




NL2SQL简单使用
1 简介
将自然语言转化为SQL或者叫Text转SQL可称为NL2SQL(Natural Language to SQL) 。NL2SQL的核心作用是降低数据库查询的技术门槛,让非技术用户能用日常语言直接获取数据。 它通过自动将自然语言问题转换为SQL查询,极大地提升数据访问和决策的效率。开源比较出名的NL2SQL框架有很多,例如:Chat2DB、Vanna、WrenAI、sqlchat等。
(1)Chat2DB
Chat2DB是国产的开源项目,可支持MySQL, PostgreSQL, H2, Oracle, SQLServer, SQLite, MariaDB, ClickHouse, DM, Presto, DB2, OceanBase, Hive, KingBase, MongoDB, Redis, Snowflake等数据库。优点是具有可视化页面,可快速搭建。不足之处是开源版本可以使用的功能较少,不过功能基本够用了。不太合适进行定制开发。它具有三个版本,开源版本和收费版本(2个)。Docker安装相对容易。
# Github地址
https://github.com/CodePhiliaX/Chat2DB
# 官网文档地址
https://chat2db-ai.com/resources/docs/start-guide/about-chat2db
(2)Vanna
Vanna是一个专为NL2SQL任务设计的Python RAG(Retrieval-Augmented Generation))框架,用于SQL生成和相关功能,它的核心作用是让开发者能够基于自己的数据库 schema 和业务上下文,快速、安全地训练和部署一个高度定制化且准确的文本转SQL生成应用。优点是方便定制化。
# Github地址
https://github.com/vanna-ai/vanna
# 官网文档地址
https://vanna.ai/docs/
(3)WrenAI
