










 本文介绍了Redis的基础知识,包括为何使用Redis、其内存存储和高性能特点。详细阐述了Redis的数据类型,如string、hash、list、set和zset,以及它们在不同场景下的应用。还探讨了Redis的配置选项,如持久化策略、集群设置等,并提供了配置示例。此外,讲解了如何在Java应用中集成和使用Jedis。最后,讨论了Redis的rdb和aof两种持久化机制及其优缺点,以及如何在实际开发中结合使用。
本文介绍了Redis的基础知识,包括为何使用Redis、其内存存储和高性能特点。详细阐述了Redis的数据类型,如string、hash、list、set和zset,以及它们在不同场景下的应用。还探讨了Redis的配置选项,如持久化策略、集群设置等,并提供了配置示例。此外,讲解了如何在Java应用中集成和使用Jedis。最后,讨论了Redis的rdb和aof两种持久化机制及其优缺点,以及如何在实际开发中结合使用。
redis入门应用
为何用redis
传统的MySQL在查询走的是磁盘IO,耗时较长,在高并发的情况下,性能很容易出问题;redis是一个基于内存设计的非关系型数据库,数据之间没有关系,查询速度非常快,对海量用户处理非常高效;
redis介绍
Redis(Remote Dictionary Server)是用 C 语言开发的一个开源的基于内存的高性能键值对(key-value)缓存和存储系统。
特点
- 高性能。
内存存储,不走磁盘IO,在大数据量下也可以高性能运行。
官方提供测试数据,50个并发执行100000个请求,读110000 次/s,写81000次/s - 数据结构丰富
支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。 - 原子性
核心读写部分是单线程的,排队执行,对应的操作便具有了原子性,避免了多线程操作带来的复杂性和不安全因素。 - 易拓展。
关系型数据库中记录、表关系复杂,扩容难度高;NoSQL中数据无关系,Redis3.0开始支持集群,扩容简单。 - 高可用。
Redis3.0开始支持集群,可以多主多从,当某个节点发生异常时,可以由其他对应节点顶替,保持整个集群的高可用。 - 可持久化
支持把数据持久化存储到磁盘中,以便下次启动或遇到故障时,从磁盘加载恢复数据。
应用场景
- 缓存。查询频率较高,长久保存,但又不经常变化的数据。
- 即时信息。临时性的,经常变化的数据。(手机号验证码)
- Session共享。解决分布式系统中session共享的问题。(分布式系统访问令牌)
- 其他。诸如:时效性信息、消息队列等(list类型左进右出)
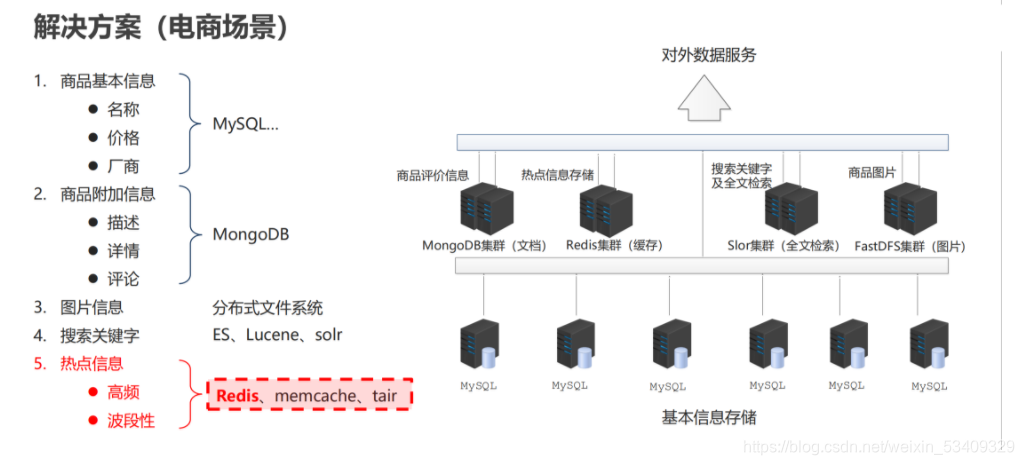
数据库应用场景示意
配置
最简配置
# 绑定Ip 指定可以通过本机的哪个网口连接本Redis实例 如果注释(删掉)则任意IP都可以连接
# 生产环境中,为了安全,需要指定。学习期间为了方便,注释掉
# 可以在一行绑定本机的多个IP,中间使用空格分割
# bind 127.0.0.1
bind 127.0.0.1 192.168.115.130
# 指定Redis的端口
port 6379
# 当客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 0
# 是否以守护进程启动,守护进程表示后台启动,非守护进程表示前台启动
daemonize no
# 设置日志的级别 debug、verbose、notice、warning,默认为verbose
loglevel verbose
# 日志文件的名字,当指定为空字符串时,为标准输出,如果redis已守护进程模式运行,那么日志将会输出到 /dev/null 。
# 如果这里配置了指定的日志文件,就算redis以非守护进程方式启动(前台启动),日志也只是输入到日志文件,而不会在启动窗口展示
logfile ""
