



智能体长记忆解决方案Mem0和Memobase
1 简单介绍
为解决智能体的长记忆问题,有很多开源的方案,具有代表性的有Mem0、MemoryOS、Memobase、cognee等。
Mem0是嵌入式项目,特长多Agent记忆管理,适用于快速集成、短期记忆、开发资源有限的环境;
Memobase是非嵌入式(需要构建独立的服务),特长单用户记忆管理,适用于长期画像、结构化记忆、企业级扩展;
Mem0是专为现代 AI 智能体设计的记忆层。它作为一个持久化的记忆层,使智能体能够:回忆相关的过往交互 、存储重要的用户偏好和事实性上下文 、从成功与失败中学习等,它赋予 AI 智能体记忆能力,使其能够在多次交互中记住信息、持续学习并不断进化。它适配的组件较多。
# Github地址
https://github.com/mem0ai/mem0
# 文档地址
https://docs.mem0.ai/introduction
# Python客户端
https://docs.mem0.ai/open-source/python-quickstart
# 官网地址
https://mem0.ai/
Memobase 是一个基于用户画像的记忆系统,旨在为您的大语言模型(LLM)应用提供长期的用户记忆能力。无论您是在构建虚拟伴侣、教育工具,还是个性化助手,Memobase 都能让您的 AI 记住用户、理解用户,并随着用户共同成长。
# Github地址
https://github.com/memodb-io/memobase
# 文档地址
https://docs.memobase.io/introduction
# 官网地址
https://www.memobase.io/
MemoryOS是一个用于个性化 AI 代理的记忆操作系统,能够实现更连贯、更个性化且更具上下文感知能力的交互。它采用分层存储架构,包含存储、更新、检索和生成四个核心模块,以实现全面且高效的记忆管理。
# Github地址
https://github.com/BAI-LAB/MemoryOS
# 地址
https://bai-lab.github.io/MemoryOS/docs
# 官网
https://baijia.online/memoryos/
Cognee会将您的数据组织成 AI 记忆,它会创建一个包含原始信息、提取出的概念以及有意义关系的知识图谱,供您进行查询。为智能体构建动态记忆,利用可扩展、模块化的 ECL(提取、认知、加载)管道,取代传统的 RAG(检索增强生成)。
# Github地址
https://github.com/topoteretes/cognee
# 开发文档
https://docs.cognee.ai/getting-started/introduction
2 Mem0简单使用
2.1 Docker安装向量数据库
docker run -itd \
--name qdrant \
--restart always \
-p 6333:6333 \
-p 6334:6334 \
-v /home/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant:v1.15.5
2.2 Python使用Mem0
# 安装依赖包
pip install mem0ai
Python代码
from mem0 import Memory
from openai import OpenAI
# 配置向量库
config = {
"vector_store": {
"provider": "qdrant",
"config": {
