



简单使用Vanna
1 安装依赖环境
⚠️ 表结构等信息,请参考见“https://blog.youkuaiyun.com/make_progress/article/details/151905155”
安装依赖
pip install vanna
pip install PyMySQL
pip install cryptography
pip install vanna[chromadb,openai,bigquery]
2 构建模型
2.1 自定义CustomVanna
from abc import ABC
from openai import OpenAI
from vanna.base import VannaBase
from vanna.chromadb import ChromaDB_VectorStore
class CustomLLM(VannaBase, ABC):
"""
自定义虚拟基类大模型
"""
def __init__(self, config=None):
# 调用超类
super().__init__(config)
if config is None:
raise ValueError(
"For LLM, config must be provided with an api_key and model"
)
if "base_url" not in config:
raise ValueError("config must contain a LLM base_url")
if "api_key" not in config:
raise ValueError("config must contain a LLM api_key")
if "model" not in config:
raise ValueError("config must contain a LLM model")
# 模型基本信息
base_url = config["base_url"]
api_key = config["api_key"]
model = config["model"]
# 构建客户端
self.client = OpenAI(base_url=base_url, api_key=api_key)
self.model = model
def system_message(self, message: str) -> any:
return {"role": "system", "content": message}
def user_message(self, message: str) -> any:
return {"role": "user", "content": message}
def assistant_message(self, message: str) -> any:
return {"role": "assistant", "content": message}
def generate_sql(self, question: str, **kwargs) -> str:
# 调用超类生成sql
sql = super().generate_sql(question, **kwargs)
# 用 "_" 替换 "\_"
sql = sql.replace("\\_", "_")
return sql
def submit_prompt(self, prompt, **kwargs) -> str:
chat_response = self.client.chat.completions.create(
model=self.model,
messages=prompt,
)
return chat_response.choices[0].message.content
# 继承虚拟基类
class CustomVanna(ChromaDB_VectorStore, CustomLLM):
def __init__(self, config=None):
# 注意会使用向量,模型默认是 all-MiniLM-L6-v2
ChromaDB_VectorStore.__init__(self, config=config)
CustomLLM.__init__(self, config=config)
# 构建自定义Vanna
vn = CustomVanna(config={
"base_url": "https://api.moonshot.cn/v1",
"api_key": "XXXX",
"model": "kimi-k2-0905-preview"
})
2.2 使用自定义的Vanna
from vanna.flask import VannaFlaskApp
from my.custom_vanna import vn
