







 本文介绍了汽车制造中涂装和总装车间的生产流程,重点讨论了涂装-总装缓存调序区(PBS)在调度优化中的作用。针对PBS的约束和时间数据,提出了优化调度模型以满足总装生产需求。文章提出了两个问题,分别考虑不同的约束条件,并提供了模型应用于不同数据集后的得分结果和调度输出格式。
本文介绍了汽车制造中涂装和总装车间的生产流程,重点讨论了涂装-总装缓存调序区(PBS)在调度优化中的作用。针对PBS的约束和时间数据,提出了优化调度模型以满足总装生产需求。文章提出了两个问题,分别考虑不同的约束条件,并提供了模型应用于不同数据集后的得分结果和调度输出格式。
一、背景介绍
汽车制造厂主要由焊装车间、涂装车间、总装车间构成,每个车间有不同的生产偏好,如:焊装车间由于车身夹具的限制偏向最小车型及配置切换生产,涂装车间由于喷漆(固定每5辆车清洗喷头、颜色切换也需清洗喷头)限制偏向颜色以5的倍数切换生产,总装车间由于人员工时(不同车型及配置人员工时不同)及硬件(零部件数量等)等限制偏向按照车型及配置按比例切换生产。
由于各车间的约束不同导致生产调度无法按照同一序列连续生产,特别是涂装车间与总装车间序列差异较大,这就需要在两个车间之间建立一个具有调序功能的缓存区,即PBS(Painted Body Store,汽车制造涂装-总装缓存调序区),用来将涂装车间的出车序列调整到满足总装车间约束的进车序列。
目前,一天安排上线生产的车辆数介于200-450之间,对于每天要上线生产的车辆,车型、颜色等属性均有变化,目前车型大类有2种,颜色大约有10种,各个车间的产能不定,主要根据当天生产安排调整,涂装车间及总装车间的工艺流程如下:
- 涂装车间处理喷漆工艺,主要是将涂料涂覆于白车身表面,最终形成涂膜或者漆膜或者涂层。涂装车间的详细流程如图1所示,主要是将白车身经过前处理电泳-中涂-色漆-清漆,最终得到修饰完整的车身。
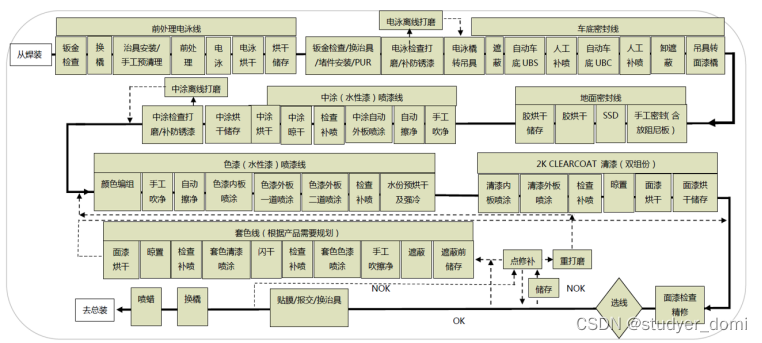
图1 涂装车间工艺流程图
- 总

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