# 集合名称
"collection_name": "test",
# qdrant的地址
"host": "192.168.108.147",
# 端口号
"port": 6333,
# 设置向量维度,注意与本地模型同步
"embedding_model_dims": 1024
}
},
# 配置大模型
"llm": {
"provider": "openai",
"config": {
# 类OpenAI的大模型地址
"openai_base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"api_key": "sk-XXXX",
# 大模型名称
"model": "qwen-plus",
"temperature": 0.3,
"max_tokens": 2000
}
},
# 配置嵌入模型
"embedder": {
"provider": "openai",
"config": {
# 类OpenAI的嵌入地址
"openai_base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"api_key": "sk-XXXX",
# 嵌入模型名称
"model": "text-embedding-v4",
# 生成文本的维度
"embedding_dims": 1024
}
}
}
# 加载配置
memory = Memory.from_config(config)
# 2 添加记忆
messages = [
{
"role": "user",
"content": "I like to drink coffee in the morning and go for a walk"
}
]
# 用户编号
user_id = "mason"
result = memory.add(messages, user_id=user_id, metadata={"category": "preferences"})
print("result", result)
# 历史记忆
history = memory.history(memory_id="c0cd9919-54e3-4127-b657-7cdb7bb096f1")
# 3 查询记忆
related_memories = memory.search("Should I drink coffee or tea?", user_id="mason")
print("related_memories", related_memories)
# 4 使用memory
openai_client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-XXXX"
)
# 查询记忆
message = "tea"
relevant_memories = memory.search(query=message, user_id=user_id, limit=3)
# 封装记忆
memories_history = "\n".join(f"- {entry['memory']}" for entry in relevant_memories["results"])
# 设置模型的提示词
system_prompt = f"You are a helpful AI. Answer the question based on query and memories.\nUser Memories:\n{memories_history}"