详细配置
# Redis configuration file example.
# 配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit 对大小写不敏感
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
################################## INCLUDES ###################################
# 引入其他文件
# include /path/to/local.conf
# include /path/to/other.conf
# 绑定Ip 指定可以通过本机的哪个网口连接本Redis实例 如果注释(删掉)则任意IP都可以连接
# 生产环境中,为了安全,需要指定。学习期间为了方便,注释掉
# 可以在一行绑定本机的多个IP,中间使用空格分割
# bind 127.0.0.1
# bind 127.0.0.1 192.168.115.130
# 禁止外网访问redis,如果启用了,即使注释掉了bind 127.0.0.1,再访问redisd时候还是无法连接的
# 如果bind了网卡的IP(非127),可以通过对应IP连接
# 它启用的条件有两个,第一是没有使用bind,第二是没有设置访问密码。
protected-mode yes
# 指定Redis的端口
port 6379
# 此参数确定了TCP连接中已完成队列(完成三次握手之后)的长度,
# 当然此值必须不大于Linux系统定义的/proc/sys/net/core/somaxconn值,默认是511,
# 而Linux的默认参数值是128。当系统并发量大并且客户端速度缓慢的时候,可以将这二个参数一起参考设定。
# 在高并发环境下你需要一个高backlog值来避免慢客户端连接问题
tcp-backlog 511
# 当客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 0
# 设置多长时间检测死连接 单位为秒,如果设置为0,则不会进行Keepalive检测
tcp-keepalive 0
# 是否以守护进程启动,守护进程表示后台启动,非守护进程表示前台启动
daemonize no
# 可以通过upstart和systemd管理Redis守护进程,这个参数是和具体的操作系统相关的。
supervised no
# 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis_6379.pid
# 设置日志的级别 debug、verbose、notice、warning,默认为verbose
loglevel verbose
# 日志文件的位置,当指定为空字符串时,为标准输出,如果redis已守护进程模式运行,那么日志将会输出到 /dev/null 。
# 如果这里配置了指定的日志文件,就算redis以非守护进程方式启动(前台启动),日志也只是输入到日志文件,而不会在启动窗口展示
logfile ""
# 设置数据库的数目。默认的数据库是DB 0 ,可以在每个连接上使用select <dbid> 命令选择一个不同的数据库,dbid是一个介于0到databases - 1 之间的数值。
databases 16
#########################以上为基础设置,以下为高级设置#############################
# 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
# 这里表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改
# 如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数也可以
save 900 1
save 300 10
save 60 1
# rdb文件的名字。
dbfilename dump.rdb
# dbfilename文件存放目录。必须是一个目录,aof文件也会保存到该目录下。
dir ./
# 是否启用aof持久化方式 。否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。
# 因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
# 指定更新日志(aof)文件名,默认为appendonly.aof
appendfilename "appendonly.aof"
# 指定更新日志条件,共有3个可选值:
# no:表示等操作系统进行数据缓存同步到磁盘(快,持久化没保证)
# always:同步持久化,每次发生数据变更时,立即记录到磁盘(慢,安全)
# everysec:表示每秒同步一次(默认值,很快,但可能会丢失一秒以内的数据)
# appendfsync always
appendfsync everysec
# appendfsync no
# 指定是否在后台aof文件rewrite期间调用fsync,默认为no,表示要调用fsync(无论后台是否有子进程在刷盘)。
# Redis在后台写RDB文件或重写AOF文件期间会存在大量磁盘IO,此时,在某些linux系统中,调用fsync可能会阻塞。
#如果应用系统无法忍受延迟,而可以容忍少量的数据丢失,则设置为yes。如果应用系统无法忍受数据丢失,则设置为no。
no-appendfsync-on-rewrite no
# 当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写 。当AOF文件大小的增长率大于该配置项时自动开启重写。
auto-aof-rewrite-percentage 100