WrenAI是一个GenBI智能体,可以在几秒钟内使用自然语言查询数据库,获得准确的SQL(文本到SQL)、图表(文本到图表)和AI生成的深度洞察。支持的数据库有Athena (Trino)、Redshift、BigQuery、DuckDB、PostgreSQL、MySQL、Microsoft SQL Server、ClickHouse、Oracle、Trino、Snowflake。优点是具有可视化页面。也具有三个版本。开源版本和收费版本(2个)。使用Docker安装的组件比较多,不太好安装,放弃。
# Github地址
https://github.com/Canner/WrenAI
# 官网文档地址
https://docs.getwren.ai/oss/overview/introduction
(4)sqlchat
Sqlchat很久没更新了。
# Github地址
https://github.com/sqlchat/sqlchat
2 创建数据库
2.1 创建MySQL容器
docker run -itd \
-p 3306:3306 \
-v /home/mysql/conf:/etc/mysql/conf.d \
-v /home/mysql/data:/var/lib/mysql \
-v /home/mysql/log:/var/log/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysqldb \
mysql:8.0.29
⚠️ 连接出错“Public Key Retrieval is not allowed”的解决方法,设置“allowPublicKeyRetrieval”为true。
使用工具连接时
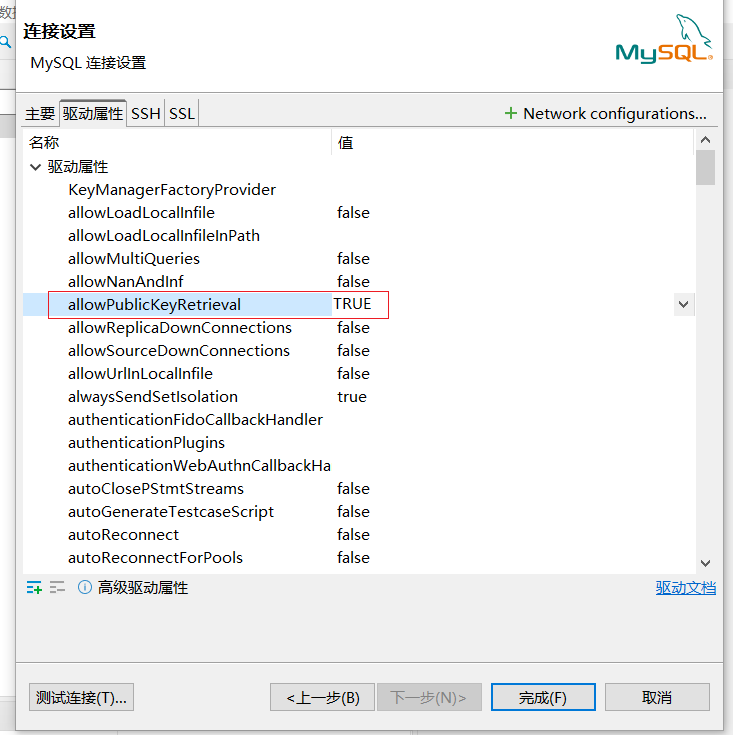
使用代码连接时
jdbc:mysql://localhost:3306/your_database?allowPublicKeyRetrieval=true
2.2 创建表结构
-- 创建数据库
CREATE DATABASE IF NOT EXISTS company_salary CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 使用数据库
