






 本文详细介绍了KNN算法的工作原理,包括通过计算特征值距离进行分类的过程,以及数据准备和分类器测试的方法。通过实例展示了如何使用Python实现KNN算法并进行结果预测,同时提及了通过错误率评估分类器性能。
本文详细介绍了KNN算法的工作原理,包括通过计算特征值距离进行分类的过程,以及数据准备和分类器测试的方法。通过实例展示了如何使用Python实现KNN算法并进行结果预测,同时提及了通过错误率评估分类器性能。
KNN算法概述
KNN算法是通过计算不同特征值之间的距离来进行分类的算法。
其工作原理是这样的,存在一个样本数据的集合,这个样本数据的集合被称作训练样本集,样本集中每个数据的标签与这些数据之间有着一一对应的关系。输入没有标签的新数据后,会将新数据的每个特征与样本集中数据特征进行比较,然后利用相关的距离算法提取样本集中特征最相似数据的分类标签。一般会选择样本数据集中前k个最相似的数据,通常k的取值是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
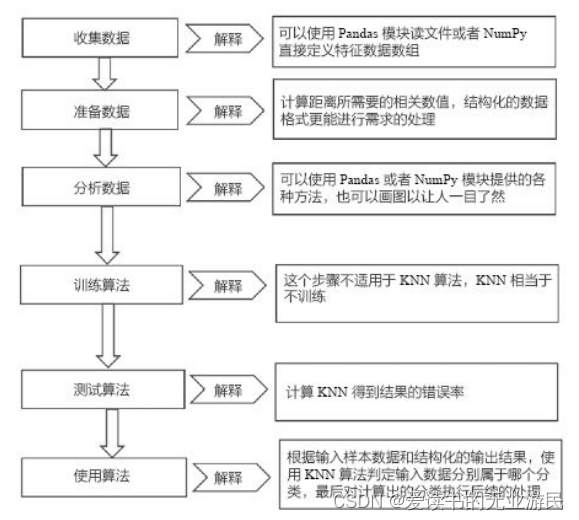
KNN算法一般流程
KNN算法数据准备
通过以下代码定义本示例所需数据(本数据仅供学习使用):
def createDataSet():
group=array( [[20,3 ],[15,5],[18,1],[5,17],[2,15],[3,20]])
labels = ["服务策略","服务策略","服务策略","平台策略","平台策略","平台策略"]
return group, labels
上述函数创建了数据分析所用的数据集和标签,可以通过Matplotlib模块对函数返回的数据集和标签进行绘制,展示其数据的特点,代码如下:
if __name__=="__main__":
group,labels=createDataSet()
x=[item[0] for item in group[:3]]
y=[item[1] for item in group[:3]]
pyplot.scatter(x,y,s=30,c="r",marker="o")
x=[item[0] for item in group[3:6]]
y=[item[1] for item in group[3:6]]
pyplot.scatter(x,y,s=100,c="b",marker="x")
pyplot.show()
上述代码运行结果如下图所示:
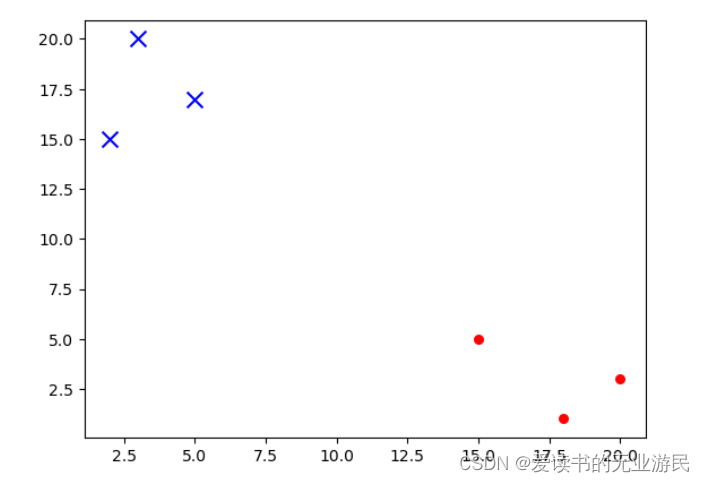 从图中显示的数据可视化可知,将数据点(20,3)、(15,5)、(18,1) 定义为“服务策略”,数据点(5,17)、(2,15)、(3,20)定义为“平台策略”,就构成了带有类标签信息的6个数据点。
从图中显示的数据可视化可知,将数据点(20,3)、(15,5)、(18,1) 定义为“服务策略”,数据点(5,17)、(2,15)、(3,20)定义为“平台策略”,就构成了带有类标签信息的6个数据点。