# 当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写 。当AOF文件大小大于该配置项时自动开启重写
auto-aof-rewrite-min-size 64mb
# redis在启动时可以加载被截断的AOF文件,而不需要先执行redis-check-aof 工具。
aof-load-truncated yes
# 是否开启混合持久化
aof-use-rdb-preamble yes
# 默认情况下,如果 redis 最后一次的后台保存失败,redis 将停止接受写操作,这样以一种强硬的方式让用户知道数据不能正确的持久化到磁盘,
# 否则就会没人注意到灾难的发生。 如果后台保存进程重新启动工作了,redis 也将自动的允许写操作。
# 如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制
stop-writes-on-bgsave-error yes
# 对于存储到磁盘中的快照(rdb),可以设置是否进行压缩存储。如果是的话,redis会采用
# LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能
rdbcompression yes
# 在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约
# 10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdbchecksum yes
# 设置当本机为slave服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
# replicaof <masterip> <masterport>
# 当master服务设置了密码保护时,slave服务连接master的密码
# masterauth <master-password>
# 当一个slave与master失去联系时,或者复制正在进行的时候,slave应对请求的行为:
# 如果为 yes(默认值) ,slave 仍然会应答客户端请求,但返回的数据可能是过时,或者数据可能是空的在第一次同步的时候
# 如果为 no ,在你执行除了 info 和 salveof 之外的其他命令时,slave 都将返回一个 "SYNC with master in progress" 的错误。
replica-serve-stale-data yes
# 设置slave是否是只读的。从2.6版起,slave默认是只读的。
replica-read-only yes
# 主从数据复制是否使用无硬盘复制功能。
repl-diskless-sync no
# 指定slave定期ping master的周期,默认10秒钟。
# repl-ping-replica-period 10
# 设置主库批量数据传输时间或者ping回复时间间隔,默认值是60秒 。
# repl-timeout 60
# 指定向slave同步数据时,是否禁用socket的NO_DELAY选项。
# 若配置为“yes”,则禁用NO_DELAY,则TCP协议栈会合并小包统一发送,这样可以减少主从节点间的包数量并节省带宽,但会增加数据同步到 slave的时间。
# 若配置为“no”,表明启用NO_DELAY,则TCP协议栈不会延迟小包的发送时机,这样数据同步的延时会减少,但需要更大的带宽。
# 通常情况下,应该配置为no以降低同步延时,但在主从节点间网络负载已经很高的情况下,可以配置为yes。
repl-disable-tcp-nodelay no
# 设置主从复制backlog容量大小。这个 backlog 是一个用来在 slaves 被断开连接时存放 slave 数据的 buffer,
# 所以当一个 slave 想要重新连接,通常不希望全部重新同步,只是部分同步就够了,仅仅传递 slave 在断开连接时丢失的这部分数据。
# 这个值越大,salve 可以断开连接的时间就越长。
# repl-backlog-size 1mb
# 配置当master和slave失去联系多少秒之后,清空backlog释放空间。当配置成0时,表示永远不清空。
# repl-backlog-ttl 3600
# 当 master 不能正常工作的时候,Redis Sentinel 会从 slaves 中选出一个新的 master,这个值越小,就越会被优先选中,但是如果是 0 , 那是意味着这个 slave 不可能被选中。 # 默认优先级为 100。
replica-priority 100
# 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
# requirepass foobared
# 设置同一时间最大客户端连接数,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,
# 如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
# maxclients 10000
# 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,
# 当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。
# Redis新的vm机制,会把Key存放内存,Value会存放在swap区
# maxmemory <bytes>
# 当内存使用达到最大值时,redis使用的清除策略。有以下几种可以选择(明明有6种,官方配置文件里却说有5种可以选择?):
# 1)volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
# 2)allkeys-lru 利用LRU算法移除任何key
# 3)volatile-random 移除设置过过期时间的随机key
# 4)allkeys-random 移除随机key
# 5)volatile-ttl 移除即将过期的key(minor TTL)
# 6)noeviction 不移除任何key,只是返回一个写错误 。默认选项
# maxmemory-policy noeviction
# LRU 和 minimal TTL
# 算法都不是精准的算法,但是相对精确的算法(为了节省内存),随意你可以选择样本大小进行检测。redis默认选择5个样本进行检测,你可以通过maxmemory-samples进行设置样本数。
# maxmemory-samples 5
# 一个Lua脚本最长的执行时间,单位为毫秒,如果为0或负数表示无限执行时间
lua-time-limit 5000
