



Spark 2.4.0 三节点集群部署文档 (Standalone 模式)
1. 集群规划
| 节点 IP | 主机名 (映射) | 角色分配 | 备注 |
|---|---|---|---|
| 10.8.16.213 | node213 | Master + Worker | Spark主节点兼Flink分节点 |
| 10.8.16.209 | node209 | Worker | Spark分节点兼Flink主节点 |
| 10.8.16.210 | node210 | Worker | Spark分节点兼Flink分节点 |
- 安装路径:/home/bigdata/spark-2.4.0-bin-hadoop2.7
- 运行用户:bigdata
- JDK版本:1.8
2. 环境准备 (所有节点)
2.1 jdk8安装
JDK 8 安装
#下载jdk8
sudo yum install -y java-1.8.0-openjdk-devel
修改环境变量:
vi ~/.bashrc
添加以下:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$JAVA_HOME/bin:$PATH
刷新环境变量
source ~/.bashrc
查看jdk是否安装成功
java -version

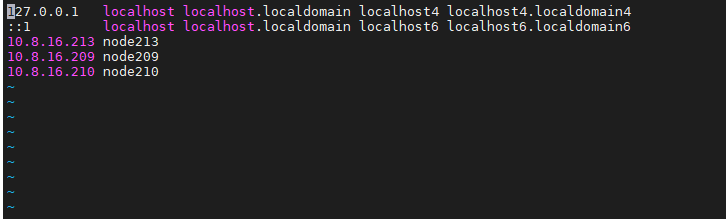
2.2 修改 Hosts 文件
在 /etc/hosts 中添加映射,确保三台机器能通过主机名互访:
10.8.16.213 node213
10.8.16.209 node209
10.8.16.210 node210
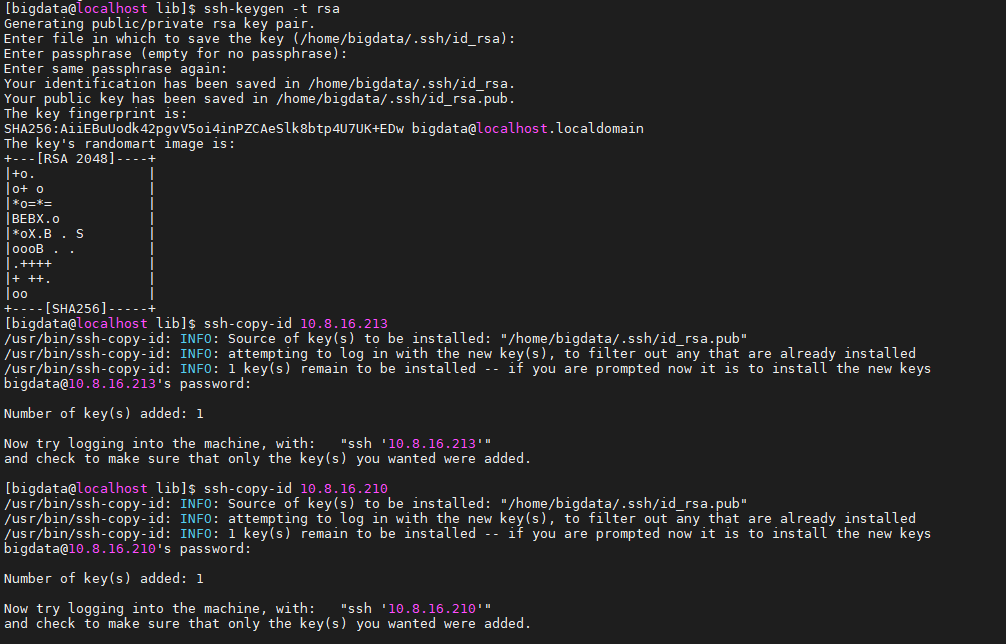
2.2 SSH 免密登录 (以 bigdata 用户执行)
在 10.8.16.213 上生成密钥并分发,确保 Master 启动时不需要输入密码:
ssh-keygen -t rsa # 一路回车
ssh-copy-id bigdata@10.8.16.213
ssh-copy-id bigdata@10.8.16.209
ssh-copy-id bigdata@10.8.16.210
3. 软件安装与配置 (三节点都需要)
3.1 下载并解压
cd /home/bigdata
wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
3.2 配置环境变量
编辑 ~/.bashrc:
export SPARK_HOME=/home/bigdata/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
