




Redis快速入门
Redis(Remote Dictionary Server)是一款 开源、高性能、基于内存的键值对(Key-Value)数据库,支持多种数据结构,常被用于缓存、会话存储、消息队列、实时统计等场景。以下是 Redis 的核心知识点、使用场景及关键特性,帮你快速掌握核心内容:
一、Redis 核心特性
- 基于内存,速度极快:数据主要存储在内存中,读写性能峰值可达 10 万 + QPS,延迟低至亚毫秒级(适合高频访问场景)。
- 支持多种数据结构:不止字符串(String),还支持哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)、位图(Bitmap)、地理哈希(Geo)等,灵活适配不同业务。
- 持久化机制:支持两种持久化方式,避免内存数据丢失:
- RDB(Redis Database):定时快照(如每 5 分钟 + 10 次写入),适合备份、灾难恢复(恢复速度快,但可能丢失最后一次快照后的 data)。
- AOF(Append Only File):记录每一条写命令(如每秒刷盘),数据完整性更高(最多丢失 1 秒数据),但文件体积大、恢复慢。
- 生产环境常搭配使用(RDB 做备份,AOF 保证数据安全)
- 高可用与分布式:
- 主从复制(Master-Slave):主节点写、从节点读,实现读写分离、负载均衡。
- 哨兵(Sentinel):监控主从节点,自动故障转移(主节点挂了,从节点晋升为主)。
- Redis Cluster:分片集群(默认 16384 个哈希槽),支持水平扩容(最多 1000+ 节点),解决单节点内存上限问题。
- 原子操作与事务:支持单个命令的原子性(如
incr自增),也支持MULTI/EXEC事务(批量命令要么全执行,要么全不执行,但不支持回滚)。 - 支持过期键与淘汰策略:
- 键可以设置过期时间(
EXPIRE key seconds),自动删除。 - 内存满时,触发淘汰策略(如 LRU 最近最少使用、LFU 最不经常使用、随机淘汰等)。
- 键可以设置过期时间(
二、核心数据结构及使用场景
| 数据结构 | 核心特点 | 常用命令 | 典型场景 |
|---|---|---|---|
| String(字符串) | 二进制安全(可存图片 / 序列化数据),支持自增 / 自减、拼接 | SET、GET、INCR、APPEND、EXPIRE | 缓存用户信息、计数器(文章阅读量)、分布式锁(SET NX EX) |
| Hash(哈希) | 键值对集合(类似 Java Map),支持单个字段读写 | HSET、HGET、HMGET、HDEL | 存储对象(如用户信息:id -> {name: "xxx", age: 20}) |
| List(列表) | 有序、可重复,支持首尾插入 / 删除(双向链表) | LPUSH、RPUSH、LPOP、RPOP、LRANGE | 消息队列(简单 FIFO)、最新列表(如朋友圈最新动态) |
| Set(集合) | 无序、不可重复,支持交集 / 并集 / 差集 | SADD、SMEMBERS、SINTER(交集)、SUNION(并集) | 好友关系(共同好友)、去重(抽奖用户去重) |
| Sorted Set(有序集合) | 不可重复,每个元素关联分数(score),按分数排序 | ZADD、ZRANGE、ZSCORE、ZREVRANK | 排行榜(如游戏积分排名)、带权重的消息队列 |
| Bitmap(位图) | 以位为单位存储(节省空间),支持位运算 | SETBIT、GETBIT、BITCOUNT | 签到统计(1 代表签到,0 代表未签)、用户在线状态 |
| Geo(地理哈希) | 存储经纬度,支持距离计算、范围查询 | GEOADD、GEODIST、GEORADIUS | 附近的人、外卖骑手定位 |
三、常见使用场景
- 缓存(最核心场景):
- 缓存热点数据(如商品详情、用户信息),减少数据库访问压力。
- 缓存穿透防护:缓存空值或使用布隆过滤器。
- 缓存击穿防护:热点 key 永不过期或加互斥锁。
- 缓存雪崩防护:过期时间加随机值、主从切换、熔断降级。
- 分布式锁:
- 基于
SET key value NX EX seconds实现(NX:不存在才设置,EX:过期时间),保证分布式系统中资源互斥访问。 - 进阶:Redlock 算法(解决单节点故障问题)。
- 基于
- 会话存储:
- 存储用户登录会话(如 Session ID -> 用户信息),替代服务器本地 Session,支持分布式部署。
- 消息队列:
- 基于 List 的
LPUSH + RPOP实现简单 FIFO 队列(缺点:无 ack、无持久化保障)。 - 进阶:使用 Redis Stream(支持 ack、分组消费、持久化)。
- 基于 List 的
- 实时统计:
- 计数器:
INCR统计文章阅读量、接口访问量。 - 位图:统计用户签到天数、活跃用户数。
- 有序集合:实时排行榜(如直播礼物榜)。
- 计数器:
- 限流:
- 基于
INCR + EXPIRE实现固定窗口限流(如 1 分钟最多访问 100 次)。 - 进阶:滑动窗口限流(结合 ZSet 或 Lua 脚本)。