# 1 连接MySQL数据库
vn.connect_to_mysql(host="192.168.108.147", port=3306, dbname="company_salary", user="root",password="123456")
# 2 训练数据
"""
# 此注释的内容可以不要
# 获取数据的属性信息
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# 把信息模式分解为LLM可以引用的小块
plan = vn.get_training_plan_generic(df_information_schema)
vn.train(plan=plan)
"""
# 添加表结构schema
vn.train(ddl="""
CREATE TABLE salary_records (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键自增ID',
employee_id VARCHAR(10) NOT NULL COMMENT '员工编号唯一标识员工',
name VARCHAR(50) NOT NULL COMMENT '员工姓名',
department VARCHAR(50) COMMENT '所属部门如技术部、人事部等',
position VARCHAR(50) COMMENT '职位名称',
base_salary DECIMAL(10,2) DEFAULT 0.00 COMMENT '基本工资税前基础薪资',
bonus DECIMAL(10,2) DEFAULT 0.00 COMMENT '奖金、绩效或项目奖励',
deductions DECIMAL(10,2) DEFAULT 0.00 COMMENT '扣款含社保、公积金、个税等',
net_salary DECIMAL(10,2) AS (base_salary + bonus - deductions) STORED COMMENT '实发工资自动计算字段',
pay_date DATE COMMENT '发薪日期通常为每月固定日期',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工工资记录表存储每位员工的月度工资明细'
""")
# 训练数据说明
vn.train(documentation="数据中包括员工名称、部门名称、职位名称、基本工资等信息")
vn.train(documentation="统计员工的基本工资、奖金等")
