\right)\right),
Att=Conv1×1(i=0∑3Scalei(DW-Conv(F))),
Out
=
Att
⊗
F
,
\text{Out} = \text{Att} \otimes F,
Out=Att⊗F,
4.3 参考代码
下面代码来源于
class MSCAAttention(BaseModule):
"""Attention Module in Multi-Scale Convolutional Attention Module (MSCA).
Args:
channels (int): The dimension of channels.
kernel_sizes (list): The size of attention
kernel. Defaults: [5, [1, 7], [1, 11], [1, 21]].
paddings (list): The number of
corresponding padding value in attention module.
Defaults: [2, [0, 3], [0, 5], [0, 10]].
"""
def __init__(self,
channels,
kernel_sizes=[5, [1, 7], [1, 11], [1, 21]],
paddings=[2, [0, 3], [0, 5], [0, 10]]):
super().__init__()
self.conv0 = nn.Conv2d(
channels,
channels,
kernel_size=kernel_sizes[0],
padding=paddings[0],
groups=channels)
for i, (kernel_size,
padding) in enumerate(zip(kernel_sizes[1:], paddings[1:])):
kernel_size_ = [kernel_size, kernel_size[::-1]]
padding_ = [padding, padding[::-1]]
conv_name = [f'conv{i}_1', f'conv{i}_2']
for i_kernel, i_pad, i_conv in zip(kernel_size_, padding_,
conv_name):
self.add_module(
i_conv,
nn.Conv2d(
channels,
channels,
tuple(i_kernel),
padding=i_pad,
groups=channels))
self.conv3 = nn.Conv2d(channels, channels, 1)
def forward(self, x):
"""Forward function."""
u = x.clone()
attn = self.conv0(x)
# Multi-Scale Feature extraction
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
# Channel Mixing
attn = self.conv3(attn)
# Convolutional Attention
x = attn * u
return x
下面代码来源于
https://zhuanlan.zhihu.com/p/566607168
class AttentionModule(BaseModule):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * u
4.4 核心代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 MSCA为文件名的py文件, 把代码拷贝进去。
import torch
import torch.nn as nn
from torch.nn import functional as F
class MSCAAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * u
4.5 注册卷积
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.MSCA import MSCAAttention
步骤2
修改def parse_model(d, ch, verbose=True):
只需要添加截图中标明的,其他没有的模块不用添加。
elif m in {MSCAAttention}:
c2 = ch[f]
args = [c2, *args]
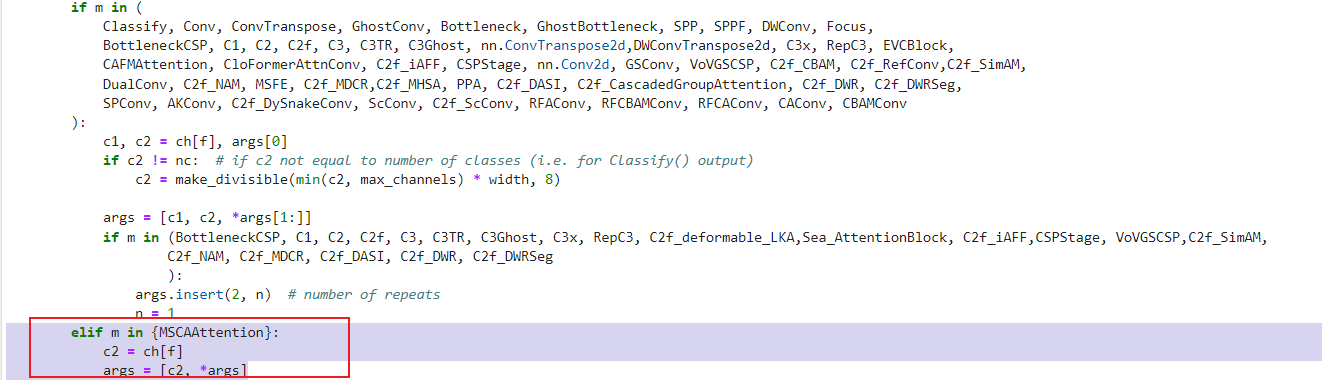
4.6 配置文件
配置文件地址: ultralytics/cfg/models/v8/yolov8_MSCA.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, MSCAAttention, []] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.7 模型训练
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/yolov8_MSCA.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='ultralytics/datasets/original-license-plates.yaml',
name='yolov8_MSCA',
epochs=10,
workers=8,
batch=1)
5. BoTNet + EMA 骨干网络与多尺度注意力的融合改进小目标
5.1 EMA