- 基于
四、连接到redis
命令行连接:
redis-cli -h 127.0.0.1 -p 6379
-h:指定 Redis 服务器 IP(默认127.0.0.1)。-p:指定端口(默认 6379)。-a:指定密码(简化认证,不推荐生产环境,密码会明文显示)。--raw:输出中文不转义(如存储中文值时)。
测试连接状态
ping命令可用于测试连接状态,语法如下
ping
说明:若连接正常,则会返回pong。
图形化客户端:
图形化客户端有很多,我这里使用的是Tiny RDM
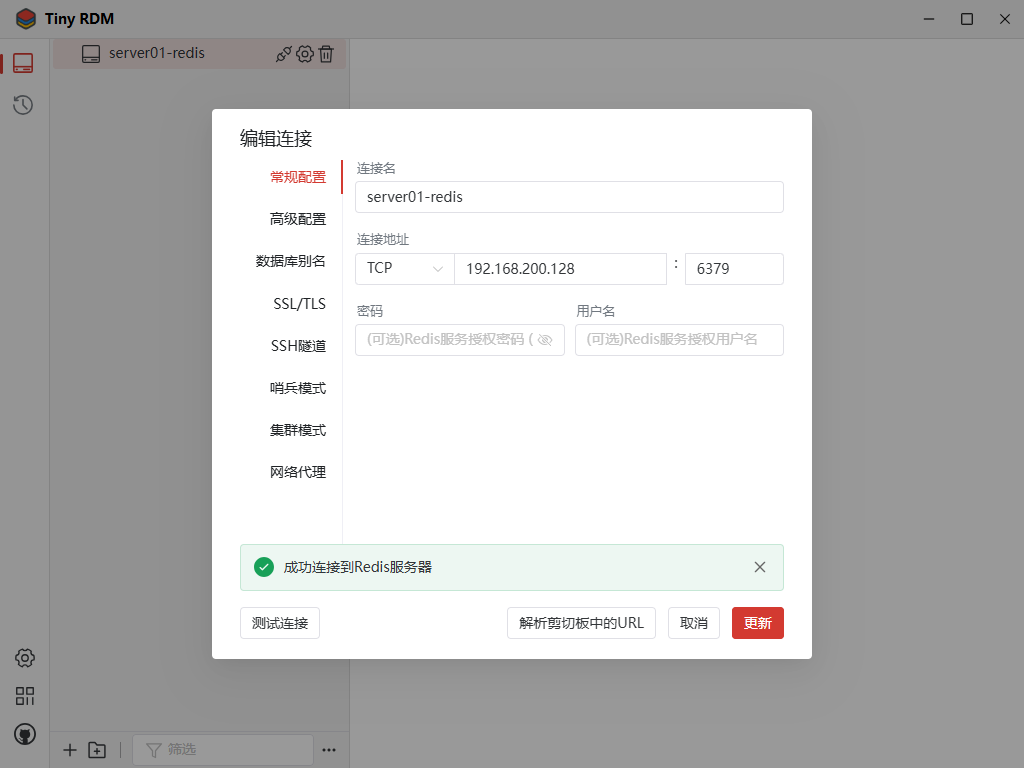
如何连接不上看看服务器防火墙和redis的配置,是否bind 0.0.0.0等
五、Redis常用数据类型及命令
一、通用命令
| 命令 | 说明 | 示例 |
|---|---|---|
KEYS 前缀* | 模糊查键(生产慎用) | KEYS user*(查 user 开头的键) |
EXISTS 键 | 判断键是否存在(1 = 是,0 = 否) | EXISTS user1001 |
DEL 键1 键2 | 批量删除键 | DEL user1001 cart200 |
EXPIRE 键 秒 | 设置过期时间 | EXPIRE code 60(60 秒过期) |
TTL 键 | 查看剩余过期时间(-1 = 永久) | TTL code |
TYPE 键 | 查看键数据类型 | TYPE user1001(返回 hash) |
keys * #查询所有的key
keys user* #查询以user开头的所有key
del key1 key2 #删除key1和key2
expire key3 60 #设置key3的过期时间为60秒
ttl key3 #查看key3还有多少时间过期
type key3 #查看key3是什么类型的数据 字符串还是hash、还是list
二、String 字符串
| 命令 | 说明 | 示例 |
|---|---|---|
SET 键 值 | 设置键值(可加 EX 过期) | SET name 张三 EX 3600 |
GET 键 | 获取键值 | GET name(返回 "张三") |
INCR 键 | 整数自增 1(计数器) | INCR viewcount(阅读量 + 1) |
INCRBY 键 步长 | 自增指定步长 | INCRBY score 10(分数 + 10) |
MSET 键1 值1 键2 值2 | 批量设值 | MSET a 1 b 2 |
MGET 键1 键2 | 批量取值 | MGET a b(返回 [1,2]) |
三、Hash 哈希(存对象)
| 命令 | 说明 | 示例 |
|---|---|---|
HSET 键 字段 值 | 设置哈希字段值 | HSET user1001 name 李四 age 25 |
HGET 键 字段 | 获取哈希字段值 | HGET user1001 name(返回 "李四") |
HGETALL 键 | 获取所有字段和值 | HGETALL user1001 |
HDEL 键 字段 | 删除哈希字段 | HDEL user1001 age |
HMGET 键 字段1 字段2 | 批量获取字段值 | HMGET user1001 name age |
四、List 列表(队列 / 栈)
| 命令 | 说明 | 示例 |
|---|---|---|
LPUSH 键 值 | 左侧插入元素(栈:头进头出) | LPUSH list1 a b c(结果:c,b,a) |
RPUSH 键 值 | 右侧插入元素(队列:尾进头出) | RPUSH list1 d(结果:c,b,a,d) |
LPOP 键 | 左侧弹出元素 | LPOP list1(返回 c) |
RPOP 键 | 右侧弹出元素 | RPOP list1(返回 d) |
LRANGE 键 起始 结束 | 查看区间元素(0=-1 查所有) | LRANGE list1 0 -1(返回 [b,a]) |
五、Set 集合(无序去重)
| 命令 | 说明 | 示例 |
|---|---|---|
SADD 键 元素1 元素2 | 添加元素(自动去重) | SADD usertags java python |
SMEMBERS 键 | 查看所有元素 | SMEMBERS usertags |
SINTER 键1 键2 | 求交集(共同元素) | SINTER user1tags user2tags |
SUNION 键1 键2 | 求并集(所有元素) | SUNION user1tags user2tags |
SREM 键 元素 | 删除集合元素 | SREM usertags python |
六、Sorted Set 有序集合(排行榜)
| 命令 | 说明 | 示例 |
|---|---|---|
ZADD 键 分数1 元素1 | 添加元素(按分数排序) | ZADD rank 95 小明 99 小刚 |
ZRANGE 键 起始 结束 WITHSCORES | 升序查看(带分数) | ZRANGE rank 0 -1 WITHSCORES |
ZREVRANGE 键 起始 结束 | 降序查看(排行榜常用) | ZREVRANGE rank 0 2(前 3 名) |