# 是否开启cluster集群模式 如果配置yes则开启集群功能,此redis实例作为集群的一个节点,否则,它是一个普通的单一的redis实例。
# cluster-enabled yes
# 虽然此配置的名字叫"集群配置文件",但是此配置文件不能人工编辑,它是集群节点自动维护的文件,
# 主要用于记录集群中有哪些节点、他们的状态以及一些持久化参数等,方便在重启时恢复这些状态。通常是在收到请求之后这个文件就会被更新。
# cluster-config-file nodes-6379.conf
# 这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。
# cluster-node-timeout 15000
# 如果设置成0,则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。
# 如果设置成正数,则cluster-node-timeout乘以cluster-slave-validity-factor得到的时间,是从节点与主节点失联后,
# 此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。
# 假设cluster-node-timeout=5,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过50秒,此从节点不能成为主节点。
# 注意,如果此参数配置为非0,将可能出现由于某主节点失联却没有从节点能顶上的情况,从而导致集群不能正常工作,
# 在这种情况下,只有等到原来的主节点重新回归到集群,集群才恢复运作。
# cluster-replica-validity-factor 10
# master的slave数量大于该值,slave才能迁移到其他孤立master上,如这个参数若被设为2,那么只有当一个主节点拥有2 个可工作的从节点时,它的一个从节点会尝试迁移。
# 不建议设置为0
# 想禁用可以设置一个非常大的值
# 如果小于0则启动失败
# cluster-migration-barrier 1
# 表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,是否整个集群不可用?
# cluster-require-full-coverage yes
redis应用
数据类型
数据类型指的是key-value中的value的类型,key永远是字符串 。
Redis的value支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
- string – Map<String, String>
- hash – Map<String,HashMap<String,String>>
- list – Map<String,List> 有序 可重复
- set – Map<String,Set> 无序 不可重复
- zset(sorted set) – Map<String,TreeSet> 不可重复,可以基于score实现排序
会根据数据不同,选择不同的数据类型,保证在不同场景下,存取处理的速度都是最快的。
String
最简单、最常用的单个数据存储的类型。
常用命令:set/get/mset/mget/setnx/setex
应用场景:计数器(incr、decr)、分布式锁(setnx、del、expire)、存储对象(不经常变化的)(set、get、json格式)、验证码(setex)
命令:
set key value key存在,则覆盖原值
get key
del key
setnx key value 判定性添加数据;key存在,则添加失败
mset key1 value1 key2 value2 ...
mget key1 key2 ..
strlen key 获取数据字符个数(字符串长度)
append key value 追加信息到原始信息后部(存在追加,不存在新建)
incr key ++ (原值不存在,从0开始累加)
incrby key increment +n
incrbyfloat key increment
decr key --
decrby key increment -n
setex key seconds value
psetex key milliseconds value
hash
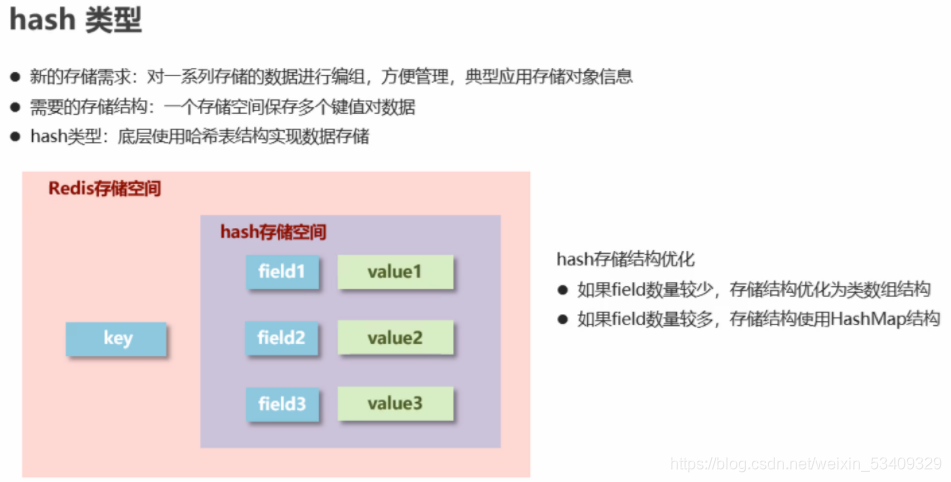
常用指令:hset/hget/hmset/hmget/hexists
应用场景:购物车(hset、hdel)、存储对象(频繁变化的)(hset、hdel)
常用指令示例:
命令:
hset key field value
hget key field
hgetall key //对操作数据量可能会比较大的指令,一定要小心,不要阻塞后面命令执行。先获取长度hlen key
hdel key field1 [field2] ..