EMA(Efficient Multi-Scale Attention)模块是一种新颖的高效多尺度注意力机制,旨在提高计算机视觉任务中的特征表示效果。 EMA注意力模块通过结合通道和空间信息、采用多尺度并行子网络结构以及优化坐标注意力机制,实现了更加高效和有效的特征表示,为计算机视觉任务的性能提升提供了重要的技术支持。
-
通道和空间注意力的结合:EMA模块通过将通道和空间信息相结合,实现了通道维度的信息保留和降低计算负担。这种结合有助于在特征表示中捕捉跨通道关系,同时避免了通道维度的削减,从而提高了模型的表现效果。
-
多尺度并行子网络:EMA模块采用多尺度并行子网络结构,其中包括一个处理1x1卷积核和一个处理3x3卷积核的并行子网络。这种结构有助于有效捕获跨维度交互作用,建立不同维度之间的依赖关系,从而提高特征表示的能力。
-
坐标注意力(CA)的再审视:EMA模块在坐标注意力(CA)的基础上进行了改进和优化。CA模块通过将位置信息嵌入通道注意力图中,实现了跨通道和空间信息的融合。EMA模块在此基础上进一步发展,通过并行子网络块有效捕获跨维度交互作用,建立不同维度之间的依赖关系。
-
特征聚合和交互:EMA模块通过并行子网络的设计,有助于实现特征的聚合和交互,从而提高模型对长距离依赖关系的建模能力。这种设计避免了更多的顺序处理和大规模深度,使模型更加高效和有效。
下图是结构,其中包括输入、特征重组、通道注意力和输出步骤。

5.2 BoTNet介绍
BoTNet(Bottleneck Transformers for Visual Recognition)是一种结合自注意力机制和卷积神经网络的骨干架构,主要用于图像分类、目标检测和实例分割等视觉任务。BoTNet通过在ResNet的最后三个瓶颈块中用全局自注意力层替代空间卷积层,显著提高了基线性能,并减少了参数量,同时保持了较低的延迟。
-
瓶颈块与自注意力机制:
- ResNet瓶颈块:经典的ResNet瓶颈块使用多个3×3的卷积层来提取特征。尽管卷积操作能够有效捕捉局部信息,但对于需要建模长距离依赖关系的任务(如实例分割)存在一定局限。
- 多头自注意力(MHSA):BoTNet通过用多头自注意力层替代ResNet瓶颈块中的3×3卷积层,来捕捉全局信息。这种替换使得BoTNet不仅能够捕捉局部特征,还能建模图像中的长距离依赖关系,从而更有效地完成复杂的视觉任务。
-
架构设计:
- 混合模型:BoTNet是一种混合模型,结合了卷积和自注意力机制。卷积层用于从大图像中高效地学习抽象和低分辨率的特征图,自注意力层则用于处理和聚合卷积层捕捉到的信息。
- 具体实现:BoTNet保留了ResNet的大部分架构,仅在最后三个瓶颈块中将3×3卷积层替换为多头自注意力层。这种设计在实例分割任务中显著提升了性能,例如在COCO数据集上,BoTNet在Mask R-CNN框架下实现了44.4%的Mask AP和49.7%的Box AP。
-
计算效率与扩展性:
- 计算效率:尽管自注意力机制的计算和内存需求随着空间维度呈二次方增长,但通过在低分辨率特征图上应用自注意力层,BoTNet有效地控制了计算开销。
- 扩展性:BoTNet不仅适用于图像分类,还在更高分辨率的图像检测和实例分割任务中表现出色。例如,BoTNet在训练72个epoch后,在更大图像尺寸(1280×1280)上的性能优于ResNet,展示了其良好的扩展性。
-
性能表现:
- COCO实例分割:在COCO实例分割基准上,BoTNet显著提升了基于ResNet的Mask R-CNN性能。例如,与使用ResNet-50的基线相比,BoTNet-50在使用相同超参数和训练配置下,Mask AP提高了1.2%。
- ImageNet分类:在ImageNet分类任务中,BoTNet在标准训练设置下表现优异,尤其在使用增强的数据增强和更长时间训练时,BoTNet模型的top-1准确率达到了84.7%。
-
相对位置编码:
- 相对位置编码:BoTNet采用了相对位置编码,使得自注意力操作能够感知位置,这对于视觉任务尤为重要。这种编码方式不仅考虑内容信息,还能有效关联不同位置的特征,从而提高模型性能。
论文地址:论文地址
5.3 引入EMA代码
在根目录下的ultralytics/nn/目录,新建一个attention目录,然后新建一个以 EMA_attention为文件名的py文件, 把代码拷贝进去。
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, c2=None, factor=32):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.EMA_attention import EMA
步骤2
修改def parse_model(d, ch, verbose=True):
elif m in {EMA}:
args = [ch[f],*args]
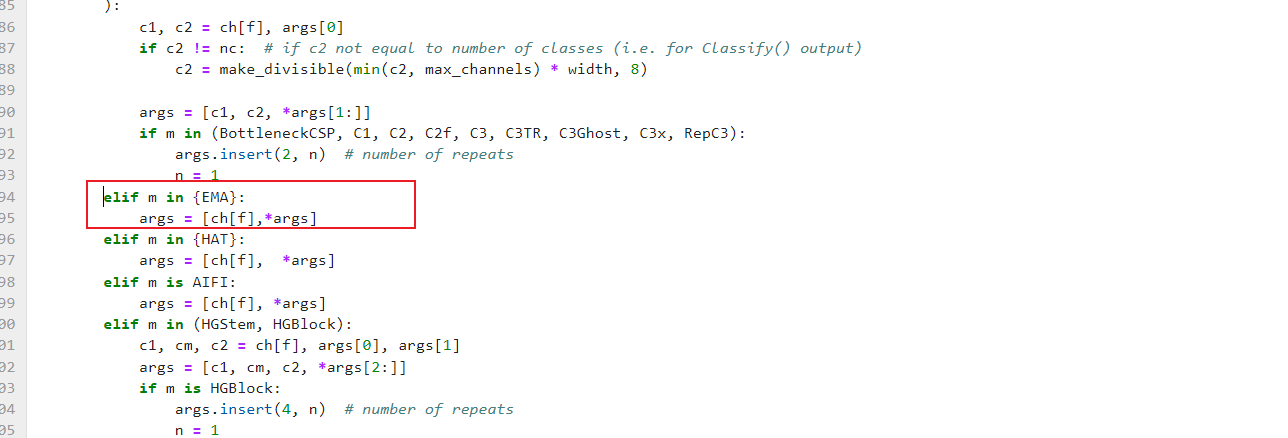
5.4 引入BotNet代码
在根目录下的ultralytics/nn/目录,新建一个 otherModules目录,然后新建一个以 BoTNet为文件名的py文件, 把代码拷贝进去。
import torch
from torch import nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = (
d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
) # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(
c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False
)
self.bn = nn.BatchNorm2d(c2)