messages = [{"role": "system", "content": system_prompt}, {"role": "user", "content": message}]
# 设置生成结果
response = openai_client.chat.completions.create(model="qwen-plus", messages=messages)
assistant_response = response.choices[0].message.content
print("assistant_response", assistant_response)
# 追加新的记忆
messages.append({"role": "assistant", "content": assistant_response})
memory.add(messages, user_id=user_id)
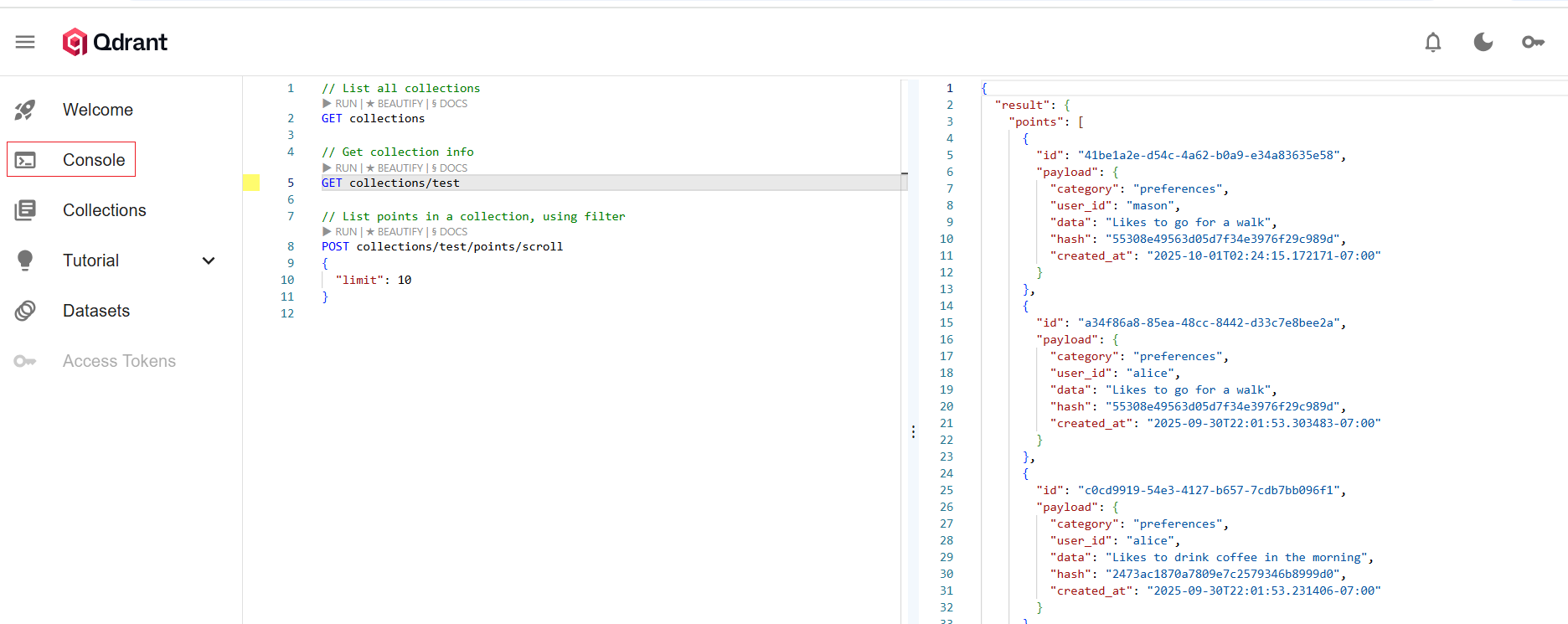
2.3 执行结果
(1)代码执行

(2)Qdrant数据
3 Memobase简单使用
3.1 Docker安装Memobase服务器
⚠️ 可以使用官网的docker-compose直接安装,为了更好控制容器,此处分开安装。
(1)下载镜像
# 下载镜像,下载速度比较慢
docker pull ghcr.io/memodb-io/memobase:0.0.40
# 下载pgvector
docker pull pgvector/pgvector:pg17
# 下载redis
docker pull redis:7.4
(2)创建容器
网桥
# 创建网桥
sudo docker network create --driver bridge memobase-bridge
pgvector
# 创建向量库pgvector
docker run -itd \
--name memobase-server-db \
--network memobase-bridge \
--restart always \
-e POSTGRES_USER=root \
-e POSTGRES_PASSWORD=123456 \
-e POSTGRES_DB=memobase \
-p 5432:5432 \
-v /home/memobase/pgvector/data:/var/lib/postgresql/data \
pgvector/pgvector:pg17
redis
# 创建缓存库redis
docker run -itd \
--name memobase-server-redis \
--network memobase-bridge \
--restart always \
-p 6379:6379 \
-v /home/memobase/redis/data:/var/lib/postgresql/data \
redis:7.4 redis-server --requirepass 123456
Memobase
# 创建Memobase接口服务
# 注意:memobase是数据库
# memobase-server-db是数据库的容器名称
# memobase-server-redis是redis的容器名称
docker run -itd \
--name memobase-server-api \
--network memobase-bridge \
--restart always \
-e DATABASE_URL=postgresql://root:123456@memobase-server-db:5432/memobase \
