



✅作者简介:热爱数据处理、数学建模、算法创新的Matlab仿真开发者。
🍎更多Matlab代码及仿真咨询内容点击 🔗:Matlab科研工作室
🍊个人信条:格物致知。
🔥 内容介绍
自动驾驶技术的飞速发展对精确、高效的车辆控制和轨迹规划提出了更高的要求。传统的控制方法往往依赖于预先设计的规则和复杂的数学模型,难以应对复杂多变的道路环境。近年来,深度强化学习技术,特别是深度Q学习(Deep Q-Network, DQN)的出现,为解决这一难题提供了新的思路。本文将探讨如何结合深度Q学习和自行车动力学模型,实现更鲁棒、更智能的汽车控制和轨迹规划。
自行车动力学模型是简化车辆运动学和动力学特征的有效工具,它能够以相对较低的计算代价描述车辆在平面上的运动状态。该模型通常包含车辆的横向和纵向速度、转向角以及车辆的几何参数等关键变量。通过自行车动力学模型,我们可以将控制问题转化为一个基于状态和动作的决策问题,这为应用深度Q学习提供了理想的框架。 DQN算法的核心在于利用神经网络逼近Q函数,该函数表示在特定状态下采取特定动作所获得的预期累积奖励。通过不断地与环境交互,DQN能够学习到最优的策略,从而指导车辆在复杂环境中进行精准的控制和轨迹规划。
然而,直接将DQN应用于汽车控制存在诸多挑战。首先,汽车控制问题是一个高维连续控制问题,而传统的DQN算法主要针对低维离散控制问题进行设计。为了处理连续动作空间,我们可以采用诸如确定性策略梯度(Deterministic Policy Gradient, DDPG)或近端策略优化(Proximal Policy Optimization, PPO)等改进算法。这些算法能够有效地处理连续动作空间,并提高学习效率和稳定性。其次,汽车控制环境的安全性要求极高,任何错误的控制决策都可能导致严重的交通事故。因此,需要设计合适的奖励函数,引导DQN学习到安全可靠的控制策略。奖励函数的设计应综合考虑行驶速度、轨迹跟踪精度、碰撞避免等多种因素,并赋予安全因素更高的权重。此外,为了加速学习过程和提高泛化能力,可以采用经验回放机制和目标网络等技术。经验回放机制可以有效地打破样本间的相关性,提高学习效率;目标网络可以稳定学习过程,避免目标Q值剧烈震荡。
在具体实现过程中,我们可以将自行车动力学模型作为环境模型,DQN作为控制策略。在每个时间步,DQN根据当前车辆状态(例如速度、方向、位置等),从连续的动作空间中选择一个动作(例如转向角和加速度),并将其传递给自行车动力学模型。根据模型的输出,我们可以得到车辆的下一状态以及相应的奖励。DQN根据获得的奖励更新其参数,不断改进控制策略。通过反复迭代,DQN能够学习到一个能够在复杂环境中有效控制车辆的策略,实现精准的轨迹跟踪和安全避障。
为了提高算法的鲁棒性,我们可以考虑引入一些辅助技术。例如,可以利用传感器数据,例如激光雷达或摄像头的数据,来感知周围环境,并将这些信息作为额外的输入特征传递给DQN,从而增强算法对环境变化的适应能力。此外,可以采用多智能体强化学习技术,实现多车协同控制,进一步提高交通效率和安全性。
当然,基于深度Q学习和自行车动力学模型的汽车控制和轨迹规划方法也存在一些局限性。例如,自行车动力学模型本身就是一个简化的模型,它忽略了车辆的许多细节,例如轮胎的侧偏特性和悬架系统的影响。因此,基于该模型训练出的控制策略可能在实际应用中存在一定的误差。此外,深度强化学习算法的训练过程通常需要大量的样本数据,这需要大量的计算资源和时间。
总结而言,基于深度Q学习和自行车动力学模型的汽车控制和轨迹规划方法为自动驾驶技术的发展提供了新的方向。通过结合深度学习的强大学习能力和自行车动力学模型的效率,我们可以实现更加智能、更加安全的车辆控制和轨迹规划。未来研究可以集中在提高模型精度、减少训练数据需求、增强算法鲁棒性以及探索更先进的深度强化学习算法等方面,以进一步提升自动驾驶系统的性能和可靠性。 然而,在实际应用中,需要充分考虑算法的安全性、可靠性和实时性,并进行严格的测试和验证,才能确保其在实际道路环境中的安全和有效运行。
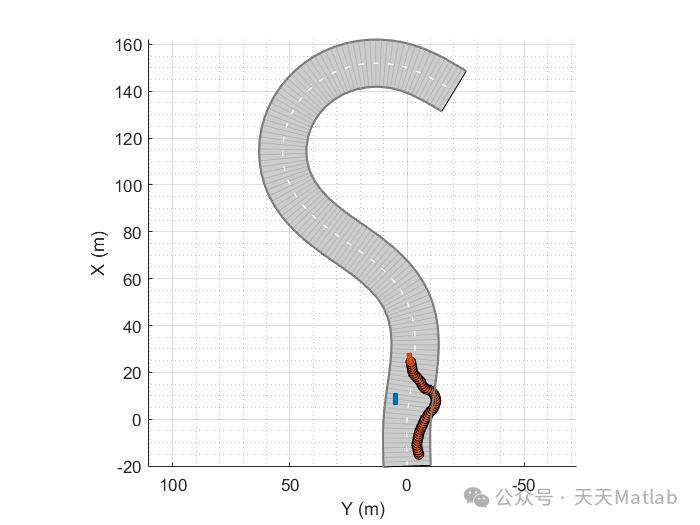
⛳️ 运行结果

🔗 参考文献
🎈 部分理论引用网络文献,若有侵权联系博主删除
🌈 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱调度、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题、港口调度、港口岸桥调度、停机位分配、机场航班调度、泄漏源定位
🌈 机器学习和深度学习时序、回归、分类、聚类和降维
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN|TCN|GCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类


















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











