




一 RAG回顾
RAG(Retrieval-Augmented Generation)的改进方案的提纲。RAG是一种结合了检索和生成的技术,用于提高问答系统的性能。以下是对提纲内容的简单分析:
-
RAG回顾以及有可能存在的问题:
-
文档的读取的准确性,及数据清洗的逻辑。
-
拆分文档也比较麻烦,拆分为chunk
-
query 的不完整性,提问问题的处理。
-
搜索相似的文档,比较 向量的相似度,搜索结果是否能满足回复问题的背景信息。
-
是否对搜索文档做排序,怎么排序?
-
是否需要 对模型回复的结果做 post-process?
-
-
RAG的改进方案
-
这一部分详细列出了四个改进方案:
-
Query的改造:可能涉及对查询语句的优化,使其更有效地检索相关信息。
-
Retriever的改造:可能指的是对检索器的改进,以提高检索结果的相关性和准确性。
-
Ranking的改造:可能涉及对检索结果进行重新排序,以确保最相关的信息排在前面。
-
RAGAS:RAG评估:可能是指对RAG系统进行评估的方法或工具,以衡量其性能和改进效果。
-
-
-
Advanced RAG + 实战项目讲解
-
这一部分可能会介绍更高级的RAG技术,以及如何在实际项目中应用这些技术。这可能包括具体的案例分析和最佳实践。
-
二 RAG优化
2.1 Self-querying retrieval
是RAG优化中的一种技术,它涉及到自我查询检索的过程。以下是对这一概念的简单解读:
-
Self-querying:自我查询是一种策略,其中 模型会生成自己的查询来检索信息。这意味着模型不仅仅是被动地接收输入查询,而是能够主动地生成查询以获取更相关的信息。
-
Retrieval:检索是指从大量数据中找到与查询最相关的信息的过程。在RAG模型中,检索器负责从文档集合中找到与输入查询最相关的文档片段。
-
Self-querying retrieval in RAG:在RAG模型中,自我查询检索可能涉及到模型在生成答案的过程中,根据当前的上下文和已检索到的信息,动态地生成新的查询来进一步检索更精确的信息。这种方法可以帮助模型更深入地理解问题,并从文档中检索到更相关的内容,从而提高生成答案的质量。
2.1.1 写入数据库
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
docs = [
Document(
page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},
),
Document(
page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},
),
Document(
page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},
),
Document(
page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated"},
),
Document(
page_content="Three men walk into the Zone, three men walk out of the Zone",
metadata={
"year": 1979,
"director": "Andrei Tarkovsky",
"genre": "thriller",
"rating": 9.9,
},
),
]
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())2.1.2 自查询
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",
type="string",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
document_content_description = "Brief summary of a movie"
#llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
# This example only specifies a filter
retriever.invoke("I want to watch a movie rated higher than 8.5")
2.2 parent-child splitting and retrieval
Parent-Child Splitting and Retrieval 是一种文档检索技术,它通过将文档分割成多级结构的文本块来提高检索精度和效率。这种方法特别适用于处理大规模和复杂的信息,如电子商务、知识管理、法律和医疗文献检索等领域。
具体来说,该技术包含以下几个步骤:
-
文档分割:首先,将文档分割成较大的文本块,称为Parent Chunks,每个Parent Chunk代表文档中的一个较大部分,通常包含多个段落或章节。然后,每个Parent Chunk进一步细分为更小的块,称为Child Chunks,每个Child Chunk通常包含一个段落或几句话。
-
向量嵌入:使用预训练的模型(例如BERT、GPT等)将每个Child Chunk转换为向量,这些向量代表了文本块的语义信息,可以通过向量检索算法来进行比对和匹配。
-
保持关联关系:Child Chunks与其对应的Parent Chunk保持关联,在后续的检索过程中可以对Parent Chunk进行合并,确保用户获取的信息上下文连贯。
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
loaders = [
TextLoader("example_data/FDR_State_of_Union_1944.txt"),
TextLoader("example_data/Lincoln_State_of_Union_1862.txt"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
# This text splitter is used to create the parent documents
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# This text splitter is used to create the child documents
# It should create documents smaller than the parent
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(
collection_name="split_parents", embedding_function=OpenAIEmbeddings()
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retriever.add_documents(docs)
sub_docs = vectorstore.similarity_search("justice breyer")
print(sub_docs[0].page_content)
retrieved_docs = retriever.get_relevant_documents("justice breyer")
len(retrieved_docs[0].page_content)
2.3 Multiquery Retriever
MultiQueryRetriever是一种检索技术,它通过使用大型语言模型(LLM)从不同角度为给定的用户输入查询生成多个查询,从而自动化提示调优的过程。对于每个查询,它检索一组相关文档,并在所有查询中取唯一的并集,以获取更大的一组潜在相关文档。通过对同一问题生成多个视角,MultiQueryRetriever可以减轻基于距离的检索的一些局限性,并获得更丰富的结果集。
具体来说,MultiQueryRetriever的工作原理如下:
-
接收用户输入的查询。
-
使用LLM生成多个相关但不同的查询。
-
对每个生成的查询进行向量数据库检索。
-
合并所有检索结果,去重后返回。
# Build a sample vectorDB
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
len(unique_docs) # 52.4 Ensemble Retriever
Ensemble Retriever是一种检索工具,它能够集成多个基础检索器(Base Retriever)的结果,通过结合每个检索器的输出来提升整体的检索效果。这种方法利用了不同检索算法的优势,例如将稀疏检索器(如BM25)与密集检索器(如基于向量嵌入的检索)结合起来,因为它们的优势互补,这也被称为"混合搜索"。稀疏检索器擅长通过关键字找到相关文档,而密集检索器则擅长通过语义相似性找到相关文档。
