




 本文介绍了《A Transductive Approach for Video Object Segmentation》的论文笔记,提出了一种不需要额外模块或数据的传导方法,利用特征相似性进行像素信息传导,实现视频分割。这种方法在DAVIS-2017上取得了良好效果,但infer时可能因存储和计算需求影响速度。
本文介绍了《A Transductive Approach for Video Object Segmentation》的论文笔记,提出了一种不需要额外模块或数据的传导方法,利用特征相似性进行像素信息传导,实现视频分割。这种方法在DAVIS-2017上取得了良好效果,但infer时可能因存储和计算需求影响速度。
1. 概述
导读:现有的很多视频分割算法是依赖在外部训练好的额外模块实现的,如光流网络与实例分割,这就导致了这些方法在传统基准上无法与其它方法媲美。为此文章提出了一个简单且强大的传导方法来解决这个问题,这个方法不需要额外的子计网络模块,数据,或是专用的网络结构。在文章的方法使用标注传导的方式,它是在特征空间上基于特征相似性实现分割中像素信息的传导。与之前的一些短依赖不同的是文章采用了“全局”的方式,将较为长期的目标特性考虑在内,从而有较好的帧间一致性。但是,有一点问题就是需要在infer前需要一些计算量,在Titan XP GPU上能跑到37 FPS(backbone为ResNet-50,在ImageNet上预训练),在DAVIS-2017 val上达到了72.3%,test上达到了63.1%,效果还是很不错的。
在视频分割中有两个基本的前提假设:1)相邻两帧之间的label差异很小,动作的连续性;2)视频帧中的相同区域中应该有相同的标签;因而在视频分割中局部和全局的依赖是比较核心的概念,它将视频分割提供了充足且平滑的相关性分布,因而就可以在未标注的后序视频数据上进行预测。
这篇文章中的局部依赖来自于空间与运动的先验,这是基于空间上的邻域像素具有相同的标签,并且时序上相隔较远的帧在空间上的联系较弱。而全局依赖是目标的视觉外在特征,这是通过在训练数据上使用卷积网络得到的。
网络在infer的时候也是需要将目标的mask放在建立的空间时序特征上进行的,但是现有的很多分割算法它们已建立依赖要么是相邻的两帧,要么就是开头给定的参考帧,这就会导致mask推导信息的丢失,从而使得对目标形变和遮挡的鲁棒性不是很好。文章的方法与之前的方法进行比较,其差异见下图2所示:

而在文章中是使用从开始帧到当前帧的所有信息进行mask传导,但为了减少计算量分割网络会对当前帧的邻近帧密集采样,那些时序上相对较远的帧就采样相对稀疏。
经过上面思路的改进,则将文章的方法与之前的方法进行比较其性能(DAVIS-2017)比较见下图所示:

PS:文章给出的算法确实是很快的,主要因为文章的网络部分就十分的简单,stride=8的backbone直接输出,之后就是一些矩阵运算计算相似性。但是在infer的时候需要存储较多的之前帧的特征图与之前帧的label,以及一些矩阵运算,这些会不会拖慢整个算法流程在手机等设备上的速度呢? 需要进一步移植实验-_-||。
2. 方法设计
2.1 可传导的推理框架
这里给出了一个通过给出的部分标注数据进行半监督的推导模型,之后的视频分割就是在这个基础上发展而来的,算是文章提出的视频分割算法的理论基础。
对于一个给定的数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
(
x
l
,
y
l
)
,
x
l
+
1
,
…
,
x
n
}
D=\{(x_1,y_1),(x_2,y_2),(x_l,y_l),x_{l+1},\dots,x_n\}
D={(x1,y1),(x2,y2),(xl,yl),xl+1,…,xn},也就是给出前
l
l
l个有标注的数据(看作先验知识),之后的
n
−
l
n-l
n−l个数据时候没有对应的标注信息的,就是需要使用这个序列进行位置标注推导。因而这个推导计算过程描述为:
Q
(
y
^
)
=
∑
i
,
j
n
w
i
,
j
∣
∣
y
i
^
d
i
+
y
j
^
d
j
∣
∣
2
+
μ
∑
i
=
1
l
∣
∣
y
i
^
−
y
i
∣
∣
2
Q(\hat{y})=\sum_{i,j}^nw_{i,j}||\frac{\hat{y_i}}{\sqrt{d_i}}+\frac{\hat{y_j}}{\sqrt{d_j}}||^2+\mu \sum_{i=1}^l||\hat{y_i}-y_i||^2
Q(y^)=i,j∑nwi,j∣∣diyi^+djyj^∣∣2+μi=1∑l∣∣yi^−yi∣∣2
其中,
w
i
j
w_{ij}
wij编码的是两个数据
(
x
i
,
x
j
)
(x_i,x_j)
(xi,xj)之间的相似性,
d
i
=
∑
j
w
i
j
d_i=\sum_jw_{ij}
di=∑jwij表示对
x
i
x_i
xi的度,因而从上面的公式中可以看出其具有两个方面的约束:
- 1)平滑约束:它使得相邻近似的点具有相同标签;
- 2)一致性约束:惩罚输出的结果偏离之前的观测结果;
然后,上式中的
μ
\mu
μ是用来平衡两个约束用的,而对与上面的半监督分类模型可以描述为解决下面的
arg min
\argmin
argmin问题:
y
^
=
arg min
Q
(
y
)
\hat{y}=\argmin Q(y)
y^=argminQ(y)
而要解决上面的优化问题可以通过下面迭代的方式进行求解。首先,令
S
=
D
−
1
2
W
D
−
1
2
S=D^{-\frac{1}{2}}WD^{-\frac{1}{2}}
S=D−21WD−21,它代表的是由
w
i
j
w_{ij}
wij构建的经过归一化之后的相似性矩阵。之后迭代优化
y
k
^
\hat{y_k}
yk^直到收敛,因而对于下一个数据的预测可以表示为:
y
^
(
k
+
1
)
=
α
S
y
^
(
k
)
+
(
1
−
α
)
y
(
0
)
\hat{y}(k+1)=\alpha S\hat{y}(k)+(1-\alpha)y(0)
y^(k+1)=αSy^(k)+(1−α)y(0)
其中,
α
=
μ
μ
+
1
\alpha=\frac{\mu}{\mu+1}
α=μ+1μ,一般情况下取值为0.99,而
y
(
0
)
=
[
y
1
,
y
2
,
…
,
y
n
]
T
y(0)=[y_1,y_2,\dots,y_n]^T
y(0)=[y1,y2,…,yn]T是包含了初始与预测标签的组合。
2.2 在线视频分割推导模型
这部分是在上面理论推导的基础上进行的,但是要解决视频分割领域的问题还是面临3个方面的难题:
- 1)视频帧是一个序列,因而只能利用当前帧与之前帧的信息进行推导;
- 2)图像中的像素点是很多的,计算这些像素点的相似矩阵是很难计算的;
- 3)需要有在视频序列帧中像素有效的相似度量 W W W;
由于到当前帧之前的mask信息都已经被推导出来了,因而上面的推导可以描述为:
$
y
^
(
t
+
1
)
=
S
1
:
t
→
t
+
1
y
^
(
t
)
\hat{y}(t+1)=S_{1:t\rightarrow t+1}\hat{y}(t)
y^(t+1)=S1:t→t+1y^(t)
其中,
S
1
:
t
→
t
+
1
S_{1:t\rightarrow t+1}
S1:t→t+1代表的是第
t
t
t帧与第
t
+
1
t+1
t+1帧的相似度量矩阵,而
y
(
0
)
y(0)
y(0)是被忽略的,这是由于除了视频的第一帧给了真实的标注,其它的都是推理出来的。
因而对于帧
t
+
1
t+1
t+1上面的推导过程也就是在空间时序上去最小化之前的平滑部分约束:
Q
t
+
1
(
y
^
)
=
∑
i
∑
j
w
i
,
j
∣
∣
y
i
^
d
i
+
y
j
^
d
j
∣
∣
2
Q^{t+1}(\hat{y})=\sum_i \sum_jw_{i,j}||\frac{\hat{y_i}}{\sqrt{d_i}}+\frac{\hat{y_j}}{\sqrt{d_j}}||^2
Qt+1(y^)=i∑j∑wi,j∣∣diyi^+djyj^∣∣2
其中,
i
i
i代表时序
t
+
1
t+1
t+1帧中的像素,
j
j
j代表包含
t
t
t及其之前帧的先验。
2.3 label的传导
有了上面的公式推导,那么视频分割中帧的传导就变得很清晰了,那么其核心就是相似度矩阵 S S S,而它的核心组成部分就是相似性度量矩阵 W W W。
PS:下面的机制都是在infer的时候进行的,由于训练的时候数据都有标注,则直接使用之前帧的嵌入特征与标签预测当前帧的结果。
相似度度量准则
为了实现平滑的分割结果,这里的相似性度量需要兼顾全局的高层次语义信息与局部的低层次空间连续性,因而这里的相似性度量