执行 source ~/.bashrc 生效:
source ~/.bashrc
3.3 修改 spark-env.sh(仅在10.8.16.213)
#进入所在文件目录
cd /home/bigdata/spark-2.4.0-bin-hadoop2.7/conf
#复制备份原文件
cp spark-env.sh.template spark-env.sh
#进入编辑
vi spark-env.sh
本次搭建环境是三节点flink1.19.3集群模式和三节点spark2.4.0集群模式,如果单独搭建spark2.4.0集群模式可以省略以下这一步:
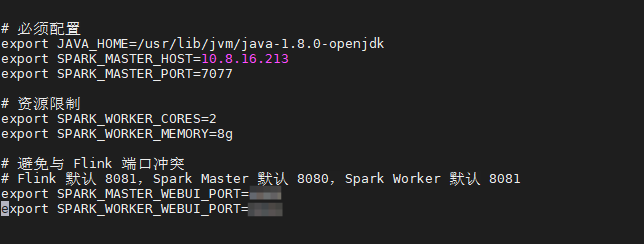
添加以下内容(注意避开 Flink 端口):
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export SPARK_MASTER_HOST=10.8.16.213
export SPARK_MASTER_PORT=7077
# Web UI 端口配置 (避开 Flink 8081),自行设置即可
export SPARK_MASTER_WEBUI_PORT=xxxx
export SPARK_WORKER_WEBUI_PORT=xxxx
# 资源限制
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=8g
3.4 修改 slaves(仅在10.8.16.213)
cp slaves.template slaves
vi slaves
写入 Worker 节点 IP:
10.8.16.213
10.8.16.209
10.8.16.210
4. 分发配置 (从10.8.16. 213主节点分发到其余节点)
将配置好的文件同步到其他两台机器:
分发slaves:
#分发到10.8.16.209
scp /home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/slaves bigdata@10.8.16.209:/home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/
#分发到10.8.19.210
scp /home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/slaves bigdata@10.8.16.210:/home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/
分发spark-env.sh:
#分发到10.8.16.209