EnsembleRetriever通过初始化一个包含多个BaseRetriever对象的列表,并使用Reciprocal Rank Fusion算法对这些检索器的结果进行重排序。最常见的模式是结合稀疏检索器和密集检索器,因为它们在不同场景下表现出不同的优势。
# !pip install rank_bm25
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
doc_list_1 = [
"I like apples",
"I like oranges",
"Apples and oranges are fruits",
]
# initialize the bm25 retriever and faiss retriever
bm25_retriever = BM25Retriever.from_texts(
doc_list_1, metadatas=[{"source": 1}] * len(doc_list_1)
)
bm25_retriever.k = 2
doc_list_2 = [
"You like apples",
"You like oranges",
]
embedding = OpenAIEmbeddings()
faiss_vectorstore = FAISS.from_texts(
doc_list_2, embedding, metadatas=[{"source": 2}] * len(doc_list_2)
)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
docs = ensemble_retriever.invoke("apples")
docs
三 优化实操代码
3.1 rag优化方式简介
检索器优化:
-
BGE Embedding:使用BGE(Baidu General Embedding)进行文本嵌入,这是一种将文本转换为向量表示的方法,有助于提高检索的准确性。
-
BM25 Retriever:
使用BM25算法进行检索,这是一种基于词频和逆文档频率的检索方法,常用于信息检索任务。 -
Ensemble Retriever:结合多个检索器(如embedding retriever和BM25 retriever)来提高检索效果,通过集成多个模型的优势来提升整体性能。
生成器优化:
-
Contextual Compression:上下文压缩技术,用于减少生成器需要处理的上下文信息量,从而提高生成效率。如 LLMChainExtractor:使用LLMChainExtractor进行文本压缩,这是一种基于大语言模型的文本压缩方法,旨在提取关键信息。
-
BGE Reranker:使用BGE进行重排序,这是一种基于嵌入的重排序方法,用于优化生成器的输出结果。
Ragas评估框架:使用Ragas评估框架对模型进行评估,这是一种用于评估检索增强生成模型性能的工具。
具体步骤:
-
简单RAG - Ragas评估:进行基础的RAG模型评估,使用Ragas框架来测试模型的性能。
-
进阶RAG(检索器优化) - Ragas评估:在简单RAG的基础上,进行检索器优化,使用embedding retriever和BM25 retriever的集成方法,然后进行Ragas评估。
-
进阶RAG(生成器优化 + Bage评估):在检索器优化的基础上,进一步进行生成器优化,使用LLMChainExtractor和BGE Reranker进行文本压缩和重排序,然后进行Ragas评估。
注意1:
如果遇到这种错误:
ModuleNotFoundError: No module named 'pwd'解决方案:
- pip uninstall langchain-community
- pip install langchain-community==0.0.19
2、配置环境变量
- 填写完整该文件中的
OPENAI_API_KEY、HTTP_PROXY、HTTPS_PROXY、HUGGING_FACE_ACCESS_TOKEN四个环境变量
HUGGING_FACE_ACCESS_TOKEN获取方式:https://huggingface.co/settings/tokens- 把
.env.example文件重命名为.env3、运行 Jupyter Lab
- 命令行或终端运行
jupyter lab
(py38_AdvancedRAG) D:\Work\GreedyAI\GiteeProjects\llmdeveloping-advanced-rag>jupyter lab- 浏览器会自动弹出网页:
http://localhost:8888/lab4、下载 embedding model
- 运行
test_bge-large-zh-v1.5.ipynb下载并测试BAAI/bge-large-zh-v1.5模型- 模型 Hugging Face 地址:https://huggingface.co/BAAI/bge-large-zh-v1.5
5、下载 reranker model
- 运行
test_bge-reranker-large.ipynb下载并测试BAAI/bge-reranker-large模型- 模型 Hugging Face 地址:https://huggingface.co/BAAI/bge-reranker-large
3.2 项目准备
3.2.1 测试GPU
import torch
# 检查 PyTorch 版本:确保输出的 PyTorch 版本是支持 GPU 的版本。
print(torch.__version__)
# 例如,版本号中包含 +cpu 表示 CPU 版本,而 +cu 表示 GPU 版本。
# 例如,1.9.0+cu102 表示支持 CUDA 10.2 的 GPU 版本。
# 检查 CUDA 版本:如果您的 PyTorch 版本支持 GPU,您还需要确认您的系统上安装了与 PyTorch 兼容的 CUDA 版本。
print(torch.version.cuda)
# 确保输出的 CUDA 版本与 PyTorch 所需的版本匹配。
# 检查 GPU 是否可用:确保 PyTorch 能够检测到可用的 GPU
print(torch.cuda.is_available())
# 如果输出为 True,则表示 PyTorch 可以使用 GPU。
# 检查 cuDNN 是否可用
print(torch.backends.cudnn.version())
# 如果输出一个版本号,那么 cuDNN 已经成功安装并且可以在 PyTorch 中使用。
# 如果输出 None,则表示 cuDNN 可能没有正确安装或没有与 PyTorch 版本兼容。
# 运行结果:
# 2.1.2+cpu
# None
# False
# None
# 安装GPU版本的torch,从官网(https://pytorch.org/)查询自己的电脑环境支持的版本,这里我下载CUDA11.8版本:
# pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 成功安装:
# Successfully installed torch-2.2.0+cu118 torchaudio-2.2.0+cu118 torchvision-0.17.0+cu118
# 再次运行结果:
# 2.2.0+cu118
# 11.8
# True
# 87003.2.2 test_bge-large-zh-v1.5 模型
https://huggingface.co/BAAI/bge-large-zh-v1.5
获取 hugging face access token:https://huggingface.co/settings/tokens
import os
from dotenv import find_dotenv, load_dotenv
# 加载环境变量
load_dotenv(find_dotenv())
HUGGING_FACE_ACCESS_TOKEN = os.getenv('HUGGING_FACE_ACCESS_TOKEN')from huggingface_hub import snapshot_download
repo_id = "BAAI/bge-large-zh-v1.5" # 模型在huggingface上的名称
local_dir = f"{repo_id.split('/')[0]}/{repo_id.split('/')[1]}" # 本地模型存储的地址
local_dir_use_symlinks = False # 本地模型使用文件保存,而非blob形式保存
# 注意:在hugging face上生成的自己的 access token,否则模型下载会中断
token = HUGGING_FACE_ACCESS_TOKEN
# 开始下载
snapshot_download(
repo_id=repo_id,
local_dir=local_dir,
local_dir_use_symlinks=local_dir_use_symlinks,
token=token,
)测试模型:
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)Using Langchain:
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-zh-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
model.embed_query("样例数据-1")Using Huggingface transformers:
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)3.2.3 test_bge-reranker-large
https://huggingface.co/BAAI/bge-reranker-largetest_bge-reranker-large:https://huggingface.co/BAAI/bge-reranker-large
import os
from dotenv import find_dotenv, load_dotenv
# 加载环境变量
load_dotenv(find_dotenv())
HUGGING_FACE_ACCESS_TOKEN = os.getenv('HUGGING_FACE_ACCESS_TOKEN')
from huggingface_hub import snapshot_download
repo_id = "BAAI/bge-reranker-large" # 模型在huggingface上的名称
local_dir = f"{repo_id.split('/')[0]}/{repo_id.split('/')[1]}" # 本地模型存储的地址
local_dir_use_symlinks = False # 本地模型使用文件保存,而非blob形式保存
# 注意:在hugging face上生成的自己的access token,否则模型下载会中断
token = HUGGING_FACE_ACCESS_TOKEN
# 开始下载
snapshot_download(
repo_id=repo_id,
local_dir=local_dir,
local_dir_use_symlinks=local_dir_use_symlinks,
token=token,
)测试模型:
Using Huggingface transformers:
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
# tensor([-5.6085, 5.7623])results = sorted(enumerate(scores), key=lambda x: x[1], reverse=True)
results # [(1, tensor(5.7623)), (0, tensor(-5.6085))]Using Sentence-Transformers:
from sentence_transformers import CrossEncoder
model_name = 'BAAI/bge-reranker-large'
model = CrossEncoder(model_name)
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
model.predict(pairs) # array([0.00365301, 0.9968658 ], dtype=float32)3.3 简单RAG1 - Ragas评估
一篇新闻文章,有一个(问题,答案)对 - 简单RAG - Ragas评估
import os
from dotenv import find_dotenv, load_dotenv
# 加载环境变量
load_dotenv(find_dotenv())3.3.1 源数据
data from CRUD-RAG:大型语言模型检索增强生成的综合中文基准
origin_data = {
"ID": "64fa9b27b82641eb8ecbe14c",
"event": "2023年7月28日,国家卫生健康委在全国范围内开展“启明行动”——防控儿童青少年近视健康促进活动,发布《防控儿童青少年近视核心知识十条》。",
"news1": "2023-07-28 10:14:27作者:白剑峰来源:人民日报 ,正文:为在全社会形成重视儿童眼健康的良好氛围,持续推进综合防控儿童青少年近视工作落实,国家卫生健康委决定在全国持续开展“启明行动”——防控儿童青少年近视健康促进活动,并发布了《防控儿童青少年近视核心知识十条》。本次活动的主题为:重视儿童眼保健,守护孩子明眸“视”界。强调预防为主,推动关口前移,倡导和推动家庭及全社会共同行动起来,营造爱眼护眼的视觉友好环境,共同呵护好孩子的眼睛,让他们拥有一个光明的未来。国家卫生健康委要求,开展社会宣传和健康教育。充分利用网络、广播电视、报纸杂志、海报墙报、培训讲座等多种形式,广泛开展宣传倡导,向社会公众传播开展儿童眼保健、保护儿童视力健康的重要意义,以《防控儿童青少年近视核心知识十条》为重点普及预防近视科学知识。创新健康教育方式和载体,开发制作群众喜闻乐见的健康教育科普作品,利用互联网媒体扩大传播效果,提高健康教育的针对性、精准性和实效性。指导相关医疗机构将儿童眼保健和近视防控等科学知识纳入孕妇学校、家长课堂内容。开展儿童眼保健及视力检查咨询指导。医疗机构要以儿童家长和养育人为重点,结合眼保健和眼科临床服务,开展个性化咨询指导。要针对儿童常见眼病和近视防控等重点问题,通过面对面咨询指导,引导儿童家长树立近视防控意识,改变不良生活方式,加强户外活动,养成爱眼护眼健康行为习惯。提高儿童眼保健专科服务能力。各地要积极推进儿童眼保健专科建设,扎实组织好妇幼健康职业技能竞赛“儿童眼保健”项目,推动各层级开展比武练兵,提升业务能力。",
"questions": "国家卫生健康委在2023年7月28日开展的“启明行动”是为了防控哪个群体的哪种健康问题,并请列出活动发布的指导性文件名称。",
"answers": "“启明行动”是为了防控儿童青少年的近视问题,并发布了《防控儿童青少年近视核心知识十条》。"
}
print(origin_data['news1'], "\n")
print(origin_data['questions'], "\n")
print(origin_data['answers'], "\n")
3.3.2 构建RAG
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n + {d.page_content}\n{d.metadata}" for i,d in enumerate(docs)])
)
from langchain.schema import Document
# 加载文档
docs = [Document(page_content=origin_data['news1'], metadata={'source': origin_data['ID']})]
print(len(docs)) # 1
pretty_print_docs(docs[:2])
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=256,
chunk_overlap=50,
)
split_docs = text_splitter.split_documents(docs)
print(len(split_docs)) # 4
pretty_print_docs(split_docs[:2])
from langchain.embeddings import HuggingFaceBgeEmbeddings
# 创建嵌入模型
model_name = 'BAAI/bge-large-zh-v1.5'
model_kwargs = {'device': 'cuda'} # 需要安装GPU版本的torch
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)from langchain_community.vectorstores import FAISS
# 创建向量存储
vectordb = FAISS.from_documents(split_docs, embeddings)
index_folder_path = "data/faiss_index"
index_name = "0"
# 保存索引
vectordb.save_local(index_folder_path, index_name)
# 加载索引
vectordb = FAISS.load_local(index_folder_path, embeddings, index_name)
# 创建检索器
retriever = vectordb.as_retriever(search_kwargs={"k": 5})from langchain_openai import ChatOpenAI
# 创建模型
llm = ChatOpenAI(temperature=0)
print(llm.model_name) # gpt-3.5-turbofrom langchain.chains import RetrievalQA
