




 本文介绍了TDNet,一种利用时序分布网络进行快速视频语义分割的算法。通过拆分原始深层网络为多个浅层子网络,并结合注意力传播模块(APM)解决目标移动对分割的影响。同时,采用知识蒸馏提升学生网络性能。实验在Cityscapes等数据集上取得良好效果,强调了在推理过程中利用视频帧的时间顺序以提高效率。
本文介绍了TDNet,一种利用时序分布网络进行快速视频语义分割的算法。通过拆分原始深层网络为多个浅层子网络,并结合注意力传播模块(APM)解决目标移动对分割的影响。同时,采用知识蒸馏提升学生网络性能。实验在Cityscapes等数据集上取得良好效果,强调了在推理过程中利用视频帧的时间顺序以提高效率。
代码地址:TDNet
1. 概述
导读:这篇文章提出了一个基于时序分布网络的视频语义分割算法TDNet(Temporally Distributed Network),它的设计思想来自于这么一个观察:较深的网络输出的特征是可以由一系列的浅层网络输出的特征进行组合得到。而在视频分割任务中视频是具有时序属性的,而且视频分割也是有时序属性的,因而就可以在一定的时序范围内使用浅层的网络进行特征抽取,之后在经过组合可以达到深层网络输出特征的效果。这样的思路迁移也是相当简单的,那么怎么来实现文章中说的将多个浅层特征进行组合呢?文章对此的解决办法是使用一个新的APM(attention propagation module)来实现,减少分割目标移动对分割性能的影响。此外,还引入了知识蒸馏的概念,从使其可以在浅层网络输出特征与组合特征的两个层面进行知识迁移,从而提升学生网络的性能。文章的方法在Cityscapes/CamVid/NYUD-v2数据集上取得了不错的效果,不过说是视频分割怎么没有DAVIS呢-_-||?
这篇文章使用
N
N
N(每个子网络是原始网络尺寸的
1
N
\frac{1}{N}
N1)个子网络去构建文章提到的特征抽取网络组,之后再将这些子网络的结果进行组合得到最后用于分割的特征图,组合部分使用了文章提出的APM(attention propagatuion module)的方式进行,从而减少分割目标运动对分割带来的影响。在inference的时候由于利用了视频帧时序上的特点,因此当前帧只需要用子网络进行infer之后将这个特征与之前的
N
−
1
N-1
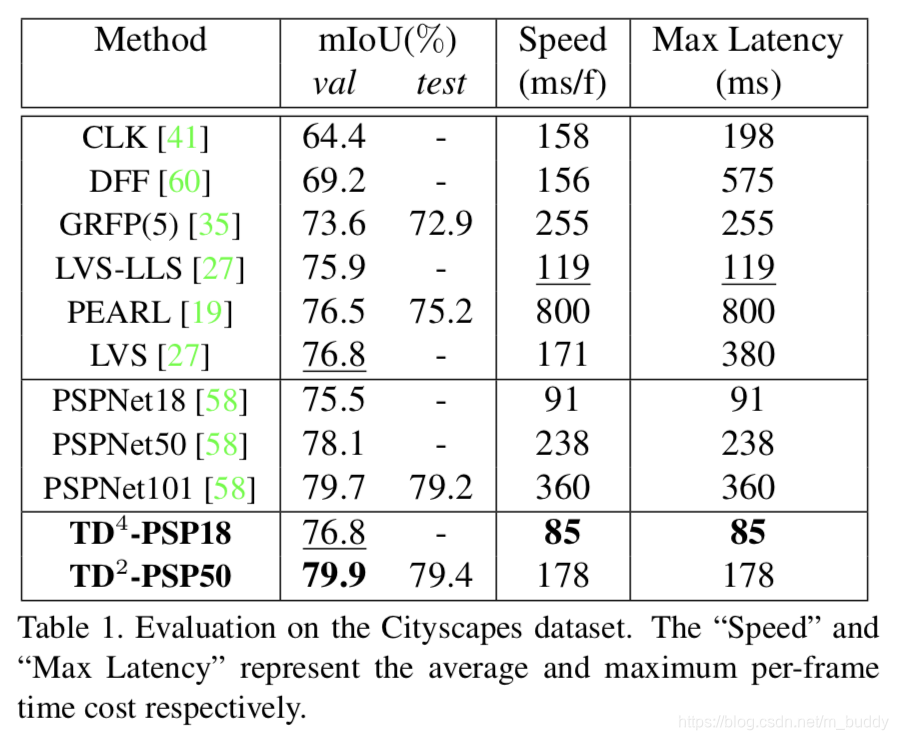
N−1个特征组合,之后进行分割,因而速度来所是很快的,就是需要消耗部分存储空间。其性能在Cityscapes数据集上与其它一些方法的比较见下图1所示:

2. 方法设计
2.1 原始网络拆分
现有的一些文献表明基于分组的卷积能在减少计算量的同时获取较好的性能,而传统分割网络中为了更好的性能会采用较深的特征抽取网络结构,这部分是相当耗时的。并且有相应的文章指出使用特征组合也能使用小网络获得大网络性能匹配的特征,因而文章将之前的大网络进行拆分,之后使用文章的APM模块进行融合,从而进一步减少计算量,则传统的特征抽取网络与文章提出的特征抽取网络其结构对比见下图所示:

2.2 子网络组成特征的融合
由于视频时序中存在目标的移动情况,这就会导致子网络处理的图片其中的目标像素是不能对齐的。虽然像光流这样的方式可以进行弥补,但是其计算开销较大/结果存在误差/具有限制等。文章对此是提出了一个基于non-local注意力机制的APM模块去解决对齐的问题,将APM集成到文章的网络中其结构见下图所示:

从上图中可以看出文章将网络划分为了两个阶段:编码阶段和分割阶段。
- 1)编码阶段:这里使用子网络进行特征抽取,得到特征图 X i ∈ R C ∗ H ∗ W X_i\in R^{C*H*W} Xi∈RC∗H∗W,之后使用一个编码单元(使用 1 ∗ 1 1*1 1∗1的卷积层)将这个特征图转换得到3个特征图: V i ∈ R C ∗ H ∗ W , Q i ∈ R C 8 ∗ H ∗ W , K i ∈ C 8 ∗ H ∗ W V_i\in R^{C*H*W},Q_i\in R^{\frac{C}{8}*H*W},K_i\in^{\frac{C}{8}*H*W} Vi∈RC∗H∗W,Qi∈R8C∗H∗W,Ki∈8C∗H∗W,前一个特征用于提供丰富的分割语义信息,后面的两个特征图用于时序对齐和注意力机制使用。
- 2)分割阶段:这里前 m − 1 m-1 m−1个子网络的特征进行attention操作,通过相邻帧之间attention传导的形式优化特征图,之后在当前帧使用分割层分割得到最后的结果。
在文章中所使用的子网络数目为
m
=
4
m=4
m=4,因而这里使用空间时序注意力机制将当前帧与前面的
m
−
1
m-1
m−1帧数据建立空间关系,因而当前帧与之前帧之间的相关性可以描述为:
A
f
f
p
=
S
o
f
t
m
a
x
(
Q
t
K
p
T
d
k
)
Aff_p=Softmax(\frac{Q_tK_p^T}{\sqrt{d_k}})
Affp=Softmax(dkQtKpT)
其中,
p
p
p代表之前帧的索引,
d
k
d_k
dk代表特征
Q
,
K
Q,K
Q,K的维度。因而当前经过空间位置对齐之后的特征图可以描述为:
V
t
‘
=
V
t
+
∑
p
=
t
−
m
+
1
t
−
1
ϕ
(
A
f
f
p
V
p
)
V_t^{‘}=V_t+\sum_{p=t-m+1}^{t-1}\phi (Aff_pV_p)
Vt‘=Vt+p=t−m+1∑t−1ϕ(AffpVp)
通过上面的计算方法可以高效捕获不同帧上像素的non-local相关性,其计算量为:
O
(
(
m
−
1
)
d
k
H
2
W
2
)
O((m-1)d_kH^2W^2)
O((m−1)dkH2W2),这部分计算量也是较大的,那么直观的方法就是对输入的特征图进行尺度压缩了。
特征图下采样
针对于降低网络计算量文章对特征图
Q
,
K
,
V
Q,K,V
Q,K,V进行了下采样(对之前的视频帧),其使用的操作是
γ
n
(
⋅
)
\gamma_n(\cdot)
γn(⋅)(文章将步长设置为
n
=
4
n=4
n=4),因而经过采样之后的特征描述为:
q
i
=
γ
n
(
Q
i
)
,
k
i
=
γ
n
(
K
i
)
,
v
i
=
γ
n
(
V
i
)
q_i=\gamma_n(Q_i),k_i=\gamma_n(K_i),v_i=\gamma_n(V_i)
qi=γn(Qi),ki=γn(Ki),vi=γn(Vi),经过这样的操作计算量下降为
O
(
(
m
−
1
)
d
k
H
2
W
2
n
2
)
O(\frac{(m-1)d_kH^2W^2}{n^2})
O(n2(m−1)dkH2W2)。