USE company_salary;
-- 工资表
CREATE TABLE salary_records (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键,自增ID',
employee_id VARCHAR(10) NOT NULL COMMENT '员工编号,唯一标识员工',
name VARCHAR(50) NOT NULL COMMENT '员工姓名',
department VARCHAR(50) COMMENT '所属部门,如技术部、人事部等',
position VARCHAR(50) COMMENT '职位名称',
base_salary DECIMAL(10,2) DEFAULT 0.00 COMMENT '基本工资,税前基础薪资',
bonus DECIMAL(10,2) DEFAULT 0.00 COMMENT '奖金,绩效或项目奖励',
deductions DECIMAL(10,2) DEFAULT 0.00 COMMENT '扣款,含社保、公积金、个税等',
net_salary DECIMAL(10,2) AS (base_salary + bonus - deductions) STORED COMMENT '实发工资,自动计算字段',
pay_date DATE COMMENT '发薪日期,通常为每月固定日期',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工工资记录表,存储每位员工的月度工资明细';
2.3 添加数据
-- 选择数据库
USE company_salary;
-- 添加数据库
INSERT INTO salary_records
(employee_id, name, department, position, base_salary, bonus, deductions, pay_date) VALUES
('EMP0001', '张伟', '技术部', '前端开发工程师', 8500.00, 1200.00, 950.00, '2025-08-05'),