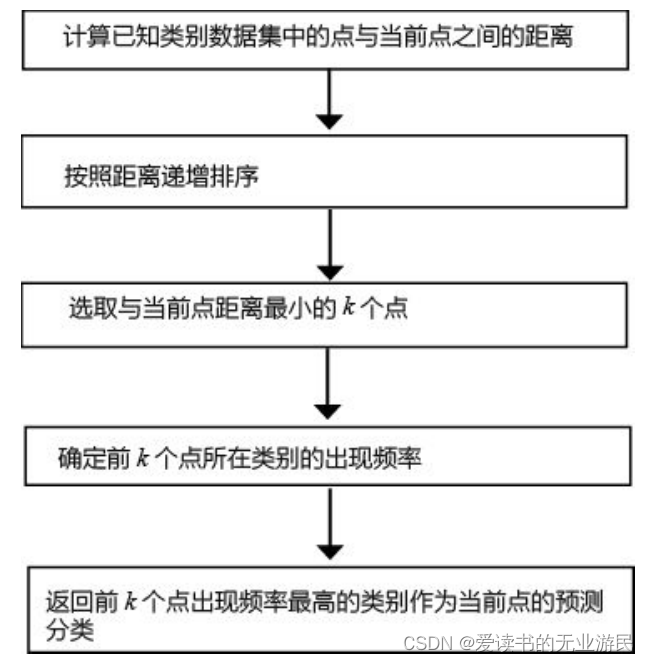
下图是KNN算法对未知属性点的操作流程
 Python中对未知属性点的操作的函数classify()功能的具体实现代码如下:
Python中对未知属性点的操作的函数classify()功能的具体实现代码如下:
def classify(in_x,datas,labels,k):
data_size = datas.shape[0]
diff_mat = tile(in_x,(data_size,1))-datas
sqrt_diff = diff_mat**2
sub_distances = sqrt_diff.sum(axis = 1)
distances = sub_distances**0.5
sorted_distances = distances.argsort()
class_count = {}
for i in range(k):
votel_label = labels[sorted_distances[i]]
class_count[votel_label]=class_count.get(votel_label,0)+1
sorted_class_count = sorted(class_count.itemitems()
return sorted_class_count[0][0]
上述代码中的 classify()函数有4个输入参数:用于分类的输入向量是in_x,输入的训练样本集为datas,标签向量为labels,最后的参数k表示用于选择最近邻居的数目,其中标签向量的元素数目和datas的行数相同。
其距离使用欧氏距离公式,计算两个向量点A xy 和B xy 之间的关系,其公式为:
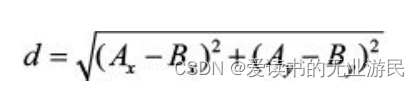
计算完所有点之间的距离后,可以对数据按照从小到大的次序排列。然后,确定前k个距离最小元素所在的主要分类,输入参数k总是正整数;最后,将class_count字典分解为元组列表,并使用程序第二行导入运算符模块的itemgetter() ,按照第二个元素的次序对元组进行排序。此处的排序为逆序,即按照从大到小的次序排列,返回发生频率最高的元素标签。
运行以下代码可以预测数据所在分类:
classify([4,17],group,labels,3)
其结果为“平台策略”
分类器结果测试
为了测试分类器的效果,可以使用已知答案的数据,检验分类器给出的结果是否是先前已知的答案,当然先前已知答案是不能告诉分类器的。通过大量的测试数据不断地参与,就可以得到分类器的错误率,这个错误率的计算方式就是用分类器给出错误结果的次数除以测试执行的总数。错误率是最常用的评估方法,评估分类器在某个特定数据集上的执行效果。“最完美”的分类器肯定错误率为0 ,在这种情况下,分类器找到的全是正确答案;最差的分类器的错误率应该是1.0,相当于分类器根本就无法找到一个正确答案。

















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