Attention的传导过程
文章中对于最后attention特征图的生成不是直接将之前
m
−
1
m-1
m−1个特征图组合起来计算attention特征图,而是在相邻的两帧上计算attention特征图(文章提到这样会使得对于运动场景更加鲁棒),之后经过传导的形式传导到当前帧。
对于之前的
m
−
1
m-1
m−1帧的attention优化结果可以描述为:
v
p
‘
=
ϕ
(
S
o
f
t
m
a
x
(
q
p
k
p
−
1
T
d
k
)
v
p
−
1
‘
)
+
v
p
v_p^{‘}=\phi (Softmax(\frac{q_pk_{p-1}^T}{\sqrt{d_k}})v_{p-1}^{‘})+v_p
vp‘=ϕ(Softmax(dkqpkp−1T)vp−1‘)+vp
其中,
p
∈
(
t
−
m
+
1
,
t
)
p\in (t-m+1, t)
p∈(t−m+1,t)代表之前帧的索引,
ϕ
p
\phi_p
ϕp是一个
1
∗
1
1*1
1∗1的卷积操作,这里的特征图都是经过下采样的。
之后当前帧优化之后的特征可以描述为:
V
t
‘
=
ϕ
(
S
o
f
t
m
a
x
(
Q
t
k
t
−
1
T
d
k
)
v
t
−
1
‘
)
+
V
t
V_t^{‘}=\phi (Softmax(\frac{Q_tk_{t-1}^T}{\sqrt{d_k}})v_{t-1}^{‘})+V_t
Vt‘=ϕ(Softmax(dkQtkt−1T)vt−1‘)+Vt
之后这个优化之后的特征图就被送入到分割网络进行分割了。不过这里是不是该有之前优化之后特征图的上采样呢?需要去看具体代码实现了。
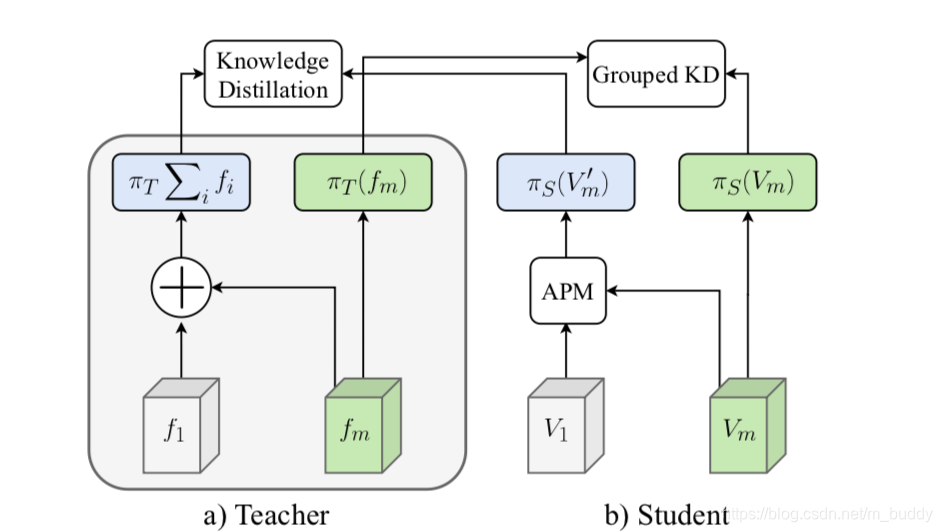
2.3 引入知识蒸馏
文章使用PSPNet101作为教师网络,带有
m
m
m个子网络的TDNet作为学生网络。
m
m
m个子网络产生了一系列的特征图
{
f
i
∣
i
=
1
,
…
,
m
}
\{f_i|i=1,\dots,m\}
{fi∣i=1,…,m},原始使用教师网络进行输出表示为:
π
T
(
∑
f
)
\pi_T(\sum f)
πT(∑f),则每个子网络的特征图在教室网络分割层上的分量为
π
T
(
f
i
)
\pi_T(f_i)
πT(fi),因而总的蒸馏部分的损失就可以描述为:教师网络单纯使用组合特征分割生成结果与学生网络使用组合优化特征分割生成结果进行蒸馏,针对当前帧的分割结果进行蒸馏。这样就兼顾到了整体与局部,实现子网络与整体网络的提升。因而文章的损失函数设计为:
L
o
s
s
=
C
E
(
π
S
(
V
i
‘
,
g
t
)
)
+
α
⋅
K
L
(
π
S
(
V
i
‘
)
∣
∣
π
T
(
∑
f
)
)
+
β
⋅
K
L
(
π
S
(
V
i
)
∣
∣
π
T
(
f
i
)
)
Loss=CE(\pi_S(V_i^{‘},gt))+\alpha \cdot KL(\pi_S(V_i^{‘})||\pi_T(\sum f))+\beta \cdot KL(\pi_S(V_i)||\pi_T(f_i))
Loss=CE(πS(Vi‘,gt))+α⋅KL(πS(Vi‘)∣∣πT(∑f))+β⋅KL(πS(Vi)∣∣πT(fi))
其计算流程可以表示为:
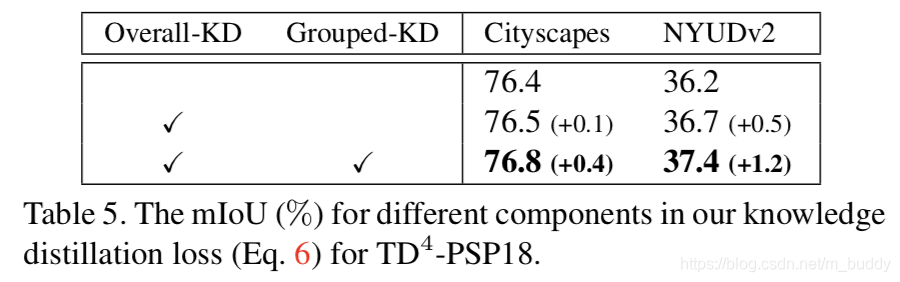
知识蒸馏带来的影响:
3. 实验结果

















 1459
1459





 到【灌水乐园】发言
到【灌水乐园】发言