# 创建链
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
# 运行链
response = chain(origin_data['questions'])
print(response)
response['query']
# '国家卫生健康委在2023年7月28日开展的“启明行动”是为了防控哪个群体的哪种健康问题,并请列出活动发布的指导性文件名称。'
response['result']
# '国家卫生健康委在2023年7月28日开展的“启明行动”是为了防控儿童青少年近视健康问题。活动发布的指导性文件名称是《防控儿童青少年近视核心知识十条》。'
pretty_print_docs(response['source_documents'])
3.3.3 评估RAG
数据集包含以下列:
question: list[str] - 这些是将评估您的 RAG 管道的问题。
answer: list[str] - 您的 RAG 管道生成的答案。
context: list[list[str]] - 传递到 LLM 来回答问题的上下文。
ground_truth: list[str] - 问题的真实答案。
# 构建评估数据集
from datasets import Dataset
questions = [origin_data['questions']]
answers = [response['result']]
contexts = [[doc.page_content for doc in response['source_documents']]]
ground_truths = [origin_data['answers']]
evaluate_data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
evaluate_dataset = Dataset.from_dict(evaluate_data)
evaluate_dataset
evaluate_dataset[0]
评估指标:
- Faithfulness
- 如果答案中提出的所有主张都可以从给定的上下文中推断出来,则生成的答案被认为是忠实的。
- answer 和 contexts
- Answer Relevancy
- 评估指标“答案相关性”重点评估生成的答案与给定提示的相关程度。不完整或包含冗余信息的答案将获得较低分数。
- answer 和 question
- Context Precision
- 用于评估 contexts 中存在的所有真实相关项目是否排名较高。理想情况下,所有相关块必须出现在顶层。
- question 和 contexts
- Context Recall
- 上下文回忆衡量检索到的上下文与带注释的答案(被视为基本事实)的一致程度。
- ground truth 和 contexts
- RAGAS评估框架评估了RAG管道的两个主要组件:
- Retriever 检索器
- Generator 生成器
- 与评估 Retrieval 相关的指标如下:
- Context Precision。question 和 contexts
- Context Recall。ground truth 和 contexts
- 与评估 Generation 相关的指标如下:
- Faithfulness。answer 和 contexts
- Answer Relevancy。answer 和 question
# 导入指标
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
# 开始评估
from ragas import evaluate
evaluate_result = evaluate(
evaluate_dataset,
metrics=[
faithfulness,
answer_relevancy,
context_recall,
context_precision,
]
)
evaluate_result
# {'faithfulness': 1.0000, 'answer_relevancy': 0.9222, 'context_recall': 1.0000, 'context_precision': 1.0000}df_evaluate_result = evaluate_result.to_pandas()
df_evaluate_result.to_excel(f'data/{index_name}_eval_result.xlsx', index=False)
df_evaluate_result
3.4 简单RAG2 - Ragas评估
3.4.1 构建Rag
一份PDF文档,有三个(问题,答案)对 - 简单RAG - Ragas评估
import os
from dotenv import find_dotenv, load_dotenv
# 加载环境变量
load_dotenv(find_dotenv())
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n + {d.page_content}\n{d.metadata}" for i,d in enumerate(docs)])
)
from langchain_community.document_loaders import PyPDFLoader
# 加载文档
file_path = "data/初赛训练数据集.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(len(docs)) # 354
pretty_print_docs(docs[:3])
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=256,
chunk_overlap=50,
)
split_docs = text_splitter.split_documents(docs)
print(len(split_docs) # 807
pretty_print_docs(split_docs[:3])
from langchain.embeddings import HuggingFaceBgeEmbeddings
# 创建嵌入模型
model_name = 'BAAI/bge-large-zh-v1.5'
model_kwargs = {'device': 'cuda'} # 需要安装GPU版本的torch
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
from langchain_community.vectorstores import FAISS
# 创建向量存储
vectordb = FAISS.from_documents(split_docs, embeddings)
index_folder_path = "data/faiss_index"
index_name = "1"
# 保存索引
vectordb.save_local(index_folder_path, index_name)
# 加载索引
vectordb = FAISS.load_local(index_folder_path, embeddings, index_name)
# 创建检索器
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
from langchain_openai import ChatOpenAI
# 创建模型
llm = ChatOpenAI(temperature=0)
print(llm.model_name) # gpt-3.5-turbo
from langchain.chains import RetrievalQA
# 创建链
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
# 运行链 - 测试
question = "怎么打开危险警告灯?"
response = chain(question)
print(response)
response['query']
# '怎么打开危险警告灯?'
response['result']
# '要打开危险警告灯,您需要按下车辆上的危险警告灯按键。当车辆遇到交通事故或其他紧急情况时,按下该按键即可启用危险警告灯。值得注意的是,在发生碰撞情况下,危险警告灯也会自动点亮。'
pretty_print_docs(response['source_documents']) 3.4.2 评估RAG
3.4.2 评估RAG
数据集包含以下列:
- question: list[str] - 这些是将评估您的 RAG 管道的问题。
- answer: list[str] - 您的 RAG 管道生成的答案。
- context: list[list[str]] - 传递到 LLM 来回答问题的上下文。
- ground_truth: list[str] - 问题的真实答案。
questions = ["怎么打开危险警告灯?",
"车辆如何保养?",
"靠背太热怎么办?"]