scp /home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh bigdata@10.8.16.209:/home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/
#分发到10.8.19.210
scp /home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh bigdata@10.8.16.210:/home/bigdata/spark-2.4.0-bin-hadoop2.7/conf/
也可以分发覆盖全部配置:
scp -r $SPARK_HOME/conf/* bigdata@10.8.16.209:$SPARK_HOME/conf/
scp -r $SPARK_HOME/conf/* bigdata@10.8.16.210:$SPARK_HOME/conf/
5. 集群启停
5.1 启动集群 (在 10.8.16.213 执行)
#进入spark路径
cd /home/bigdata/spark-2.4.0-bin-hadoop2.7/sbin
#启动
./start-all.sh
5.2 停止集群
./stop-all.sh
6. 验证与测试
6.1 进程检查
各节点执行 jps:
-
213: Master, Worker
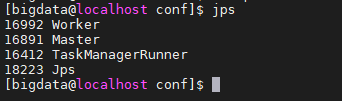
-
209/210: Worker

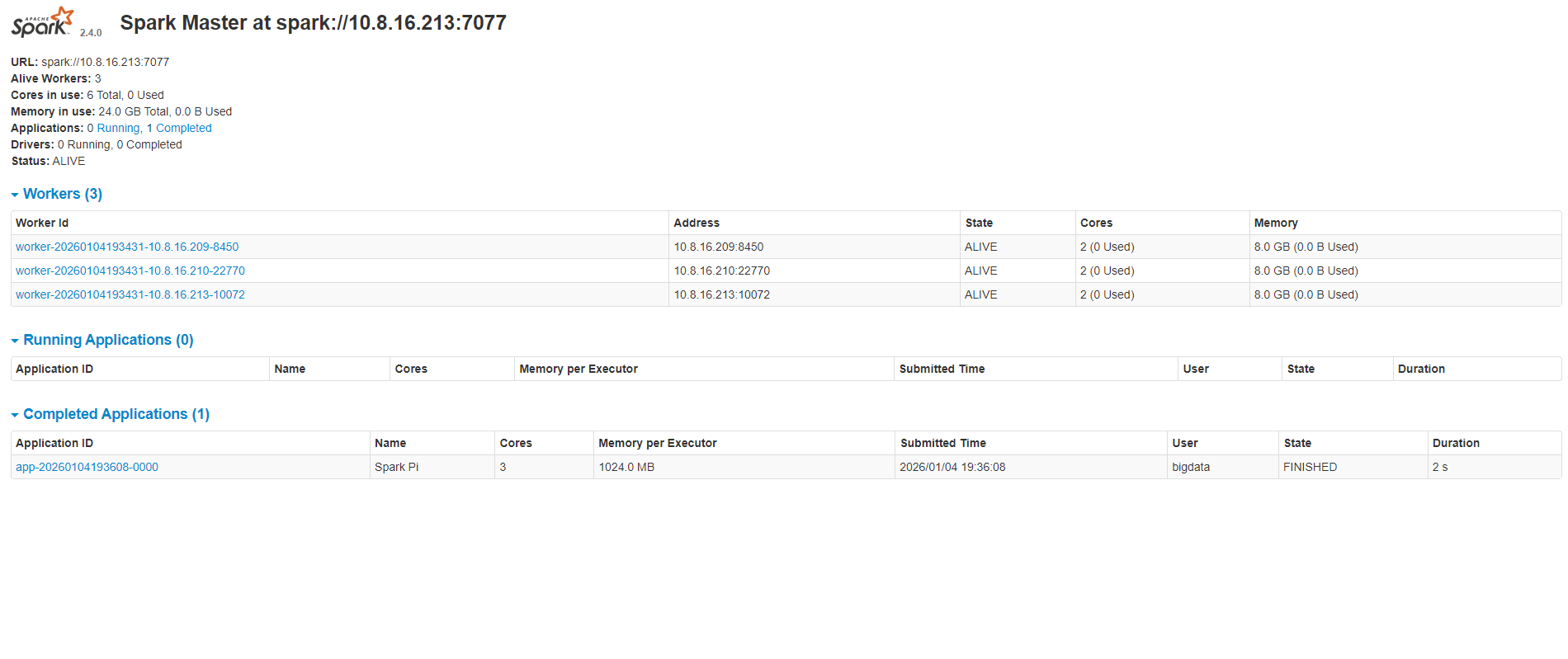
6.2 Web UI 监控
访问:http://10.8.16.213:xxxx(自定义的端口)
确认 Alive Workers 数量为 3。
6.3 运行示例任务
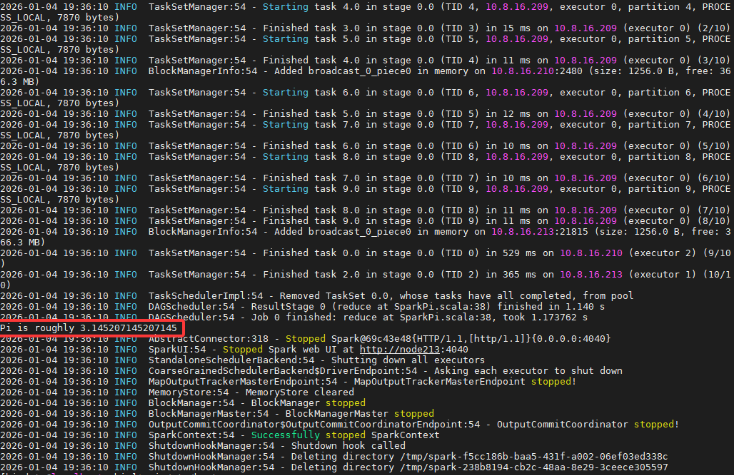
在 10.8.16.213 节点执行以下官方示例命令(计算圆周率 Pi):
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://10.8.16.213:7077 \
--executor-memory 1G \
--total-executor-cores 3 \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.4.0.jar \
10
结果确认:在终端日志或 Web UI 的 stdout 中看到 Pi is roughly 3.1415…。

















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