('EMP0002', '李娜', '技术部', '前端开发工程师', 6000.00, 800.00, 700.00, '2025-08-05'),
('EMP0003', '王强', '技术部', '前端开发工程师', 9500.00, 1500.00, 1100.00, '2025-08-05'),
('EMP0004', '陈静', '技术部', '算法工程师', 7000.00, 900.00, 800.00, '2025-08-05'),
('EMP0005', '刘洋', '技术部', '算法工程师', 5500.00, 2000.00, 600.00, '2025-08-05'),
('EMP0006', '赵敏', '技术部', '算法工程师', 6800.00, 1100.00, 750.00, '2025-08-05'),
('EMP0007', '孙浩', '技术部', '算法工程师', 10000.00, 1800.00, 1300.00, '2025-08-05'),
('EMP0008', '周琳', '销售部', '销售经理', 7500.00, 1000.00, 850.00, '2025-08-05'),
('EMP0009', '吴磊', '销售部', '销售经理', 8000.00, 2500.00, 1000.00, '2025-08-05'),
('EMP0010', '徐婷', '销售部', '销售经理', 9000.00, 1300.00, 950.00, '2025-08-05'),
('EMP0011', '黄峰', '销售部', '销售经理', 7500.00, 900.00, 780.00, '2025-08-05'),
('EMP0012', '何娟', '销售部', '销售经理', 8200.00, 1100.00, 880.00, '2025-08-05'),
('EMP0013', '马超', '销售部', '销售经理', 8800.00, 3000.00, 1100.00, '2025-08-05'),