hsetnx key field value
hmset key field1 value1 field2 value2 ...
hmget key field1 field2 ...
hlen key
hexists key field
hkeys key 获取所有键 // 在明确数量之前,慎用
hvals key 获取所有值 // 在明确数量之前,慎用
hincrby key field increment
hincrbyfloat key field increment
hexists key 判断对应redis的键是否有值
案例:
双11活动日,销售手机充值卡的商家对移动、联通、电信的30元、50元、100元商品推出抢购活动,每种商品抢购上限1000张
hmset id:001 c30 1000 c50 1000 c100 1000
hmset id:002 c30 1000 c50 1000 c100 1000
hincrby id:001 c30 -5
hincrby id:001 c50 -15
工作中主要还是设置和获取,修改的操作通过java代码实现,而不是通过hincryby
list
键为字符串,值为list。
两端操作的队列,所以可以左右两端操作;
命令中涉及两端操作的,l表示 左,r表示右;其他情况下命令以l开头
没有索引越界异常,获取超出索引返回的是nil
常用命令:lpush/rpush/lpop/rpop/lrange/llen
应用场景:数据顺序添加并汇总,eg:消息队列、最新列表(log日志顺序打印)
常用指令示例:
命令:
lpush key value1 [value2] ... //添加或修改数据
rpush key value2 [value2] ...
lrange key start stop // 在不明确list长度的前提下,慎用lrange key 0 -1
lindex key index 获取指定索引的值
llen key
lpop key
rpop key
lrem key count value 移除指定个数的值
blpop key1 [key2] timeout 规定时间内获取并移除数据
brpop key1 [key2] timeout 规定时间内获取并移除数据
brpoplpush source destination timeout 迁移数据
set
与hash的key结构相同,无序不重复。
命令多以s开头
常用命令sadd/smembers/sismember/sinter/sunion/sdiff
应用场景:好友关注感兴趣的人的集合操作(sinter/sunion/sdiff)、随机展示(srandmember)、黑白名单(sismember)
常用指令示例:
命令:
sadd key member1 [member2]
smembers key // 在明确member数量之前,慎用
srem key member1 [member2]
scard key 获取集合数据总量
sismember key member 判断集合中是否包含指定数据
srandmember key [count] 随机获取集合中指定数量的数据
spop key 随机获取集合中的某个数据并将该数据移出集合
sinter key1 [key2] .. 交集
sunion key1 [key2] .. 并集
sdiff key1 [key2] .. 差集
sinterstore destination key1 [key2]... 交集到指定集合
sunionstore destination key1 [key2]... 并集到指定集合
sdiffstore destination key1 [key2]... 差集到指定集合
综合命令
key
del key -- 删除键值
expires key seconds -- 设置键的有效时长
ttl key -- 查看键的有效时长
keys * // 所有不确定范围的操作,都要慎重!!!