ground_truths = ["危险警告灯开关在方向盘下方,按下开关即可打开危险警告灯。",
"为了保持车辆处于最佳状态,建议您定期关注车辆状态,包括定期保养、洗车、内部清洁、外部清洁、轮胎的保养、低压蓄电池的保养等。",
"您好,如果您的座椅靠背太热,可以尝试关闭座椅加热功能。在多媒体显示屏上依次点击空调开启按键→座椅→加热,在该界面下可以关闭座椅加热。"]
# 生成 answers 和 contexts
answers = []
contexts = []
for question in questions:
print(question)
response = chain(question)
print(response['result'], "\n")
answers.append(response['result'])
contexts.append([doc.page_content for doc in response['source_documents']])
# 构建评估数据集
from datasets import Dataset
evaluate_data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
evaluate_dataset = Dataset.from_dict(evaluate_data)
evaluate_dataset
evaluate_dataset[0]
# 导入指标
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
# 开始评估
from ragas import evaluate
evaluate_result = evaluate(
evaluate_dataset,
metrics=[
faithfulness,
answer_relevancy,
context_recall,
context_precision,
]
)
evaluate_result
# {'faithfulness': 0.6000, 'answer_relevancy': 0.6278, 'context_recall': 1.0000, 'context_precision': 0.3167}
df_evaluate_result = evaluate_result.to_pandas()
df_evaluate_result.to_excel(f'data/{index_name}_eval_result.xlsx', index=False)
df_evaluate_result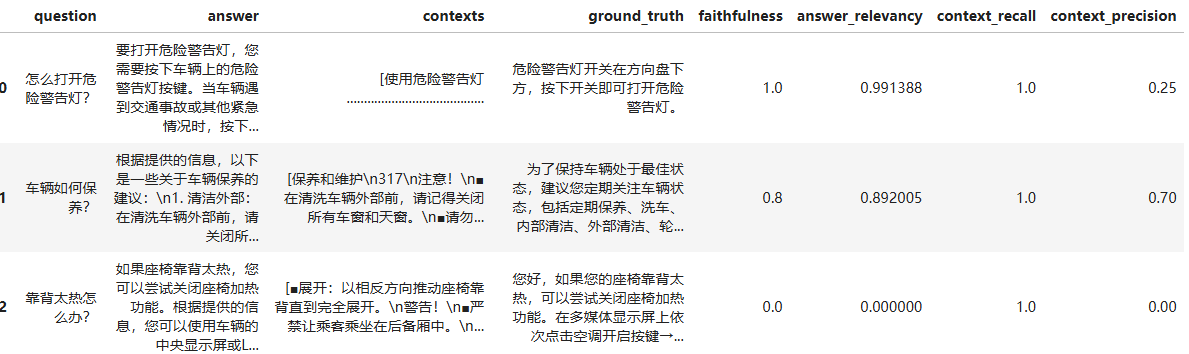
3.5 检索器优化1
3.5.1 构建Raag
一份PDF文档,有三个(问题,答案)对 - 进阶RAG(检索器优化) - Ragas评估
import os
from dotenv import find_dotenv, load_dotenv
# 加载环境变量
load_dotenv(find_dotenv())
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n + {d.page_content}\n{d.metadata}" for i,d in enumerate(docs)])
)
from langchain_community.document_loaders import PyPDFLoader
# 加载文档
file_path = "data/初赛训练数据集.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(len(docs))
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=256,
chunk_overlap=50,
)
split_docs = text_splitter.split_documents(docs)
print(len(split_docs))
pretty_print_docs(split_docs[:3])
from langchain.embeddings import HuggingFaceBgeEmbeddings
# 创建嵌入模型
model_name = 'BAAI/bge-large-zh-v1.5'
model_kwargs = {'device': 'cuda'} # 需要安装GPU版本的torch
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
from langchain_community.vectorstores import FAISS
# 创建向量存储
vectordb = FAISS.from_documents(split_docs, embeddings)
index_folder_path = "data/faiss_index"
index_name = "2"
# 保存索引
vectordb.save_local(index_folder_path, index_name)
# 加载索引
vectordb = FAISS.load_local(index_folder_path, embeddings, index_name)
# 创建密集检索器,擅长根据语义相似度查找相关文档
faiss_retriever = vectordb.as_retriever(search_kwargs={"k": 10})
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# 创建稀疏检索器,擅长根据关键词查找相关文档
bm25_retriever = BM25Retriever.from_documents(split_docs)
bm25_retriever.k=10
# 创建混合检索器
retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever],
weight=[0.5, 0.5]
question = "怎么打开危险警告灯?"
retrieval_docs = retriever.invoke(question)
len(retrieval_docs) # 20
# 去重后
len(list(set([doc.page_content for doc in retrieval_docs]))) # 20pretty_print_docs(retrieval_docs)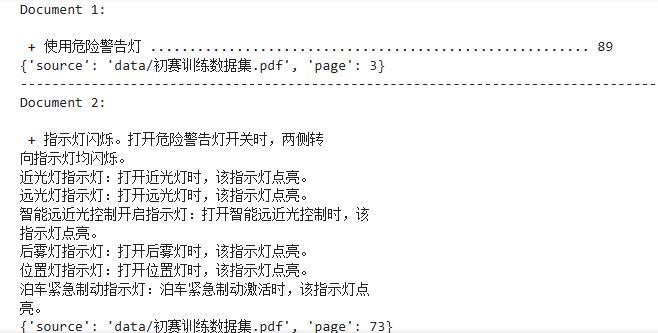
pretty_print_docs(bm25_retriever.invoke(question))
from langchain_openai import ChatOpenAI
# 创建模型
llm = ChatOpenAI(temperature=0)
print(llm.model_name)
from langchain.chains import RetrievalQA
# 创建链
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)3.5.2 评估Rag
questions = ["怎么打开危险警告灯?",
"车辆如何保养?",
"靠背太热怎么办?"]