w
i
j
w_{ij}
wij可以描述为:
w
i
j
=
e
x
p
(
f
i
T
f
j
)
⋅
e
x
p
(
−
∣
∣
l
o
c
(
i
)
−
l
o
c
(
j
)
∣
∣
2
σ
2
)
w_{ij}=exp(f_i^Tf_j)\cdot exp(-\frac{||loc(i)-loc(j)||^2}{\sigma^2})
wij=exp(fiTfj)⋅exp(−σ2∣∣loc(i)−loc(j)∣∣2)
其中,
f
i
,
f
j
f_i,f_j
fi,fj是像素
p
i
,
p
j
p_i,p_j
pi,pj的嵌入特征,
l
o
c
(
i
)
loc(i)
loc(i)是像素
i
i
i空间位置,
σ
\sigma
σ是用于控制空间连续的本地化参数。
视频帧采样策略
在一个视频中往往有很多的帧,要对这些帧组合起来计算相似矩阵
S
S
S是相当耗时的。对此文章提出了一种高效的采样策略,文章中总共采样9帧,对于当前帧之前的4帧进行密集采样,对于余下的5帧就在密集采样之前的帧里面进行随机选择(也就是稀疏采样),其示意见下图所示:

运动先验
由于相隔较远的帧之间它们之间的空间依赖性就变得很弱了(隔了那么久,肯定变化了很多),对此文章对于密集采样使用局部参数
σ
=
8
\sigma=8
σ=8,而对于稀疏采样则使用的是
σ
=
21
\sigma=21
σ=21。这样就可以很好监督长短依赖问题。
2.4 目标表面特征学习
这部分是以数据驱动的方式进行的,去适应目标不同的运动/尺度/形变的因素,对于目标像素
x
i
x_i
xi它是将之前帧中所有的像素作为参考,
f
i
,
f
j
f_i,f_j
fi,fj代表目标像素
x
i
x_i
xi与参考像素
x
j
x_j
xj的嵌入特征,因而目标像素
x
i
x_i
xi的预测结果
y
i
^
\hat{y_i}
yi^可以描述为:
y
^
=
∑
j
e
x
p
(
f
i
T
f
j
)
∑
k
e
x
p
(
f
i
T
f
k
)
⋅
y
j
\hat{y}=\sum_j\frac{exp(f_i^{T}f_j)}{\sum_kexp(f_i^Tf_k)}\cdot y_j
y^=j∑∑kexp(fiTfk)exp(fiTfj)⋅yj
得到预测结果之后,使用传统的交叉墒损失函数就可以实现训练(代码里面使用的是:nn.NLLLoss())。
3. 实验结果
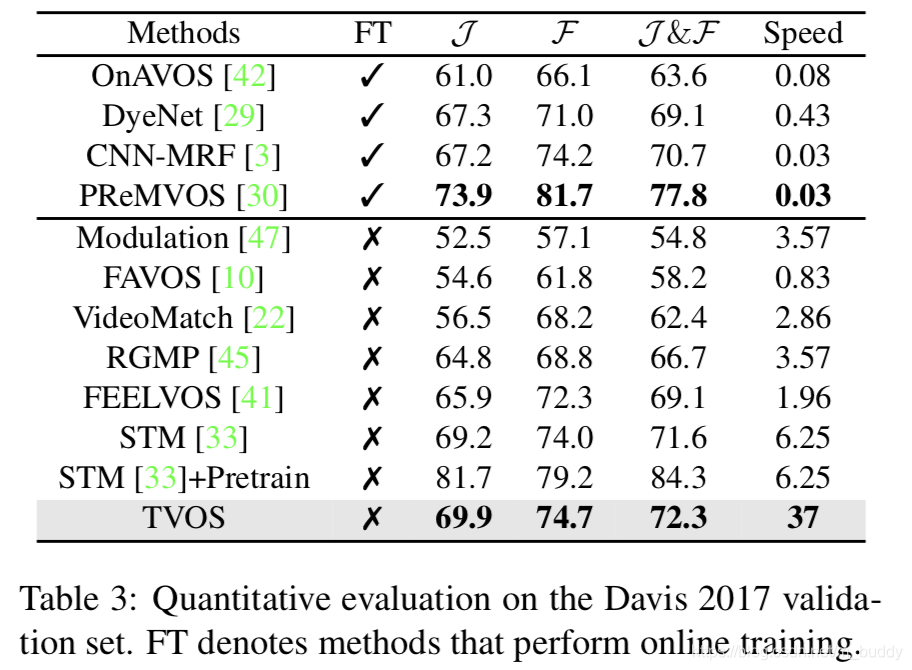
DAVIS-2017 val数据集上的性能表现:
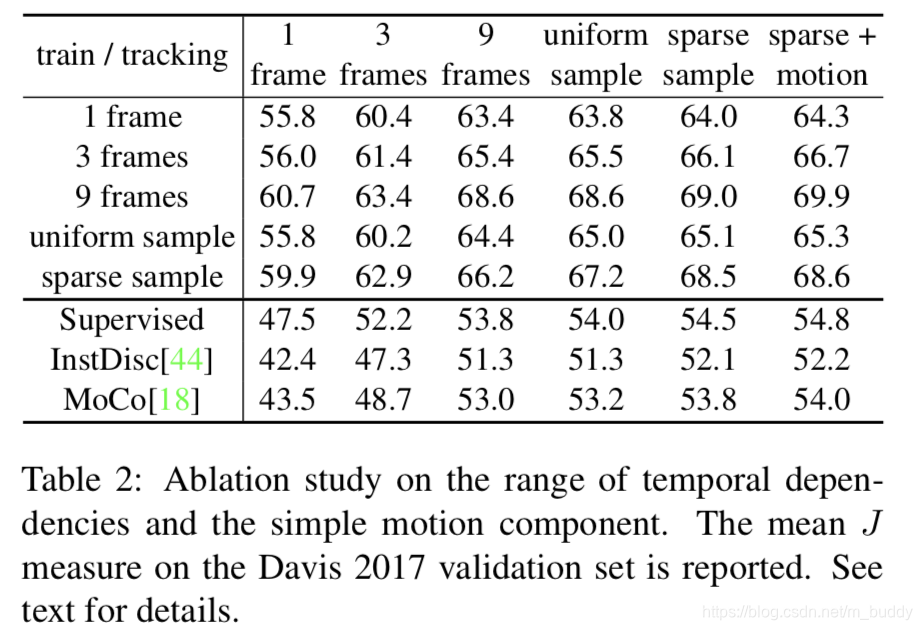
算法中一些变量对于最后结果的影响:

















 2239
2239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









