




 本文介绍了一种基于几何先验的2D-to-BEV表示学习方法,利用几何指导的核变换器在图像特征上进行高效且鲁棒的特征优化。该方法通过预设的查找表加速计算,对相机标定参数扰动具有鲁棒性,适用于动态场景。实验结果显示在nuScenes数据集上,GKT在车辆分割性能和运行帧率上表现出优势。
本文介绍了一种基于几何先验的2D-to-BEV表示学习方法,利用几何指导的核变换器在图像特征上进行高效且鲁棒的特征优化。该方法通过预设的查找表加速计算,对相机标定参数扰动具有鲁棒性,适用于动态场景。实验结果显示在nuScenes数据集上,GKT在车辆分割性能和运行帧率上表现出优势。
参考代码:GKT
1. 概述
介绍:这篇文章介绍了一种基于几何先验在图像特征中寻找reference points,同时在该reference points处通过预先设置窗口抠取图像特征,并在此基础上使用attention操作实现特征优化,从而获取bev特征的方法。上述通过几何先验寻找reference points的方法可以通过look up table实现加速,这样整体网络的计算耗时就相对较小,可以跑到很高的帧率。对于车辆行驶过程中存在抖动的情况,文中提出了一种扰动机制添加到训练过程中,使得网络对扰动具有一定鲁棒性。
对于bev特征的构建主要分为两个流派:
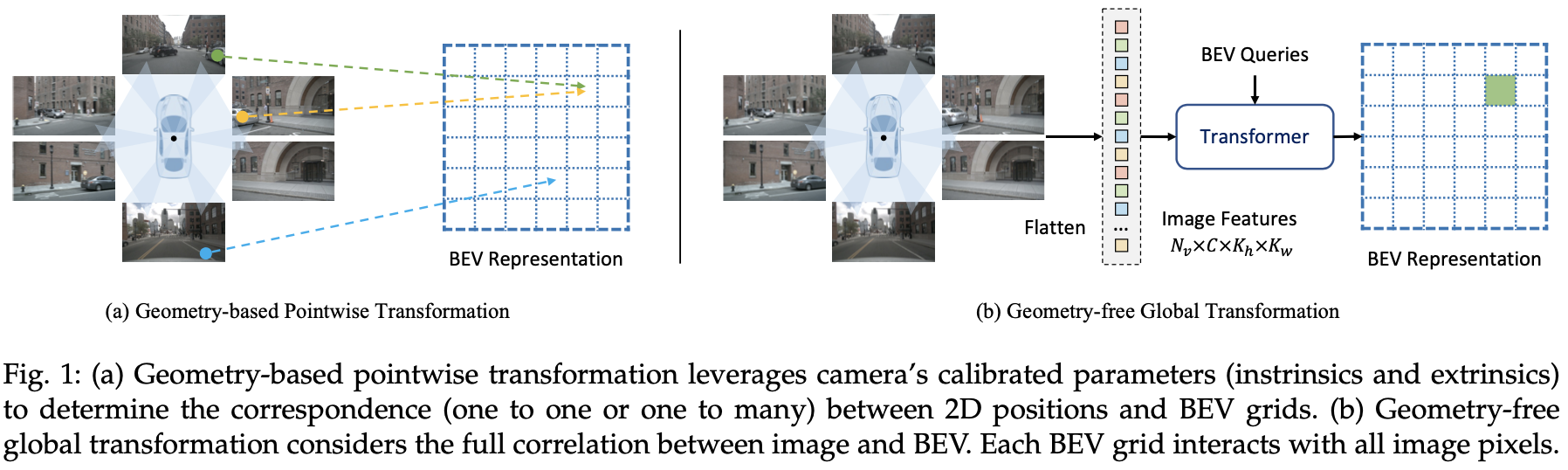
- 1)基于几何先验:使用相机标定参数实现图像特征到bev特征的映射,以此构建bev特征。但是该方法对相机标定参数依赖强,对于动态场景适应能力较差。见下图左图。
- 2)基于transformer:使用global attention的方式用设定好的bev query在图像特征上做attention从而得到bev特征,以CVT为代表,其收敛性和运算效率上存在瓶颈。但是其实现在也有基于deformable attention的实现,也能带来收敛性和运算效率上的改善,只不过相对这篇文章方法更复杂一些,而且文章就是指着CVT弄的,这个就先别杠。见下图右图。
2. 方法设计
2.1 pipeline
文章提出的方法见下图所示:
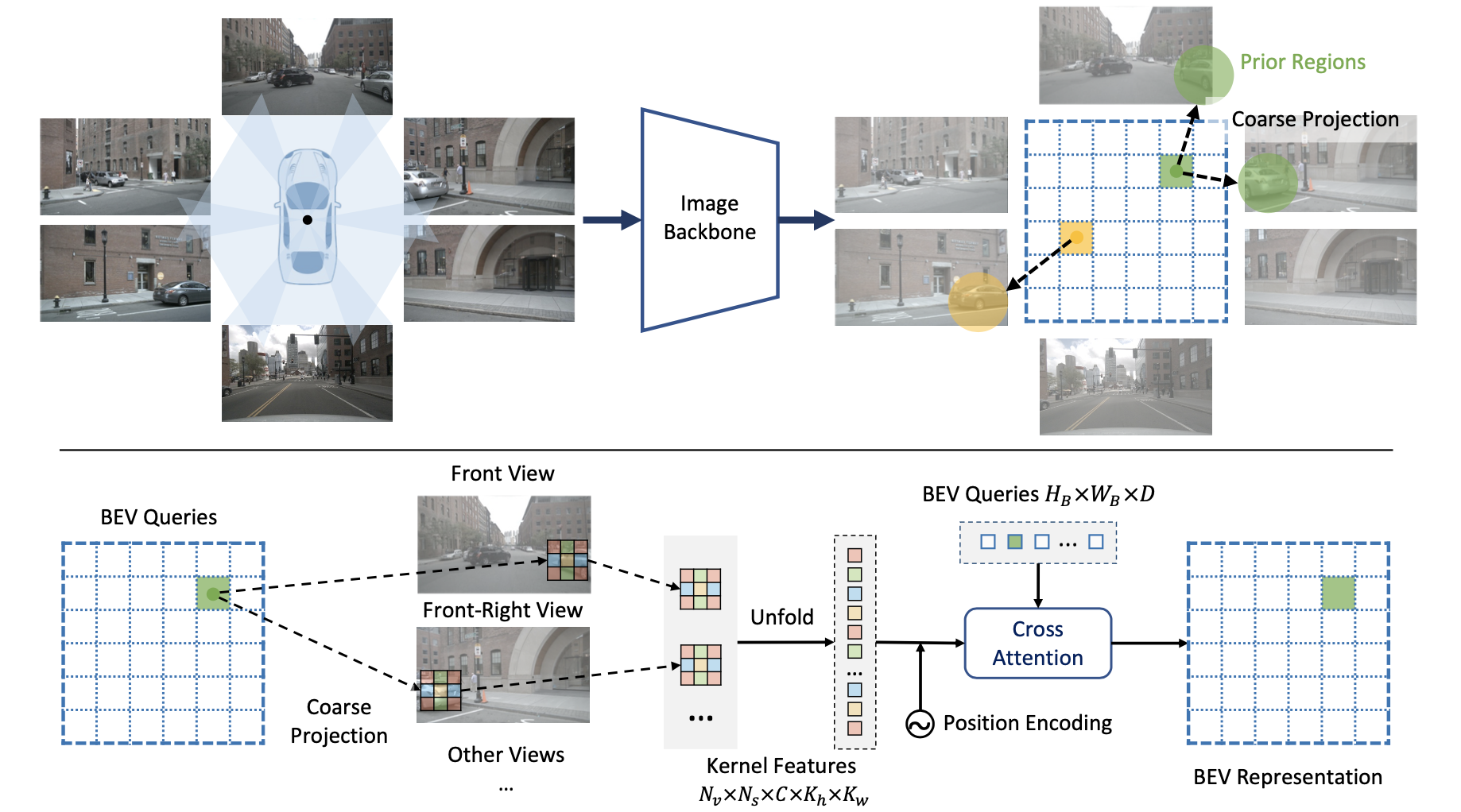
从上图中可以将该pipline划分为如下几个步骤:
- 1)使用CNN网络完成对输入图像数据特征抽取,并通过几何先验确定bev grid与图像特征上reference point的对应关系,相当于是粗定位。
- 2)由于自身运动或者周围场景中物体的运动相比标准环境带来的扰动,这里对每个bev grid对应的reference point处使用大小为 K h ∗ K w K_h*K_w Kh∗Kw窗口进行特征抠取,抠取之后的特征展平之后使用attention确定元素权重,从而得到在该bev grid下的特征表达。
2.2 实现中的一些trick
2.2.1 标定参数扰动问题
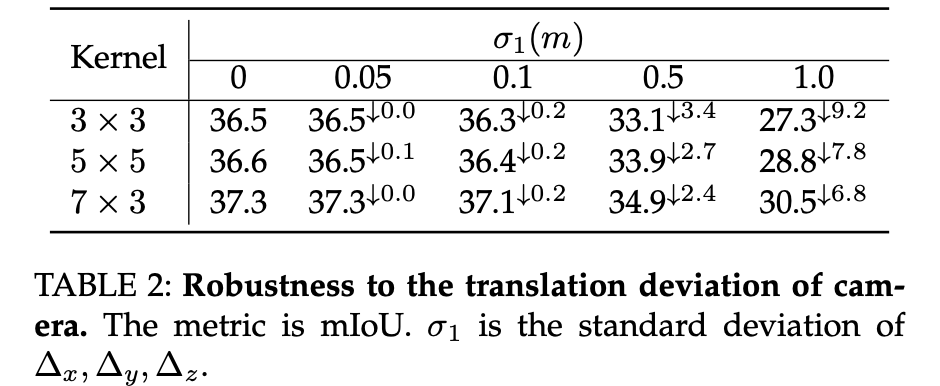
在之前论述中提到车辆自身运动会给相机标定参数带来扰动,对此一种办法便是在训练的过程给标定参数中的旋转和平移矩阵添加扰动,对于这个扰动文中是将其建模为高斯分布的采样,从而通过网络训练的方式给网络添加一定的适应能力。在下表中查看平移扰动的鲁棒性分析:
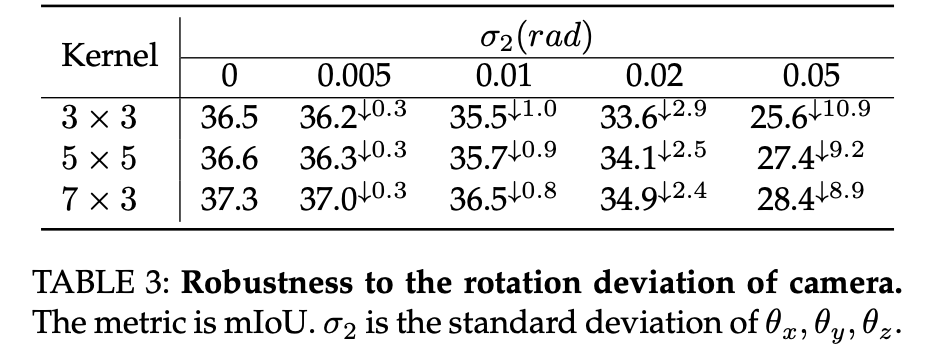
旋转扰动鲁棒性分析:
对bev特征中高度的鲁棒性:

2.2.2 快速查找表与采样窗口
通过设定bev grid到图像reference point的查找表可以加快网络的预算速度。查找表带来的帧率提升:

并且通过采样窗口在丰富特征表达的同时,也为系统带来一定的鲁棒性,对于窗口大小与形状对性能的影响,可以在上一节中的表中查看。
3. 实验结果
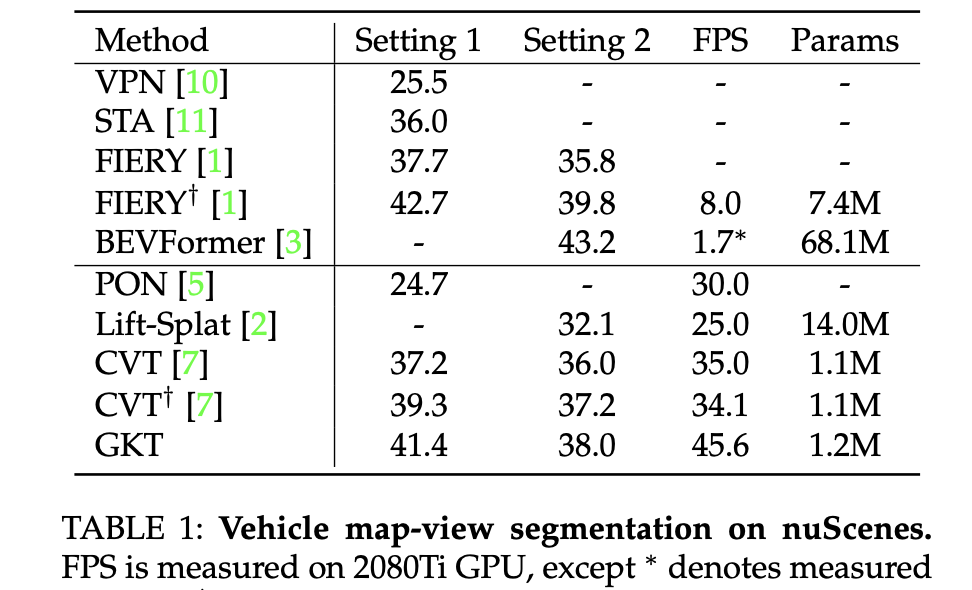
nuScenes数据下车辆分割性能与运行帧率比较:
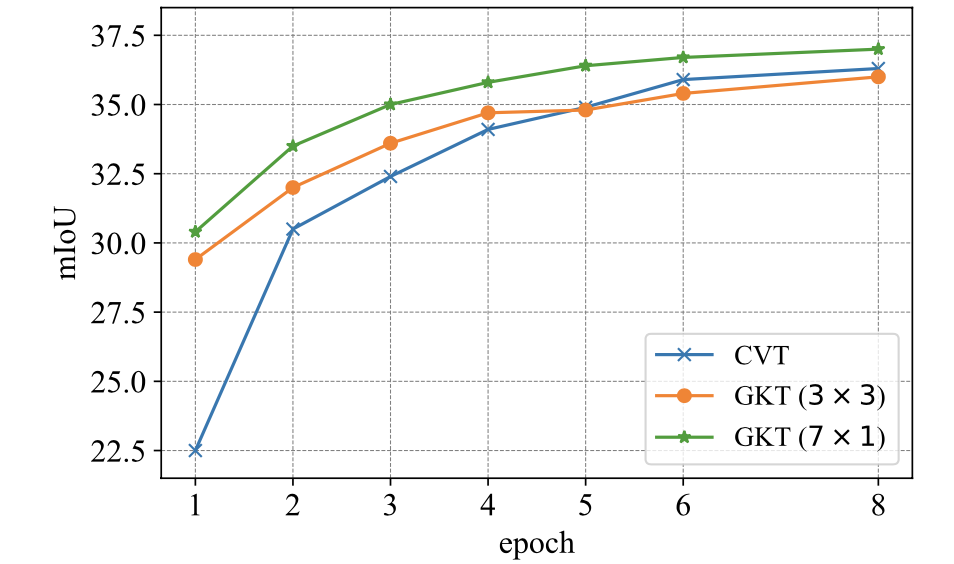
由于更加显式使用几个先验信息,文章的方法收敛性比CVT更好:


















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