ZSCORE 键 元素 | 查看元素分数 | ZSCORE rank 小刚(返回 99) |
七、运维常用
| 命令 | 说明 | 示例 |
|---|---|---|
PING | 测试连接(返回 PONG = 正常) | PING |
INFO | 查看 Redis 状态 | INFO memory(查内存) |
CONFIG GET 配置项 | 查看配置(如密码、端口) | CONFIG GET requirepass |
SpringBoot整合Redis
Spring Data Redis概述
Spring Data Redis 是 Spring 生态下的 Redis 数据访问框架,核心作用是简化 Redis 的 Java 开发—— 它封装了原生 Redis 客户端(如 Jedis、Lettuce)的复杂操作,提供统一、简洁的 API,让开发者无需关注底层连接管理、序列化、命令封装等细节,专注于业务逻辑。
简单说:原生 Redis 客户端需要手动写连接、序列化、异常处理代码,而 Spring Data Redis 把这些 “重复工作” 做了封装,让你用类似操作数据库的方式操作 Redis。
一、添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
二、配置application.yml文件
spring:
data:
redis:
host: 192.168.200.128
port: 6379
database: 0
三、RedisConfig配置
package com.yuhuan.book.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 配置连接工厂
redisTemplate.setConnectionFactory(factory);
// 1. 配置 key 序列化器(必须是 String 格式,否则 Redis 中 key 会乱码)
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer()); // hash 的 key 也用字符串序列化
// 2. 配置 value 序列化器(JSON 格式,支持对象自动序列化/反序列化)
GenericJackson2JsonRedisSerializer valueSerializer = new GenericJackson2JsonRedisSerializer();
redisTemplate.setValueSerializer(valueSerializer);
redisTemplate.setHashValueSerializer(valueSerializer); // hash 的 value 也用 JSON 序列化
// 初始化 RedisTemplate
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
四、相关的方法
根据Redis的数据类型,RedisTemplate对各种交互方法做了分组,以下是常用的几个分组
| 分组 | 说明 |
|---|---|
| redisTemplate.opsForValue() | 操作string类型的方法 |
| redisTemplate.opsForList() | 操作list类型的方法 |
| redisTemplate.opsForSet() | 操作set类型的方法 |
| redisTemplate.opsForHash() | 操作hash类型的方法 |
| redisTemplate.opsForZSet() | 操作zset类型的方法 |
| redisTemplate | 通用方法 |
五、使用示例
package com.yuhuan.book;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.connection.DataType;
import org.springframework.data.redis.core.*;
import java.util.*;
import java.util.concurrent.TimeUnit;
@SpringBootTest
public class RedisTemplateTest {
// 注入 RedisTemplate(后续手动设置序列化器避免乱码)
@Autowired
private RedisTemplate redisTemplate;
// ========================== 1. 字符串(String)操作(原有基础扩展)==========================
@Test
public void testStringOps() {
ValueOperations valueOps = redisTemplate.opsForValue();
// 1. 普通设值(无过期时间)
valueOps.set("user002", "wangdaniu");
// 2. 设值并设置过期时间(10分钟)
