



简单使用LangExtract
⚠️ 请关注公众号“朋蛋”
1 简介
LangExtract是一个Python库,利用大型语言模型(LLM)根据用户定义的指令从非结构化文本文档中提取结构化信息。它能处理临床记录或报告等材料,识别并组织关键细节,同时确保提取的数据与原文内容一致。
注意:LangExtract提取数据时内部使用了线程,如果直接使用线程提取是不行的,只能使用进程提取。
https://github.com/google/langextract
发现有一个TinyDB项目很好用,可替代手写文件,TinyDB是一个轻量级的面向文档的数据库,可以替换文件存储。注意:TinyDB也是线程和进程不安全的。
# 官网地址
https://tinydb.readthedocs.io/en/latest/
# Github
https://github.com/msiemens/tinydb
2 代码
实现的Python代码
import langextract as lx
import textwrap
from langextract.core.data import AnnotatedDocument
from langextract.providers.openai import OpenAILanguageModel
def run_extract_info(input_text: str):
# 案例是提取“罗密欧和朱丽叶”的实体信息
# 1. 设置提示词
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.
""")
# 2. 提供样例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling": "gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type": "metaphor"}
)
]
)
]
# 3. 抽取数据
result: list[AnnotatedDocument] | AnnotatedDocument = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
fence_output=True,
use_schema_constraints=False,
# 添加自定义模型
# 使用下面的方式,可调用用vLLM的服务
model=OpenAILanguageModel(
# 设置自定义模型名称
model_id='llm-v1',
# 自定模型地址
base_url='http://192.168.43.139:8000/v1',
api_key='Empty',
# 设置自定义模型参数
provider_kwargs={
'connect_timeout': 60,
'timeout': 120
}
)
)
return result
def show_view(result):
# 判断数据类型
if not isinstance(result, list):
result = [result]
# 保存为JSON文件,iter函数是将列表转为迭代器
lx.io.save_annotated_documents(iter(result), output_name="extraction_results.jsonl", output_dir=".")
# 可视化生成的结果
html_content = lx.visualize("extraction_results.jsonl")
# 设置编码方式为GBK,避免乱码
with open("visualization.html", "w", encoding='GBK', errors='ignore') as f:
if hasattr(html_content, 'data'):
f.write(html_content.data)
else:
f.write(html_content)
if __name__ == '__main__':
# 输入抽取的数据
input_text_temp = "Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
result_tmp = run_extract_info(input_text_temp)
# 显示数据
show_view(result_tmp)
3 截图
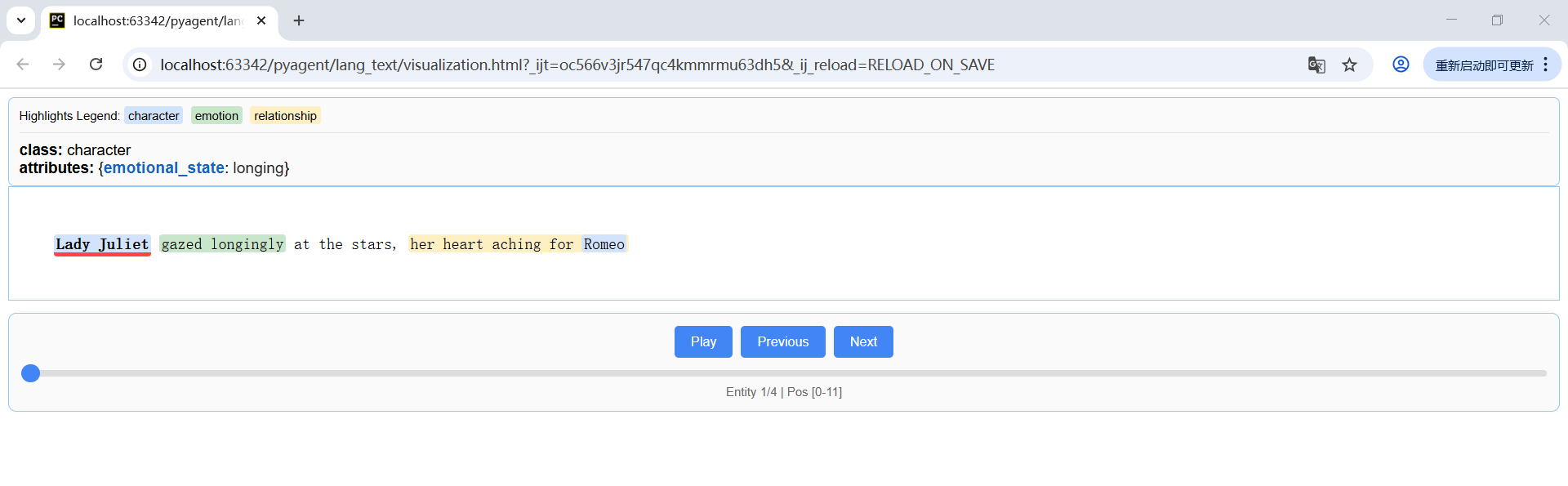
4 简单使用TinyDB
from tinydb import TinyDB, Query
db = TinyDB('db.json')
# 添加数据
db.insert({'type': 'peach', 'count': 3})
db.insert({'type': 'apple', 'count': 7})
# 查看全部数据
print(db.all())
# 查看全部数据
# for item in db.all():
for item in db:
print(item)
# 查找数据
Fruit = Query()
db.search(Fruit.type == 'peach')
# 更新数据
db.update({'count': 10}, Fruit.type == 'apple')
# 删除数据
db.remove(Fruit.count < 5)
# 清空数据
db.truncate()

















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