self.act = (
self.default_act
if act is True
else act if isinstance(act, nn.Module) else nn.Identity()
)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]),
requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]),
requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k) # 1,C,h*w,h*w
c1, c2, c3, c4 = content_content.size()
if self.pos:
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(
0, 1, 3, 2) # 1,4,1024,64
content_position = torch.matmul(content_position, q) # ([1, 4, 1024, 256])
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2)) # 1,4,256,64
out = out.view(n_batch, C, width, height)
return out
class BottleneckTransformer(nn.Module):
def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None, expansion=1):
super(BottleneckTransformer, self).__init__()
c_ = int(c2 * expansion)
self.cv1 = Conv(c1, c_, 1, 1)
if not mhsa:
self.cv2 = Conv(c_, c2, 3, 1)
else:
self.cv2 = nn.ModuleList()
self.cv2.append(MHSA(c2, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.cv2.append(nn.AvgPool2d(2, 2))
self.cv2 = nn.Sequential(*self.cv2)
self.shortcut = c1 == c2
if stride != 1 or c1 != expansion * c2:
self.shortcut = nn.Sequential(
nn.Conv2d(c1, expansion * c2, kernel_size=1, stride=stride),
nn.BatchNorm2d(expansion * c2)
)
self.fc1 = nn.Linear(c2, c2)
def forward(self, x):
out = x + self.cv2(self.cv1(x)) if self.shortcut else self.cv2(self.cv1(x))
return out
class BoT3(nn.Module):
def __init__(self, c1, c2, n=1, e=0.5, e2=1, w=20, h=20): # ch_in, ch_out, number, , expansion,w,h
super(BoT3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(
*[BottleneckTransformer(c_, c_, stride=1, heads=4, mhsa=True, resolution=(w, h), expansion=e2) for _ in
range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.otherModules.BoTNet import BoT3
步骤2
修改def parse_model(d, ch, verbose=True):
BoT3

5.4 配置文件
配置文件在: ultralytics/ultralytics/cfg/models/v8/yolov8_BoTNet_EMA.yaml
-
在YOLOv8的骨干网络末端引入BotNet架构,其作用是用来优化骨干网络对输入图像特征的提取。
-
在YOLOv8的头部网络末端引入EMA注意力机制,其作用是用来防止权重的剧烈变化,进而提高模型的鲁棒性。
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, BoT3, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [-1, 1, EMA, [1024]] # 23 (P5/32-large)
- [[16, 19, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
5.5 训练
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, BoT3, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [-1, 1, EMA, [1024]] # 23 (P5/32-large)
- [[16, 19, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)


















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