-e REDIS_URL=redis://:123456@memobase-server-redis:6379/0 \
-e ACCESS_TOKEN=secret \
-e PROJECT_ID=memobase_dev \
-e API_HOSTS=http://0.0.0.0:8019 \
-e USE_CORS=false \
-p 8019:8000 \
-v /home/memobase/api/config.yaml:/app/config.yaml \
ghcr.io/memodb-io/memobase:0.0.40
配置文件:config.yaml
参数地址
https://docs.memobase.io/references/local_config#full-explanation-of-config-yaml
配置说明
# config.yaml
# 默认是OpenAI的地址,可以不设置
llm_base_url: OpenAI的地址
# 默认OpenAI的Key,必须设置,可以与上面的llm_base_url同步设置
llm_api_key: YOUR-OPENAI-KEY
# 设置模型名称,默认gpt-4o-mini
best_llm_model: 模型名称
# 如果使用lstudio提供embedded, 可参考下面配置
# embedding_provider: lmstudio
# embedding_api_key: lm_XXX
# embedding_model: text-embedding-qwen3-embedding-8b
# 如果使用地址访问嵌入模型,可参考下面配置
# embedding_base_url: http://127.0.0.1:1234/v1
# embedding_api_key: 嵌入模型的api-key
# embedding_model: 模型名称
# embedding_dim: 1024
# language: zh
配置示例(以阿里云大模型)
# config.yaml
# 默认是OpenAI的地址,可以不设置
llm_base_url: https://dashscope.aliyuncs.com/compatible-mode/v1
# 默认OpenAI的Key,必须设置,可以与上面的llm_base_url同步设置
llm_api_key: sk-xxxxx
# 设置模型名称,默认gpt-4o-mini
best_llm_model: qwen-plus
# 如果使用lstudio提供embedded, 可参考下面配置
# embedding_provider: lmstudio
# embedding_api_key: lm_XXX
# embedding_model: text-embedding-qwen3-embedding-8b
# 如果使用地址访问嵌入模型,可参考下面配置
embedding_base_url: https://dashscope.aliyuncs.com/compatible-mode/v1
embedding_api_key: sk-xxxxx
embedding_model: text-embedding-v4
embedding_dim: 1024
language: zh
3.2 Python使用Memobase
⚠️ Python版本要求:Python>=3.11
pip install memobase
简单示例
from openai import OpenAI