('EMP0014', '高翔', '销售部', '销售经理', 10500.00, 1600.00, 1200.00, '2025-08-05'),
('EMP0015', '林雪', '技术部', '后端开发工程师', 7800.00, 1300.00, 820.00, '2025-08-05'),
('EMP0016', '邓杰', '技术部', '后端开发工程师', 6200.00, 950.00, 680.00, '2025-08-05'),
('EMP0017', '罗丹', '技术部', '后端开发工程师', 9500.00, 1800.00, 980.00, '2025-08-05'),
('EMP0018', '谢鹏', '技术部', '后端开发工程师', 9200.00, 1400.00, 1020.00, '2025-08-05'),
('EMP0019', '宋佳', '技术部', '后端开发工程师', 5800.00, 700.00, 600.00, '2025-08-05'),
('EMP0020', '程明', '技术部', '后端开发工程师', 8000.00, 1200.00, 850.00, '2025-08-05'),
('EMP0021', '朱莉', '市场部', '项目经理', 6500.00, 1000.00, 720.00, '2025-08-05'),
('EMP0022', '韩磊', '市场部', '项目经理', 8300.00, 1100.00, 900.00, '2025-08-05'),
('EMP0023', '唐敏', '市场部', '项目经理', 5900.00, 750.00, 680.00, '2025-08-05'),
('EMP0024', '冯伟', '市场部', '项目经理', 5600.00, 1800.00, 620.00, '2025-08-05'),
('EMP0025', '许静', '人事部', 'HR经理', 8800.00, 1400.00, 930.00, '2025-08-05'),