valueOps.set("verify_code_138", "67890", 10, TimeUnit.MINUTES);
// 3. 不存在时才设值(避免覆盖,返回 boolean)
boolean success = valueOps.setIfAbsent("lock_key", "locked", 30, TimeUnit.SECONDS);
System.out.println("锁设置成功?" + success);
// 4. 取值
String user = (String) valueOps.get("user002");
String code = (String) valueOps.get("verify_code_138");
System.out.println("user002: " + user);
System.out.println("验证码: " + code);
// 5. 自增(常用于计数器,比如文章阅读量)
valueOps.set("article_view_1001", 0);
Long viewCount = valueOps.increment("article_view_1001"); // 自增1,返回新值
System.out.println("文章1001阅读量: " + viewCount);
// 6. 自减(比如库存)
valueOps.set("product_stock_2001", 100);
Long stock = valueOps.decrement("product_stock_2001", 5); // 自减5,返回新值
System.out.println("商品2001库存: " + stock);
}
// ========================== 2. 哈希(Hash)操作(适合存储对象属性)==========================
@Test
public void testHashOps() {
HashOperations hashOps = redisTemplate.opsForHash();
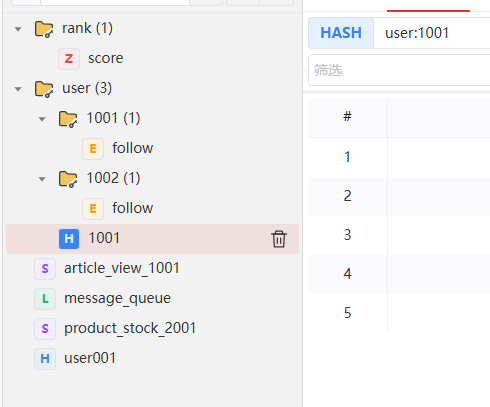
String hashKey = "user:1001"; // 哈希表的 key(比如用户ID)
// 1. 单个属性设值
hashOps.put(hashKey, "id", "1001");
hashOps.put(hashKey, "username", "zhangsan");
hashOps.put(hashKey, "age", "25");
hashOps.put(hashKey, "email", "zhangsan@xxx.com");
// 2. 批量设值(Map)
Map<String, String> userMap = new HashMap<>();
userMap.put("gender", "male");
userMap.put("phone", "13800138000");
hashOps.putAll(hashKey, userMap);
// 3. 取值(单个属性)
String username = (String) hashOps.get(hashKey, "username");
System.out.println("用户名: " + username);
// 4. 取所有属性和值(返回 Map)
Map<String, String> allProperties = hashOps.entries(hashKey);
System.out.println("用户1001所有属性: " + allProperties);
// 5. 取所有属性名(key集合)
Set<String> keys = hashOps.keys(hashKey);
System.out.println("属性名集合: " + keys);
// 6. 取所有属性值(value集合)
List<String> values = hashOps.values(hashKey);
System.out.println("属性值集合: " + values);
// 7. 判断属性是否存在
boolean hasEmail = hashOps.hasKey(hashKey, "email");
System.out.println("是否有email属性?" + hasEmail);
// 8. 删除某个属性
hashOps.delete(hashKey, "phone");
System.out.println("删除phone后属性: " + hashOps.entries(hashKey));
}
// ========================== 3. 列表(List)操作(有序、可重复,适合队列/栈)==========================
@Test
public void testListOps() {
ListOperations listOps = redisTemplate.opsForList();
String listKey = "message_queue"; // 比如消息队列
// 1. 从列表左侧添加元素(栈:先进后出)