from memobase import MemoBaseClient, ChatBlob
# 1 连接服务器,设置客户端
client = MemoBaseClient(
# 服务器地址
project_url="http://192.168.108.147:8019",
# ACCESS_TOKEN=secret
api_key="secret"
)
print(client.ping())
# 2 添加用户信息
uid = client.add_user({"name": "Mason"})
# 可以用历史的用户编号查数据
# uid = "0c38e40e-89d0-4b5d-a423-526266abf48e"
print("uid", uid)
# 3 获取用户信息
user = client.get_user(uid)
print("user", user)
# 4 为用户添加记忆信息
message = ChatBlob(messages=[
{"role": "user", "content": "Hi, I'm here again"},
{"role": "assistant", "content": "Hi, Mason! How can I help you?"}
])
bid = user.insert(message)
print("bid", bid)
# 5 将用户画像存储人库中
# 更新缓冲区的过程比较慢,可以注释掉
# 如果不刷新缓冲区,不会显示user.profile,也不能搜索记忆消息
# 默认情况,缓冲区数据太多(例如:1024 tokens),或者持续空闲很久(例如:1个小时),系统会自动将缓冲更新到库中
# 设置等待缓冲区执行
user.flush(sync=True)
# 打印用户画像
print(user.profile(need_json=True))
# 6 搜索记忆消息数据
# 语义查询
events = user.search_event("you")
print(events)
# 要点查询
events = user.search_event_gist("you")
print(events)
# 7 获取context
context = user.context()
# 8 使用context应用到对话中
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-XXXX"
)
SYSTEM_PROMPT = f"""You're a helpful assistant.
Your job is to ...
Below is the user's memory:
{context}"""
# 获取值
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": "Who'am I?s"}
]
)
print(response.choices[0].message.content)
3.3 执行结果
查看服务日志
docker logs -f memobase-server-api
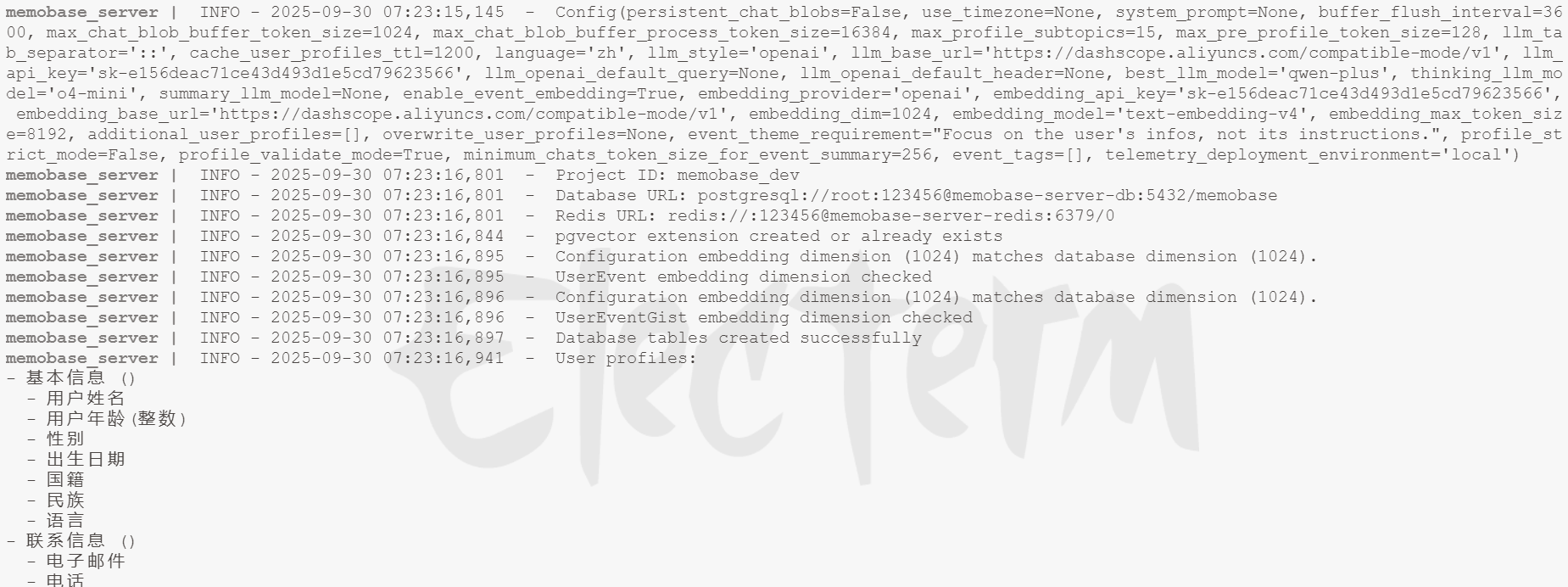
Python执行结果

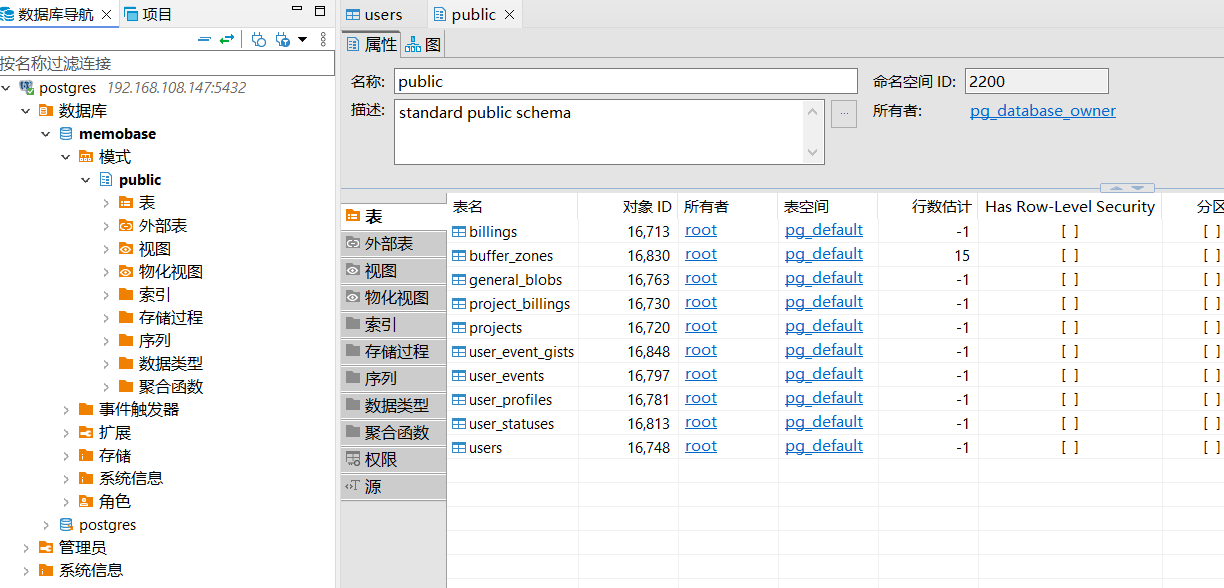
数据库信息
使用DBeaver打开向量数据库


















 4485
4485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









