 理解Transformer与BERT:注意力机制与自注意力详解
理解Transformer与BERT:注意力机制与自注意力详解





 本文深入探讨Transformer模型,它是BERT的基础。Transformer通过注意力机制解决了RNN和CNN在序列处理中的局限,实现了并行计算。自我注意力(Self-Attention)层是Transformer的核心,它允许模型考虑全局信息并进行平行化处理。多头自我注意力允许模型从不同角度捕获信息。此外,原始论文中引入的位置编码用于保留序列位置信息。
本文深入探讨Transformer模型,它是BERT的基础。Transformer通过注意力机制解决了RNN和CNN在序列处理中的局限,实现了并行计算。自我注意力(Self-Attention)层是Transformer的核心,它允许模型考虑全局信息并进行平行化处理。多头自我注意力允许模型从不同角度捕获信息。此外,原始论文中引入的位置编码用于保留序列位置信息。
BERT是基于transformer的,在理解BERT之前,需要先了解transformer。Transformer就是将模型中lstm或者RNN结构替换成attention结构,这里就涉及了attention结构。
1. attention
- Attention由来的背景:
RNN模型在解决序列问题上具有一定优势,下图中的左半部分展示了一个双向RNN结构,但通过RNN输出的序列数据不容平行化,例如,b4是融合了a1,a2,a3,a4的基础上才能够得出来,在得出b4之前,需要先计算出b1、b2、b3,这是一个迭代的过程。当然可以考虑使用CNN来实现序列数据平行化,但CNN是通过卷积核的不断划动进行卷积操作,每次卷积只涉及句子的部分信息,不能考虑全局信息。而attention机制则是解决了两者的缺点,及考虑了句子的全局信息,同时实现平行化过程。下图的右半部分展示了Self-attention,可以简单直观理解,self-attention是一个黑盒子,经过它即能输出序列数据,同时也考虑了序列数据的全局信息,且可以平行化。

2. self-attention
- self-attention layer层内部原理
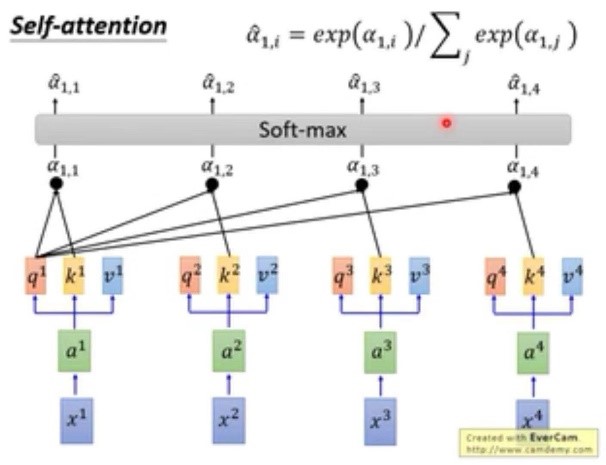
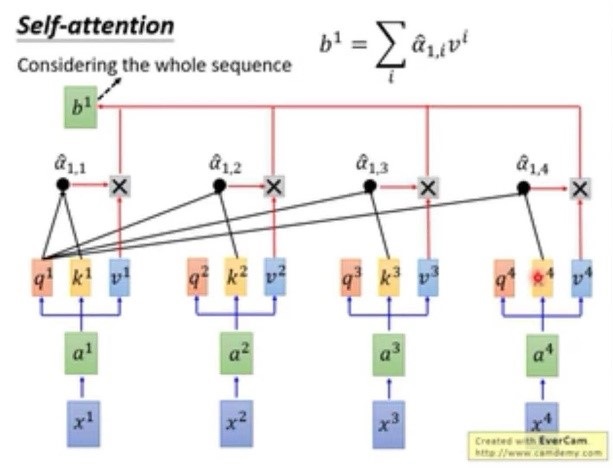

- Attention的平行化
下图表示Attention的平行化,在计算b1的同时是可以计算b2的,两者可以同时进行,没有影响,且b2的输出也包含句子的全部信息。

矩阵表达如下:

展示了经过self-attention后的输入I与输出O:
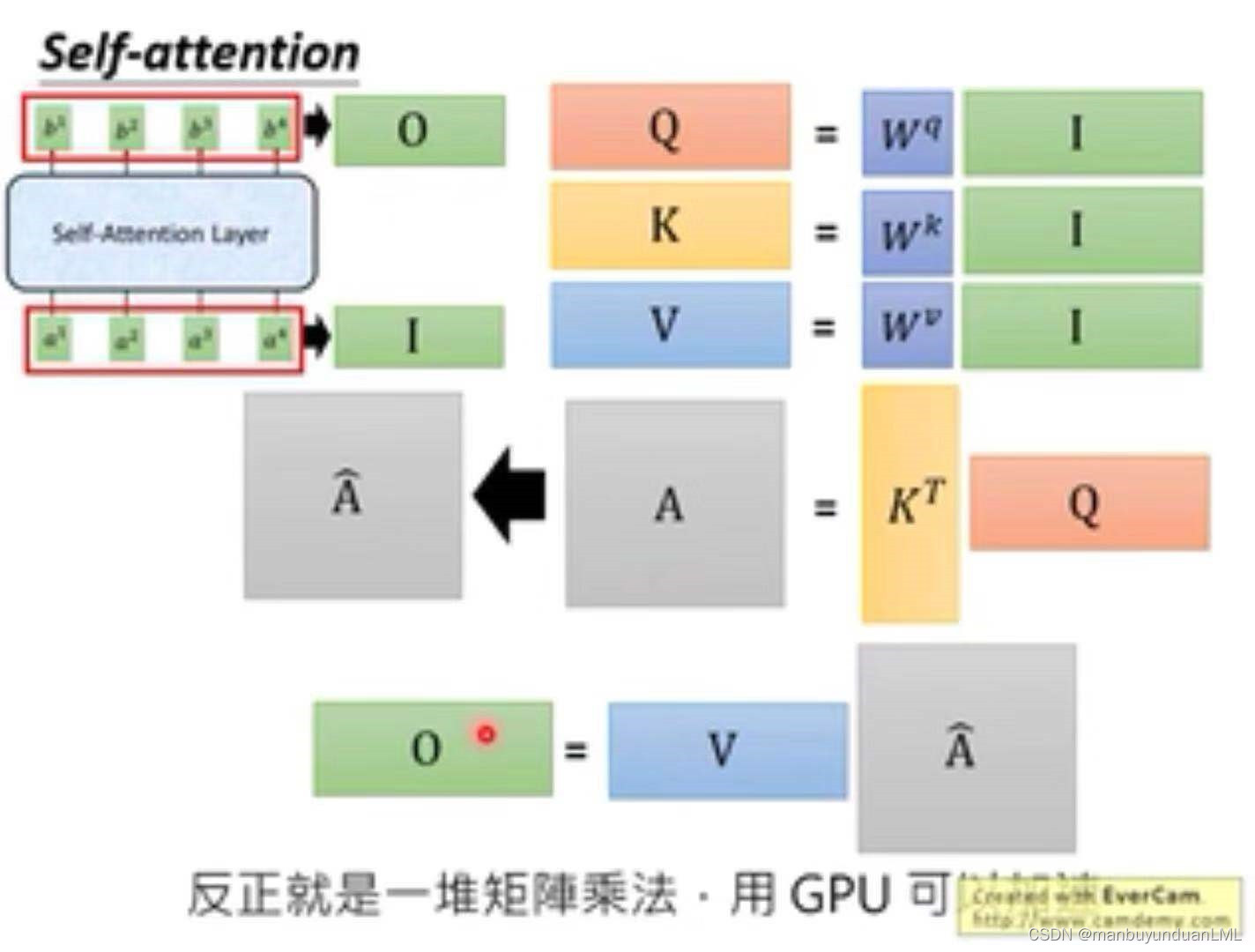 综上所述,self-attention是一堆矩阵的乘法运算,GPU可实现其加速过程。
综上所述,self-attention是一堆矩阵的乘法运算,GPU可实现其加速过程。
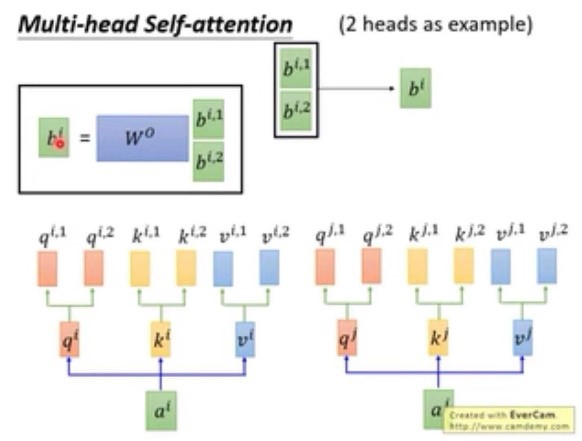
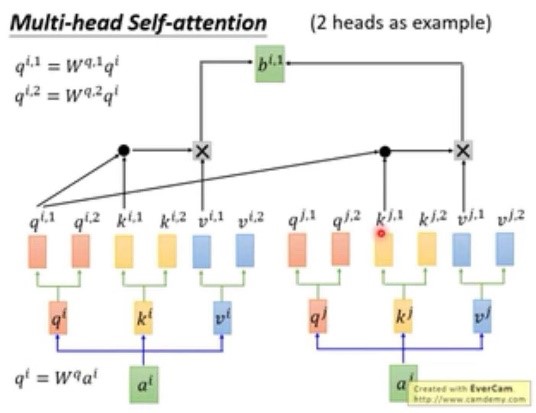
3. multi-head self-attention
下图展示了2个head的self-attention,其中q只能与同样位置的K进行点乘,之所以会选用这种方式是因为每个head的关注点不一样,有的关注句子的局部信息local haed,有的则关注全局信息globel head。对于输出的bi,1与bi,2最终可通过连接和降维等方式输出最后的bi。
- 位置信息
Self-attention是没有考虑位置信息,在原始论文中涉及了位置信息:在ai处增加了相同维度的位置向量ei,该向量不是从数据中得来,是人工设定的,反映不同的位置信息。当然,也可采用其他方式来体现位置在这里的作用。

















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