# 将示例SQL查询添加到训练数据中,越多越好
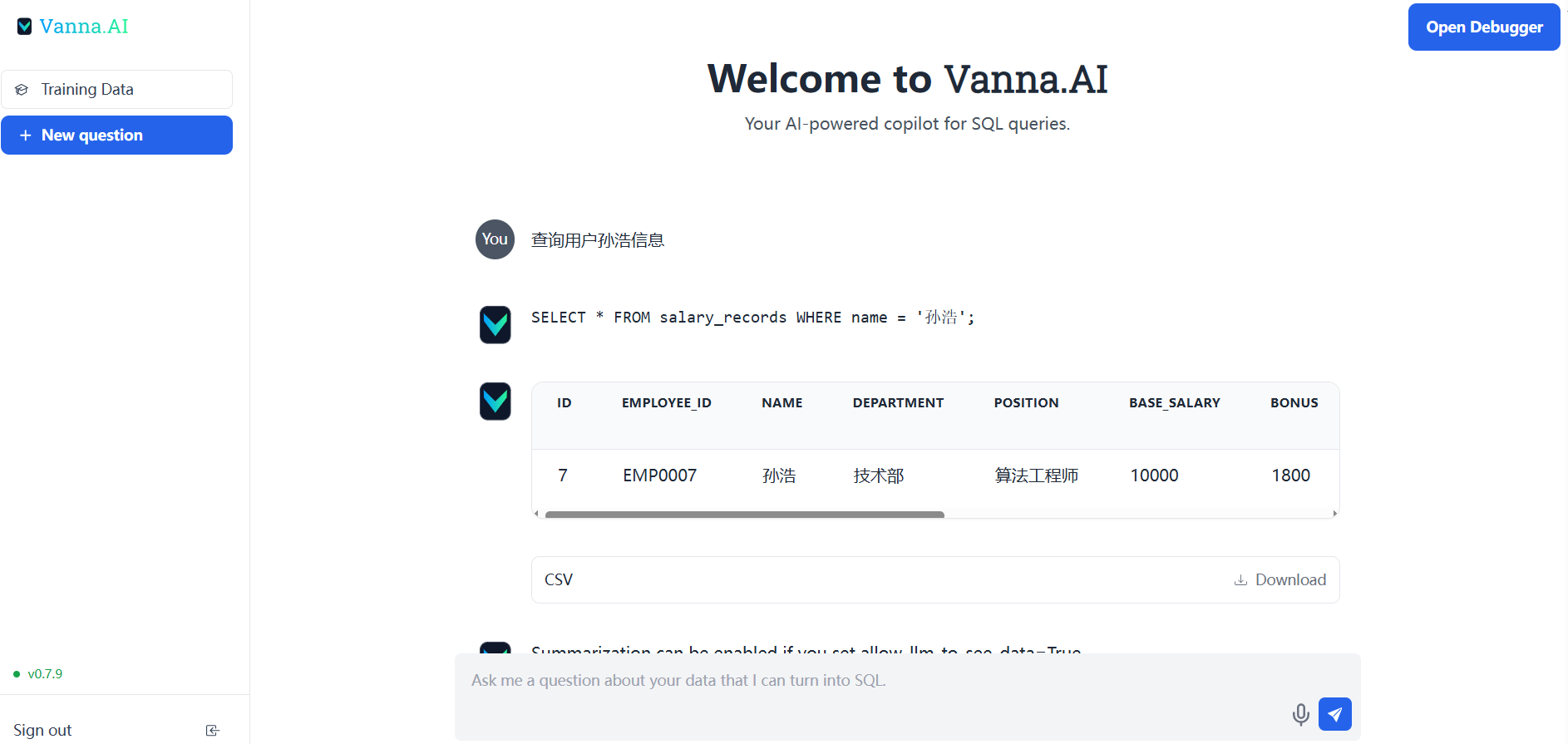
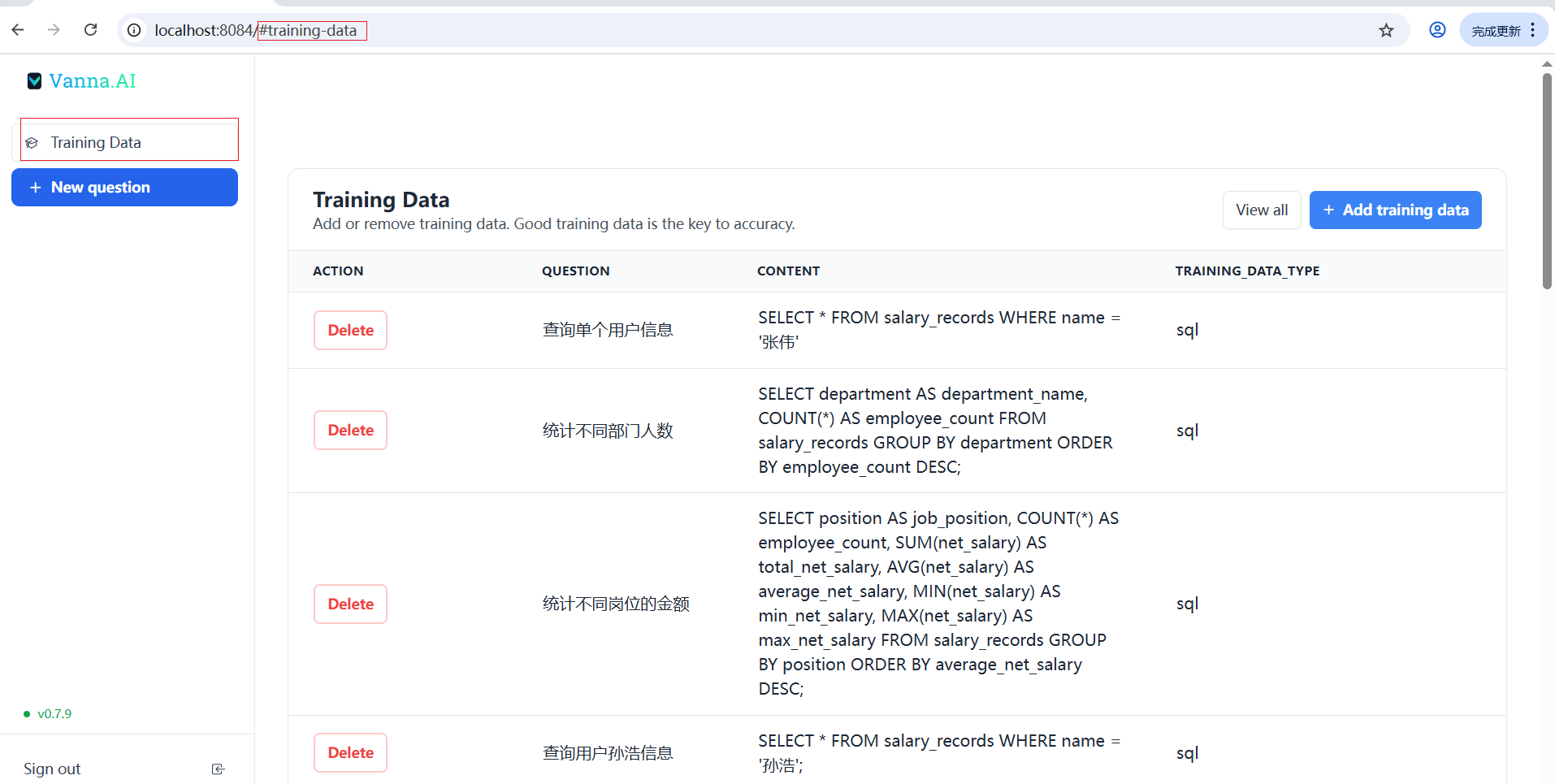
vn.train(question="查询单个用户信息", sql="SELECT * FROM salary_records WHERE name = '张伟'")
vn.train(question="统计不同部门人数", sql="SELECT department AS department_name, COUNT(*) AS employee_count FROM salary_records GROUP BY department ORDER BY employee_count DESC;")
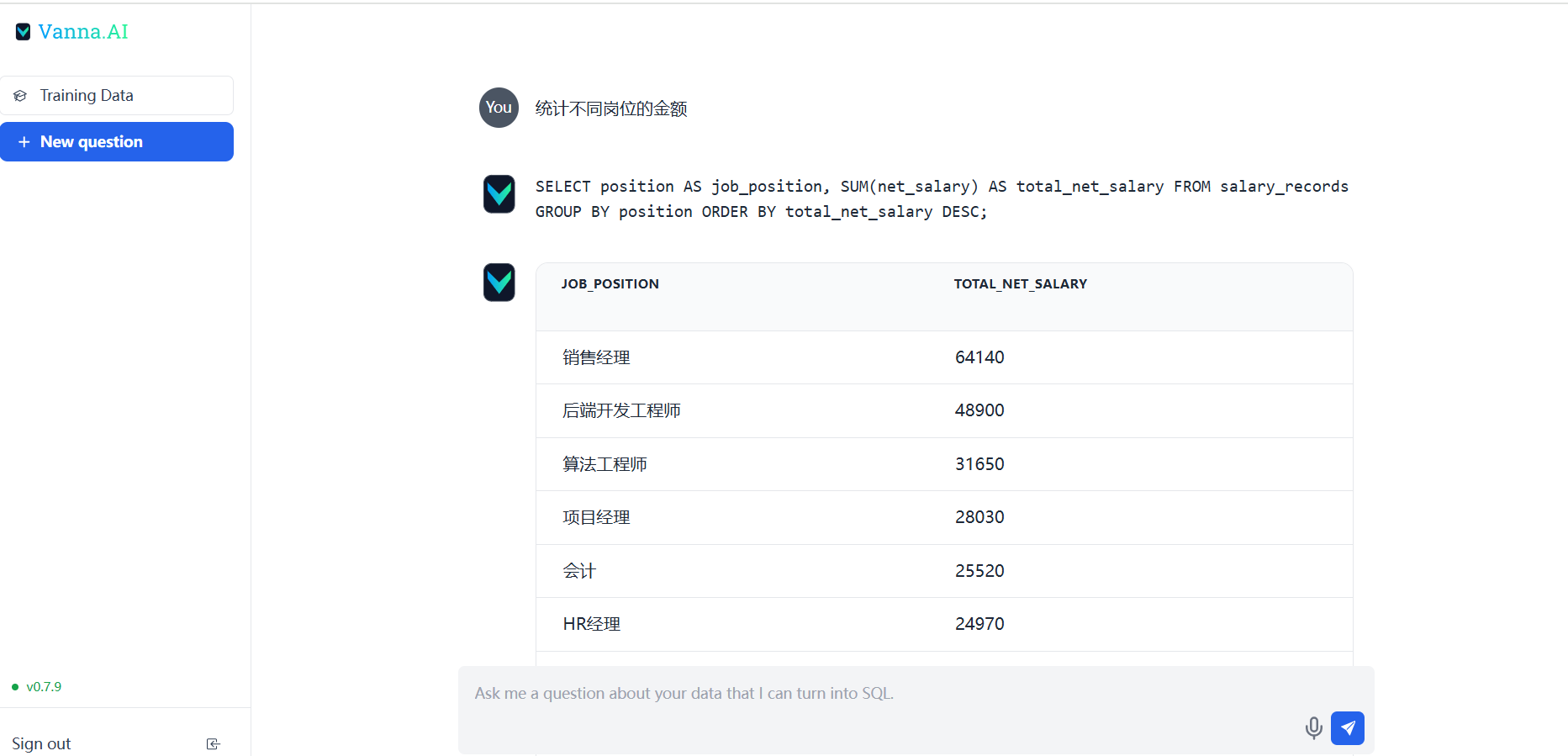
vn.train(question="统计不同岗位的金额", sql="SELECT position AS job_position, COUNT(*) AS employee_count, SUM(net_salary) AS total_net_salary, AVG(net_salary) AS average_net_salary, MIN(net_salary) AS min_net_salary, MAX(net_salary) AS max_net_salary FROM salary_records GROUP BY position ORDER BY average_net_salary DESC;")
# 调用问题,visualize=True会使用的token数量
data = vn.ask(question="查询单个用户信息", visualize=False)
# 返回的数据信息是个元组
print(data)
# 用于启动可视化页面,根据自己的情况可以不要
VannaFlaskApp(vn).run()
3 使用截图
⚠️ 有的时候加载不出来下面的页面,关闭网络,再重新打开,就可以了。
(1)简单使用
查询用户孙浩信息
统计不同岗位的金额
(2)查看Training Data

















 3047
3047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