listOps.leftPush(listKey, "msg1: 订单创建");
listOps.leftPush(listKey, "msg2: 订单支付");
listOps.leftPush(listKey, "msg3: 订单发货");
// 2. 从列表右侧添加元素(队列:先进先出)
listOps.rightPush(listKey, "msg4: 订单完成");
// 3. 取列表长度
Long size = listOps.size(listKey);
System.out.println("消息队列长度: " + size);
// 4. 遍历列表(0=开始索引,-1=结束索引,即所有元素)
List<String> allMsg = listOps.range(listKey, 0, -1);
System.out.println("所有消息: " + allMsg);
// 5. 从左侧弹出元素(移除并返回)
String leftPopMsg = (String) listOps.leftPop(listKey);
System.out.println("左侧弹出消息: " + leftPopMsg);
// 6. 从右侧弹出元素
String rightPopMsg = (String) listOps.rightPop(listKey);
System.out.println("右侧弹出消息: " + rightPopMsg);
// 7. 按索引取值(0=第一个,-1=最后一个)
String indexMsg = (String) listOps.index(listKey, 0);
System.out.println("第一个消息: " + indexMsg);
// 8. 截取列表(保留索引0-1的元素,其余删除)
listOps.trim(listKey, 0, 1);
System.out.println("截取后消息: " + listOps.range(listKey, 0, -1));
}
// ========================== 4. 集合(Set)操作(无序、不可重复,适合去重/交集)==========================
@Test
public void testSetOps() {
SetOperations setOps = redisTemplate.opsForSet();
String setKey1 = "user:1001:follow"; // 用户1001关注的人
String setKey2 = "user:1002:follow"; // 用户1002关注的人
// 1. 添加元素(可多个)
setOps.add(setKey1, "user2001", "user2002", "user2003", "user2004");
setOps.add(setKey2, "user2002", "user2003", "user2005", "user2006");
// 2. 取集合所有元素
Set<String> follow1 = setOps.members(setKey1);
Set<String> follow2 = setOps.members(setKey2);
System.out.println("用户1001关注: " + follow1);
System.out.println("用户1002关注: " + follow2);
// 3. 取两个集合的交集(共同关注)
Set<String> commonFollow = setOps.intersect(setKey1, setKey2);
System.out.println("共同关注: " + commonFollow);
// 4. 取两个集合的并集(所有关注)
Set<String> allFollow = setOps.union(setKey1, setKey2);
System.out.println("所有关注(去重): " + allFollow);
// 5. 取差集(用户1001关注但1002没关注的)
Set<String> diffFollow = setOps.difference(setKey1, setKey2);
System.out.println("1001独有关注: " + diffFollow);
// 6. 判断元素是否在集合中
boolean isFollow = setOps.isMember(setKey1, "user2002");
System.out.println("1001是否关注user2002?" + isFollow);
// 7. 随机弹出一个元素
String randomMember = (String) setOps.pop(setKey1);
System.out.println("随机弹出关注: " + randomMember);
// 8. 集合大小
Long setSize = setOps.size(setKey1);
System.out.println("1001关注数: " + setSize);
}