ground_truths = ["危险警告灯开关在方向盘下方,按下开关即可打开危险警告灯。",
"为了保持车辆处于最佳状态,建议您定期关注车辆状态,包括定期保养、洗车、内部清洁、外部清洁、轮胎的保养、低压蓄电池的保养等。",
"您好,如果您的座椅靠背太热,可以尝试关闭座椅加热功能。在多媒体显示屏上依次点击空调开启按键→座椅→加热,在该界面下可以关闭座椅加热。"]
# 生成 answers 和 contexts
answers = []
contexts = []
for question in questions:
print(question)
response = chain(question)
print(response['result'], "\n")
answers.append(response['result'])
contexts.append([doc.page_content for doc in response['source_documents']])
# 构建评估数据集
from datasets import Dataset
evaluate_data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
evaluate_dataset = Dataset.from_dict(evaluate_data)
evaluate_dataset
evaluate_dataset[0]
# 导入指标
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
# 开始评估
from ragas import evaluate
evaluate_result = evaluate(
evaluate_dataset,
metrics=[
faithfulness,
answer_relevancy,
context_recall,
context_precision,
]
)
evaluate_result
# {'faithfulness': 1.0000, 'answer_relevancy': 0.8593, 'context_recall': 1.0000, 'context_precision': 0.1517}
df_evaluate_result = evaluate_result.to_pandas()
df_evaluate_result.to_excel(f'data/{index_name}_eval_result.xlsx', index=False)
df_evaluate_result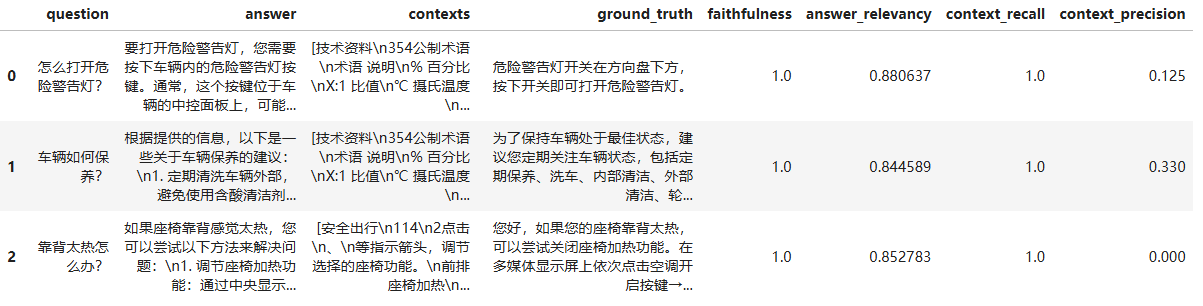
3.6 优化后的检索器 + 生成器优化
3.6.1 构建Rag
一份PDF文档,有三个(问题,答案)对 - 进阶RAG(优化后的检索器 + 生成器优化) - Ragas评估,优化后的检索器 + 基于LLMChainExtractor的文本压缩器 = 上下文压缩。
import os
from dotenv import find_dotenv, load_dotenv
# 加载环境变量
load_dotenv(find_dotenv())
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n + {d.page_content}\n{d.metadata}" for i,d in enumerate(docs)])
)
from langchain_community.document_loaders import PyPDFLoader
# 加载文档
file_path = "data/初赛训练数据集.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(len(docs))
pretty_print_docs(docs[:3])
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=256,
chunk_overlap=50,
)
split_docs = text_splitter.split_documents(docs)
print(len(split_docs)) # 807
pretty_print_docs(split_docs[:3])
from langchain.embeddings import HuggingFaceBgeEmbeddings
# 创建嵌入模型
model_name = 'BAAI/bge-large-zh-v1.5'
model_kwargs = {'device': 'cuda'} # 需要安装GPU版本的torch
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
from langchain_community.vectorstores import FAISS
# 创建向量存储
vectordb = FAISS.from_documents(split_docs, embeddings)
index_folder_path = "data/faiss_index"
index_name = "3.1"
# 保存索引
vectordb.save_local(index_folder_path, index_name)
# 加载索引
vectordb = FAISS.load_local(index_folder_path, embeddings, index_name)
# 创建密集检索器,擅长根据语义相似度查找相关文档
faiss_retriever = vectordb.as_retriever(search_kwargs={"k": 10})
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# 创建稀疏检索器,擅长根据关键词查找相关文档
bm25_retriever = BM25Retriever.from_documents(split_docs)
bm25_retriever.k=10
# 创建混合检索器
retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever],
weight=[0.5, 0.5])
from langchain_openai import ChatOpenAI
# 创建模型
llm = ChatOpenAI(temperature=0)
print(llm.model_name) 3.6.2 优化检索
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 创建文档压缩器:LLMChainExtractor ,它将遍历最初返回的文档,并仅从每个文档中提取与查询相关的内容。
compressor = LLMChainExtractor.from_llm(llm)
# 创建上下文压缩检索器:需要传入一个文档压缩器和基本检索器
# 上下文压缩检索器将查询传递到基本检索器,获取初始文档并将它们传递到文档压缩器。
# 文档压缩器获取文档列表,并通过减少文档内容或完全删除文档来缩短文档列表。
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
from langchain.chains import RetrievalQA
# 创建链
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=compression_retriever,
return_source_documents=True)
# 运行链 - 测试
question = "怎么打开危险警告灯?"
response = chain(question)
print(response)
response['query']
response['result']
pretty_print_docs(response['source_documents'])3.6.3 评估Rag
questions = ["怎么打开危险警告灯?",
"车辆如何保养?",
"靠背太热怎么办?"]
ground_truths = ["危险警告灯开关在方向盘下方,按下开关即可打开危险警告灯。",
"为了保持车辆处于最佳状态,建议您定期关注车辆状态,包括定期保养、洗车、内部清洁、外部清洁、轮胎的保养、低压蓄电池的保养等。",
"您好,如果您的座椅靠背太热,可以尝试关闭座椅加热功能。在多媒体显示屏上依次点击空调开启按键→座椅→加热,在该界面下可以关闭座椅加热。"]
# 生成 answers 和 contexts
answers = []
contexts = []
for question in questions:
print(question)
response = chain(question)
print(response['result'], "\n")
answers.append(response['result'])
contexts.append([doc.page_content for doc in response['source_documents']])
# 构建评估数据集
from datasets import Dataset
evaluate_data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
evaluate_dataset = Dataset.from_dict(evaluate_data)
evaluate_dataset
evaluate_dataset[0]
# 导入指标
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
# 开始评估
from ragas import evaluate
evaluate_result = evaluate(
evaluate_dataset,
metrics=[
faithfulness,
answer_relevancy,
context_recall,
context_precision,
]
)
evaluate_result
# {'faithfulness': 1.0000, 'answer_relevancy': 0.9479, 'context_recall': 1.0000, 'context_precision': 0.4556}
df_evaluate_result = evaluate_result.to_pandas()
df_evaluate_result.to_excel(f'data/{index_name}_eval_result.xlsx', index=False)
df_evaluate_result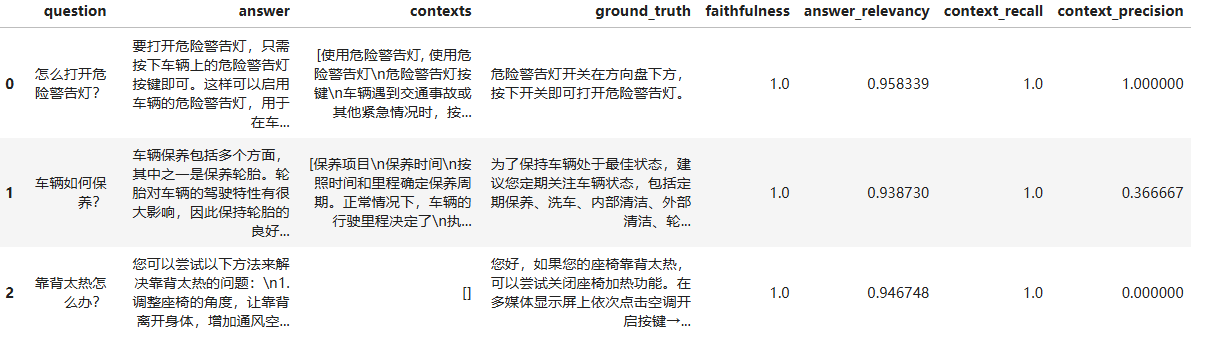
3.7 检索器优化2
一份PDF文档,有三个(问题,答案)对 - 进阶RAG(检索器优化) - Ragas评估,
优化后的检索器 + 基于BGE Reranker的自定义文本压缩器 = 上下文压缩
3.7.1 构建Rag
import os
from dotenv import find_dotenv, load_dotenv
# 加载环境变量
load_dotenv(find_dotenv())