type key
exists key -- 判断key是否存在
persist key -- 将key变为永久有效
// 有效期
永久 -1
失效/不存在 -2
正整数 剩余失效时间 s/ms
数据库操作
redis默认有16个数据库,所有数据库都共享redis内存,但是每个数据库间的数据相互隔离
select index -- 选择数据库 (index的值为0-15)
dbsize -- 查看当前数据库中键的个数
flushdb -- 清除当前数据库的内容
flushall -- 清除所有数据库的内容
jedis应用(集成到程序)
简单应用
1.项目构建:
2.pom文件引入redis依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.blabla</groupId>
<artifactId>jedis-test</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
</project>
3.代码demo:
package com.blabla.test;
import redis.clients.jedis.Jedis;
public class JedisDemo {
public static void main(String[] args) {
// 连接的服务器地址和端口
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.set("luffy","nruto");
System.out.println(jedis.get("blabla"));
//关闭连接
jedis.close();
}
}
4.代码运行前redis中数据
5.代码运行后数据:
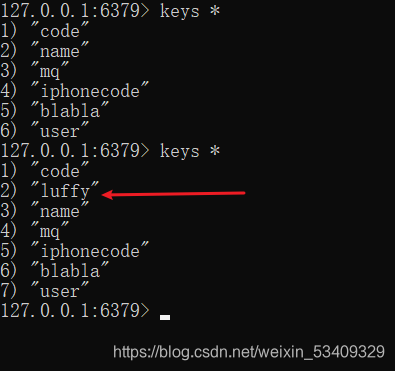
抽取到配置文件配置
池化思想:
原生的jedis使用不够灵活,服务器地址变了之后就要修改代码,而且每次都会创建和销毁,我们考虑抽一下,且不必每次都关闭连接;
项目结构
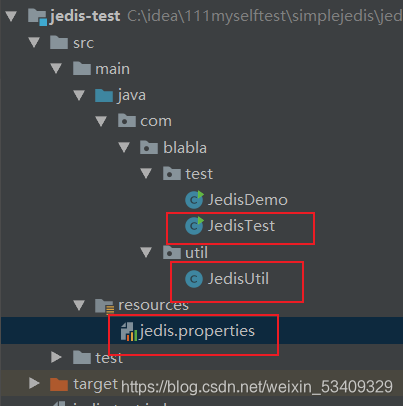
jedis配置文件
# 最大连接数
redis.maxTotal=50
# 客户端没需求留的链接数
redis.maxIdel=10
# 连接地址
redis.host=localhost
# 连接端口
redis.port=6379
JedisUtil
package com.blabla.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.ResourceBundle;
public class JedisUtil {
private static int maxTotal;
private static int maxIdel;
private static int port;
private static String host;
private static JedisPool jp;
static {
// 读取配置文件
ResourceBundle bundle = ResourceBundle.getBundle("jedis");
maxTotal = Integer.parseInt(bundle.getString("redis.maxTotal"));
maxIdel = Integer.parseInt(bundle.getString("redis.maxIdel"));
host = bundle.getString("redis.host");
port = Integer.parseInt(bundle.getString("redis.port"));
//Jedis连接池配置
JedisPoolConfig jpc = new JedisPoolConfig();
jpc.setMaxTotal(maxTotal);
jpc.setMaxIdle(maxIdel);
jp = new JedisPool(jpc,host,port);
}
public static Jedis getJedis(){
return jp.getResource();
}
}
JedisTest
package com.blabla.test;
import com.blabla.util.JedisUtil;
import redis.clients.jedis.Jedis;
public class JedisTest {
public static void main(String[] args) {
Jedis jedis = JedisUtil.getJedis();
jedis.set("ray","测试");
System.out.println(jedis.get("ray"));
}
}
集成到springboot项目
项目结构
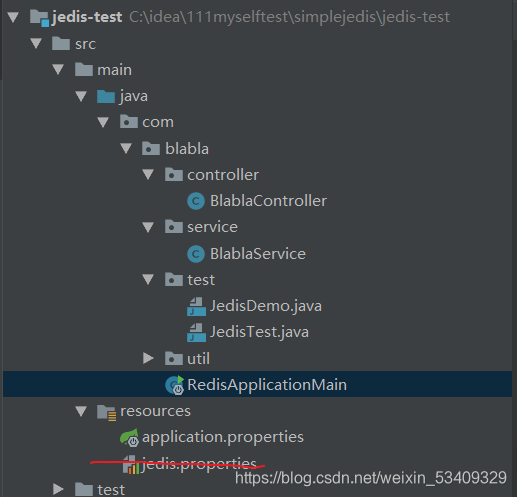
配置文件
spring.redis.jedis.pool.max-wait = 5000ms
spring.redis.jedis.pool.max-Idle = 100
spring.redis.jedis.pool.min-Idle = 10
spring.redis.timeout = 10s
spring.redis.host= 127.0.0.1
spring.redis.port= 6379
启动类
package com.blabla;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RedisApplicationMain {
public static void main(String[] args) {
SpringApplication.run(RedisApplicationMain.class,args);
}
}
controller
package com.blabla.controller;