// ========================== 5. 有序集合(ZSet)操作(有序、不可重复,适合排序/排名)==========================
@Test
public void testZSetOps() {
ZSetOperations zSetOps = redisTemplate.opsForZSet();
String zSetKey = "rank:score"; // 分数排行榜
// 1. 添加元素(value + score,score用于排序)
zSetOps.add(zSetKey, "user1001", 95.5);
zSetOps.add(zSetKey, "user1002", 88.0);
zSetOps.add(zSetKey, "user1003", 92.3);
zSetOps.add(zSetKey, "user1004", 98.0);
// 2. 按分数升序排列(0=开始索引,-1=所有元素)
Set<String> ascRank = zSetOps.range(zSetKey, 0, -1);
System.out.println("分数升序排名: " + ascRank);
// 3. 按分数降序排列(常用:排行榜从高到低)
Set<String> descRank = zSetOps.reverseRange(zSetKey, 0, -1);
System.out.println("分数降序排名: " + descRank);
// 4. 取元素的分数
Double score = zSetOps.score(zSetKey, "user1004");
System.out.println("user1004分数: " + score);
// 5. 取元素的排名(升序排名,从0开始)
Long rank = zSetOps.rank(zSetKey, "user1003");
System.out.println("user1003升序排名(第N名): " + (rank + 1)); // +1 转为人习惯的排名
// 6. 分数区间查询(比如80-90分的用户)
Set<String> scoreRange = zSetOps.rangeByScore(zSetKey, 80, 90);
System.out.println("80-90分用户: " + scoreRange);
// 7. 给元素加分(比如用户积分增加)
Double newScore = zSetOps.incrementScore(zSetKey, "user1002", 5.0);
System.out.println("user1002加分后分数: " + newScore);
// 8. 有序集合大小
Long zSetSize = zSetOps.size(zSetKey);
System.out.println("排行榜人数: " + zSetSize);
}
// ========================== 6. 通用操作(key相关)==========================
@Test
public void testCommonOps() {
// 1. 判断key是否存在
boolean exists = redisTemplate.hasKey("user002");
System.out.println("user002是否存在?" + exists);
// 2. 设置key过期时间(30秒)
redisTemplate.expire("user002", 30, TimeUnit.SECONDS);
// 3. 查看key剩余过期时间(返回-1=永久,-2=已过期/不存在)
Long expire = redisTemplate.getExpire("user002", TimeUnit.SECONDS);
System.out.println("user002剩余过期时间(秒): " + expire);
// 4. 移除key过期时间(转为永久)
redisTemplate.persist("user002");
// 5. 模糊查询key(慎用!生产环境大数据量会阻塞Redis)
Set<String> keys = redisTemplate.keys("user*"); // 匹配所有以user开头的key
System.out.println("模糊查询user开头的key: " + keys);
// 6. 删除key(单个)
redisTemplate.delete("user002");
// 7. 批量删除key
redisTemplate.delete(Arrays.asList("verify_code_138", "lock_key"));
// 8. 查看key的类型
DataType type = redisTemplate.type("rank:score");
System.out.println("rank:score的类型: " + type); // ZSET
}
}

















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