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n + {d.page_content}\n{d.metadata}" for i,d in enumerate(docs)])
)
from langchain_community.document_loaders import PyPDFLoader
# 加载文档
file_path = "data/初赛训练数据集.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(len(docs))
pretty_print_docs(docs[:3])
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 分割文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=256,
chunk_overlap=50,
)
split_docs = text_splitter.split_documents(docs)
print(len(split_docs))
from langchain.embeddings import HuggingFaceBgeEmbeddings
# 创建嵌入模型
model_name = 'BAAI/bge-large-zh-v1.5'
model_kwargs = {'device': 'cuda'} # 需要安装GPU版本的torch
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
from langchain_community.vectorstores import FAISS
# 创建向量存储
vectordb = FAISS.from_documents(split_docs, embeddings)
index_folder_path = "data/faiss_index"
index_name = "3.2"
# 保存索引
vectordb.save_local(index_folder_path, index_name)
# 加载索引
vectordb = FAISS.load_local(index_folder_path, embeddings, index_name)3.7.2 优化检索
# 创建密集检索器,擅长根据语义相似度查找相关文档
faiss_retriever = vectordb.as_retriever(search_kwargs={"k": 10})
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# 创建稀疏检索器,擅长根据关键词查找相关文档
bm25_retriever = BM25Retriever.from_documents(split_docs)
bm25_retriever.k=10
# 创建混合检索器
retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever],
weight=[0.5, 0.5])
question = "怎么打开危险警告灯?"
retrieval_docs = retriever.invoke(question)
len(retrieval_docs)
# 去重后
len(list(set([doc.page_content for doc in retrieval_docs])))
pretty_print_docs(retrieval_docs)
pretty_print_docs(faiss_retriever.invoke(question))
pretty_print_docs(bm25_retriever.invoke(question))
from langchain_openai import ChatOpenAI
# 创建模型
llm = ChatOpenAI(temperature=0)
print(llm.model_name)3.7.3 重排序
from langchain.retrievers.document_compressors import CohereRerank
compressor = CohereRerank()之前使用的是 LLMChainExtractor,现在打算使用重排序模型做上下文压缩。
我们需要构建一个与 CohereRerank 类相似的类,这个类使用我们自己的reranker模型。
CohereRerank 类代码:
from __future__ import annotations
from typing import TYPE_CHECKING, Dict, Optional, Sequence
from langchain_core.documents import Document
from langchain_core.pydantic_v1 import Extra, root_validator
from langchain.callbacks.manager import Callbacks
from langchain.retrievers.document_compressors.base import BaseDocumentCompressor
from langchain.utils import get_from_dict_or_env
if TYPE_CHECKING:
from cohere import Client
else:
# We do to avoid pydantic annotation issues when actually instantiating
# while keeping this import optional
try:
from cohere import Client
except ImportError:
pass
class CohereRerank(BaseDocumentCompressor):
"""Document compressor that uses `Cohere Rerank API`."""
client: Client
"""Cohere client to use for compressing documents."""
top_n: int = 3
"""Number of documents to return."""
model: str = "rerank-english-v2.0"
"""Model to use for reranking."""
cohere_api_key: Optional[str] = None
user_agent: str = "langchain"
"""Identifier for the application making the request."""
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@root_validator(pre=True)
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that api key and python package exists in environment."""
try:
import cohere
except ImportError:
raise ImportError(
"Could not import cohere python package. "
"Please install it with `pip install cohere`."
)
cohere_api_key = get_from_dict_or_env(
values, "cohere_api_key", "COHERE_API_KEY"
)
client_name = values.get("user_agent", "langchain")
values["client"] = cohere.Client(cohere_api_key, client_name=client_name)
return values
def compress_documents(
self,
documents: Sequence[Document],
query: str,
callbacks: Optional[Callbacks] = None,
) -> Sequence[Document]:
"""
Compress documents using Cohere's rerank API.
Args:
documents: A sequence of documents to compress.
query: The query to use for compressing the documents.
callbacks: Callbacks to run during the compression process.
Returns:
A sequence of compressed documents.
"""
if len(documents) == 0: # to avoid empty api call
return []
doc_list = list(documents)
_docs = [d.page_content for d in doc_list]
results = self.client.rerank(
model=self.model, query=query, documents=_docs, top_n=self.top_n
)
final_results = []
for r in results:
doc = doc_list[r.index]
doc.metadata["relevance_score"] = r.relevance_score
final_results.append(doc)
return final_results
基础架构类似:
from langchain.retrievers.document_compressors.base import BaseDocumentCompressor
class BgeRerank(BaseDocumentCompressor):
# 这里放一些类属性
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
def compress_documents(
self,
documents: Sequence[Document],
query: str,
callbacks: Optional[Callbacks] = None,
) -> Sequence[Document]:
"""
Compress documents using BAAI/bge-reranker models.
Args:
documents: A sequence of documents to compress.
query: The query to use for compressing the documents.
callbacks: Callbacks to run during the compression process.
Returns:
A sequence of compressed documents.