import com.blabla.service.BlablaService;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class BlablaController {
@Resource
private BlablaService blablaService;
@GetMapping("/redis")
public String redisTest(){
return blablaService.getRedis();
}
}
service
package com.blabla.service;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import javax.annotation.Resource;
@Service
public class BlablaService {
// 注入redis类
@Resource
private RedisTemplate<String,String> redisTemplate;
// http请求类
// @Resource
// private RestTemplate restTemplate;
public String getRedis(){
redisTemplate.opsForValue().set("test01","test");
String test01 = redisTemplate.opsForValue().get("test01");
return test01;
}
public String httpTest(){
return "123";
}
}
注意:Springboot整合Redis需要指定是否序列化key value 否则会出现新增key时key的前边出现序列化的字符串导致出现问题;
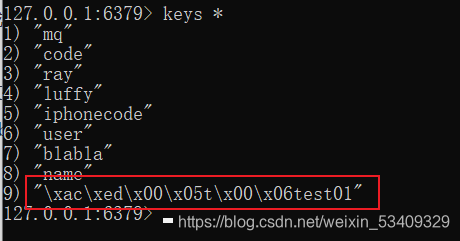
redis持久化
aof持久化
- 手动执行save命令,同步操作,会阻塞其他操作命令执行(不推荐)
- 手动执行bgsave命令,会fork一个子进程,在子进程中完成数据持久化动作,不会阻塞其他操作命令(非自动化)
- 通过配置,自动完成rdb持久化,底层是bgsave操作(建议方案)
# 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
# 这里表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改
# 如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数也可以
# 更改次数,指的是成功增、删、改
save 900 1
save 300 100
save 60 1000
# 对于存储到磁盘中的快照(rdb),可以设置是否进行压缩存储。如果是的话,redis会采用
# LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能
rdbcompression yes
# 在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约
# 10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdbchecksum yes
# dbfilename文件存放目录。必须是一个目录,aof文件也会保存到该目录下。
dir ./
#rdb文件的名字。
dbfilename dump.rdb
rdb持久化
# 是否启用aof持久化方式 。否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。
# 因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
# 指定更新日志(aof)文件名,默认为appendonly.aof
appendfilename "appendonly.aof"
#指定更新日志条件,共有3个可选值:
# no:表示等操作系统进行数据缓存同步到磁盘(快,持久化没保证)
# always:同步持久化,每次发生数据变更时,立即记录到磁盘(慢,安全)
# everysec:表示每秒同步一次(默认值,很快,但可能会丢失一秒以内的数据)
# appendfsync always
appendfsync everysec
# appendfsync no
# 指定是否在后台aof文件rewrite期间调用fsync,默认为no,表示要调用fsync(无论后台是否有子进程在刷盘)。
# Redis在后台写RDB文件或重写AOF文件期间会存在大量磁盘IO,此时,在某些linux系统中,调用fsync可能会阻塞。
#如果应用系统无法忍受延迟,而可以容忍少量的数据丢失,则设置为yes。如果应用系统无法忍受数据丢失,则设置为no。
no-appendfsync-on-rewrite no
#当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写 。当AOF文件大小的增长率大于该配置项时自动开启重写。
auto-aof-rewrite-percentage 100
#当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写 。当AOF文件大小大于该配置项时自动开启重写
auto-aof-rewrite-min-size 64mb
区别
redis支持两种持久化操作,分别是rdb和aof
rdb是以快照的方式保存某个时间点的真实数据;aof是以日志的方式保存整个操作过程中的所有操作命令。
注意:以上两种持久化方案没有好坏之分, 他们在实际开发中是一个互补的方案
rdb:数据体量少,保存效率高,但是因为是某个时间点的数据,会存在数据丢失的风险
aof:记录每个操作,数据体量大,保存效率弱于rdb,但是可以最大程度保证数据的完整性

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