('EMP0026', '丁浩', '人事部', 'HR经理', 15000.00, 2500.00, 1800.00, '2025-08-05'),
('EMP0027', '江雪', '财务部', '会计', 7100.00, 920.00, 790.00, '2025-08-05'),
('EMP0028', '白洋', '财务部', '会计', 6000.00, 880.00, 660.00, '2025-08-05'),
('EMP0029', '夏婷', '财务部', '会计', 6300.00, 950.00, 700.00, '2025-08-05'),
('EMP0030', '尹杰', '财务部', '会计', 5500.00, 600.00, 580.00, '2025-08-05');
2.4 数据结果
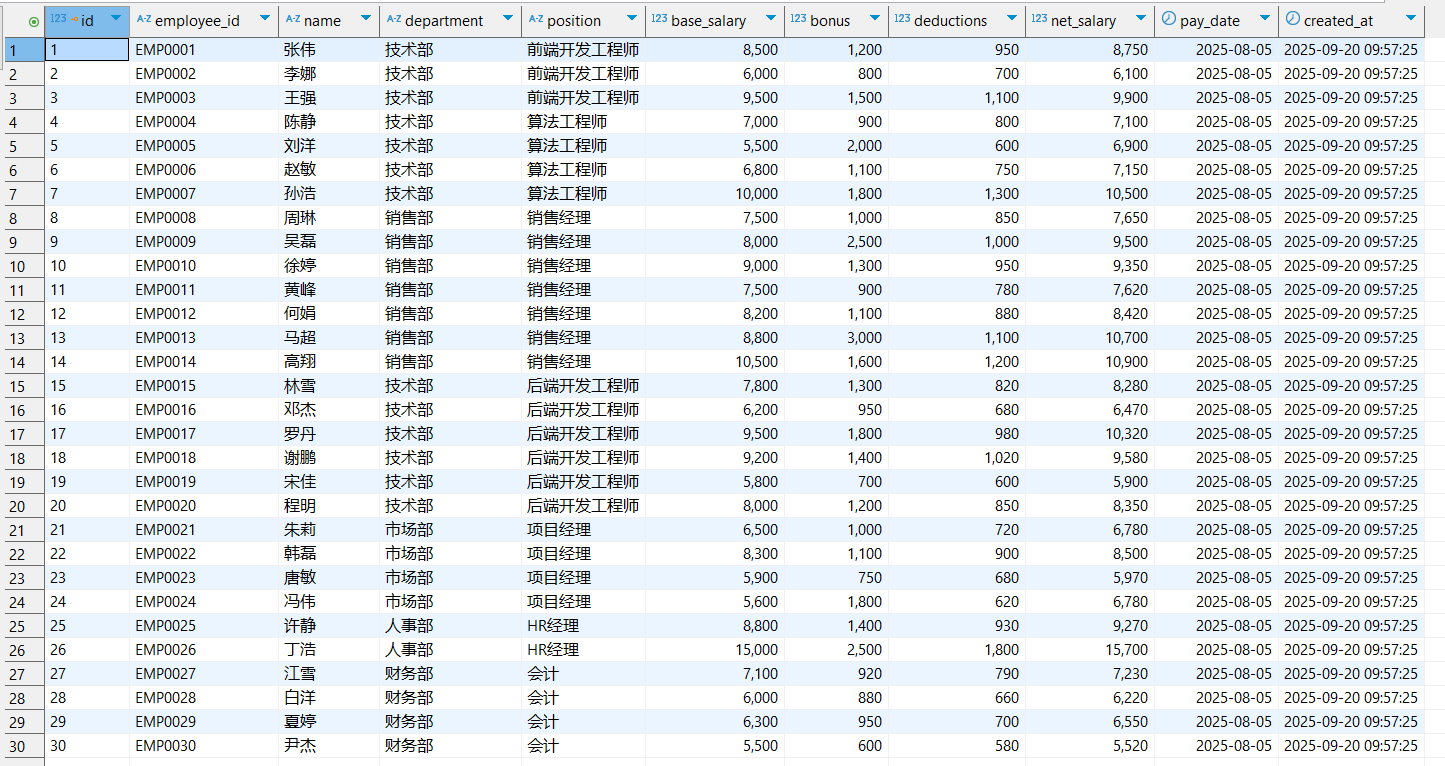
3 Chat2DB简单使用
3.1 安装容器
使用Docker安装软件系统。
docker run -itd \
--name=chat2db \
-p 10824:10824 \
-v /home/chat2db:/root/.chat2db \
chat2db/chat2db:0.3.7
3.2 简单使用
访问服务地址(192.168.108.147是我的服务器地址)
http://192.168.108.147:10824/
登录Chat2DB
默认的账号和密码都是:chat2db
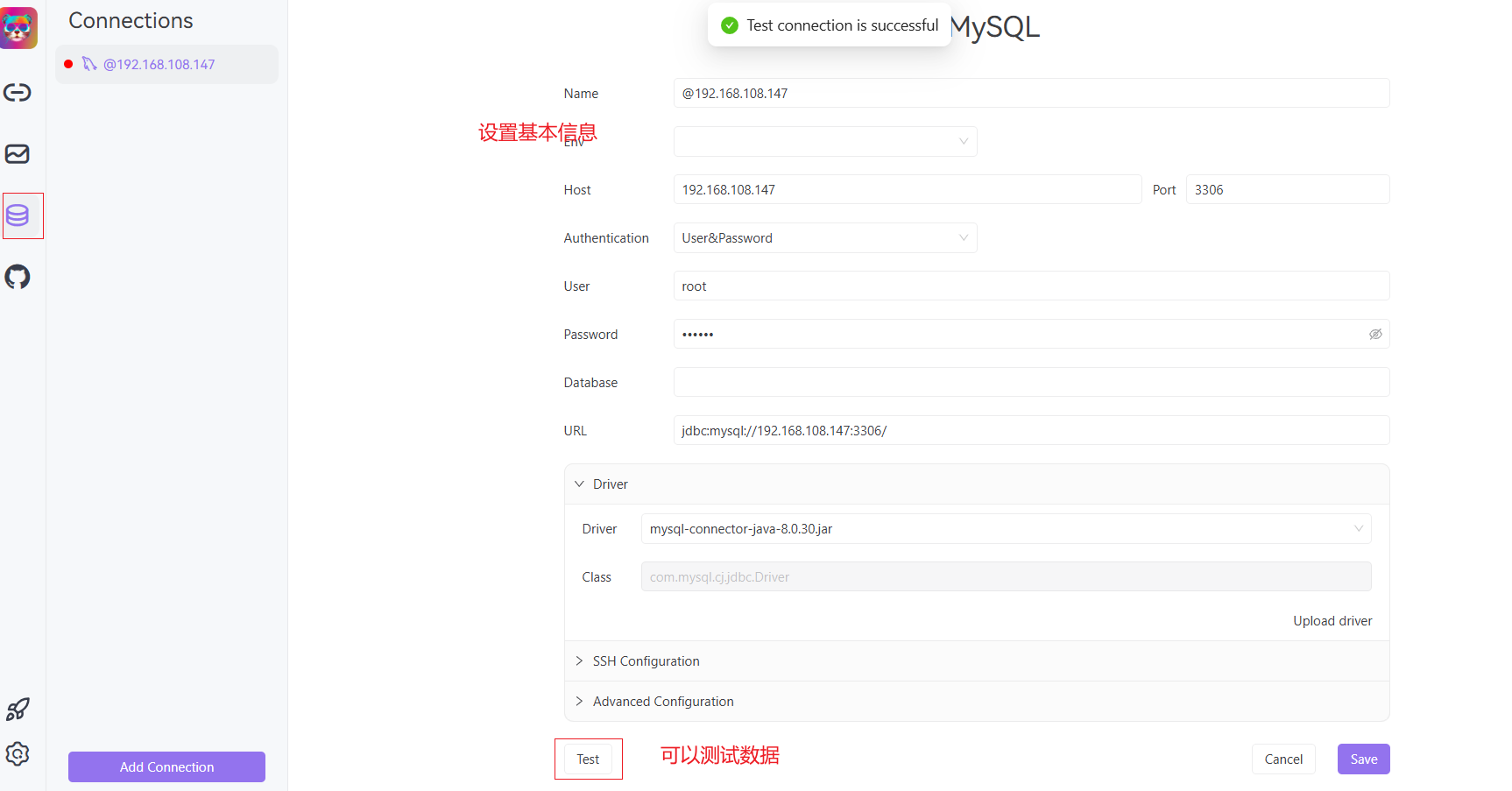
设置连接数据库的基本信息
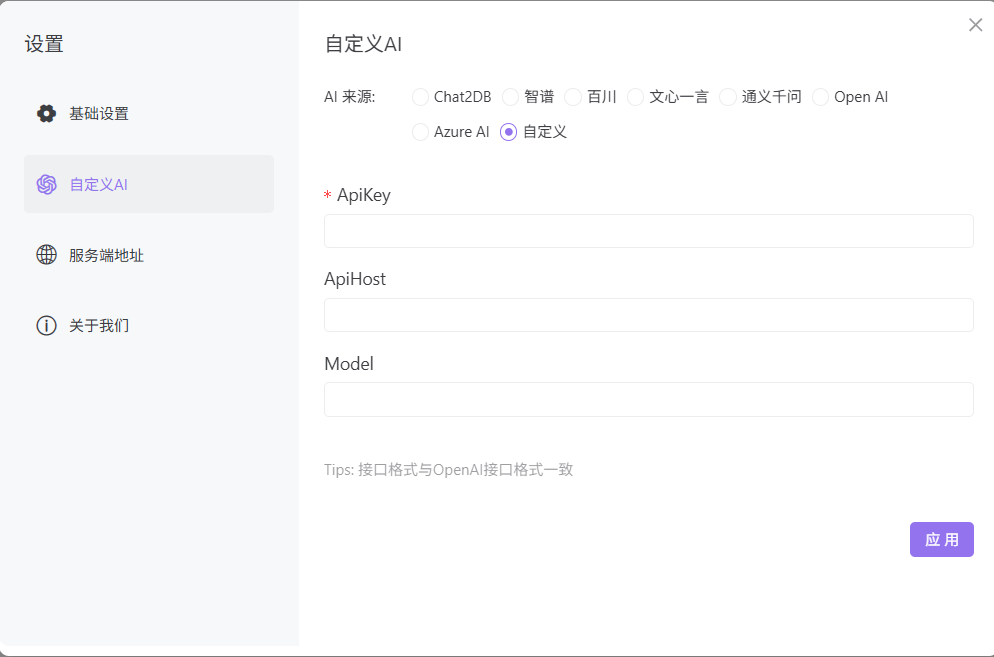
设置大模型信息
(Text2sql.assets/image-20250920195914192.png)
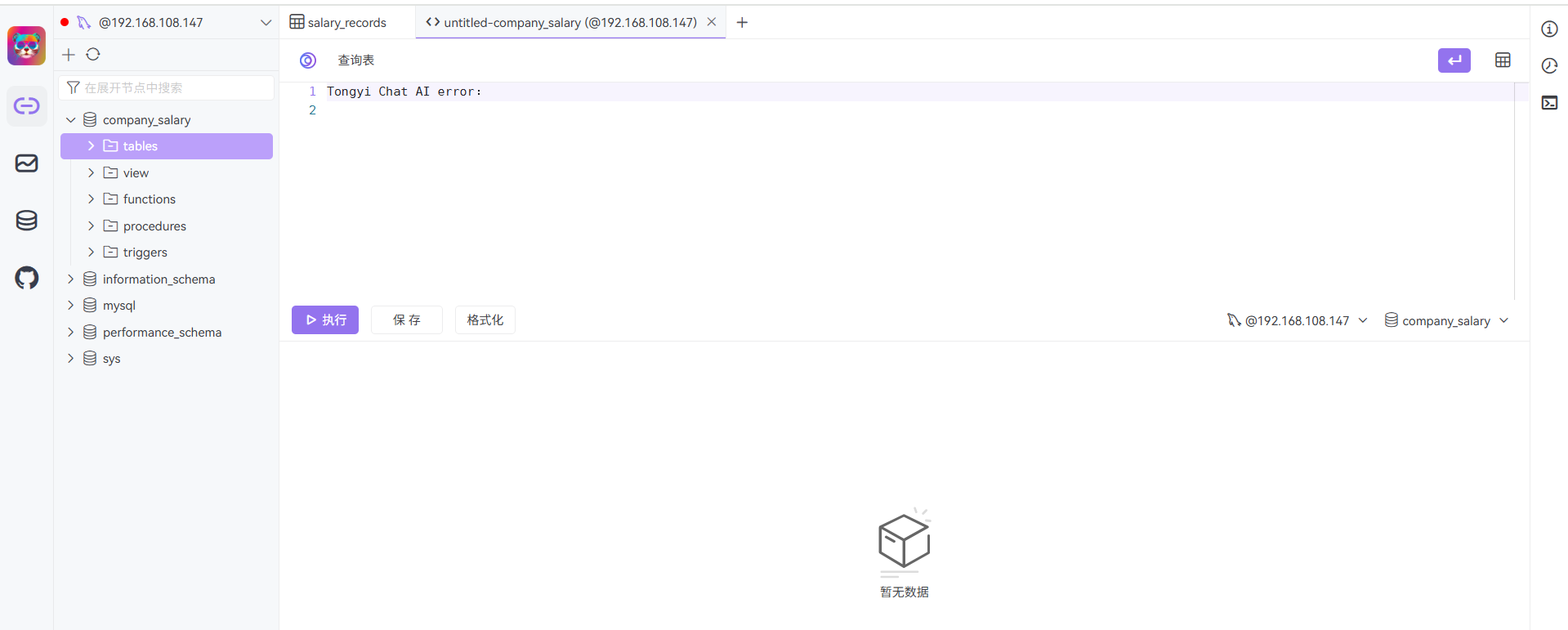
可能是我没配置好一直报错

















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