"""
if len(documents) == 0: # to avoid empty api call
return []
doc_list = list(documents)
_docs = [d.page_content for d in doc_list]
results = # self.client.rerank(
# model=self.model, query=query, documents=_docs, top_n=self.top_n
# )
final_results = []
for r in results:
doc = # doc_list[r.index]
doc.metadata["relevance_score"] = # r.relevance_score
final_results.append(doc)
return final_results重点就是如何构建compress_documents函数,其实大部分都是差不多的,只有这部分是cohere rerank 特有的:
results = self.client.rerank(
model=self.model, query=query, documents=_docs, top_n=self.top_n
)传入的是 query, _docs, top_n
query是文本字符串
_docs是文本字符串列表
最终想要的是[Document]列表
bge-reranker-large 模型的使用方式:
from sentence_transformers import CrossEncoder
model_name = 'BAAI/bge-reranker-large'
model = CrossEncoder(model_name)
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
model.predict(pairs)
# array([0.00365301, 0.9968658 ], dtype=float32)# 伪代码
# 待排序的对
pairs = [[问题,上下文], [问题,上下文]]
pairs = [[query,上下文], [query,上下文]]
pairs = []
for doc in _docs:
pairs.append([query, doc])
pairs = [[query, doc] for doc in _docs]
# 模型推理
scores = model.predict(pairs)
scores = array([0.00365301, 0.9968658 ] # len(_docs)个项
# 把scores的数值从高到低排序
results = sorted(enumerate(scores), key=lambda x: x[1], reverse=True)
results = [(1, tensor(5.7623)), (0, tensor(-5.6085))] # len(_docs)个项
return results[:top_n] # top_n个项写出排序函数 bge_rerank
def bge_rerank(self, query, documents, top_n):
pairs = [[query, doc] for doc in documents]
scores = self.model.predict(pairs)
print(scores)
results = sorted(enumerate(scores), key=lambda x: x[1], reverse=True) # 得分从高到低排
return results[:top_n]
调用bge_rerank函数:
results = self.bge_rerank(query=query, documents=_docs, top_n=self.top_n)
得到最终的results,形如:
results = [(1, tensor(5.7623)), (0, tensor(-5.6085))] # top_n个项
后续处理:
results =self.bge_rerank(query=query, documents=_docs, top_n=self.top_n)
final_results = []
for r in results:
doc = doc_list[r[0]] # 次序为r[0]时的document(Document对象)
doc.metadata["relevance_score"] = r[1] # 当前pair[query, doc.page_content]的相关度得分
final_results.append(doc)
return final_results
输出: final_results 是top_n个Document 类对象组成的列表:[Document, Document]3.7.4 实现:创建BgeRerank类
from __future__ import annotations
from typing import Dict, Optional, Sequence
from langchain_core.documents import Document
from langchain_core.pydantic_v1 import Extra, root_validator
from langchain.callbacks.manager import Callbacks
from langchain.retrievers.document_compressors.base import BaseDocumentCompressor
from sentence_transformers import CrossEncoder
class BgeRerank(BaseDocumentCompressor):
"""Document compressor that uses `BAAI/bge-reranker-large`."""
top_n: int = 3
"""Number of documents to return."""
model_name: str = "BAAI/bge-reranker-large"
"""Model name to use for reranking."""
model:CrossEncoder = CrossEncoder(model_name)
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
def bge_rerank(self, query, documents, top_n):
pairs = [[query, doc] for doc in documents]
scores = self.model.predict(pairs)
print(scores)
results = sorted(enumerate(scores), key=lambda x: x[1], reverse=True) # 得分从高到低排
return results[:top_n]
def compress_documents(
self,
documents: Sequence[Document],
query: str,
callbacks: Optional[Callbacks] = None,
) -> Sequence[Document]:
"""
Compress documents using BAAI/bge-reranker-large.
Args:
documents: A sequence of documents to compress.
query: The query to use for compressing the documents.
callbacks: Callbacks to run during the compression process.
Returns:
A sequence of compressed documents.
"""
if len(documents) == 0: # to avoid empty api call
return []
# print(documents[0])
doc_list = list(documents)
# print(doc_list[0])
_docs = [d.page_content for d in doc_list]
# print(_docs[0])
results = self.bge_rerank(query=query, documents=_docs, top_n=self.top_n)
# print(results)
final_results = []
for r in results:
# print(r[0])
doc = doc_list[r[0]]
# print(doc)
doc.metadata["relevance_score"] = r[1]
final_results.append(doc)
return final_results# 创建文档压缩器
compressor = BgeRerank()
compress
question, len(retrieval_docs)
compressor.compress_documents(retrieval_docs, question)
pretty_print_docs(compressor.compress_documents(retrieval_docs, question))
from langchain.retrievers import ContextualCompressionRetriever
# 创建上下文压缩检索器:需要传入一个文档压缩器和基本检索器
# 上下文压缩检索器将查询传递到基本检索器,获取初始文档并将它们传递到文档压缩器。
# 文档压缩器获取文档列表,并通过减少文档内容或完全删除文档来缩短文档列表。
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
from langchain.chains import RetrievalQA
# 创建链
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=compression_retriever,
return_source_documents=True)3.7.5 评估Rag
questions = ["怎么打开危险警告灯?",
"车辆如何保养?",
"靠背太热怎么办?"]
ground_truths = ["危险警告灯开关在方向盘下方,按下开关即可打开危险警告灯。",
"为了保持车辆处于最佳状态,建议您定期关注车辆状态,包括定期保养、洗车、内部清洁、外部清洁、轮胎的保养、低压蓄电池的保养等。",
"您好,如果您的座椅靠背太热,可以尝试关闭座椅加热功能。在多媒体显示屏上依次点击空调开启按键→座椅→加热,在该界面下可以关闭座椅加热。"]
# 生成 answers 和 contexts
answers = []
contexts = []
for question in questions:
print(question)
response = chain(question)
print(response['result'], "\n")
answers.append(response['result'])
contexts.append([doc.page_content for doc in response['source_documents']])
# 构建评估数据集
from datasets import Dataset
evaluate_data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
evaluate_dataset = Dataset.from_dict(evaluate_data)
evaluate_dataset
evaluate_dataset[0]
# 导入指标
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
# 开始评估
from ragas import evaluate
evaluate_result = evaluate(
evaluate_dataset,
metrics=[
faithfulness,
answer_relevancy,
context_recall,
context_precision,
]
)
evaluate_result
# {'faithfulness': 1.0000, 'answer_relevancy': 0.9258, 'context_recall': 1.0000, 'context_precision': 0.5278}
df_evaluate_result = evaluate_result.to_pandas()
df_evaluate_result.to_excel(f'data/{index_name}_eval_result.xlsx', index=False)
df_evaluate_result


















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









