



机器学习的元素:
样本:属性、标签。
模型:属性与标签的函数关系
训练:求解函数中的变量
测试:评价模型性能
推理:应用模型,通过样本推理标签
Tensor基本概念:
Tensor:张量,标量是0阶张量,向量是1阶张量,矩阵是2阶张量
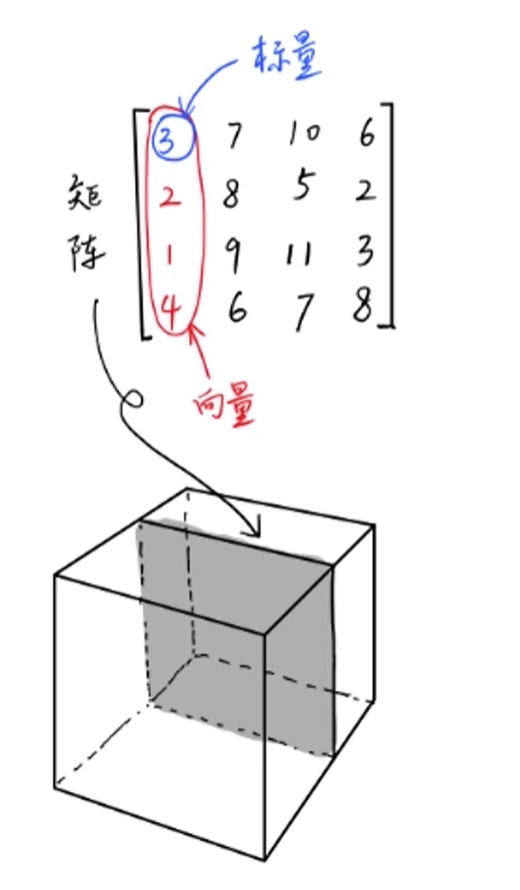
使用Tensor描述样本、变量、标签,是把现实世界数字化的工具
创建Tensor:
常规Tensor
torch.Tensor([1,2,3,4])
torch.Tensor(2,3) #2行,3列,数字随机
特殊Tensor
torch.ones(2,3) torch.ones_like(a)
torch.zeros(2,3) torch.zeros_like(a)
torch.eye(3,3) #左上到右下全是1
随机Tensor
torch.rand(2,3) #2行3列,数字为0-1之间的随机值
torch.random(1., 2. , size=(2,3)),均值为1.0, 标准差为2.0,形状为2行3列
Torch.Tensor(1,5).uniform(1,5),形状为1行5列,数字为1-5之间
序列Tensor
torch.arange(0,10, 2),0,2,4,6,8
torch.linspace(1,10, 4),1-10之间的等间隔的4个数字
torch.randperm(10),0-9 10个数字随机出现
Tensor的属性
torch.dtype: tensor 内部数据的类型,int, float等
torch.device:tensor存储在cpu还是GPU,torch.Tensor不能直接制定cpu或者cuda,使用torch.tensor可以直接制定device=‘cuda’
torch.layout:tensor在内存中的排布,稠密还是稀疏,稠密就是使用坐标标记非零的位置与数值,稠密就是所有的为0的位置都用0填满
Tensor的算术运算
加法:a+b, a.add(b)(不改变a的值 ),a.add_(b),(改变a的值) torch.add(a,b)
减法:a-b, a.sub(b)(不改变a的值),a.sub_(b), (改变a的值)torch.sub(a,b)
哈达玛积(mul): 2个tensor对应位置的数字相乘,a*b, a.mul(b)(不改变a的值), a.mul_(b)(改变a的值),torch.mul(a,b)
除法:a/b, a.div(b)(不改变a的值 ), a.div_(b)(改变a的值), torch.div(a,b)
矩阵乘法(matmul): a@b, a.matmul(b), torch.matmul(a,b)
1、标量无法与张量matmul,只能mul
2、向量@矩阵, 会将向量视为行向量
3、矩阵@向量,会将向量视为列向量
4、向量@向量,会将第二个向量视为列向量
5、3维及以上张量,只有最后2维matmul,前面几维长度要相同,前面的几维叫做批次维度
幂运算(a作为底数):a**3, a.pow(3)(不改变a的值 ), a.pow_(3)(改变a的值 ), tensor.pow(a, 3)
指数运算(a作为指数,e为底数):a.exp()(不改变a的值 ), a,exp_()(改变a的值 ),torch.exp(a)(不改变a的值 ), torch.exp_(a)(改变a的值 )
对数运算:a.log(), a.log_(), torch.log(a), torch.log_(a)
a.log2(), .......
a.log10(),......
开根号运算:a.sqrt(), a.sqrt_(), torch.sqrt(a), torch.sqrt_(a)
in-place 操作:以上带_的操作都不产生新的变量,叫做原地操作
广播机制:两个Tensor右对齐后每一个维度的长度要么相等,要么有一个为1,要么有一个Tensor维度不存在,这样才可以开启广播机制。

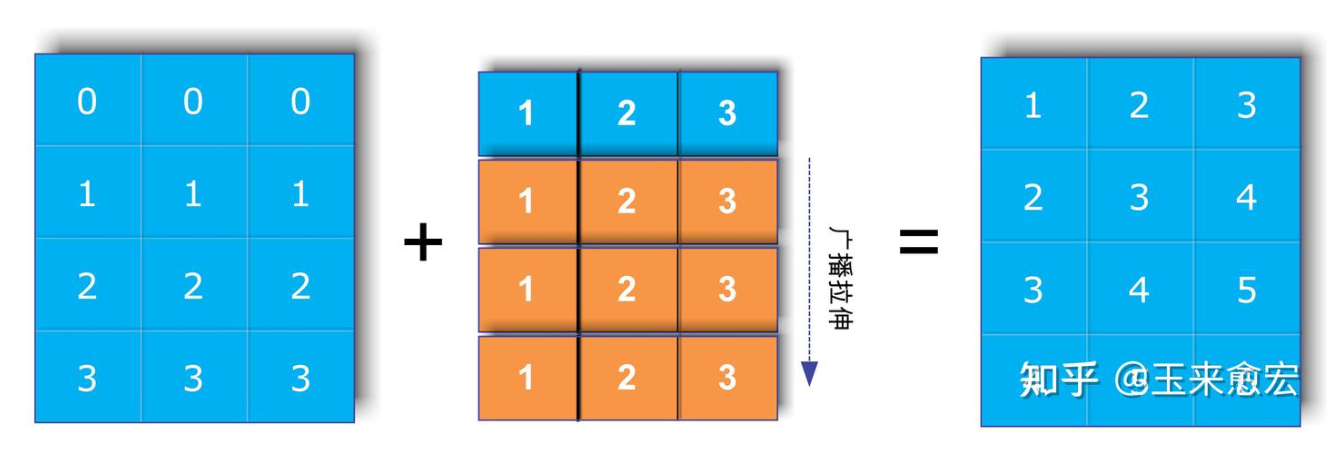 其他运算:向下取整数a.floor() 向上取整数a.ceil(), 四舍五入a.round(), 取整数部分a.trunc, 取小数部分a.frac(), 取余数a%2
其他运算:向下取整数a.floor() 向上取整数a.ceil(), 四舍五入a.round(), 取整数部分a.trunc, 取小数部分a.frac(), 取余数a%2
PCA与特征值分解:
LDA与奇异值分解
Tensor裁剪:
a.clamp(2,5): 将a的每一个值限制在2<=a.value<=5

















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









